



1 Pandas库
Pandas 是 Python 中最核心的数据分析库,专为处理结构化数据(如表格数据、时间序列等)而设计。
Pandas的主要作用有以下几点:
1、Pandas提供了一系列易于使用的数据结构和工具,包括Series(一维标签化数据结构)和DataFrame(二维标签化数据结构)。
2、Pandas擅长处理和分析结构化数据,如表格数据、时间序列数据等
3、Pandas支持从多种数据源读取数据,包括CSV文件、Excel文件、SQL数据库、网页等
4、Pandas提供了强大的数据分组和聚合功能,如求和、计数、平均值、中位数等
5、Pandas与Matplotlib、Seaborn等数据可视化库结合使用,可以轻松地绘制各种图表,如线图、柱状图、散点图、箱线图等。
两个核心数据结构
Series(序列):一维数据结构,类似带标签的数组
DataFrame(数据框):二维数据结构,类似 Excel 表格或 SQL 表
2 Series
Series是Pandas中的一维标签化数据结构,它可以存储任何数据类型(整数、字符串、浮点数、Python对象等),Series对象中每个元素都有一组索引与之对应,可以将其看做是特殊的字典。
2.1 Series创建
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
参数:data:表示传入的数据,可以是列表、数组、字典等。
index:表示索引,唯一且与数据长度相等。如果不指定,默认会自动创建一个从0开始的整数索引。
dtype:数据类型,默认会自己判断。可以显式指定数据类型以确保数据的一致性。
name:设置Series的名称,方便后续操作。
copy:拷贝数据,默认为False。如果设置为True,则会复制数据以避免在原始数据上进行修改。
fastpath:内部参数,通常不需要用户指定。
import numpy as np
import pandas as pd
# 1.列表创建
se1 = pd.Series([1, 2, 3, 5, 7])
print(type(se1))
# <class 'pandas.core.series.Series'>
print(se1)
# 0 1
# 1 2
# 2 3
# 3 5
# 4 7
# dtype: int64
# 2.元组创建
se2 = pd.Series((1, 3, 5, 7, 9))
print(type(se2))
# <class 'pandas.core.series.Series'>
print(se2)
# 0 1
# 1 3
# 2 5
# 3 7
# 4 9
# dtype: int64
# 3.通过numpy数组创建
se3 = np.array([1, 2, 3, 5, 7])
print(type(se3))
# <class 'numpy.ndarray'>
print(se3)
# [1 2 3 5 7]
# 通过字典创建,将键作为索引
data = {'a': 1, 'b': 2, 'c': 3}
se4 = pd.Series(data)
print(type(se4))
# <class 'pandas.core.series.Series'>
print(se4)
# a 1
# b 2
# c 3
# dtype: int64
2.2 Series访问
Series的访问有四种方式:
位置索引:直接通过默认索引进行访问
标签索引:使用标签进行索引,与访问字典中的元素类似。
切片索引:通过start:stop进行切片,开始值与终止值可以省略。
第一种是使用位置切片,其使用方法与列表的切片类似;遵循左闭右开,只包含start,不包含stop
第二种是使用标签切片,其语法与位置切片类似,遵循左右都闭合,即既包含start,又包含stop。
import numpy as np
import pandas as pd
ind = ['a', 'b', 'c', 'd', 'e']
se = pd.Series([1, 2, 3, 4, 5], index=ind)
print(se)
# a 1
# b 2
# c 3
# d 4
# e 5
# 位置索引
print(se[1]) # 下标为1的数据:2
# 标签索引
print(se['b']) # 标签为b的索引:2
# 切片索引
print(se[0:2]) # 访问 第一行 第二行
# a 1
# b 2
# dtype: int64
print(se['a':'c']) # 切片标签索引: a~c,包含c
# a 1
# b 2
# c 3
# dtype: int64
# 函数访问:get
print(se.get(1)) # 2
print(se.iloc[1]) # 2
# 当指定的索引超出了数据索引范围返回Not Found
print(se.get('w', 'Not Found'))
# Not Found
# 返回Series的前n个元素,默认为前5个
print(se.head())
# Not Found
# a 1
# b 2
# c 3
# d 4
# e 5
# dtype: int64
# 返回Series的后n个元素,默认为后5个。
print(se.tail(4)) # 访问后4个数据
# b 2
# c 3
# d 4
# e 5
# dtype: int64
# 判断series中是否存在指定的值,返回bool类型Series数据
val = [2, 5] # 新定义一个数组,2,5为数据
print(se.isin(val)) # 判断筛选,返回布尔值
# a False
# b True
# c False
# d False
# e True
# dtype: bool
2.3 Series属性
values:返回Series的值数组,以NumPy数组的形式返回。
index:返回Series的索引数组,索引用于标识每个数据点的位置。
dtype:返回Series的数据类型,例如int64、float64或object等。
size:返回Series的大小,即数据点的数量。
shape:返回Series的形状,以元组的形式表示,对于Series来说,其形状是一个一维数组的长度。
name:返回Series的名称,可以通过在创建Series时指定name参数来设置。
hasnans:返回数据中是否包含NaN值,存在NaN返回True否则返回False。
is_unique:用于返回数组中的元素是否为独一无二的,如果所有的元素都是独一无二的,即数组中没有重复元素,那么就返回True,否则返回False。
empty:用来表示Series数组是否为空,返回值一个布尔值,如果数组里一个元素都没有就返回True,否则返回False。数组里写有 None 或 np.nan 表示空
axes:用于返回series对象索引的列表。
import numpy as np
import pandas as pd
ind = ['a', 'b', 'c', 'd', 'e', 'f']
se = pd.Series([1, 2, 3, 4, 5, None], index=ind, name='pandas-Series')
# 获取值
print(se.values) # [ 1. 2. 3. 4. 5. nan] 是一个数组
print(type(se.values)) # <class 'numpy.ndarray'>
# 获取索引值
print(se.index) # Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object')
# 获取元素类型
print(se.dtype) # float64
# 获取数据个数
print(se.size) # 6
# 获取形状
print(se.shape) # (6,)其形状是一个一维数组的长度。
# 获取名称
print(se.name) # pandas-Series
# 判断是否有None值,有返回True
print(se.hasnans) # True
# 判断数据是否独一无二,即数据不重复,返回True
print(se.is_unique) # True
# 判断是否为空
print(se.empty) # False
# 获取索引的列表
print(se.axes) # [Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object')]
3 Dataframe
DataFrame是Pandas库中的另一个核心数据结构,它用于表示二维表格型数据;它类似于Excel中的表格或SQL表,具有行和列。
DataFrame由一组有序的列组成,每列可以是不同的数据类型(如数值、字符串、布尔型值等)。DataFrame既有行索引也有列索引,提供了丰富的功能来进行数据访问、筛选、分割、合并、重塑、聚合以及转换等操作。
3.1 Dataframe创建
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
参数:
data:数据输入,可以是ndarray、series、list、dict等类型。如果为dict,则dict的键会被用作列名,除非columns参数被显式指定。
index:行标签索引,如果没有提供,则默认为整数索引。
columns:列标签,如果没有提供且没有通过data参数传递列名,则默认为整数索引。
dtype:数据类型,可选。如果指定,则数据类型会被强制转换为dtype类型。
copy:复制数据,默认为False。如果为True,则复制数据以避免在原始数据上进行修改。
import numpy as np
import pandas as pd
df1 = pd.DataFrame([["张三", '25', 183], ['lisi', 23, 165], ['wangwu', 23, 155]])
print(df1)
# 0 1 2
# 0 张三 25 183
# 1 lisi 23 165
# 2 wangwu 23 155
# 根据字典创建
data1 = {'name': ['zhangsan', 'lisi', 'wangwu'], 'age': [24, 30, 18]}
df2 = pd.DataFrame(data1)
print(df2)
# name age
# 0 zhangsan 24
# 1 lisi 30
# 2 wangwu 18
# 根据numpy数组创建
data2 = np.random.rand(2, 3)
df3 = pd.DataFrame(data2)
print(df3)
# 0 1 2
# 0 0.678841 0.674517 0.285509
# 1 0.741403 0.239407 0.513181
data2 = np.random.rand(2, 3)
# 行标签
ind = ['a', 'b']
# 列标签
col = ['aa', 'bb', 'cc']
# 指定行列标签
df = pd.DataFrame(data2, index=ind, columns=col)
print(df)
# aa bb cc
# a 0.986127 0.848491 0.260365
# b 0.461649 0.216356 0.225175
3.2 Dataframe访问
3.2.1 通过中括号访问数据
注意先指定列标签再指定行标签。
import pandas as pd
data = {'name': ['zhangsan', 'lisi', 'wangwu'], 'age': [24, 30, 18]}
ind = ['a', 'b', 'c']
df = pd.DataFrame(data, index=ind)
# 访问元素时,先指定列在指定行标签
print(df['name'])
# a zhangsan
# b lisi
# c wangwu
# Name: name, dtype: object
# 访问元素时,先指定列在指定行标签
print(df['name'][0]) # zhangsan
print(df['name']['a']) # zhangsan
# 以列表的方式列出访问的列
print(df[['name', 'age']]) # zhangsan
# name age
# a zhangsan 24
# b lisi 30
# c wangwu 18
3.2.2 通过函数进行访问
df.loc[row_label, column_label]
功能:是基于标签的索引,用于通过行标签和列标签访问数据。
参数:row_label:行标签,可以是单个标签、标签列表、切片或布尔数组。
column_label:列标签,可以是单个标签、标签列表、切片或布尔数组
df.iloc[row_position, column_position]
功能:是基于位置的索引,用于通过行和列的位置访问数据。
参数:row_position:行的位置,可以是整数、整数列表、切片或布尔数组。
column_position:列的位置,可以是整数、整数列表、切片或布尔数组。
import numpy as np
import pandas as pd
data2 = {'name': ['zhangsan', 'lisi', 'wangwu'], 'age': [24, 30, 18]}
ind = ['1', '2', '3']
df = pd.DataFrame(data2, index=ind) # 使用 pd.DataFrame() 构造函数创建DataFrame
print(df)
# name age
# 1 zhangsan 24
# 2 lisi 30
# 3 wangwu 18
# 基于标签的索引
print(df.loc['1', 'name']) # zhangsan
# 基于位置的索引
print((df.iloc[0, 1])) # 24 坐标位置为(1,2)
3.3 Dataframe属性
index:返回行标签。
columns:返回列标签。
axes:返回行轴和列轴的列表。
values:返回DataFrame中的数据,以NumPy数组的形式。
dtypes:返回DataFrame中各列的数据类型。
shape:返回DataFrame的形状,即数据的维度(行数和列数)。
size:返回DataFrame中的元素个数。
ndim:返回DataFrame的维度(对于DataFrame来说,总是2)。
empty:判断DataFrame是否为空,如果为空则返回True,否则返回False。
T:返回DataFrame的转置
import numpy as np
import pandas as pd
# index:返回行标签。
data = {'姓名': ['张三', '李四', '王五', '赵六'],
'年龄': [25, 30, 28, 35],
'城市': ['北京', '上海', '济南', '北京'],
'工资': [15000, 18000, 22000, 25000]
}
ind = ['1', '2', '3', '4']
df = pd.DataFrame(data, index=ind)
print(df)
# 姓名 年龄 城市 工资
# 1 张三 25 北京 15000
# 2 李四 30 上海 18000
# 3 王五 28 济南 22000
# 4 赵六 35 北京 25000
print(df.index) # 返回行标签,默认是整数索引(0, 1, 2, 3)
# Index(['1', '2', '3', '4'], dtype='object')
# 可自定义索引
df1 = df.set_index('姓名')
print(df1)
# 年龄 城市 工资
# 姓名
# 张三 25 北京 15000
# 李四 30 上海 18000
# 王五 28 济南 22000
# 赵六 35 北京 25000
print(df.columns) # 返回列标签
# Index(['姓名', '年龄', '城市', '工资'], dtype='object')
# # 可修改列名:
# df.columns = ['name', 'age', 'city', 'salary']
# print(df)
# # name age city salary
# # 1 张三 25 北京 15000
# # 2 李四 30 上海 18000
# # 3 王五 28 济南 22000
# # 4 赵六 35 北京 25000
print(df.axes) # 返回行轴和列轴
# [Index(['1', '2', '3', '4'], dtype='object'),
# Index(['姓名', '年龄', '城市', '工资'], dtype='object')]
# 返回包含两个元素的列表
# 第一个元素是行索引(index)
# 第二个元素是列索引(columns)
print(df.values) # 返回数据的 NumPy 数组形式
# [['张三' 25 '北京' 15000]
# ['李四' 30 '上海' 18000]
# ['王五' 28 '济南' 22000]
# ['赵六' 35 '北京' 25000]]
# 返回 DataFrame 的原始数据(不包含索引和列名)
# 数据类型会自动转换(混合类型会转换为对象数组)
# 使用 df.to_numpy() 可指定数据类型
print(df.dtypes) # 返回各列数据类型
# 姓名 object
# 年龄 int64
# 城市 object
# 工资 int64
# dtype: object
# object 通常表示字符串或混合类型
# 可转换数据类型:df['年龄'] = df['年龄'].astype(float)
print(df.shape) # 返回数据形状(维度)
# (4, 4)
# 返回元组 (行数, 列数)
# # 类似 NumPy 数组的 shape 属性
# # 获取行数:df.shape[0]
# # 获取列数:df.shape[1]
print(df.size) # 返回元素总个数
# 16
print(df.ndim) # 返回维度数
# 2
# DataFrame 总是二维的
# Series 的 ndim 为 1
# 判断是否为空
print(df.empty) # 输出:False
empty_df = pd.DataFrame()
print(empty_df.empty) # 输出:True
# 当 DataFrame 没有行或没有列时返回 True
# 注意:包含列名但无数据的 DataFrame 不为空
print(df.T) # 返回转置
# 1 2 3 4
# 姓名 张三 李四 王五 赵六
# 年龄 25 30 28 35
# 城市 北京 上海 济南 北京
# 工资 15000 18000 22000 25000
# 行变列,列变行
# 相当于 df.transpose()
# 对于宽表转长表特别有用
4 数据操作
4.1 数据清洗
4.1.1 dropna
dropna(axis=0, inplace=False)
功能:删除包含NaN值的行 None或 np.nan表示空
参数:axis:用于指定按哪个轴删除缺失值,默认为0(一维数据结构不用修改)
inplace:True,直接在原数据上删除缺失值
False,返回一个删除了缺失值的新结构
import numpy as np
import pandas as pd
data = {'name': ['zhangsan', 'lisi', np.NaN], 'age': [24, None, 18]}
ind = ['1', '2', '3']
df = pd.DataFrame(data, index=ind)
print(df)
# name age
# 1 zhangsan 24.0
# 2 lisi NaN
# 3 NaN 18.0
setl = df.dropna(axis=0, inplace=False) # 按行删除
# inplace默认为False,返回一个删除了缺失值的新结构,所以要生成个返回值
print(setl)
# name age
# 1 zhangsan 24.0
setl2 = df.dropna(axis=1, inplace=True) # 按列删除
# inplace:True,直接在原数据上删除缺失值
print(setl2)
# None
4.1.2 fillna
fillna(value=None)
功能:填充NaN的值(不修改原数据)
参数:value:可以是单个值,也可以是字典(对不同的列填充不同的值),或者一个 Series。
返回值:新的数据结构
import numpy as np
import pandas as pd
data2 = {'name': ['zhangsan', 'lisi', np.NaN], 'age': [24, None, 18]}
ind = ['1', '2', '3']
df = pd.DataFrame(data2, index=ind)
print(df)
# name age
# 1 zhangsan 24.0
# 2 lisi NaN
# 3 NaN 18.0
setl1 = df.fillna(0)
# 功能:填充NaN的值(不修改原数据),返回值:新的数据结构,所以要生成个返回值
print(setl1)
# name age
# 1 zhangsan 24.0
# 2 lisi 0.0
# 3 0 18.0
setl2 = df.fillna({'name': 'qq', 'age': 19})
print(setl2)
# name age
# 1 zhangsan 24.0
# 2 lisi 19.0
# 3 qq 18.0
使用Series进行修改
import numpy as np
import pandas as pd
data2 = {'name': ['zhangsan', 'lisi', np.NaN], 'age': [None, None, None]}
ind = ['1', '2', '3']
df = pd.DataFrame(data2, index=ind)
# 若填充时,某一列或一行都没有,要填充时需要不一样的数据,使用Series,使用字典,会全部覆盖。
print(df)
# name age
# 1 zhangsan None
# 2 lisi None
# 3 NaN None
setl2 = df.fillna({'name': 'qq', 'age': 19})
print(setl2)
# name age
# 1 zhangsan 19
# 2 lisi 19
# 3 qq 19
val = pd.Series({'1': 20, '2': 25, '3': 22})
print((val))
# 1 20
# 2 25
# 3 22
# dtype: int64
ret = df.fillna(({'age': val}))
print(ret)
# name age
# 1 zhangsan 20
# 2 lisi 25
# 3 NaN 22
4.1.3 isnull
isnull()
功能:检测数据对象中的缺失值,它会返回一个布尔型结构,其中每个元素表示原数据对应位置的值是否为缺失值(NaN)。
import numpy as np
import pandas as pd
data = {'name': ['zhangsan', 'lisi', np.NaN, None], 'age': [36, 23, None, np.NaN]}
ind = ['a', 'b', 'c', 'd']
df = pd.DataFrame(data, index=ind)
print(df)
# name age
# a zhangsan 36.0
# b lisi 23.0
# c NaN NaN
# d None NaN
setl = df.isnull() # 返回一个布尔型结构
print(setl)
# name age
# a False False
# b False False
# c True True
# d True True
4.1.4 drop_duplicates
drop_duplicates(keep='first', inplace=False, ignore_index=False)
功能:用于去除数据对象中的重复项
参数:keep:决定了如何处理重复项
first:默认值,保留第一次出现的重复项
last:保留最后一次出现的重复项
False:不保留任何重复项,即删除所有重复项
ignore_index:默认False,True表示重置索引为默认整数索引
import numpy as np
import pandas as pd
data = {'name': ['zhangsan', 'lisi', np.NaN, None], 'age': [36, 23, None, np.NaN]}
ind = ['a', 'b', 'c', 'd']
df = pd.DataFrame(data, index=ind)
print(df)
# name age
# a zhangsan 36.0
# b lisi 23.0
# c NaN NaN
# d None NaN
# drop_duplicates 在Dataframe中删除重复的行数据
# last为保留最后一次的重复项,ignore_index:重置索引为位置索引(代码中行的行数a,b,c,变为了0,1,2)
ret1 = df.drop_duplicates(keep='last', ignore_index=True)
print(ret1)
# name age
# 0 zhangsan 36.0
# 1 lisi 23.0
# 2 None NaN
# first:默认值,保留第一次出现的重复项
ret2 = df.drop_duplicates()
print(ret2)
# name age
# a zhangsan 36.0
# b lisi 23.0
# c NaN NaN
# False:不保留任何重复项,即删除所有重复项
ret3 = df.drop_duplicates(keep=False)
print(ret3)
# name age
# a zhangsan 36.0
# b lisi 23.0
4.2 数据转换
4.2.1 replace
DataFrame.replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad')
功能:替换特定的值、一系列值或者使用字典映射进行替换
参数:to_replace:要替换的值,标量、列表、字典都可以
value:替换后的新值,格式和to_replace相同
inplace:True,则直接在原 数据上修改,不返回新的对象
import numpy as np
import pandas as pd
data = {'欧阳': [45, 36, 56], '慕容': [45, 68, 53]}
ind = ['a', 'b', 'c']
df = pd.DataFrame(data, index=ind)
ret1 = df.replace(45, 77) # 可不写返回值直接修改
print(ret1) # 单个数据全部替换
# 欧阳 慕容
# a 45 45
# b 36 68
# c 56 53
ret2 = df.replace([45, 68], [53, 99]) # 用列表类型替换
print(ret2) # 45→53,68→99
# 欧阳 慕容
# a 53 53
# b 36 99
# c 56 53
ret3 = df.replace({45: 88, 78: 90}) # 用字典类型修改
print(ret3)
# 欧阳 慕容
# a 88 88
# b 36 68
# c 56 53
4.2.2 transform
函数在 Pandas 中用于对数据进行逐行或逐列的转换操作,它通常接受一个函数(内置函数或自定义函数)作为参数,并将该函数应用于 DataFrame 的每一列或每一行,返回Dataframe和原数组形状一致
DataFrame.transform(func, axis=0, *args, **kwargs)
功能:对DataFrame中的数据进行自定义转换操作
参数:func:应用于DataFrame的函数。这个函数可以是内置函数,或者自定义的函数
import numpy as np
import pandas as pd
def div(x):
return x / 2
data = {'欧阳': [45, 36, 56], '慕容': [45, 68, 2 * np.pi]}
ind = ['a', 'b', 'c']
df = pd.DataFrame(data, index=ind)
# 使用内置函数进行转换
ret1 = df.transform(np.log)
print(ret1)
# 欧阳 慕容
# a 3.806662 3.806662
# b 3.583519 4.219508
# c 4.025352 1.837877
ret2 = df.transform(np.sin)
print(ret2)
# 欧阳 慕容
# a 0.850904 8.509035e-01
# b -0.991779 -8.979277e-01
# c -0.521551 -2.449294e-16
# 使用lambda表达式进行转换
ret3 = df.transform(lambda x: x ** 2)
print(ret3)
# 欧阳 慕容
# a 2025 2025.000000
# b 1296 4624.000000
# c 3136 39.478418
# 使用自定义函数进行转换
ret4 = df.transform(div)
print(ret4)
# 欧阳 慕容
# a 22.5 22.500000
# b 18.0 34.000000
# c 28.0 3.141593
# 传递的函数是多个参数的情况,可以使用lambda表达式
ret5 = df.transform(lambda x: np.power(x, 0.5))
print(ret5)
# 欧阳 慕容
# a 6.708204 6.708204
# b 6.000000 8.246211
# c 7.483315 2.506628
4.3 数据排序
4.3.1 sort_values
函数是用于对 DataFrame 或 Series 的数据进行排序。它可以根据一个或多个列的值对数据进行升序或降序排列。
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
功能:根据一个或多个列的值对 DataFrame 进行排序
参数:
by: 用于排序的列名或列名列表
axis:默认0,对Series无效
ascending:默认True,True:升序,False:降序
inplace:默认False,True:在原始数据上修改
kind:排序算法,默认quicksort(快排)
na_position:默认last,表示NAN放在末尾,first放在开头
ignore_index:默认False,True表示重置索引为默认整数索引
key:函数,默认为None,排序前执行自定义函数
import numpy as np
import pandas as pd
data = {'欧阳': [45, 36, 56], '慕容': [45, 68, 33]}
ind = ['a', 'b', 'c']
df = pd.DataFrame(data, index=ind)
print(df)
# 欧阳 慕容
# a 45 45
# b 36 68
# c 56 33
set1 = df.sort_values(by='欧阳') # 按照列名排序,后面的数据和前面的不分开,按照前面的数据排列
# 以列名“欧阳”对所在列进行排序,其他列跟随“欧阳”列的排序
print(set1)
# 欧阳 慕容
# b 36 68
# a 45 45
# c 56 33
set2 = df.sort_values(by='慕容')
print(set2)
# 欧阳 慕容
# c 56 33
# a 45 45
# b 36 68
# axis:默认0,对Series无效
set3 = df.sort_values(by='c', axis=1)
print(set3)
# 慕容 欧阳
# a 45 45
# b 68 36
# c 33 56
4.3.2 sort_index
DataFrame.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, ignore_index=False, key=None)
功能:根据索引对 DataFrame 进行排序
import numpy as np
import pandas as pd
ind = ['a', 'd', 'c']
data = {'chinese': [90, 67, 89], 'aath': [80, 78, 90]}
df = pd.DataFrame(data, index=ind)
print(df)
# chinese aath
# a 90 80
# d 67 78
# c 89 90
# 按照索引进行排序
ret = df.sort_index(axis=1)
print(ret)
# aath chinese
# a 80 90
# d 78 67
# c 90 89
ret2 = df.sort_index(axis=0)
print(ret2)
# chinese aath
# a 90 80
# c 89 90
# d 67 78
4.4 数据筛查
根据条件或布尔数组进行数据筛选。
import numpy as np
import pandas as pd
ind = ['a', 'b', 'c']
data = {'chinese': [90, 67, 79], 'aath': [80, 78, 90]}
df = pd.DataFrame(data, index=ind)
print(df)
# chinese aath
# a 90 80
# b 67 78
# c 79 90
# 根据条件进行筛选数据
ret1 = df['chinese'] > 88
print(df[ret1])
# chinese aath
# a 90 80
# 根据布尔列表筛选数据
ret2 = [True, False, False]
# True 对应第一行:a 90 80
# False 对应第二行:b 67 78
# False 对应第三行:c 79 90
# True打印,False不打印
print(df[ret2])
4.5 数据拼接
pandas.concat(objs, *, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=None)
功能:将多个Pandas数据沿着一个轴连接起来
参数:objs:参与连接的Pandas对象的列表或元组
axis:连接的轴,0:沿着行方向连接,1沿着列方向连接
join:outer:取所有索引的并集 inner:取所有索引的交集
ignore_index:默认False,True表示重置索引为默认整数索引
inplace:默认False,True:在原始数据上修改
kind:排序算法,默认quicksort(快排)
import pandas as pd
data = {'chinese': [90, 67, 79], 'math': [80, 78, 90]}
df = pd.DataFrame(data)
# 按行增长方向将多个数据进行拼接
new = pd.DataFrame({'chinese': [100], 'math': [80]}, index=['d'])
ret1 = pd.concat([df, new], axis=0)
print(ret1)
# chinese math
# 0 90 80
# 1 67 78
# 2 79 90
# 0 100 80
# 按列增长方向将多个数据进行拼接
new = pd.DataFrame({'english': [80, 78, 67]})
ret2 = pd.concat([df, new], axis=1)
print(ret2)
# chinese math english
# 0 90 80 80
# 1 67 78 78
# 2 79 90 67
5 统计运算
count(axis=0, numeric_only=False)
功能:用于计算 DataFrame 中非 NaN 值的数量
参数:axis:统计的方向,0:按列,1:按行
sum(axis=0, skipna=True, numeric_only=False, min_count=0)
功能:用于计算 DataFrame 中数值的总和
参数:axis: 统计的方向,0:按列,1:按行
skipna: 布尔值,默认为 True,则在计算总和时会忽略 NaN 值。
numeric_only: 布尔值,默认为 False。如果为 True,则只对数值列进行求和,忽略非数值列。
min_count: int,默认为 0。这个参数指定了在计算总和之前,至少需要非 NaN 值的最小数量。如果某个分组中的非 NaN 值的数量小于 `min_count`,则结果为 NaN。
mean(axis=0, skipna=True, numeric_only=False, **kwargs)
功能:用于计算 DataFrame 中数值的平均值
min(axis=0, skipna=True, numeric_only=False, **kwargs)
功能:用于计算 DataFrame 中数值的最小值
max(axis=0, skipna=True, numeric_only=False, **kwargs)
功能:用于计算 DataFrame 中数值的最大值。
var(axis=0, skipna=True, ddof=1, numeric_only=False, **kwargs)
功能:用于计算 DataFrame 中数值的方差
std(axis=0, skipna=True, ddof=1, numeric_only=False, **kwargs)
功能:用于计算 DataFrame 中数值的标准差
quantile(q=0.5, axis=0, numeric_only=False, interpolation='linear', method='single')
功能:计算 DataFrame 中数值的分位数。
补充:分位数的计算方式:
排序数据:首先,将数据集按升序排列。
确定分位数的位置:分位数是将数据集分成等大小的几个部分的值,如果位置是一个整数,那么分位数就是该位置的值。如果位置不是一个整数,那么分位数是该位置的整数部分和下一个整数部分的值的平均值
describe(percentiles=None, include=None, exclude=None)
功能:生成DataFrame中数值列的统计摘要,会返回一个DataFrame
返回值:包括计数、平均值、标准差、最小值、25%分位数、50%分位数(中位数)、75%分位数和最大值等。
value_counts(subset=None, normalize=False, sort=True, ascending=False, dropna=True)
功能:用于计算Series中各个值出现的频率或个数的一个方法。
参数:subset:可选参数,用于指定要进行计算操作的列名列表。如果未指定,则对整个DataFrame的所有列进行操作。
normalize:布尔值,默认为False。如果设置为True,则返回每个值的相对频率,而不是计数。
sort:布尔值,如果设置为True,则结果将按计数值降序排序。
ascending:布尔值,当`sort=True`时,此参数指定排序顺序。如果设置为True,则结果将按计数值升序排序。
dropna:布尔值,如果设置为True,则在计数之前排除缺失值。
import pandas as pd
ind = ['a', 'c', 'b']
data = {'chinese':[90, 90, 89], 'math':[80, 80, 90]}
df = pd.DataFrame(data, index=ind)
print(df)
print('------------------------')
# print(df.count(axis=1))
# print(df.sum(axis=1))
# se = pd.Series([1,2,3,4])
# print(se.quantile(0.25)) # 67 89 90
print(df.value_counts(['chinese']))
6 分组和聚合
6.1 groupby
用于将数据分组,并允许对分组后的数据进行聚合、转换、应用函数等操作。返回值是一个 DataFrameGroupBy 对象,可以对 DataFrameGroupBy 对象应用聚合函数,如 sum、mean、max、min 。
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, observed=False, dropna=True)
功能:用于将数据分组,并允许对这些分组进行操作
参数:by:是一个键(列名)、键的列表或函数,用于分组
axis:用于分组的轴
返回值:是一个 DataFrameGroupBy 对象,是一个可以对分组数据进行进一步操作的对象
DataFrameGroupBy.get_group(分组名)
功能:根据分组名获取分组后的数据
import pandas as pd
data = {
'Abc': ['A', 'B', 'A', 'B', 'C', 'A', 'C', 'B'],
'Value1': [10, 20, 30, 40, 50, 60, 70, 80],
'Value2': [1, 2, 3, 4, 5, 6, 7, 8]
}
df = pd.DataFrame(data)
print(df)
# Abc Value1 Value2
# 0 A 10 1
# 1 B 20 2
# 2 A 30 3
# 3 B 40 4
# 4 C 50 5
# 5 A 60 6
# 6 C 70 7
# 7 B 80 8
# 对数据进行分组
ret1 = df.groupby('Abc') # 对Abc进行分组
print(ret1)
# <pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000019BE3000190>
# 分组后返回值是DataframeGroupby类型,直接访问类中的统计函数
print(ret1.sum()) # 求和
# Value1 Value2
# Abc
# A 100 10
# B 140 14
# C 120 12
print(ret1.mean()) # 求平均
# Value1 Value2
# Abc
# A 33.333333 3.333333
# B 46.666667 4.666667
# C 60.000000 6.000000
print(ret1.max()) # 求最大
# 获取DataframeGroupby类对象中某一类的数据
data = ret1.get_group('A')
print(data)
# Abc Value1 Value2
# 0 A 10 1
# 2 A 30 3
# 5 A 60 6
6.2 agg
DataFrame.agg(func=None, axis=0, *args, **kwargs)
功能:用于对数据进行聚合操作
参数:func:可以是一个函数、函数列表或函数字典。用于指定聚合操作。
axis:0,表示按行聚合;如果设置为 1,则按列聚合。
import numpy as np
import pandas as pd
data = {
'Value1': [10, 20, 30, 40, 50, 60, 70, 80],
'Value2': [1, 2, 3, 4, 5, 6, 7, 8]
}
df = pd.DataFrame(data)
print(df)
# Value1 Value2
# 0 10 1
# 1 20 2
# 2 30 3
# 3 40 4
# 4 50 5
# 5 60 6
# 6 70 7
# 7 80 8
ret1 = df.agg([sum, np.mean, min])
print(ret1)
# Value1 Value2
# sum 360.0 36.0
# mean 45.0 4.5
# min 10.0 1.0
ret2 = df.agg({'Value1': [sum, np.mean], 'Value2': min})
print(ret2)
# Value1 Value2
# sum 360.0 NaN
# mean 45.0 NaN
# min NaN 1.0
7 数据可视化
用于绘制 DataFrame 数据图形,它允许用户直接从 DataFrame 创建各种类型的图表,而不需要使用其他绘图库(底层实际上使用了 Matplotlib)。
7.1 plot
DataFrame.plot(*args, **kwargs)
功能:绘制各种线图
参数:kind: 图表类型,可以是以下之一:
'line': 折线图(默认)
'bar': 柱状图
'barh': 水平柱状图
'hist': 直方图
'box': 箱线图
'kde': 核密度估计图
'area': 面积图
'pie': 饼图
'scatter': 散点图
'hexbin': 六边形箱图
x:指定X轴数据(列名或索引)
y:指定y轴数据(列名或列名列表)
ax: Matplotlib 子图对象
subplots:是否绘制子图,True绘制子图
figsize: 图表的尺寸,格式为 `(width, height)`,单位为英寸。
use_index: 是否使用 pandas 的索引作为 x 轴标签。默认为 `True`。
title: 图表的标题。
grid: 是否显示网格线。默认为 `False`。
legend: 是否显示图例。默认为 `True`。
xticks: x 轴的刻度位置。
yticks: y 轴的刻度位置。
xlim: x 轴的范围,格式为 `(min, max)`。
ylim: y 轴的范围,格式为 `(min, max)`。
color: 绘制颜色,可以是单个颜色或颜色列表。
label: 图例标签。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
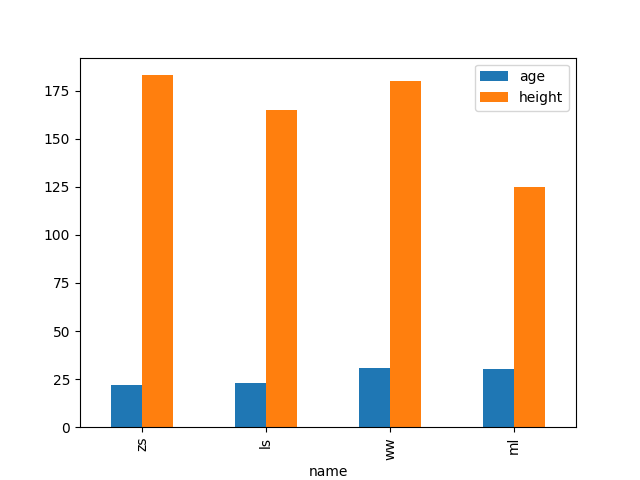
data = {'name': ['zs', 'ls', 'ww', 'ml'],
'age': [22, 23, 31, 30],
'height': [183, 165, 180, 125]
}
df = pd.DataFrame(data)
print(df)
# name age height
# 0 zs 22 183
# 1 ls 23 165
# 2 ww 31 180
# 3 ml 30 125
# 柱状图
df.plot(kind='bar', x="name") # 图表直接规定x轴y轴
plt.show()
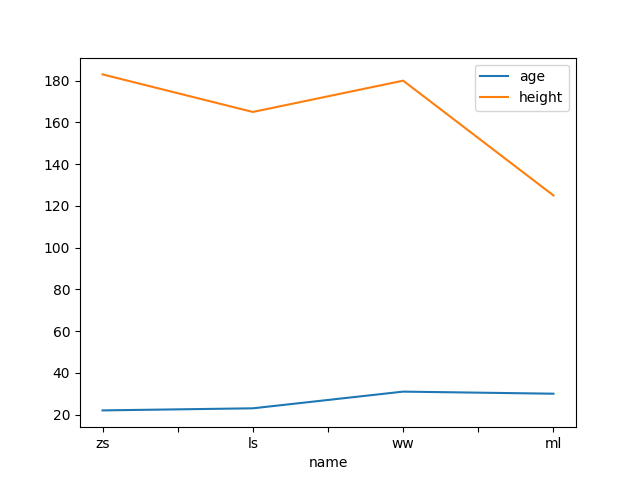
# 折线图
df.plot(kind='line', x="name")
plt.show()
8 文件的读写
pandas.read_csv(filepath, sep=',', header='infer', usecols=None,...)
功能:读取csv类型的文件
参数:filepath:读取的文件名
sep:字段分隔符,默认为逗号
header:指定第一行作为列名,默认为0(第一行)
usecols:返回一个数据子集,需要读取的列
pandas.read_excel(filepath, sheet_name=0, header=0, usecols=None, ...)
功能:读取execl类型文件
参数:sheet_name:工作表名称或索引,默认为0(第一个工作表)
其他同上
DataFrame.to_csv(path=None, sep=',', columns=None, index=True, ...)
功能:将DataFrame写入csv类型的文件
参数:columns:要写入的列名列表
index:是否写行(索引)名称。默认为True。
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', ...)
功能:将DataFrame写入excel类型的文件
参数:columns:要写入的列名列表
index:是否写行(索引)名称。默认为True。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df1 = pd.read_csv(r'C:\Users\learn_pandas.csv',
usecols=['School', "Height"]) # 另一种绝对路径方式:去掉r,每个反斜杠\再加一个\:\\
print(df1)
# 读csv文件
df2 = pd.read_csv('./learn_pandas.csv', usecols=['School', "Height"])
print(df2)
# 读excel文件
df3 = pd.read_excel('./item.xlsx', usecols=['user-info', 'order-info'])
print(df3)
# 写excel文件
df3.to_excel('test.xlsx')
print()
读取excel文件后,读取里面的数据,新建一个新的excel文件:test.xlsx

















 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









