







 本文深入探讨PyTorch中的张量概念,包括张量的创建、类型转换、设备间转换及常见操作,如初始化、数学运算等。通过实例演示张量如何在CPU和GPU间迁移,以及与NumPy数组的互转。
本文深入探讨PyTorch中的张量概念,包括张量的创建、类型转换、设备间转换及常见操作,如初始化、数学运算等。通过实例演示张量如何在CPU和GPU间迁移,以及与NumPy数组的互转。
PyTorch 基础 : 张量
# 首先要引入相关的包
import torch
import numpy as np
#打印一下版本
print(torch.__version__)

张量(Tensor)
张量的英文是Tensor,它是PyTorch里面基础的运算单位,与Numpy的ndarray相同都表示的是一个多维的矩阵。
与ndarray的最大区别就是,PyTorch的Tensor可以在 GPU 上运行,而 numpy 的 ndarray 只能在 CPU 上运行,在GPU上运行大大加快了运算速度。
下面我们生成一个简单的张量
x = torch.rand(2, 3)
print(x)

以上生成了一个,2行3列的的矩阵,我们看一下他的大小:
# 可以使用与numpy相同的shape属性查看
print(x.shape)
# 也可以使用size()函数,返回的结果都是相同的
print(x.size())

张量(Tensor)是一个定义在一些向量空间和一些对偶空间的笛卡儿积上的多重线性映射,其坐标是|n|维空间内,有|n|个分量的一种量, 其中每个分量都是坐标的函数, 而在坐标变换时,这些分量也依照某些规则作线性变换。r称为该张量的秩或阶(与矩阵的秩和阶均无关系)。 (来自百度百科)
下面我们来生成一些多维的张量:
y = torch.rand(2, 3, 4, 5)
print(y.size())
print(y)

在同构的意义下,第零阶张量 (r = 0) 为标量 (Scalar),第一阶张量 (r = 1) 为向量 (Vector), 第二阶张量 (r = 2) 则成为矩阵 (Matrix),第三阶以上的统称为多维张量。
其中要特别注意的就是标量,我们先生成一个标量:
#我们直接使用现有数字生成
scalar =torch.tensor(3.1433223)
print(scalar)
#打印标量的大小
print(scalar.size())

对于标量,我们可以直接使用 .item() 从中取出其对应的python对象的数值
print(scalar.item())
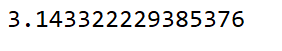
特别的:如果张量中只有一个元素的tensor也可以调用tensor.item方法
tensor = torch.tensor([3.1433223])
print(tensor)
print(tensor.size())

print(tensor.item())
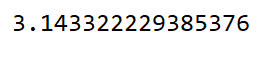
基本类型
Tensor的基本数据类型有五种:
- 32位浮点型:torch.FloatTensor。 (默认)
- 64位整型:torch.LongTensor。
- 32位整型:torch.IntTensor。
- 16位整型:torch.ShortTensor。
- 64位浮点型:torch.DoubleTensor。
除以上数字类型外,还有
byte和chart型
long = tensor.long()
print(long)
half=tensor.half()
print(half)
int_t=tensor.int()
print(int_t)
flo = tensor.float()
print(flo)
short = tensor.short()
print(short)
ch = tensor.char()
print(ch)
bt = tensor.byte()
print(bt)

Numpy转换
使用numpy方法将Tensor转为ndarray
a = torch.randn((3, 2))
# tensor转化为numpy
numpy_a = a.numpy()
print(numpy_a)

numpy转化为Tensor
torch_a = torch.from_numpy(numpy_a)
print(torch_a)

Tensor和numpy对象共享内存,所以他们之间的转换很快,而且几乎不会消耗什么资源。但这也意味着,如果其中一个变了,另外一个也会随之改变。
设备间转换
一般情况下可以使用.cuda方法将tensor移动到gpu,这步操作需要cuda设备支持
cpu_a=torch.rand(4, 3)
print(cpu_a.type())

gpu_a=cpu_a.cuda()
print(gpu_a.type())
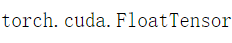
使用.cpu方法将tensor移动到cpu
cpu_b=gpu_a.cpu()
print(cpu_b.type())
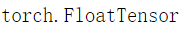
如果我们有多GPU的情况,可以使用to方法来确定使用那个设备,这里只做个简单的实例:
#使用torch.cuda.is_available()来确定是否有cuda设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
#将tensor传送到设备
gpu_b=cpu_b.to(device)
print(gpu_b.type())
初始化
Pytorch中有许多默认的初始化方法可以使用
rnd = torch.rand(5, 3)
print(rnd)

#初始化,使用1填充
one = torch.ones(2, 2)
print(one)
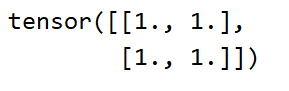
# 初始化,使用0填充
zero=torch.zeros(2,2)
print(zero)
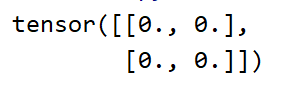
#初始化一个单位矩阵,即对角线为1 其他为0
eye=torch.eye(2,2)
print(eye)
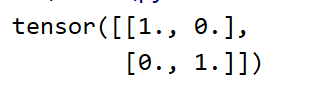
常用方法
PyTorch中对张量的操作api 和 NumPy 非常相似,如果熟悉 NumPy 中的操作,那么他们二者基本是一致的:
x = torch.randn(3, 3)
print(x)

x = torch.randn(3, 3)
print(x)
# 沿着行取最大值
max_value, max_idx = torch.max(x, dim=1)
print(max_value, max_idx)

x = torch.randn(3, 3)
print(x)
# 每行 x 求和
sum_x = torch.sum(x, dim=1)
print(sum_x)

x = torch.randn(3, 3)
print(x)
y = torch.randn(3, 3)
print(y)
z = x + y
print(z)

正如官方60分钟教程中所说,以_为结尾的,均会改变调用值
x = torch.randn(3, 3)
print(x)
y = torch.randn(3, 3)
print(y)
# add 完成后x的值改变了
x.add_(y)
print(x)

张量的基本操作都介绍的的差不多了,下一章介绍PyTorch的自动求导机制

















 504
504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









