



Flux 模型今年发布之后,带来了文生图的一次升级,图像生成的质量效果飞跃提升。
但 Flux 对显存提出了要求。Flux.1 拥有高达12B的训练参数。FLUX.1 [dev] 和 FLUX.1 [schnell]两个版本官方原配模型大小为 23.8GB,需要至少 24GB 的显卡才能顺利运行。不过得益于FP8的支持,经过优化之后模型体积可缩减至 11.9GB,不过跑起来也至少需要 16GB 显存的显卡。
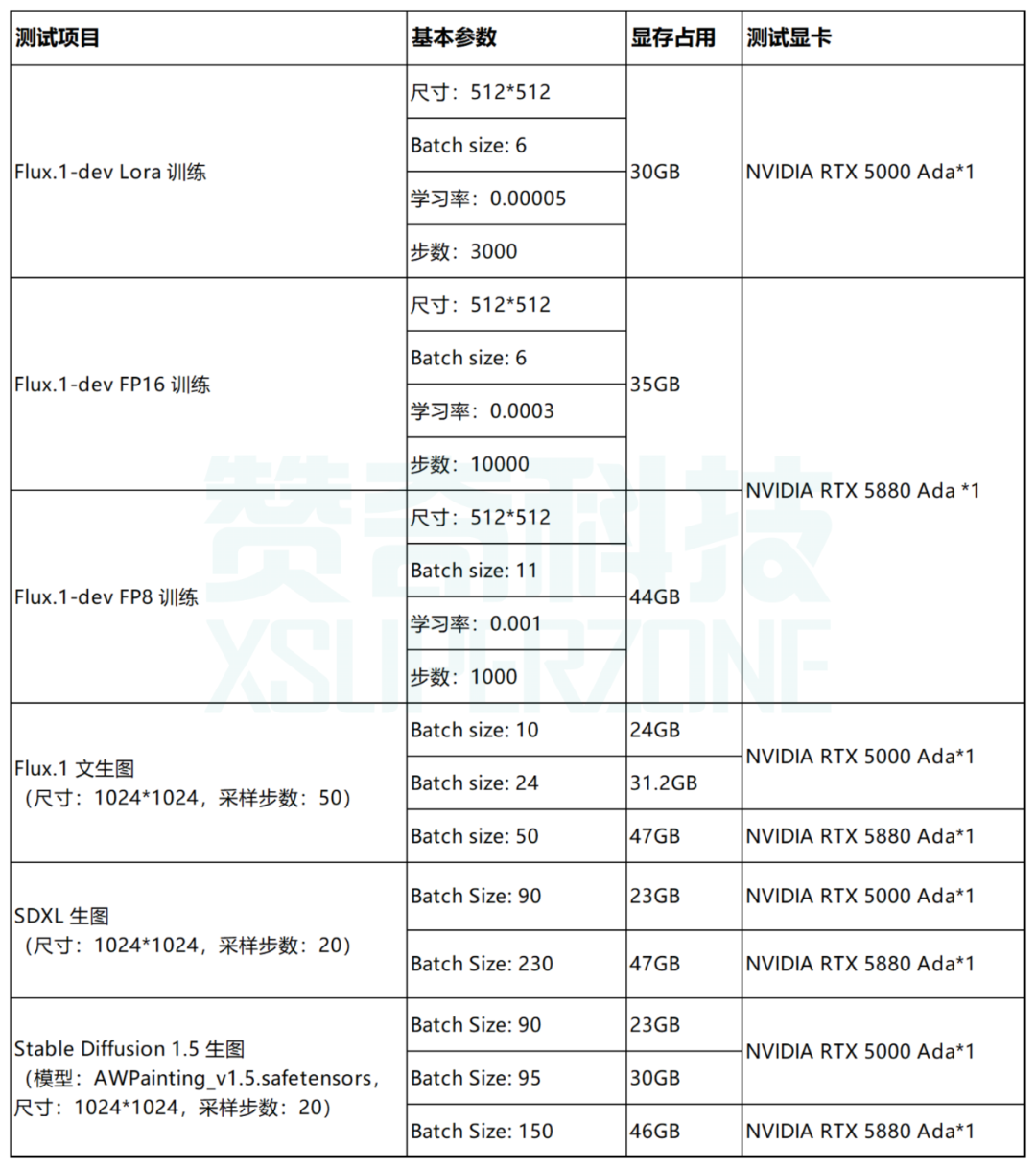
无论是模型训练,还是生图过程,batch size 等参数的调整都会直接影响显存要求。赞奇工程师团队近期对如下应用场景的高 batch size 情形进行了测试:
-
Flux.1-dev Lora 训练
-
Flux.1-dev FP16 训练
-
Flux.1-dev FP8 训练
-
Flux.1 生图
-
SDXL 生图
-
Stable Diffusion 1.5 生图
显卡选择
NVIDIA RTX™ 5000 Ada 及 NVIDIA RTX™ 5880 Ada 分别拥有32GB、48GB的高显存,能够很好地支持文生图模型训练以及 AIGC 生图。我们选用这两款显卡进行测试。

NVIDIA RTX™ 5880 Ada 图片来源于 NVIDIA

NVIDIA RTX™ 5000 Ada 图片来源于 NVIDIA
测试结果总览
接下来我们看看具体测试情况:
Flux.1-dev Lora 训练
我们用单张 NVIDIA RTX 5000 Ada(32GB 显存)进行了Flux Lora 训练的测试。测试用例中尺寸设置512*512,batch size为 6,学习率0.00005,步数为3000时,GPU显存占用约30GB,显卡利用率100%。
测试用例:
1、本地工作站配置
-
GPU:NVIDIA RTX 5000 Ada (32GB) *1
-
CPU: Intel i5-12600KF (3.7GHz) *1
-
内存:64GB
-
系统:win 11
2、训练包版本
3、训练参数:
-
数据集:帽子图片与抠脸人物图
-
ComfyUI工作流
-
学习率:0.00005
-
分辨率:512*512
-
Batch Size:6
-
dim:16
-
alpha: 8
-
步数:3000
其他全部为ComfyUI插件默认参数
* 训练数据集可与下方助手联系获取
4、训练成果

Flux.1-dev FP16 训练
我们采用单张 NVIDIA RTX 5880 Ada(48GB)开展测试。测试用例中尺寸512*512,batch size为 6,学习率0.0003,步数设置10000时,显卡显存占用约35GB,显卡利用率到 93%,共耗时20小时15分,迭代一步约7.3秒。
测试用例:
1、本地工作站配置
-
GPU:NVIDIA RTX 5880 Ada (48GB) *1
-
CPU: Intel i5-12600KF (3.7GHz) *1
-
内存:64GB
-
系统:win 11
2、训练参数
-
Flux models:
-
transformer: flux1-dev.safetensors
-
vae: ae.safetensors
-
clip_l: clip_l.safetensors
-
t5: t5xxl_fp16.safetensors
-
unetLR: 0.0003
-
networkDim: 16
-
1rScheduler: cosine_with_restarts
-
targetSteps: 10000
-
networkAlpha: 2
-
optimizerType: AdamW8Bit
-
batch size:6
-
dataset size: 512*512
-
数据集:207张
* 详细工作流可详询下方助手
3、训练成果:
原图:

训练结果图(部分):

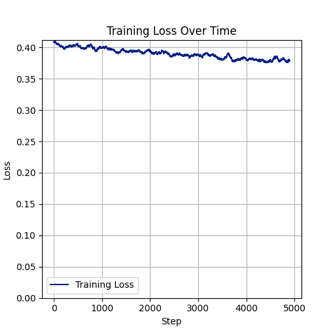
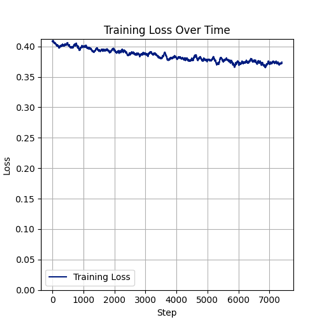
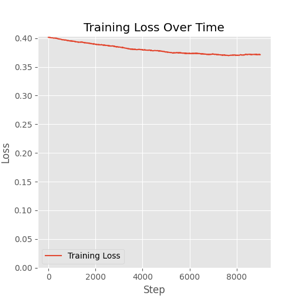
Flux.1-dev FP8 训练
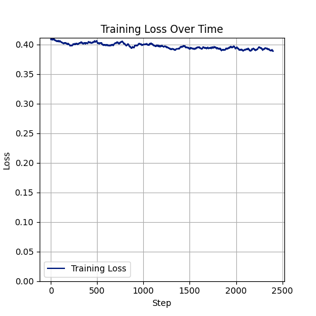
我们继续用单张 NVIDIA RTX 5880 Ada 进行高batch size的模型训练。测试用例中 batch size 设置为11,分辨率512*512,学习率0.001,步数1000时,GPU显存占用约44GB,显卡利用率到97%,共耗时3小时15分,loss 值0.067。
测试用例:
1、本地工作站配置:
与 Flux FP16 训练时相同
2、训练参数:
-
Flux models:
-
transformer: flux1-dev.safetensors
-
vae: ae.safetensors
-
clip_l: clip_l.safetensors
-
t5: t5xxl_fp8.safetensors
-
unetLR: 0.001
-
networkDim: 64
-
1rScheduler: cosine_with_restarts
-
targetSteps: 1000
-
networkAlpha: 32
-
optimizerType: AdamW8Bit
-
batch size:11
-
dataset size: 512*512
-
数据集:30张
* 详细工作流可详询下方助手
3、训练成果:
原图:

训练结果图:

Flux.1 文生图
Flux.1 生图测试中,在尺寸1024*1024,采样步数50步的情况下:
| Batch size | 显存占用 |
| 10 | 24GB |
| 24 | 31.2GB |
| 50 | 47GB |
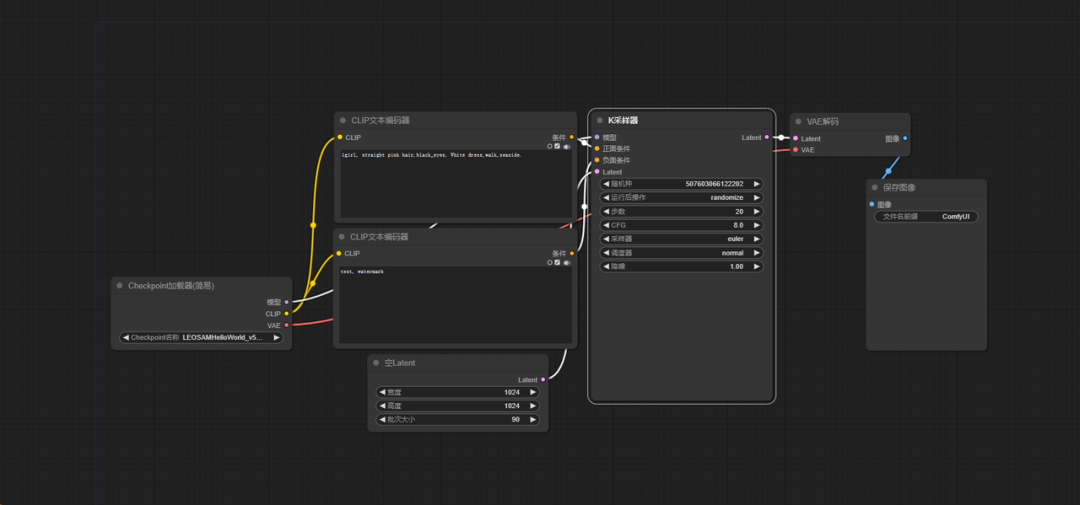
1、工作流设置:
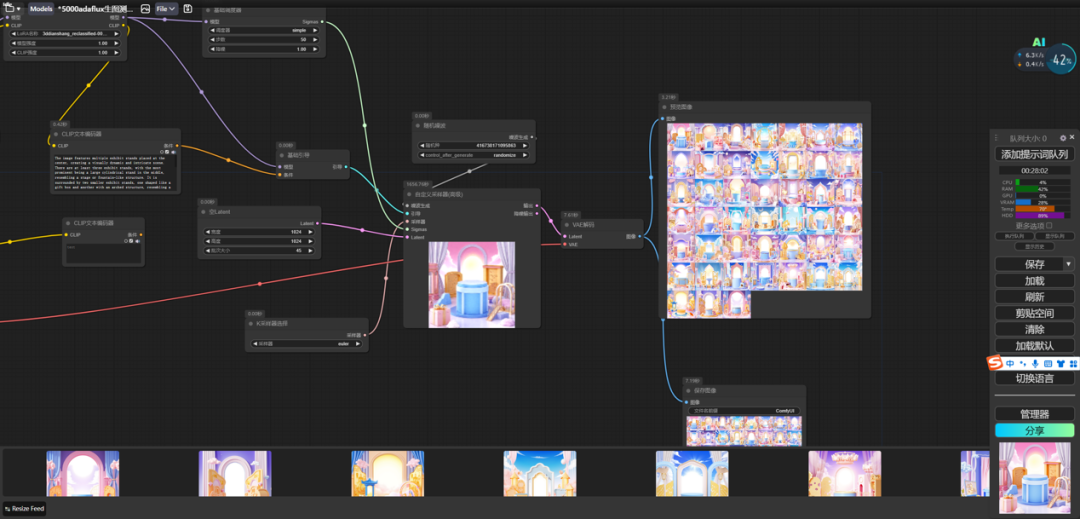
2、本地工作站配置:
-
CPU: Intel i5-12600KF (3.7GHz) *1
-
内存: 64GB
-
系统: win 11
3、测试情况:
我们选用单张 NVIDIA RTX 5000 Ada (32GB) 显卡测试了 batch size 为24时的情况。测试结果显示,GPU 显存占用 31.2GB,GPU 利用率达99%,项目总耗时约18分钟。
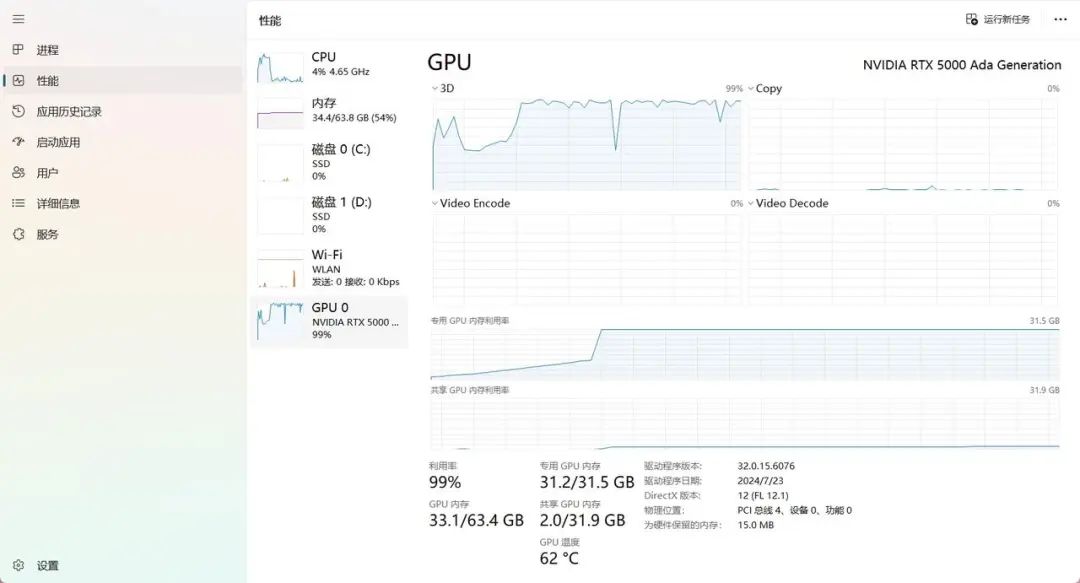
接下来,我们采用单张 NVIDIA RTX 5880 Ada (48GB) 测试了 batch size 为45至50时的情况。测试结果显示:
当 batch size 为 45 时,GPU 显存占用 44GB,GPU利用率达 95%,项目测试用时27分钟。
当 batch size 为 50 时,GPU 显存占用 47GB,GPU利用率达 97%,项目测试耗时约35分钟。
SDXL 生图
SDXL生图测试中,在设置尺寸1024*1024,采样步数20步的情况下:
| Batch size | 显存占用 |
| 90 | 23GB |
| 230 | 47GB |
1、工作流设置:
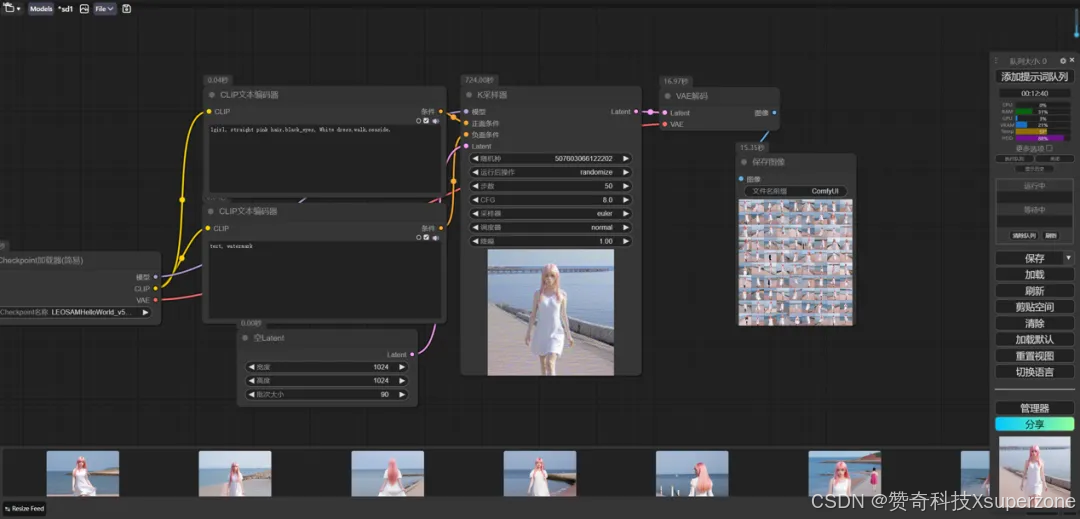
2、本地工作站配置:同 Flux.1 文生图测试。
3、测试情况:
我们选用单张 NVIDIA RTX 5000 Ada (32GB) 显卡测试了 batch size 为 90 时的情况。测试结果显示,在NVIDIA RTX 5000 Ada 加持下,GPU显存占用约23GB,GPU 利用率 97%,生图时间约10分钟,出图效率非常高。
接下来我们用单张 NVIDIA RTX 5880 Ada (48GB) 显卡测试了 batch size 为230 时的情况,GPU显存占用 47GB,GPU 利用率 99%,生图时间约22分钟。
Stable Diffusion 1.5 生图
Stable Diffusion 1.5 生图测试中,模型选用 AWPainting_v1.5.safetensors,尺寸1024*1024,采样步数20步的情况下:
| Batch size | 显存占用 |
| 90 | 23GB |
| 95 | 30GB |
| 150 | 46GB |
1、工作流设置:
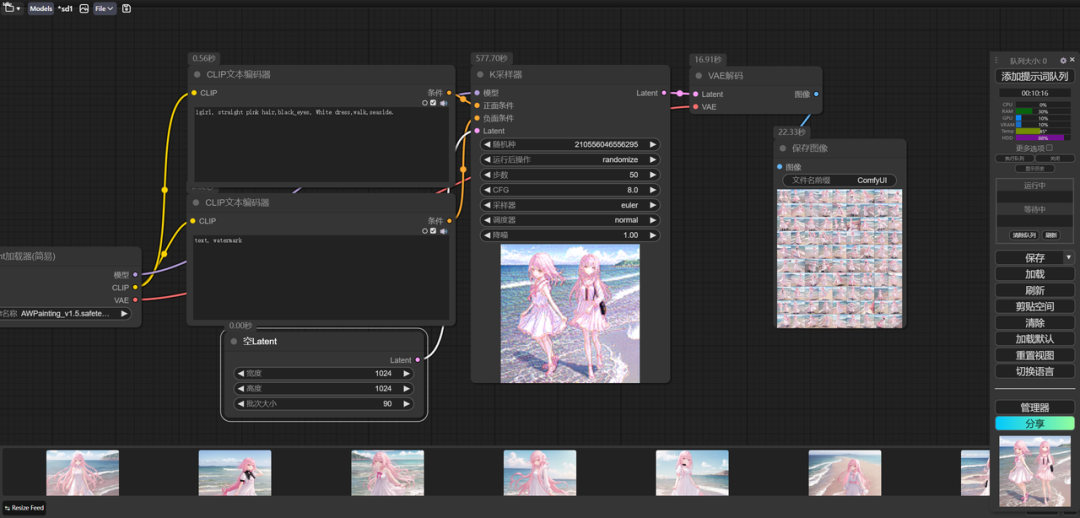
2、本地工作站配置:同Flux.1 文生图测试。
3、测试情况:
我们选用单张 NVIDIA RTX 5000 Ada (32GB) 显卡测试了 batch size 为 90 时的情况。测试结果显示,GPU显存占用约 23GB,GPU利用率100%,生图时间约10分钟,效率极高;batch size 为 95 时,显卡显存占用至 30GB,GPU利用率 99%。
我们采用单张 NVIDIA RTX 5880 Ada (48GB) 显卡测试 batch size 为 150 的情况。结果显示,GPU显存约占 46GB,显卡利用率 96%,生图时间仅6分钟,出图效率非常高。
搭载超强显卡 告别显存焦虑
NVIDIA RTX 5000 Ada 与 NVIDIA RTX 5880 Ada 均具备超高显存,在高 batch size 场景下能将生产力拉满,妥妥地甩开显存焦虑!
如想体验超强显卡的童鞋也可随时申请、免费体验:AI 工作站申请测试
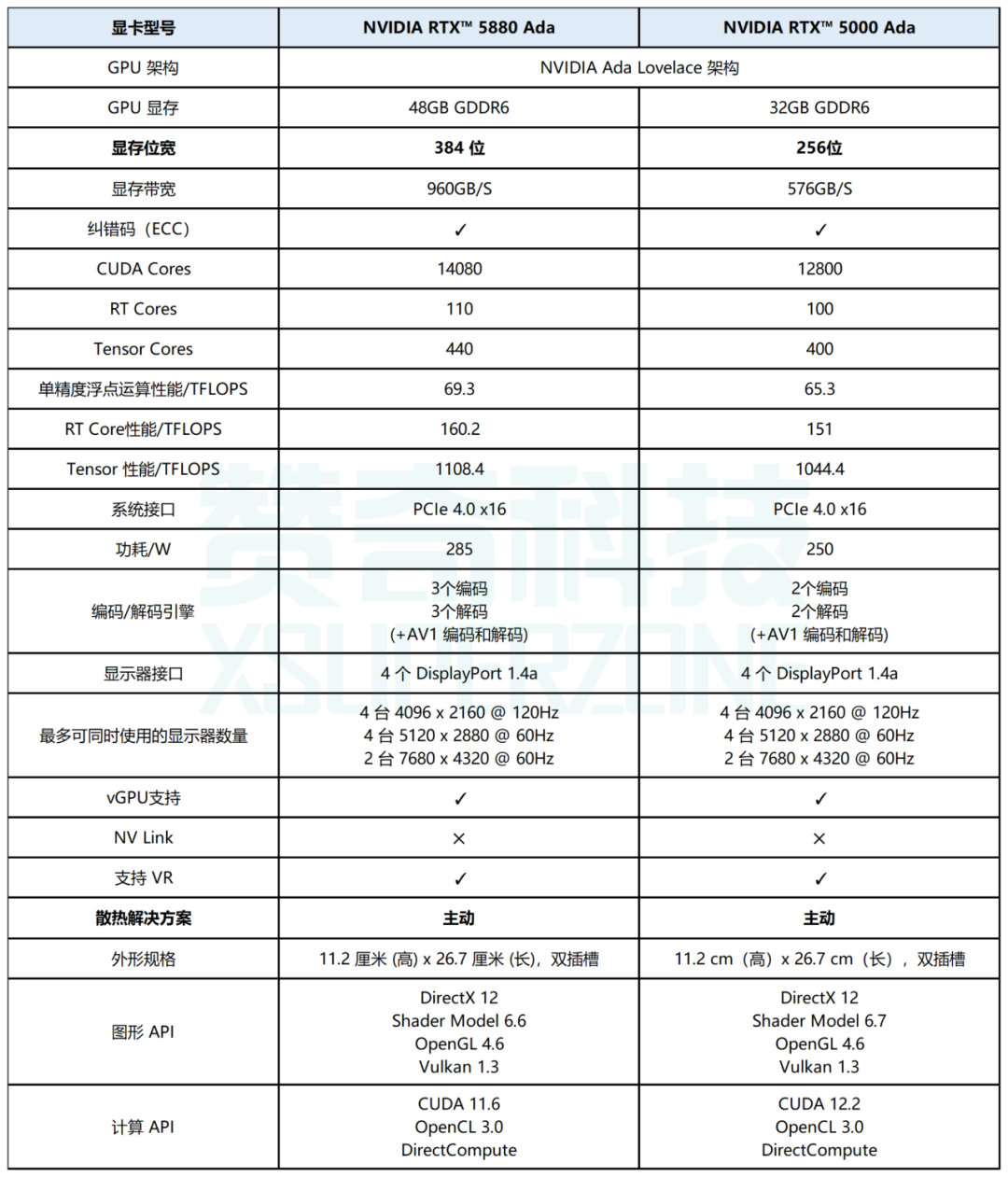
显卡规格
* 如想了解更详细的测试情况可添加微信助手:XSuperZoneTech



















 1922
1922



 到【灌水乐园】发言
到【灌水乐园】发言








