









Annoy
Annoy (Approximate Nearest Neighbors Oh Yeah) is a C++ library with Python bindings to search for points in space that are close to a given query point. It also creates large read-only file-based data structures that are mmapped into memory so that many processes may share the same data.
There are some other libraries to do nearest neighbor search. Annoy is almost as fast as the fastest libraries, (see below), but there is actually another feature that really sets Annoy apart: it has the ability to use static files as indexes. In particular, this means you can share index across processes. Annoy also decouples creating indexes from loading them, so you can pass around indexes as files and map them into memory quickly. Another nice thing of Annoy is that it tries to minimize memory footprint so the indexes are quite small.
Why is this useful? If you want to find nearest neighbors and you have many CPU’s, you only need to build the index once. You can also pass around and distribute static files to use in production environment, in Hadoop jobs, etc. Any process will be able to load (mmap) the index into memory and will be able to do lookups immediately.
We use it at Spotify for music recommendations. After running matrix factorization algorithms, every user/item can be represented as a vector in f-dimensional space. This library helps us search for similar users/items. We have many millions of tracks in a high-dimensional space, so memory usage is a prime concern.
Summary of features
1.Euclidean distance, Manhattan distance, cosine distance, Hamming distance, or Dot (Inner) Product distance
2.Cosine distance is equivalent to Euclidean distance of normalized vectors = sqrt(2-2*cos(u, v))
3.Works better if you don’t have too many dimensions (like <100) but seems to perform surprisingly well even up to 1,000 dimensions
4.Small memory usage
5.Lets you share memory between multiple processes
6.Index creation is separate from lookup (in particular you can not add more items once the tree has been created)
Python code example
from annoy import AnnoyIndex
import random
f = 40
t = AnnoyIndex(f, 'angular') # Length of item vector that will be indexed
for i in range(1000):
v = [random.gauss(0, 1) for z in range(f)]
t.add_item(i, v)
t.build(10) # 10 trees
t.save('test.ann')
# ...
u = AnnoyIndex(f, 'angular')
u.load('test.ann') # super fast, will just mmap the file
print(u.get_nns_by_item(0, 1000)) # will find the 1000 nearest neighbors
Right now it only accepts integers as identifiers for items. Note that it will allocate memory for max(id)+1 items because it assumes your items are numbered 0 … n-1. If you need other id’s, you will have to keep track of a map yourself.
Full Python API
1.a.build(n_trees, n_jobs=-1) builds a forest of n_trees trees. More trees gives higher precision when querying. After calling build, no more items can be added. n_jobs specifies the number of threads used to build the trees. n_jobs=-1 uses all available CPU cores
2.a.get_nns_by_item(i, n, search_k=-1, include_distances=False) returns the n closest items. During the query it will inspect up to search_k nodes which defaults to n_trees * n if not provided. search_k gives you a run-time tradeoff between better accuracy and speed. If you set include_distances to True, it will return a 2 element tuple with two lists in it: the second one containing all corresponding distances.
Tradeoffs
There are just two main parameters needed to tune Annoy: the number of trees n_trees and the number of nodes to inspect during searching search_k
- n_trees is provided during build time and affects the build time and the index size. A larger value will give more accurate results, but larger indexes.
- search_k is provided in runtime and affects the search performance. A larger value will give more accurate results, but will take longer time to return.
How does it work
Using random projections and by building up a tree. At every intermediate node in the tree, a random hyperplane is chosen, which divides the space into two subspaces. This hyperplane is chosen by sampling two points from the subset and taking the hyperplane equidistant from them.
We do this k times so that we get a forest of trees. k has to be tuned to your need, by looking at what tradeoff you have between precision and performance.
More Info
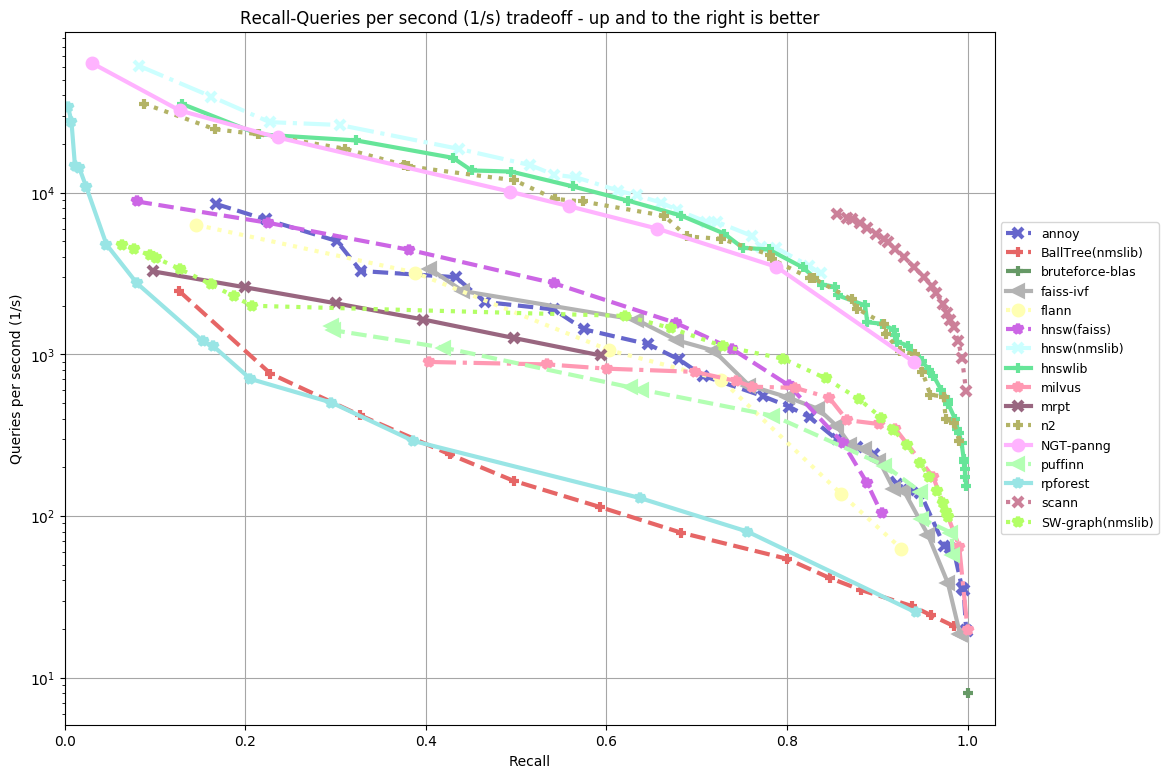
ann-benchmarks is a benchmark for several approximate nearest neighbor libraries. Annoy seems to be fairly competitive, especially at higher precisions:

















 3341
3341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









