






scrapy简介
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等。
本文简单的叙述了如何使用scrapy,设计并运行一个简单的案例,以及scrapy框架的各个部分的功能和作用,方便大家使用拓展。并对scrapy有一个完整的认识。
在使用scrapy框架之前,最好已经掌握基本的requests爬取方法,以及xpath、BS、css、正则表达式等解析方法的一种。
scrapy爬虫整体框架
以下是使用scrapy爬虫框架建立并运行爬虫项目的整个流程,之后会使用一个案例,按照这个流程来实现一个简单的操作。
第一,更改目录,改成要建立爬虫工程的文件目录,创建爬虫。
-- cd pycodes (创建一个目录,存放工程文件)
-- scrapy startproject python123demo (创建工程,工程名称)
-- cd python123demo (转移到工程目录中)
-- scrapy genspider demo python123.io (生成一个爬虫,叫demo,最后一个为域名,只能爬取这个域名一下的相关链接)
第二,修改demo的代码,完善爬虫的功能,配置爬虫文件。和常规爬虫的代码类似。
--sitting相关配置,
-- ROBOTSTXT = FALSE
-- 任意位置加上:LOG_LEVEL = 'ERROR'
-- 改use-agent: 复制粘贴,该游览器代理
-- 开启管道,可以多通道处理: 'taobao.pipelines.TaobaoPipeline': 300,数值表示的是优先级,数值越小,优先级越高
--parse解析response
-- 直接使用response.xpath()方法,xpath语法和正常的一样处理
-- xpath返回的是列表,列表元素是selector类型,使用'.extract()'方法转换成字符串,列表则是转换每一个列表元素转换成字符串,还有extract_first()方法
-- 使用content= ''.join(content),用空白字符连接content中的元素,实现一个链接的功能。
--item,每次yield item就会调用一次item类
-- spider中导入item类
-- items创建管道: # name = scrapy.Field()
-- 在parse中引入管道:
-- item = Python1Item()
-- 把数据提交给item: item['title'] = a.xpath('p/text()').extract()
-- 将item提交给管道:
-- yield item
--pipelines操作:持久化处理,多个管道类似操作,新建一个管道类,打开文件一次,写入N次,关闭一次:
-- 初始有一个process_item方法,用来处理item对象
-- 承接item对象的数据: movie = item['movie']
-- 打开操作:
-- 重写一个父类的方法,只会被爬虫调用一次:
-- def open_spider(self,spider):
-- 关闭文件操作:
-- 重写一个父类方法:
-- def close_spider(self,spider):
整体的流程图如下所示(官网):
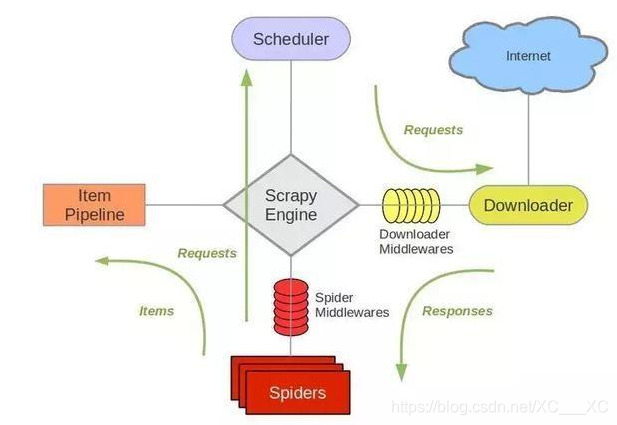
第三,运行爬虫:scrapy crawl demo(这个为爬虫的名字)
图片爬取案例
本文使用pycharm编辑器,scrapy框架实现图片的爬取,关于scrapy框架的安装,之后会进行补充,没有其他特殊的第三方库。
- 1.1 新建项目
打开pycharm,在Terminal中,在指定的工作目录下建立爬虫项目:
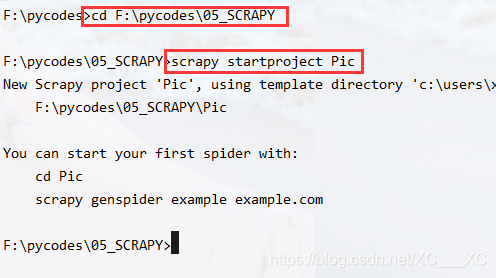
cd path #转到某个path下
scrapy startproject Pic #在该path下新建一个爬虫项目,名称叫做Pic
然后再工作目录下,就可以看到生成的Pic文件夹,里面包含了一些配置文件,文件的具体作用和功能之后会详细描述:
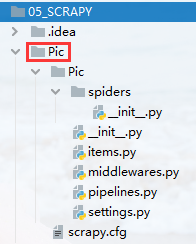
这样,第一步就完成了。
- 1.2 生成爬虫文件
先转到spider文件夹中,再生成spider文件:
cd Pic #转到Pic文件夹中
scrapy genspider download baodu.com #生成spider,名称为:download,爬取的域名为:baidu.com
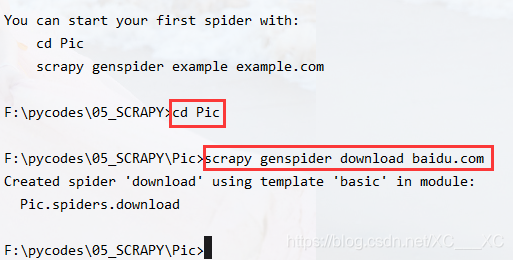
上面两个操作,scrapy也给出了提示:you can start your first spider with…,可以在工作目录下看到新建的download.py文件。
这样已经完成了项目的建立和spider文件的建立,接下来就是修改相关的配置文件,达到我们的目的。
- 1.3 修改spider
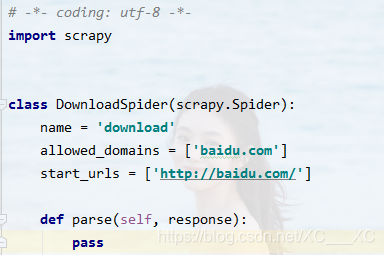
初始的download.py是这样的,我们要修改相关的参数,并解析网页,获取图片,并传递给item。
删去allowed_domains,允许域名表示我们只能在该域名下爬取,为了取消限制,故删去。
以彼岸图网为例,把start_urls改成https://pic.netbian.com/,然后写parse,获取图片。解析图片和常规的requests相同,在此不做详细介绍。
- 2.1 修改配置文件
在Pic文件夹中,有setting、item、pipeline、middleware、init五个文件。

















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









