







 2014年,OXFORDVisualGeometryGroup使用VGG模型在ImageNet竞赛中获得定位第一和分类第二的成绩。通过六组实验,展示了深度逐渐增加的网络模型在图像分类和定位任务上的优越性,尤其是16层和19层的VGGNet模型。这些模型使用固定大小的输入图像,经过预处理,并采用了特定的卷积层、池化层和激活函数配置。
2014年,OXFORDVisualGeometryGroup使用VGG模型在ImageNet竞赛中获得定位第一和分类第二的成绩。通过六组实验,展示了深度逐渐增加的网络模型在图像分类和定位任务上的优越性,尤其是16层和19层的VGGNet模型。这些模型使用固定大小的输入图像,经过预处理,并采用了特定的卷积层、池化层和激活函数配置。
论文来源:https://arxiv.org/abs/1409.1556
OXFORD Visual Geometry Group在2014年夺得ImageNet定位第一和分类第二,他们的模型称为VGG。

这篇文章是以比赛为目的——解决ImageNet中的1000类图像分类和定位问题。在此过程中,作者做了六组实验,对应6个不同的网络模型,这六个网络深度逐渐递增的同时,也有各自的特点。实验表明最后两组,即深度最深的两组16和19层的VGGNet网络模型在分类和定位任务上的效果最好。作者因此斩获2014年分类第二(第一是GoogLeNet),定位任务第一。
ConvNet Configurations
Architecture
训练过程中,输入为固定的 224 ∗ 224 224*224 224∗224的RGB图像,论文在这里提到唯一的预处理是在训练时的输入的每个像素值都会减去所有通道上的像素平均值,对此我不是很理解,不知有没有人能在评论解答一下,先感谢一下!模型中所有卷积层的卷积核尺寸均为33(因为这是最小的尺寸了11卷积核只会在通道方向进行特征交互),步长为1,填充为1像素,为此卷积前后的分辨率没有改变;池化层均为最大池化层,窗口尺寸为2*2,步长为2;激活函数均为ReLU。同时,这部分说了之前AlexNet中采用的LRN在比赛时并没有改善性能,反而增加了时间和空间复杂度。
Configurations
作者做的六组实验,其模型结构及参数量如下图:
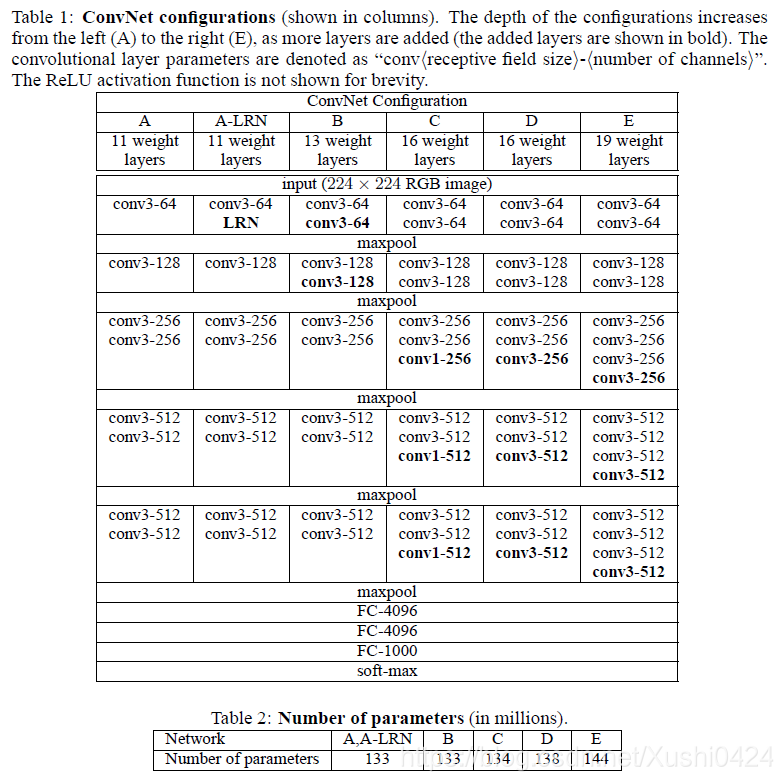
其中最后两列,常称为VGG16与VGG19。上述模型中特征图通道数从64增长到512,每次增长2倍。参数量均为133millions+,但是三层全连接层就有123.63millions,这么大的参数量将会导致训练速度缓慢。
第一个全连接层处理是将之前的77512拉直为1*25088。
Discussion
对于步长为2的33卷积核,1层的感受野显然为33,而2层的感受野为55,3层即为77,这与直接用1层7*7卷积核得到的感受野大小是一样的,但是前者提取的特征效果会更好,同时参数量也少很多。
另外更深的网络结构表现出更好的性能,ILSVRC-2014分类第一的GoogLeNet也使用了在当时较深的网络结构(22层)。也不知道是不是从这时候开始认为Deeper and Better,然后He Kaiming大神的ResNet应运而生!

















 8685
8685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









