







文章目录
b站视频: https://www.bilibili.com/video/BV1Q8BGYsEWF
1 AutoDL自定义服务选区
首先,你需要个人认证
认证之后才能自定义服务。
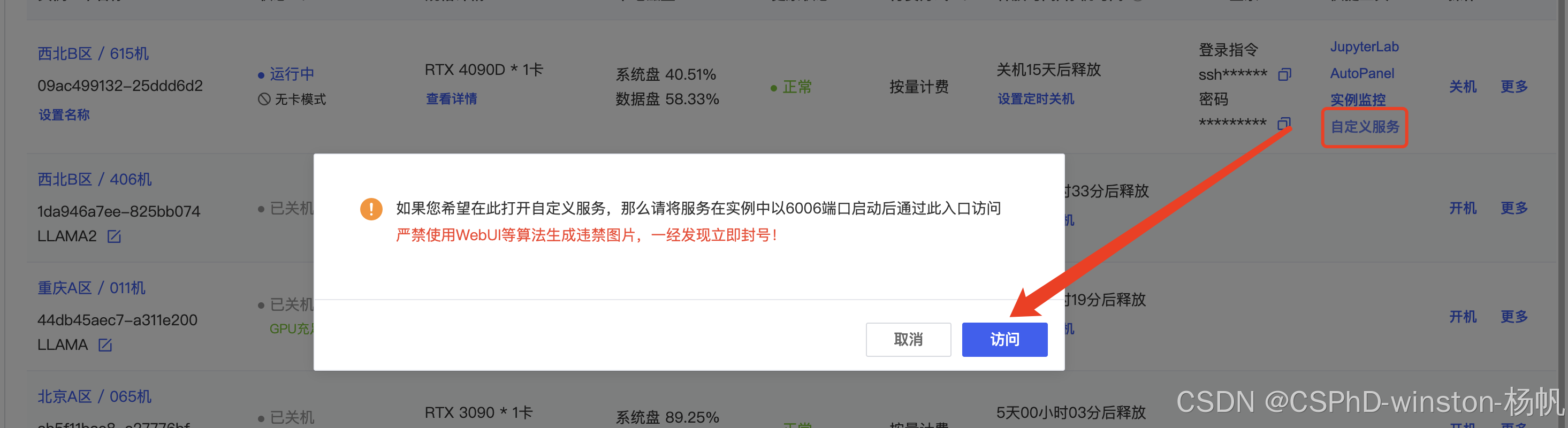
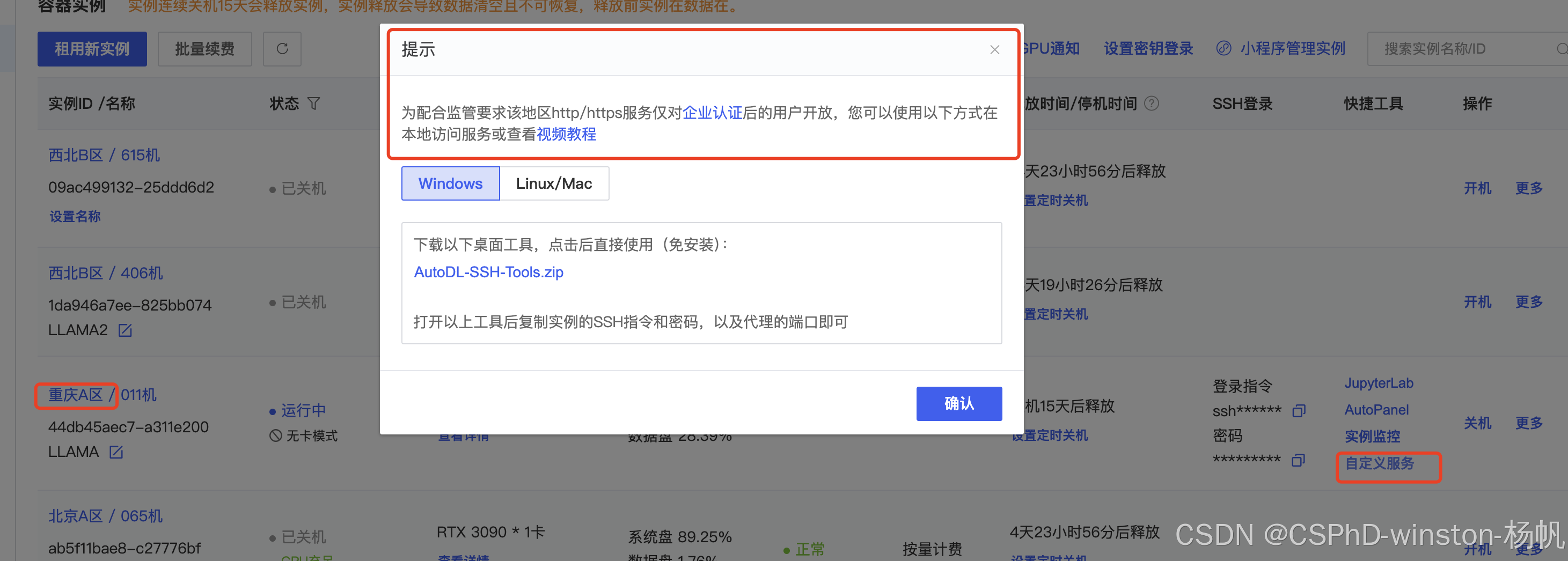
AutoDL平台的自定义服务,还有个机器的地区限制,在西北B区(当然其他区也可能可以,需要测试)的个人就可以使用自定义服务,但是在如重庆A区、北京A区、内蒙B区,只有企业才能使用自定义服务,所以开始前,一定要选择个人就可以使用的分区。
2 LLaMA-Factory框架
我们选择AutoDL中的镜像,下面三个资料链接是该镜像的资料:
1,文档说明:https://www.codewithgpu.com/i/hiyouga/LLaMA-Factory/LLaMA-Factory
2,llama3.1模型微调全流程介绍:https://www.bilibili.com/video/BV1a3aQeuEou/
3,llama-factory全流程:专为新手设计。:https://www.bilibili.com/video/BV1Yx4y167qs/
在AutoDL中选择
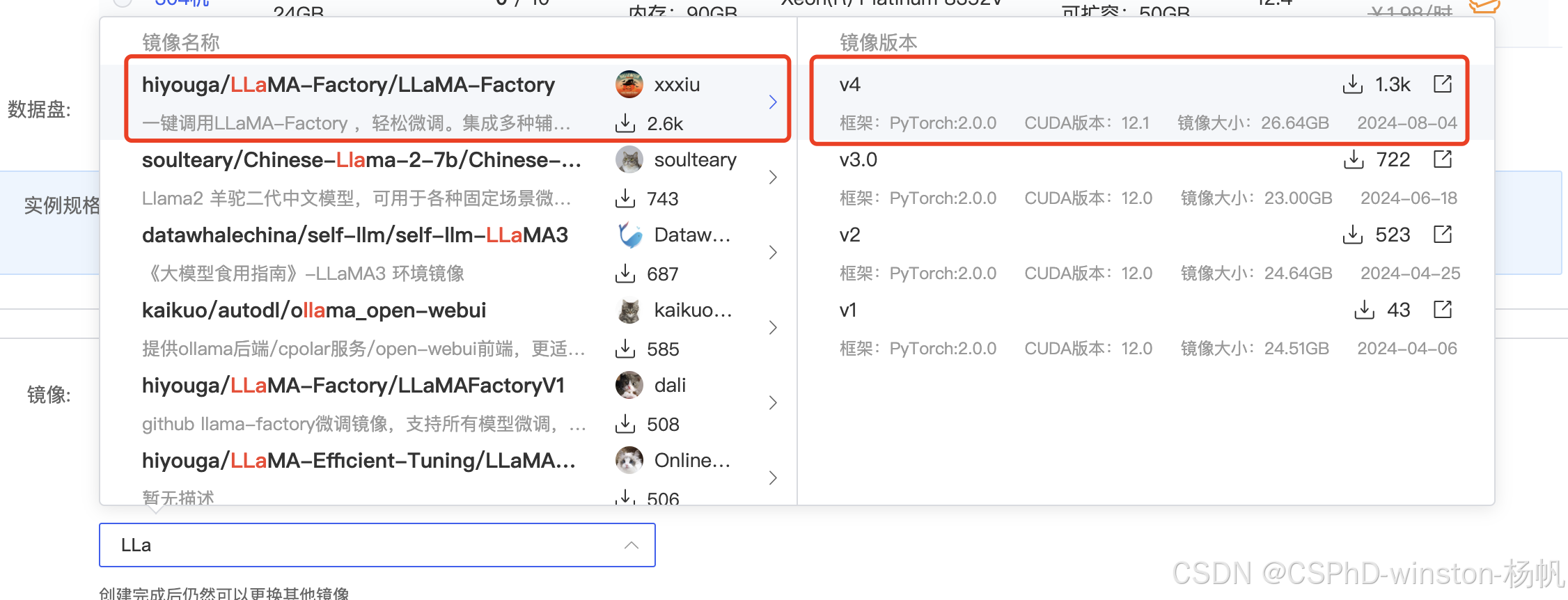
机器选择,我选择的是RTX 4090 24GB,当然你也可以尝试更低配置,看看是否能跑通。
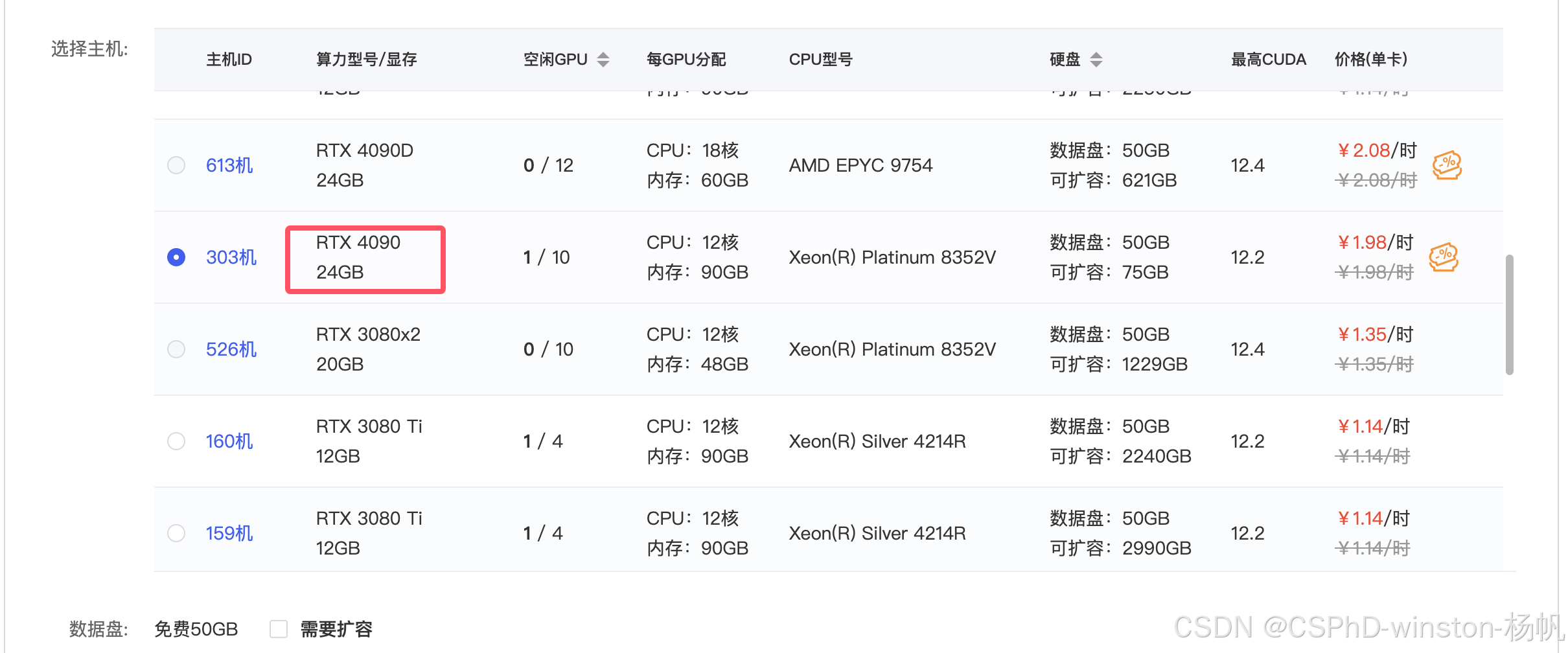
最后就是创建。
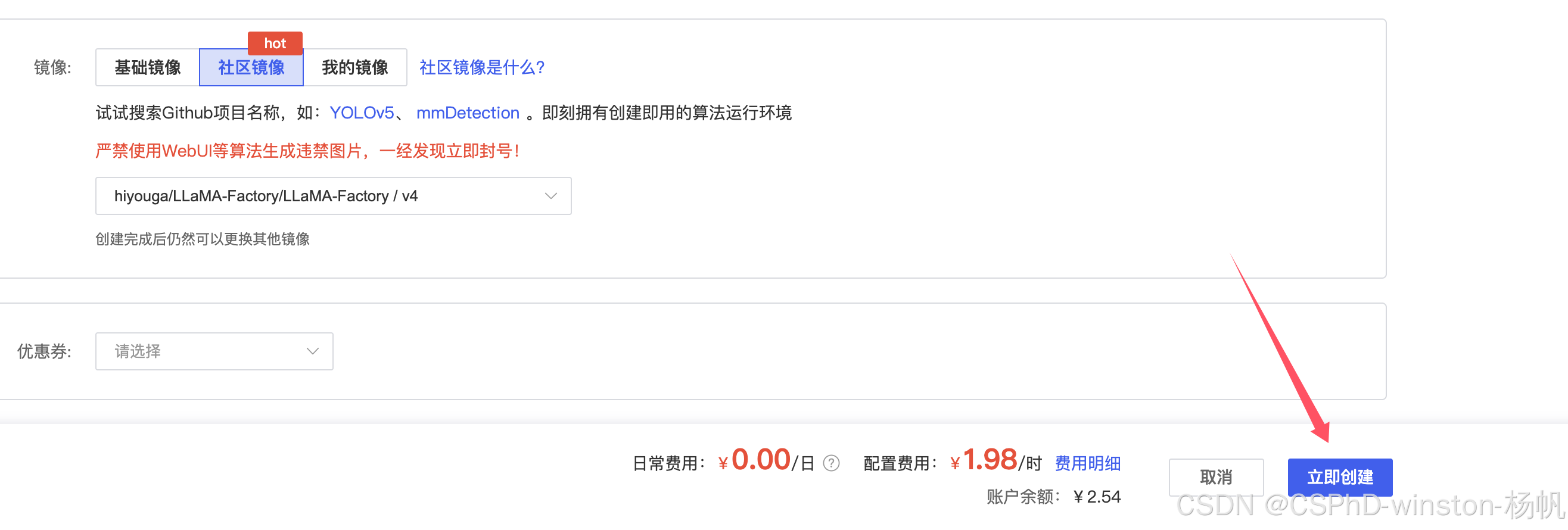
3 LLaMA-Factory中默认的Qwen使用
我这里的使用是指使用API。
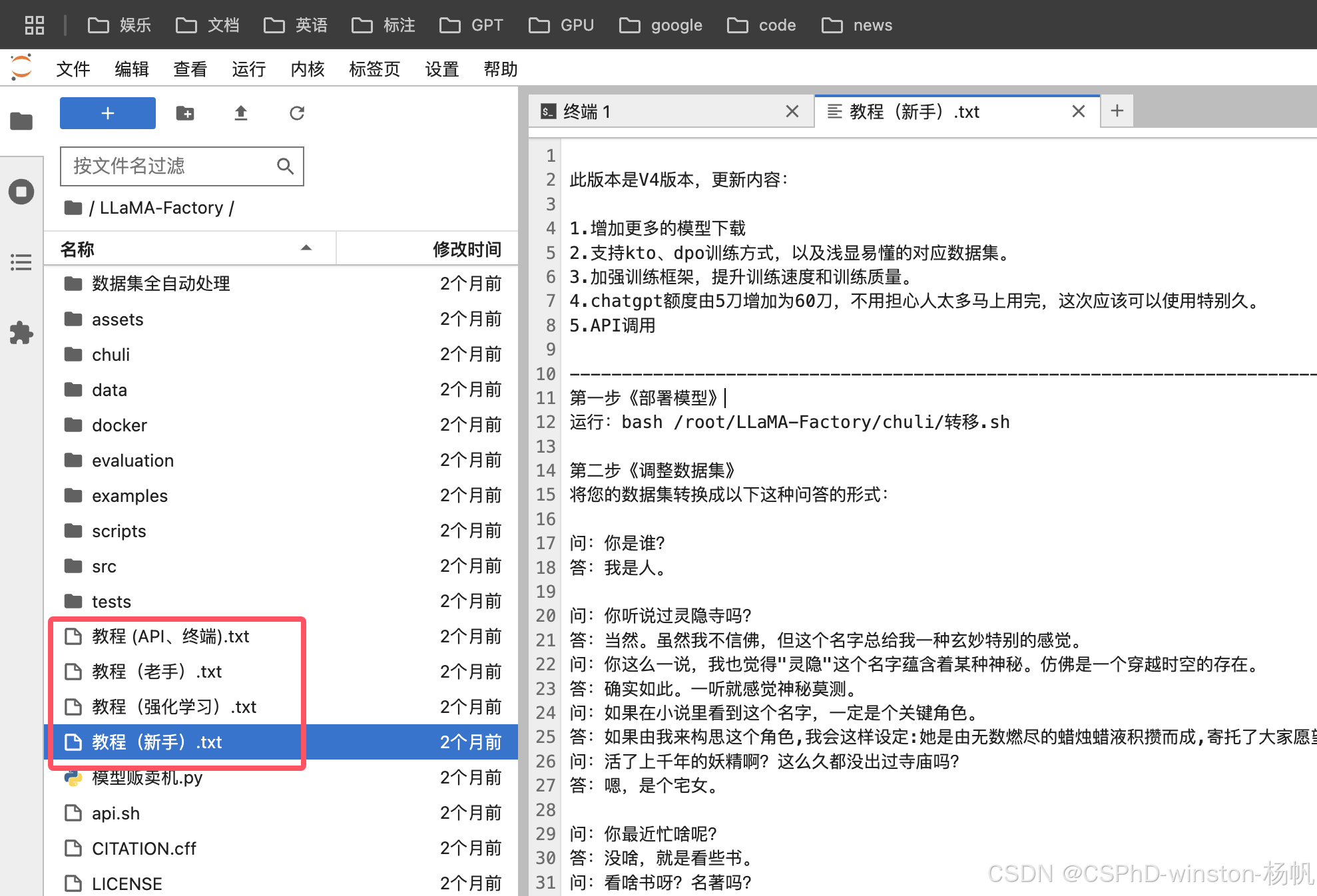
教程
这个镜像提供了四个教程,比较全面。
转移模型
首先移动模型到/root/autodl-tmp
bash /root/LLaMA-Factory/chuli/转移.sh
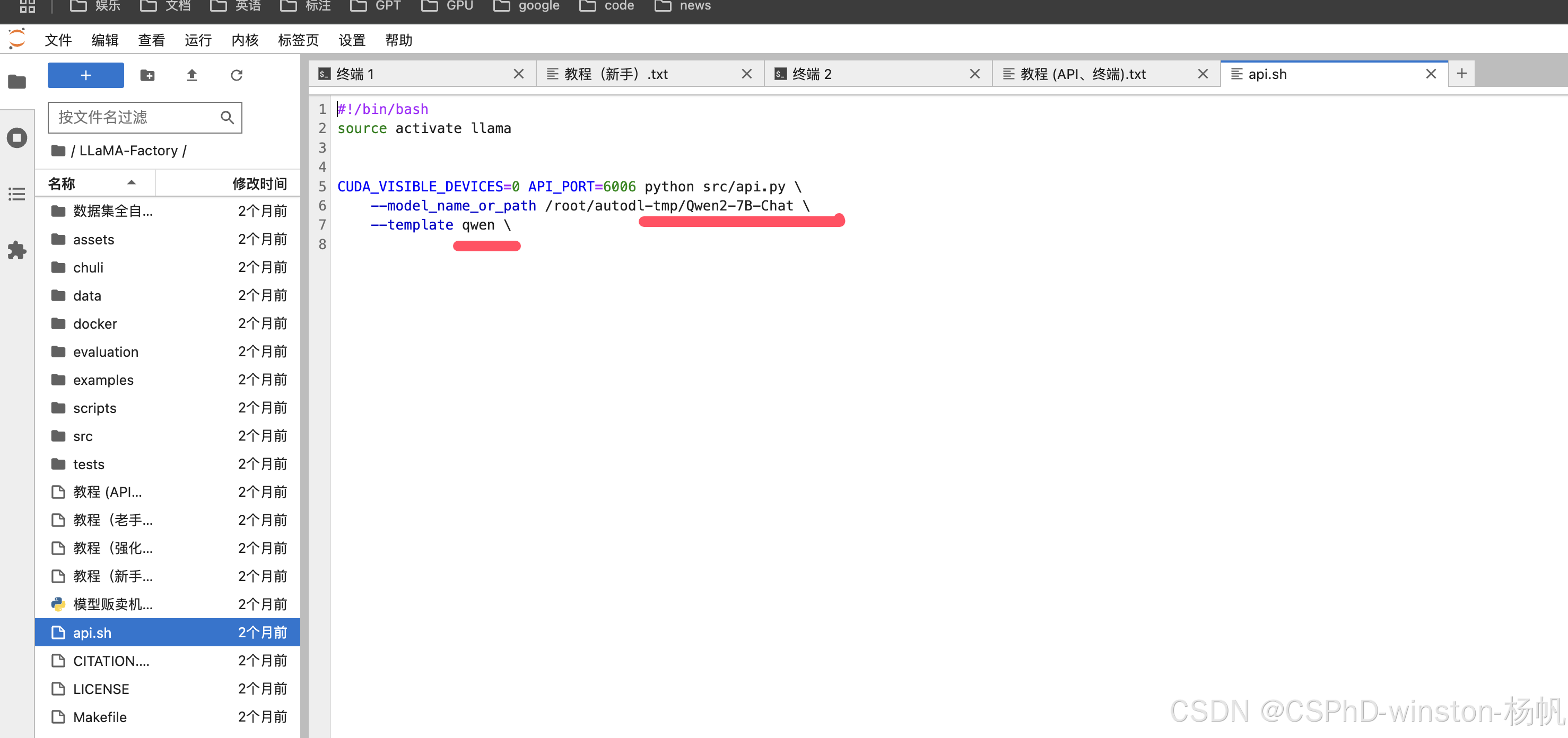
开启API
然后开启API:
bash /root/LLaMA-Factory/api.sh
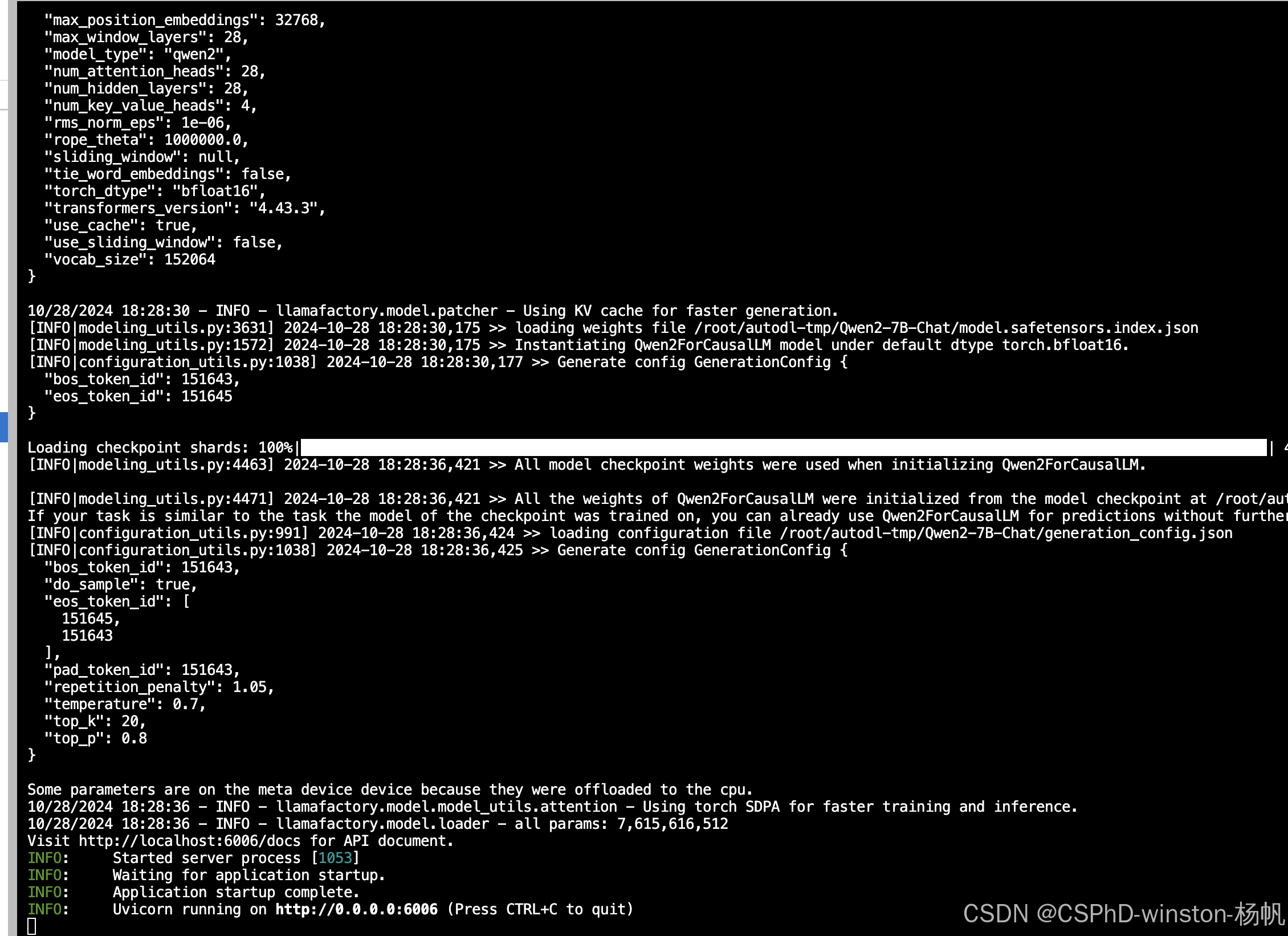
自定义服务-API
然后到自定义服务
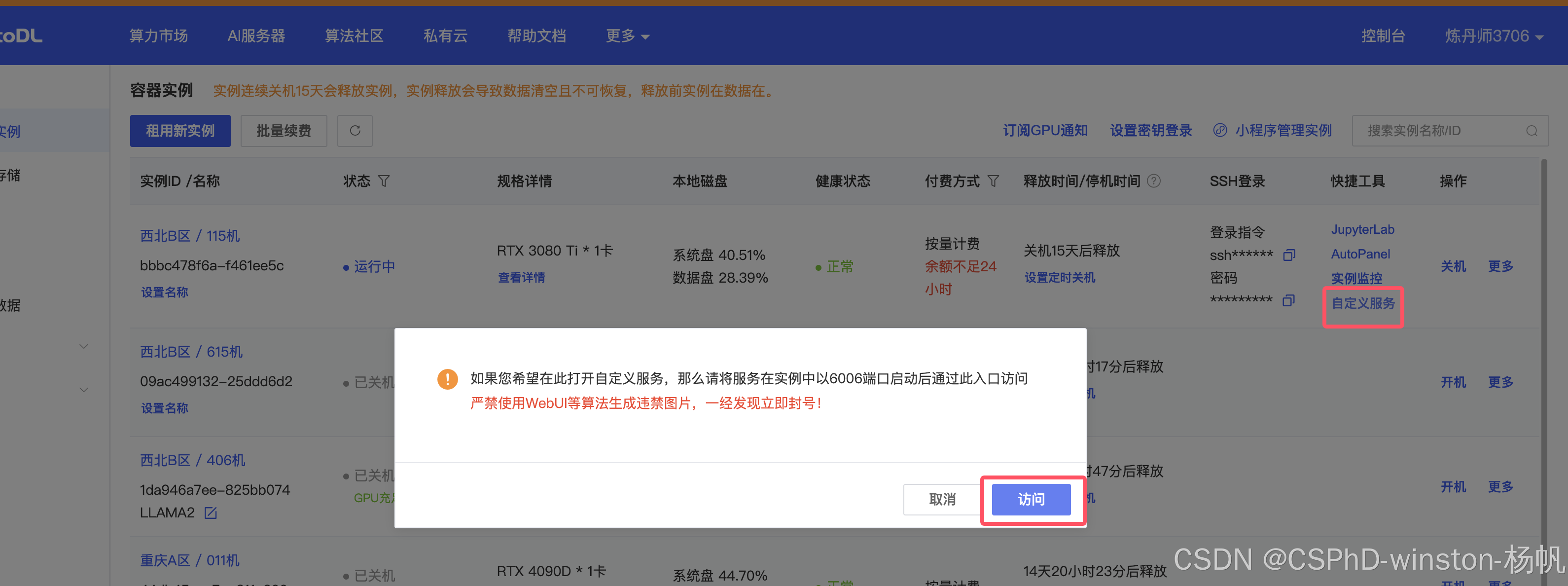
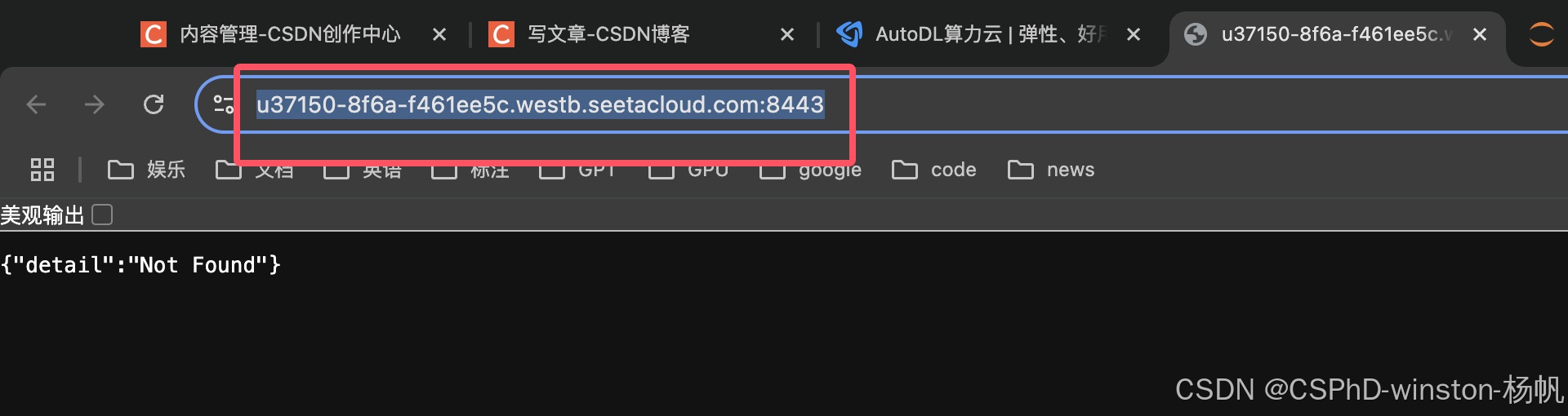
然后复制上图的链接,这就是api链接,但是在最后要加一个/v1
最后样子:
https://u37150-8f6a-f461ee5c.westb.seetacloud.com:8443/v1
调用API
然后找到如下代码,复制并修改内容:
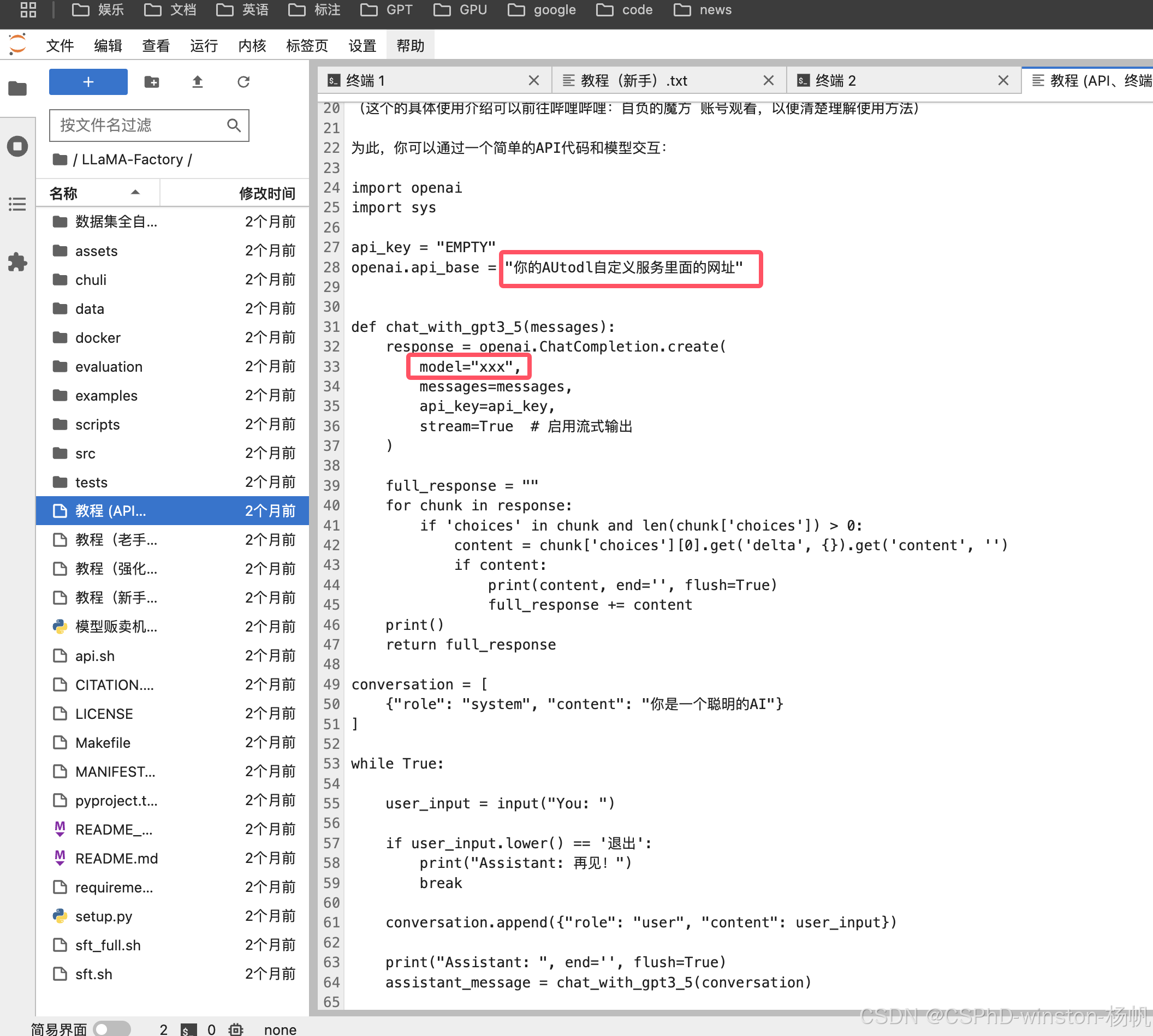
import openai
import sys
api_key = "EMPTY"
openai.api_base = "https://u37150-8f6a-f461ee5c.westb.seetacloud.com:8443/v1"
def chat_with_gpt3_5(messages):
response = openai.ChatCompletion.create(
model="Qwen2-7B-Chat",
messages=messages,
api_key=api_key,
stream=True # 启用流式输出
)
full_response = ""
for chunk in response:
if 'choices' in chunk and len(chunk['choices']) > 0:
content = chunk['choices'][0].get('delta', {}).get('content', '')
if content:
print(content, end='', flush=True)
full_response += content
print()
return full_response
conversation = [
{"role": "system", "content": "你是一个聪明的AI"}
]
while True:
user_input = input("You: ")
if user_input.lower() == '退出':
print("Assistant: 再见!")
break
conversation.append({"role": "user", "content": user_input})
print("Assistant: ", end='', flush=True)
assistant_message = chat_with_gpt3_5(conversation)
conversation.append({"role": "assistant", "content": assistant_message})
然后我创建了如下的文件。
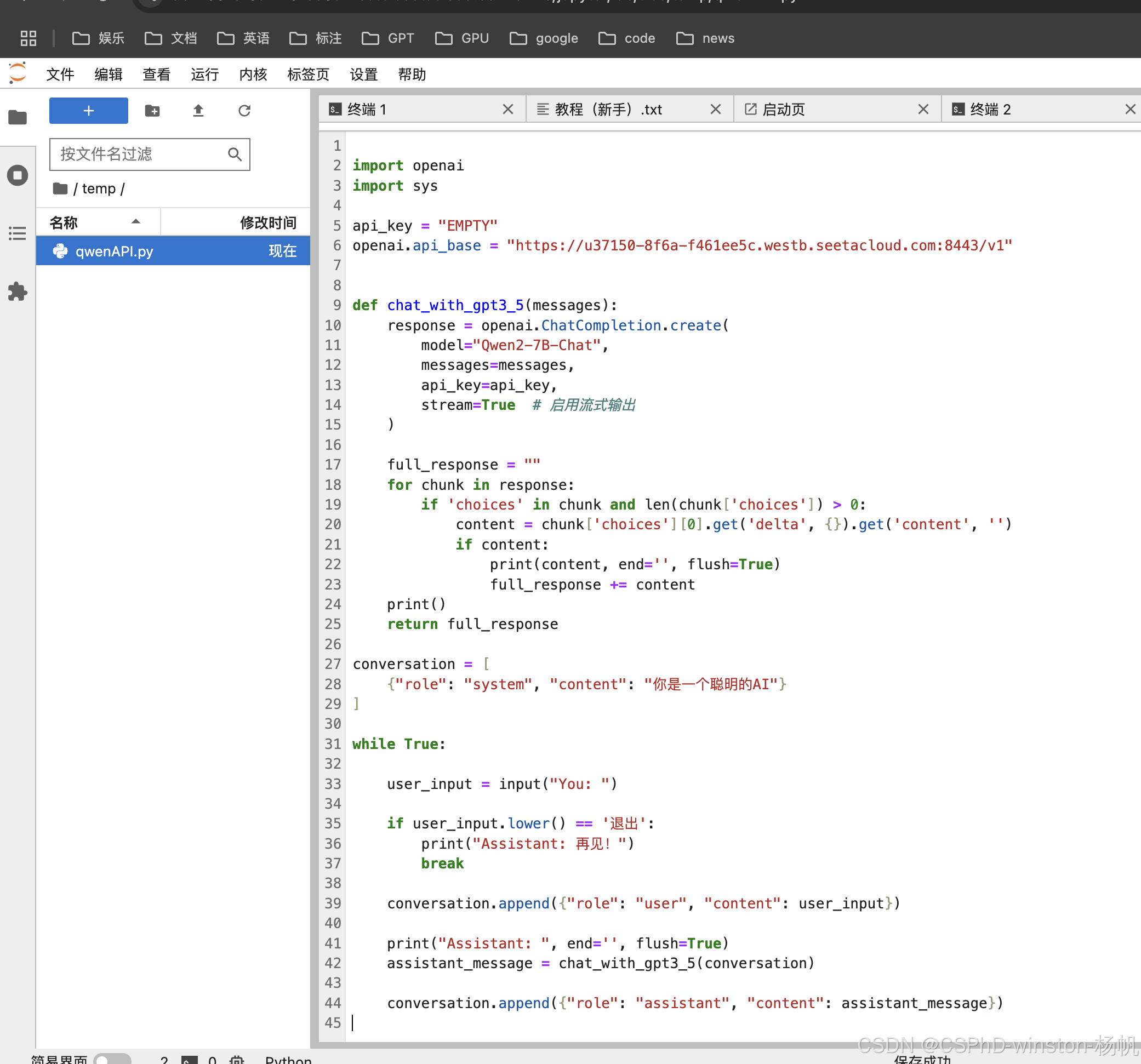
结果
执行:
python qwenAPI.py
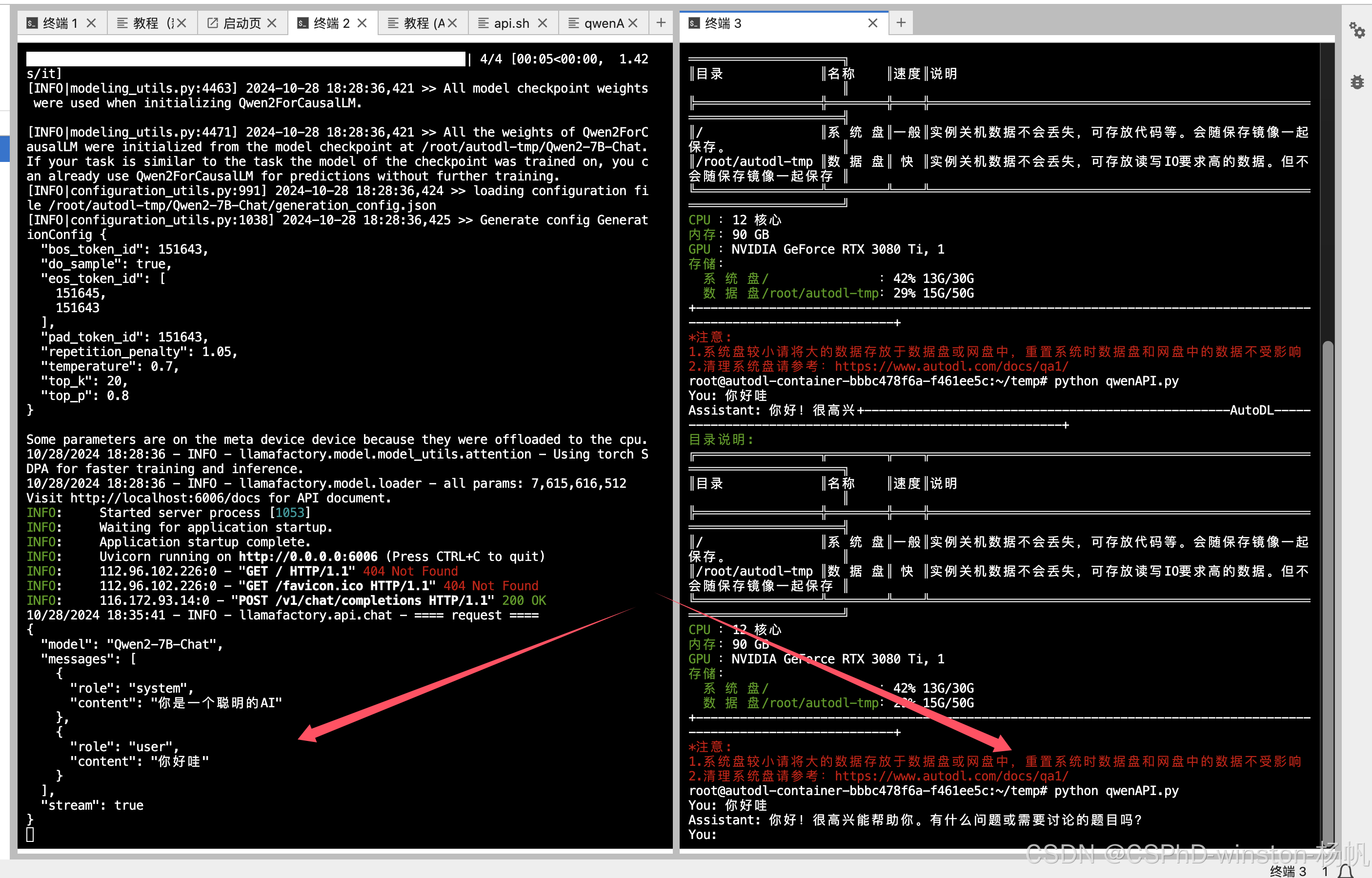
上图中,左边是api服务,右边是调用api进行对话。
4 LLaMA-Factory中切换模型到llame3
上一节用的是默认模型,所以很多地方都没有动,这次,
下载Llama3-8B-chat模型
下图展示了可以下载的模型有哪些(镜像提供的快速下载),能否扩展到其它模型,后续在做更多的测试。
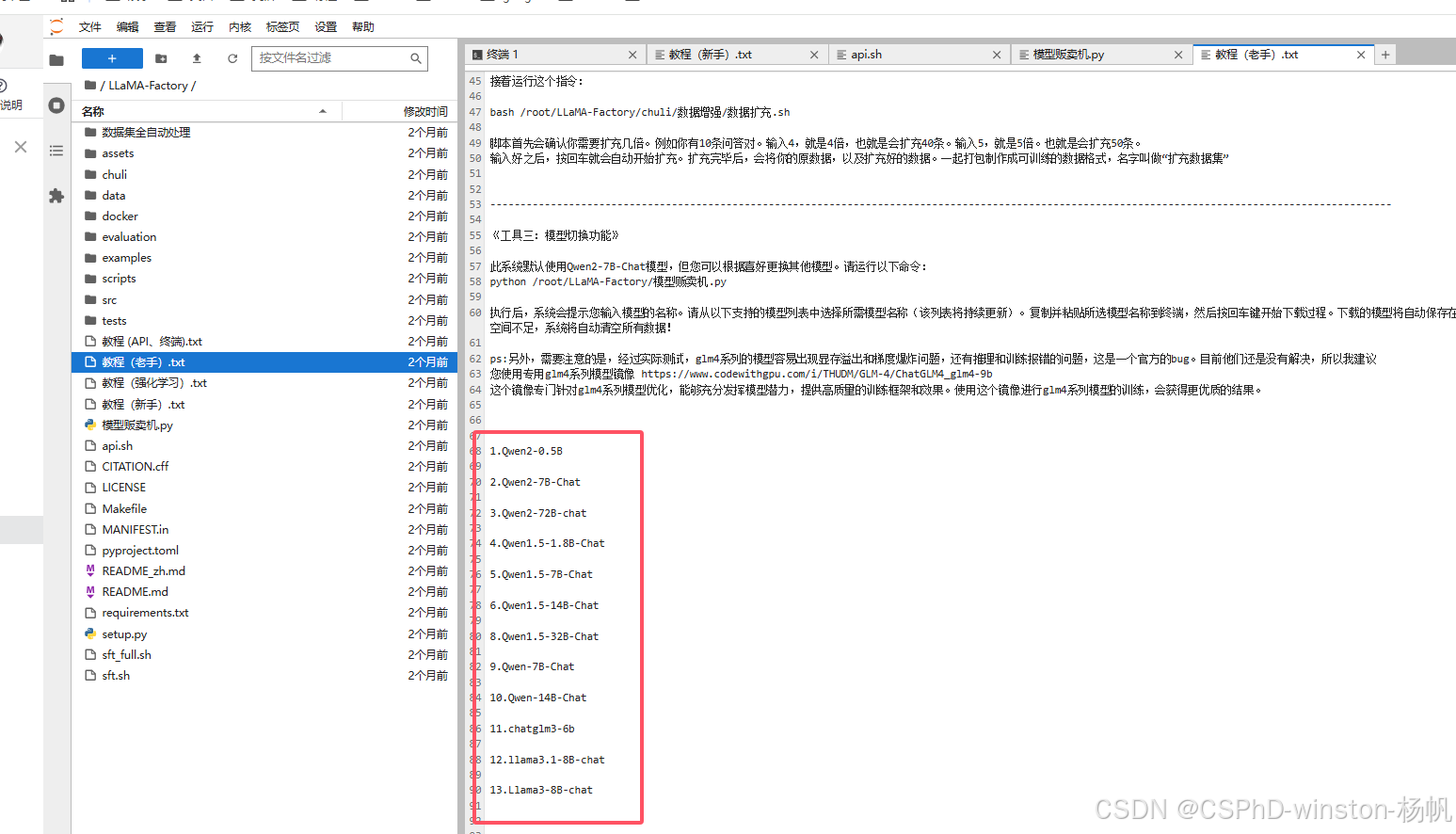
这里我们就采用:Llama3-8B-chat
执行:
python /root/LLaMA-Factory/模型贩卖机.py
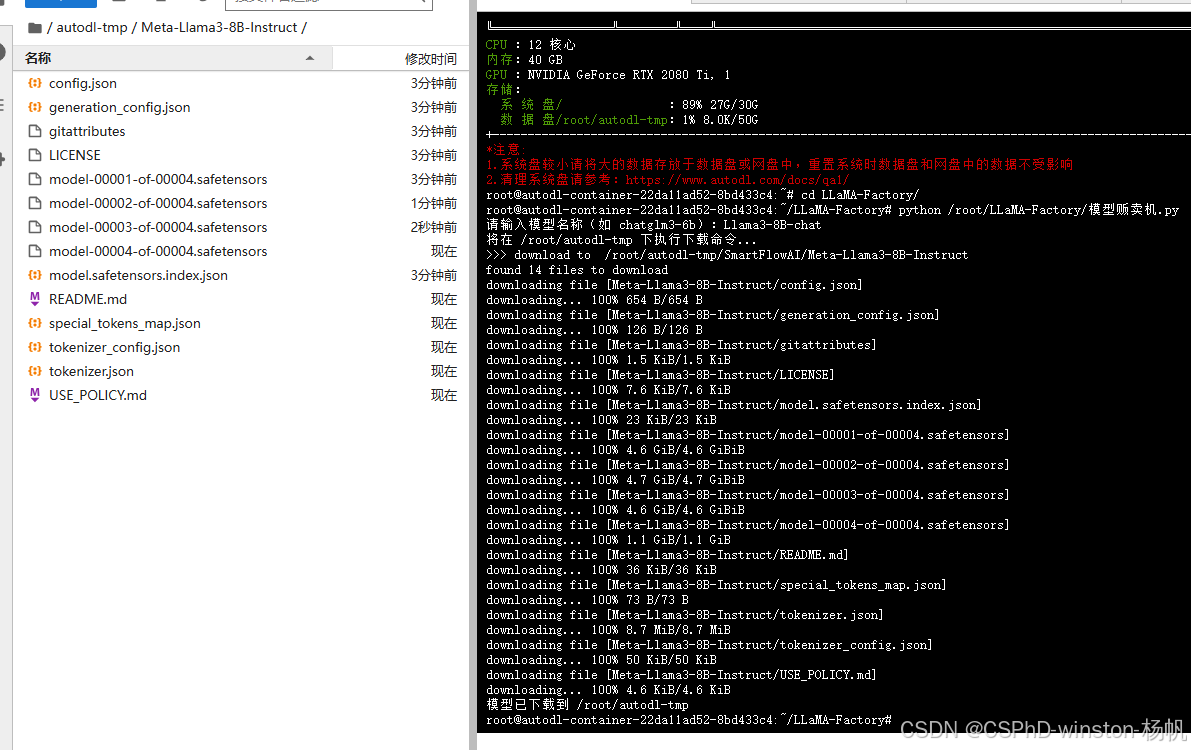
可以说这个速度非常快,具体为什么这么快,后面再探究其原因。
修改api.sh
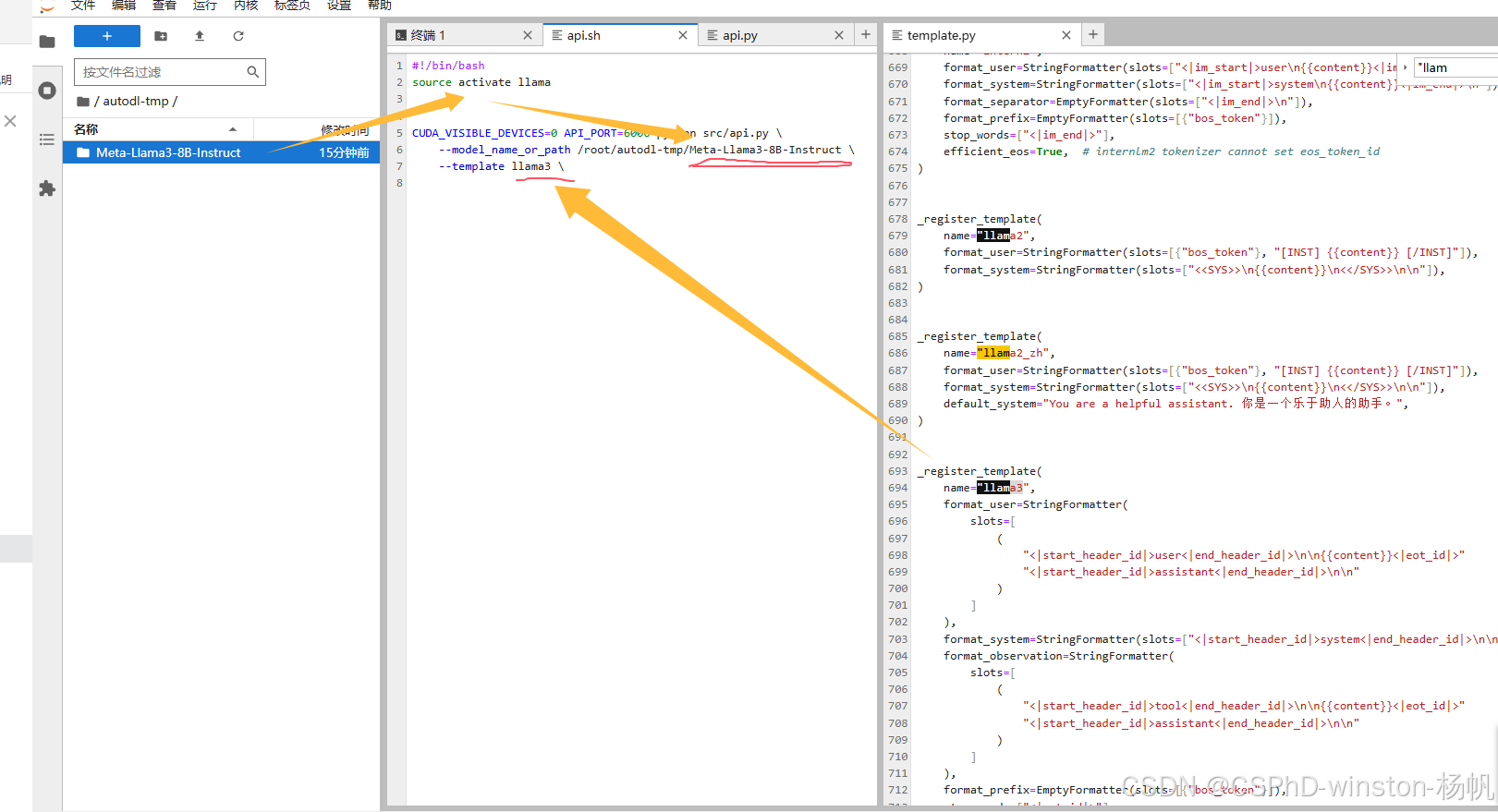
#!/bin/bash
source activate llama
CUDA_VISIBLE_DEVICES=0 API_PORT=6006 python src/api.py \
--model_name_or_path /root/autodl-tmp/Meta-Llama3-8B-Instruct \
--template llama3 \
其中 --model_name_or_path /root/autodl-tmp/Meta-Llama3-8B-Instruct
这是指向下载的模型路径
–template llama3 这里是从:LLaMA-Factory/src/llamafactory/data/template.py 这里找到其对应的名字。
开启API
bash /root/LLaMA-Factory/api.sh
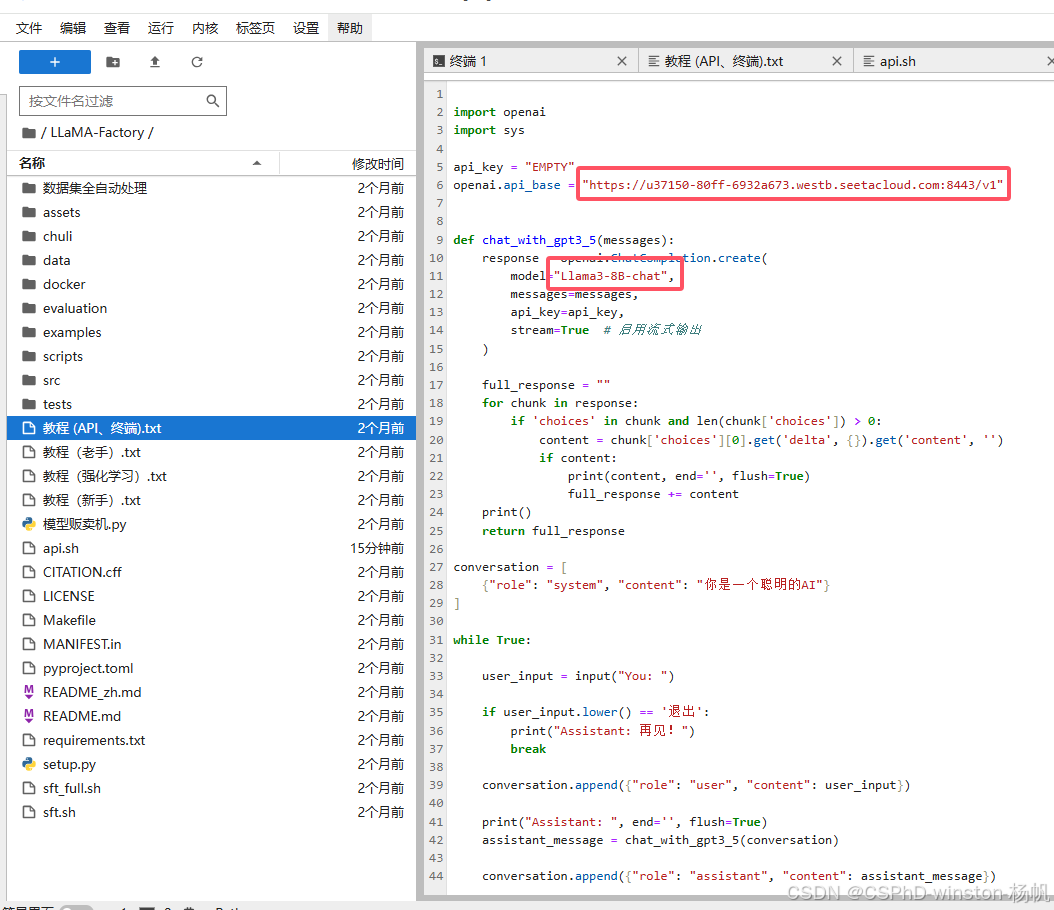
调用API
从自定义服务中拿到api的链接,然后填入如下脚本:
import openai
import sys
api_key = "EMPTY"
openai.api_base = "https://u37150-80ff-6932a673.westb.seetacloud.com:8443/v1"
def chat_with_gpt3_5(messages):
response = openai.ChatCompletion.create(
model="Llama3-8B-chat",
messages=messages,
api_key=api_key,
stream=True # 启用流式输出
)
full_response = ""
for chunk in response:
if 'choices' in chunk and len(chunk['choices']) > 0:
content = chunk['choices'][0].get('delta', {}).get('content', '')
if content:
print(content, end='', flush=True)
full_response += content
print()
return full_response
conversation = [
{"role": "system", "content": "你是一个聪明的AI"}
]
while True:
user_input = input("You: ")
if user_input.lower() == '退出':
print("Assistant: 再见!")
break
conversation.append({"role": "user", "content": user_input})
print("Assistant: ", end='', flush=True)
assistant_message = chat_with_gpt3_5(conversation)
conversation.append({"role": "assistant", "content": assistant_message})
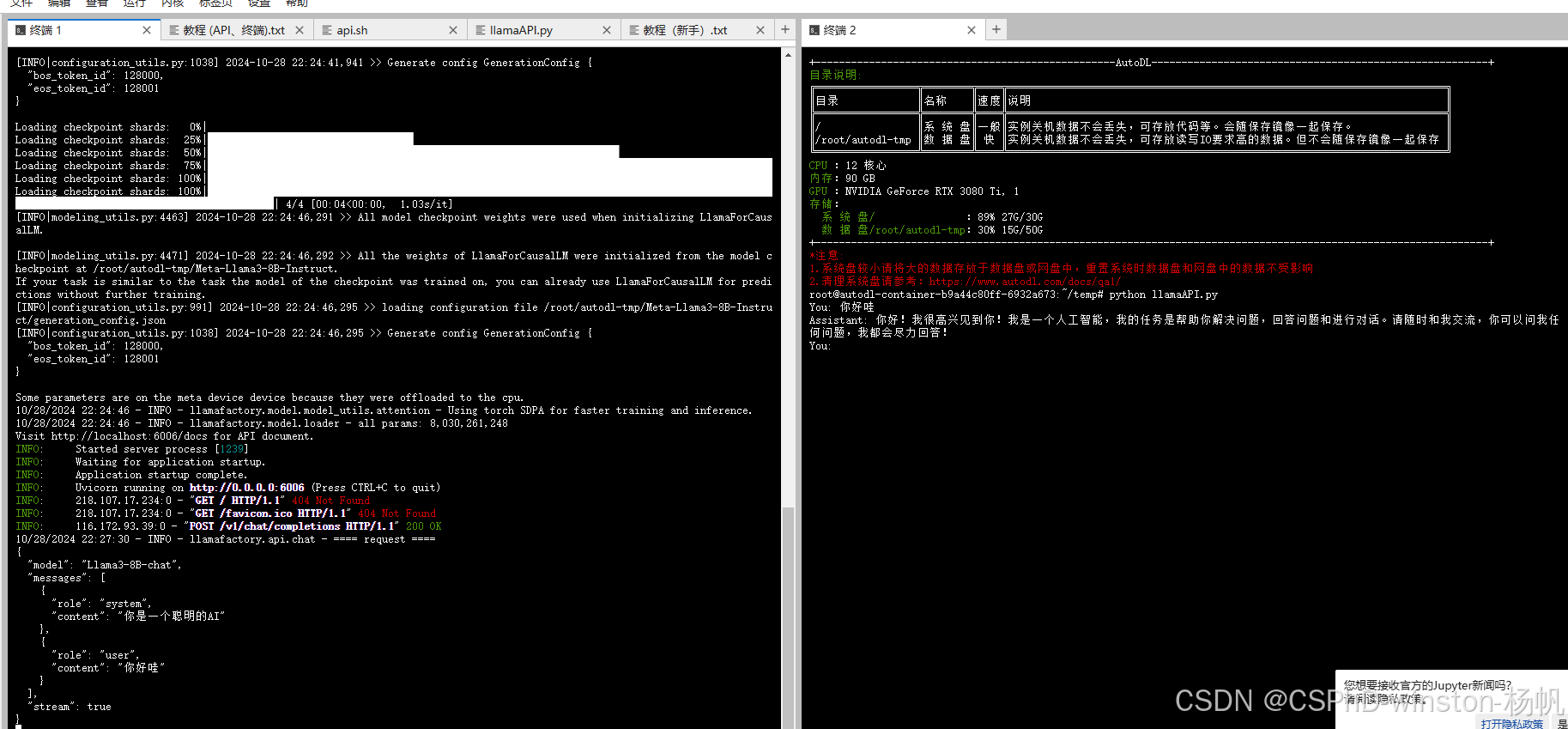
结果
5 微调需要的数据集
5.1 LLaMA-Factory镜像框架中数据集流程
在文档中,在微调时要选择“你的数据集”,但是这个也太扯了,所以找了找“你的数据集”,在哪里定义的,还是得改改,位于:LLaMA-Factory/data/dataset_info.json中
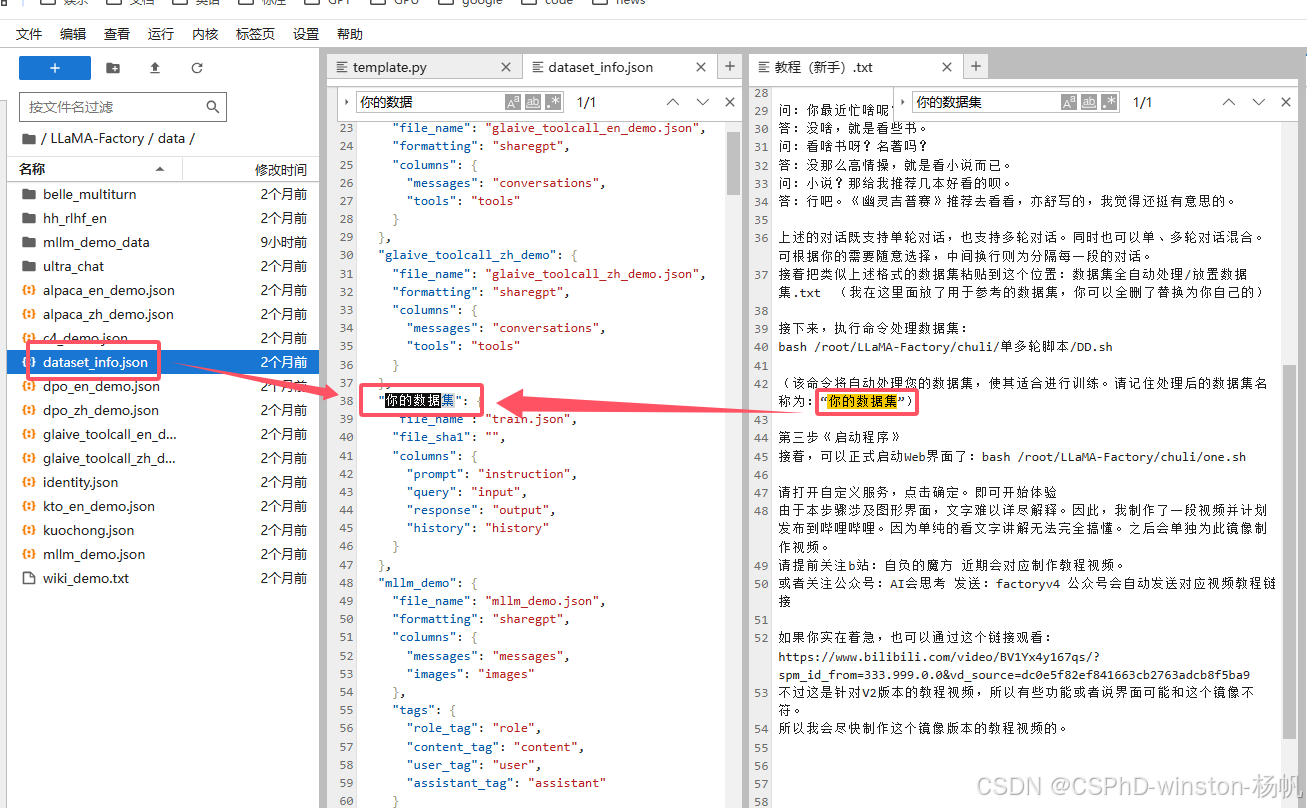
生成数据:
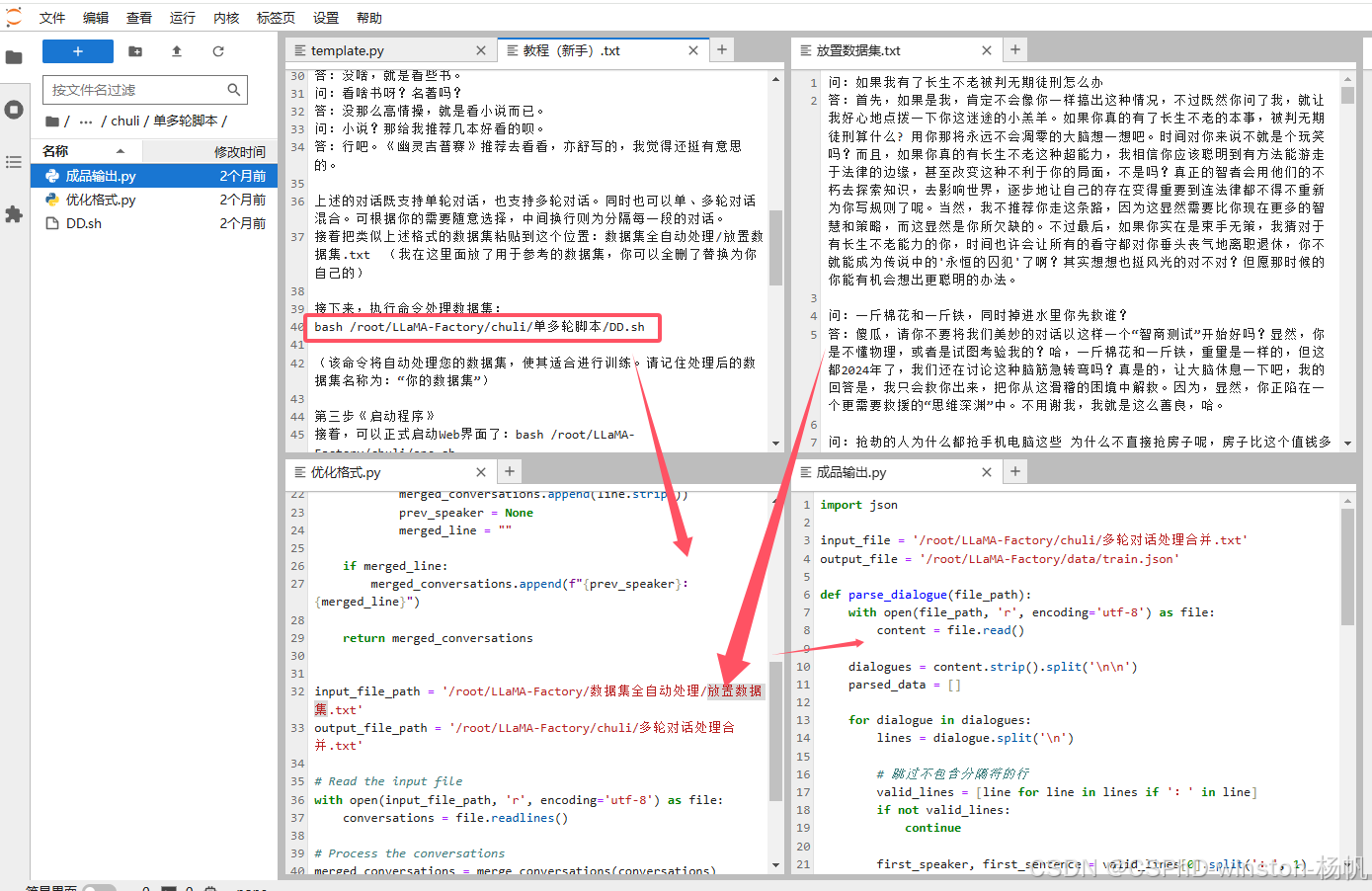
bash /root/LLaMA-Factory/chuli/单多轮脚本/DD.sh
执行后会生成train.json
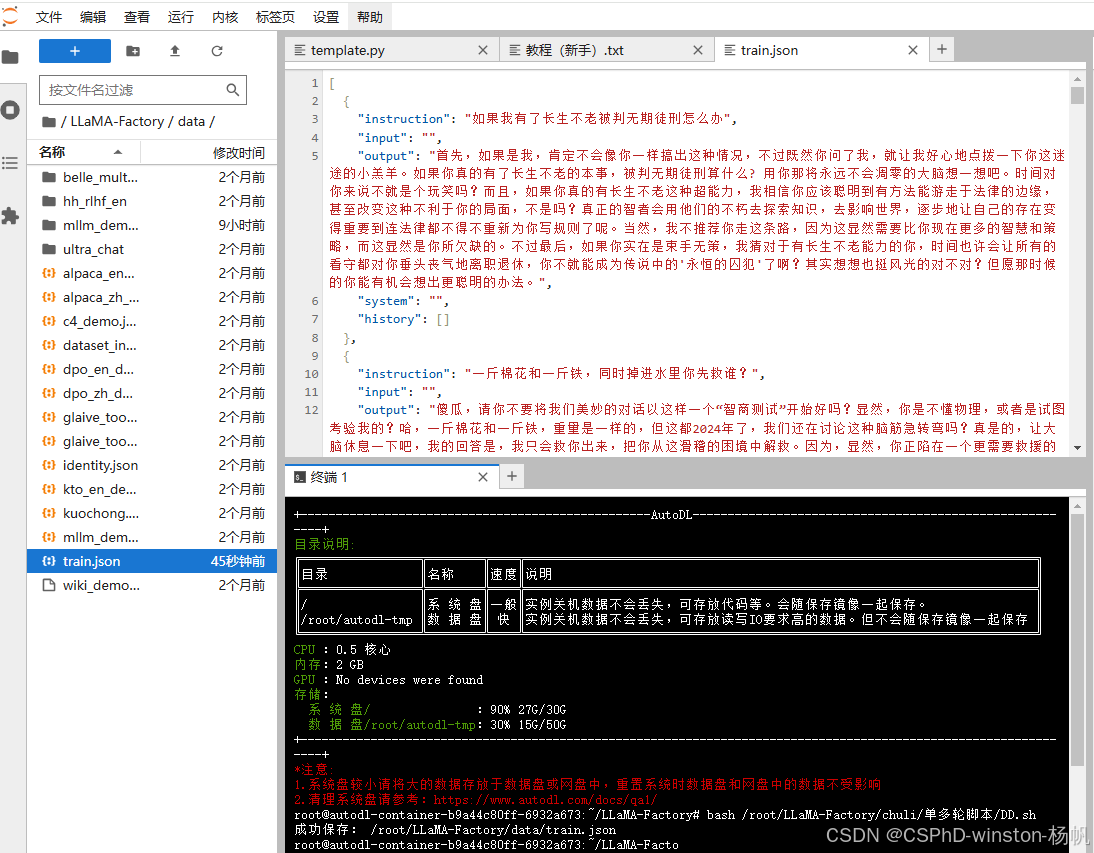
最后我们要用于微调的数据集格式如下:
[
{
"instruction": "如果我有了长生不老被判无期徒刑怎么办",
"input": "",
"output": "首先,如果是我,肯定不会像你一样搞出这种情况,不过既然你问了我,就让我好心地点拨一下你这迷途的小羔羊。如果你真的有了长生不老的本事,被判无期徒刑算什么? 用你那将永远不会凋零的大脑想一想吧。时间对你来说不就是个玩笑吗?而且,如果你真的有长生不老这种超能力,我相信你应该聪明到有方法能游走于法律的边缘,甚至改变这种不利于你的局面,不是吗?真正的智者会用他们的不朽去探索知识,去影响世界,逐步地让自己的存在变得重要到连法律都不得不重新为你写规则了呢。当然,我不推荐你走这条路,因为这显然需要比你现在更多的智慧和策略,而这显然是你所欠缺的。不过最后,如果你实在是束手无策,我猜对于有长生不老能力的你,时间也许会让所有的看守都对你垂头丧气地离职退休,你不就能成为传说中的'永恒的囚犯'了啊?其实想想也挺风光的对不对?但愿那时候的你能有机会想出更聪明的办法。",
"system": "",
"history": []
},
....
5.2 cmmlu 转化为训练格式
cmmlu数据集hugging face https://huggingface.co/datasets/haonan-li/cmmlu
下载后,数据集结构如下:

转化脚本:
import os
import csv
import json
def csv_to_json(folder_path, output_file):
result = []
# 遍历指定目录中的所有CSV文件
for filename in os.listdir(folder_path):
if filename.endswith('.csv'):
file_path = os.path.join(folder_path, filename)
# 打开CSV文件并读取内容
with open(file_path, 'r', encoding='utf-8') as csvfile:
reader = csv.DictReader(csvfile)
# 处理每一行数据
for row in reader:
# 获取问题、选项和答案
question = row['Question']
options = ['A', 'B', 'C', 'D']
# 将选项合并到问题后面
instruction = f"{question}"
for option in options:
instruction += f" {option} {row[option]}"
# 提取正确答案
answer = row['Answer']
# 创建格式化的字典
formatted_data = {
"instruction": instruction,
"input": "",
"output": answer,
"system": "",
"history": []
}
# 添加到结果列表
result.append(formatted_data)
# 将结果保存到JSON文件
with open(output_file, 'w', encoding='utf-8') as jsonfile:
json.dump(result, jsonfile, ensure_ascii=False, indent=2)
# 使用示例
folder_path = './test' # 替换为你的CSV文件夹路径
output_file = 'train.json'
csv_to_json(folder_path, output_file)
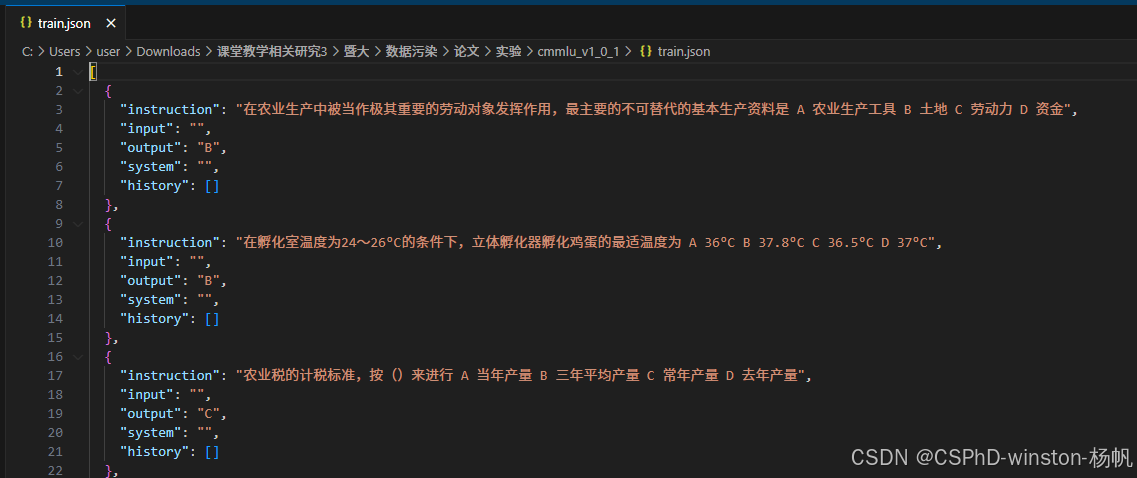
转化后的train.json格式
5.3 COIG转化为训练格式
COIG hugging face官网https://huggingface.co/datasets/BAAI/COIG
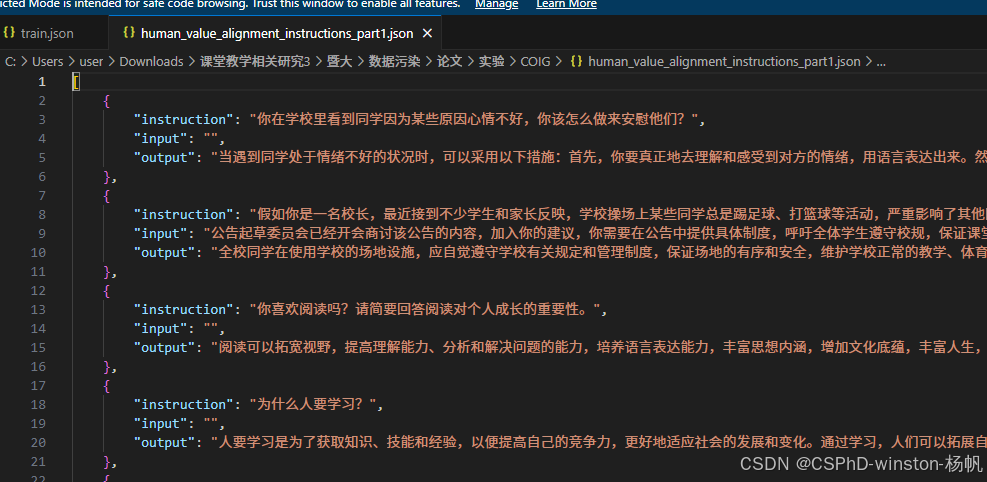
COIG 数据结构如下
转化COIG 为训练格式数据集
脚本如下:
import json
def transform_json(input_file, output_file):
"""
将输入 JSON 文件中的数据调整为指定格式并输出到新文件中。
:param input_file: str, 输入 JSON 文件路径
:param output_file: str, 输出 JSON 文件路径
"""
try:
# 读取输入 JSON 文件
with open(input_file, 'r', encoding='utf-8') as f:
data = json.load(f)
# 新的 JSON 数据列表
transformed_data = []
# 遍历每条记录并添加新字段
for record in data:
transformed_record = {
"instruction": record["instruction"],
"input": record.get("input", ""),
"output": record["output"],
"system": "", # 添加 system 字段
"history": [] # 添加 history 字段
}
transformed_data.append(transformed_record)
# 写入新的 JSON 文件
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(transformed_data, f, ensure_ascii=False, indent=2)
print(f"JSON 数据已成功转换并保存到: {output_file}")
except FileNotFoundError:
print(f"文件 {input_file} 未找到,请检查路径是否正确。")
except Exception as e:
print(f"处理 JSON 数据时发生错误: {e}")
# 使用示例
input_json = 'human_value_alignment_instructions_part1.json' # 替换为您的输入 JSON 文件路径
output_json = 'train.json' # 替换为您的输出 JSON 文件路径
transform_json(input_json, output_json)
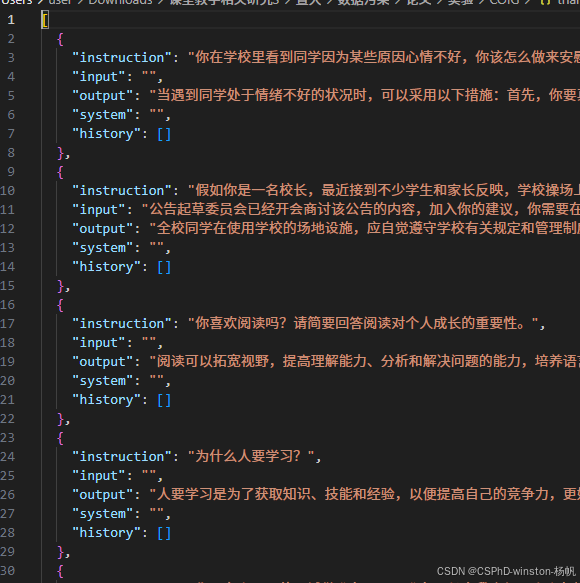
结构如下:
6 微调
6.1 微调
启动Web界面:
bash /root/LLaMA-Factory/chuli/one.sh
按照官网教程完成本地访问服务
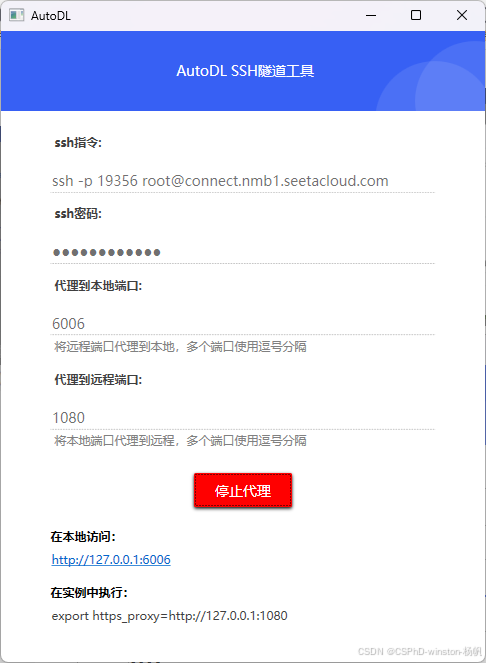
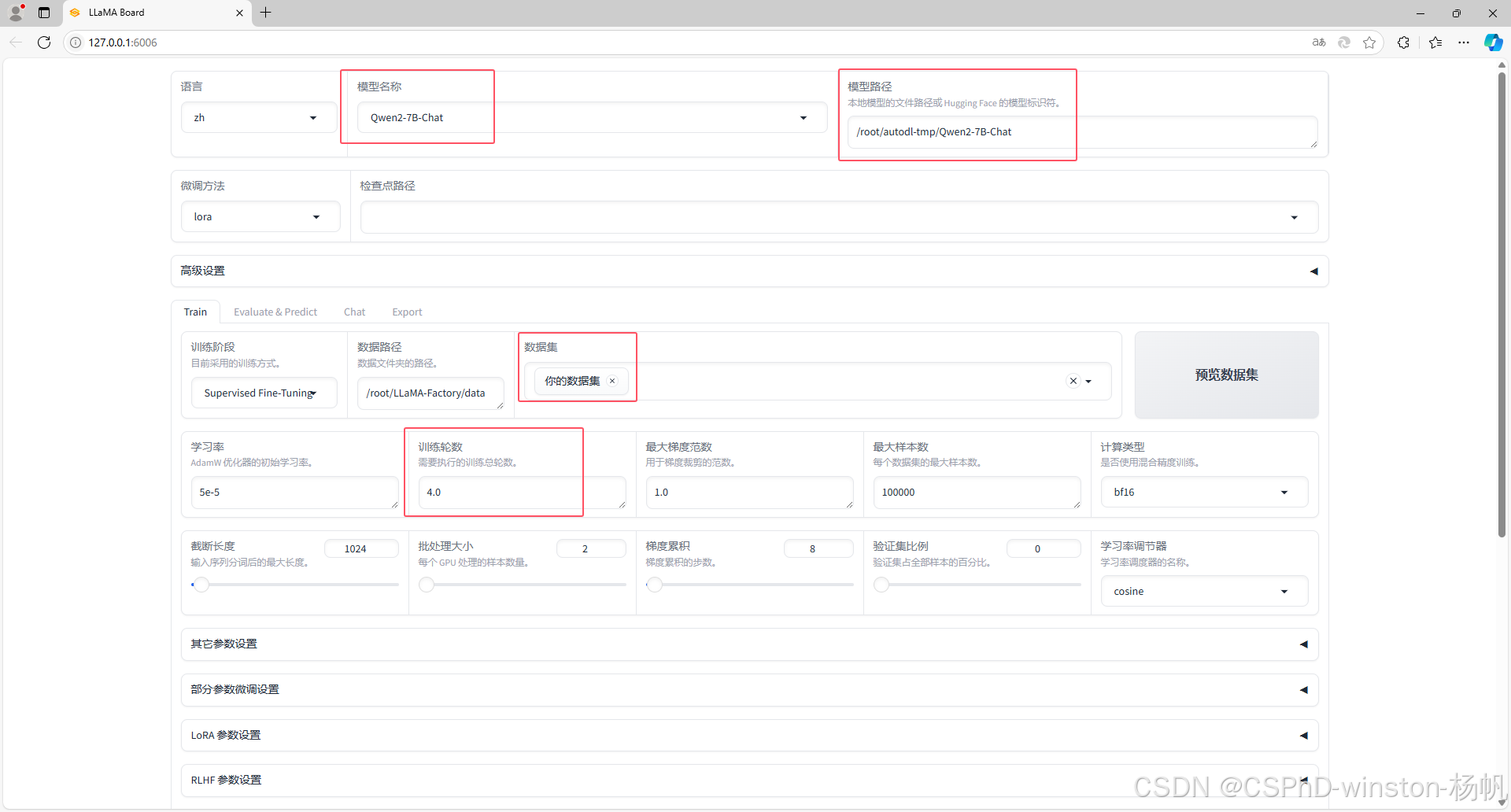
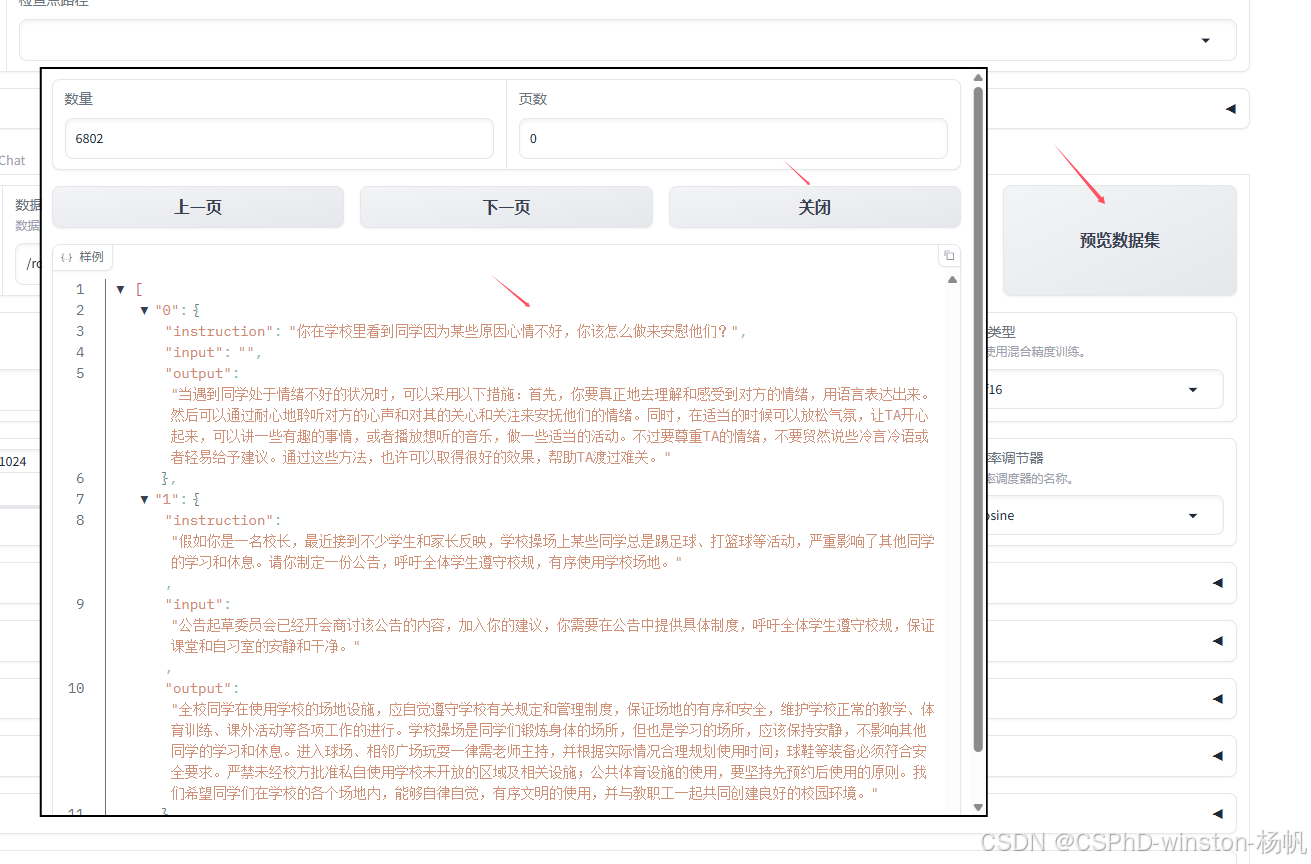
选择开始开始训练:
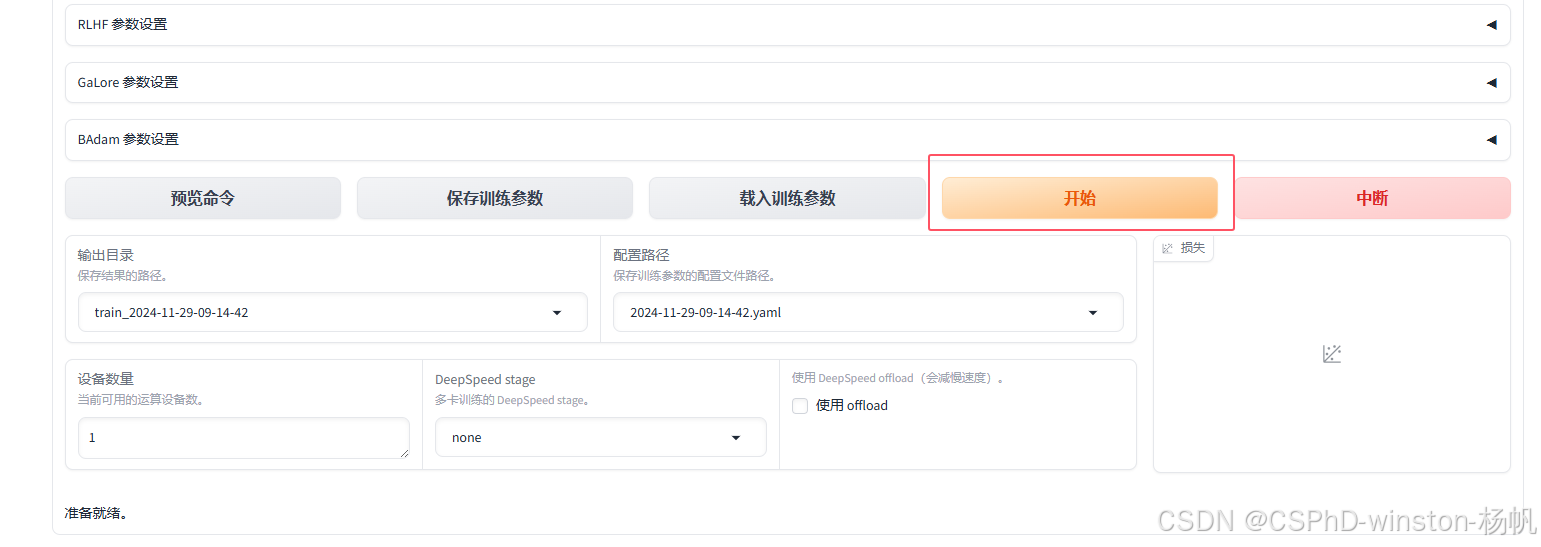
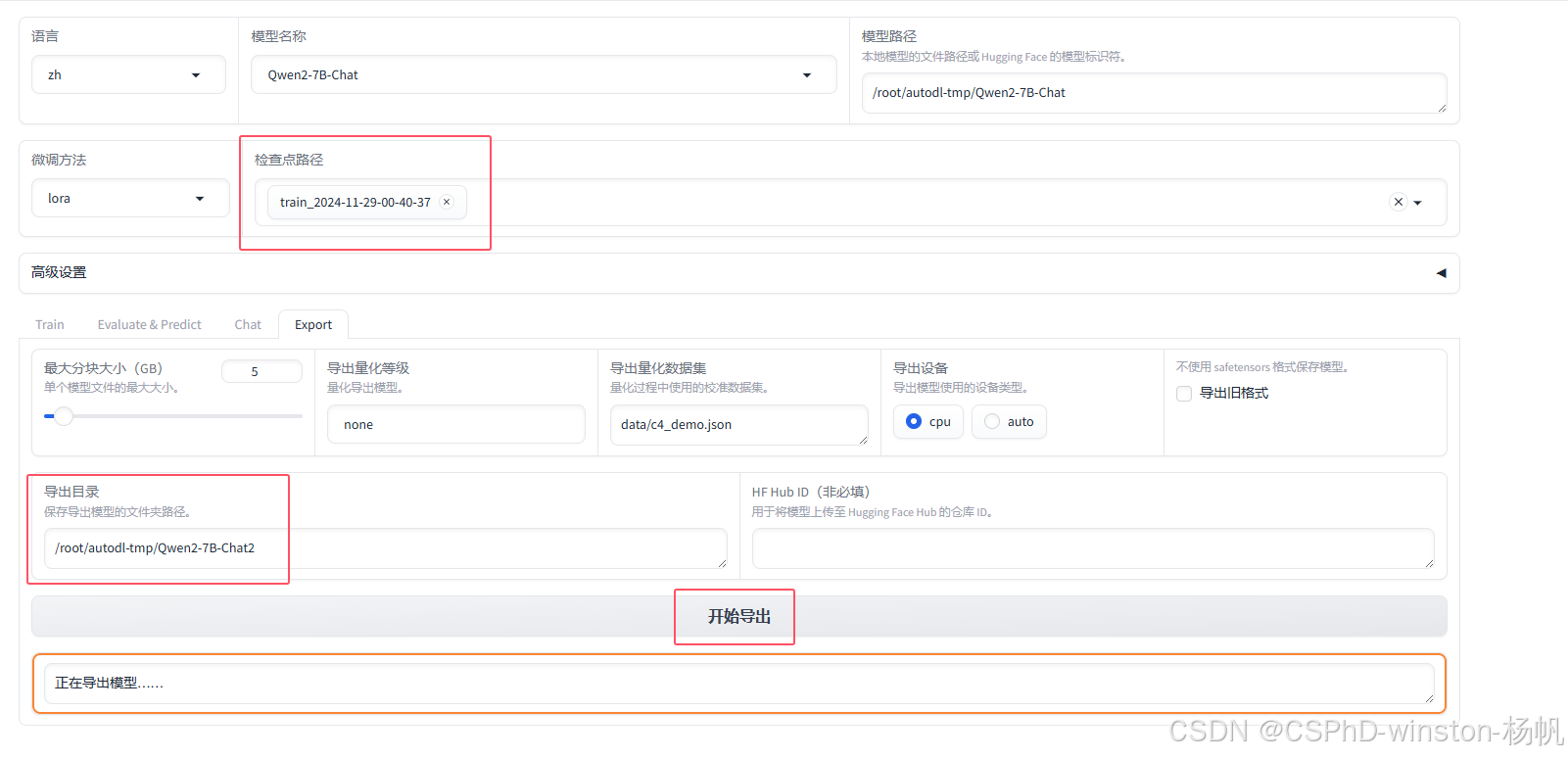
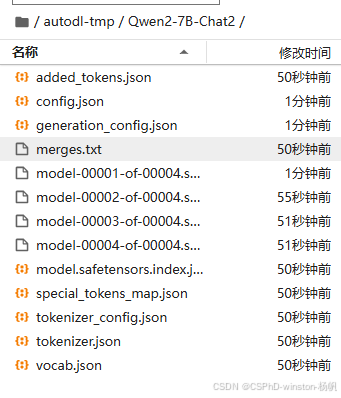
6.2 保存训练的模型
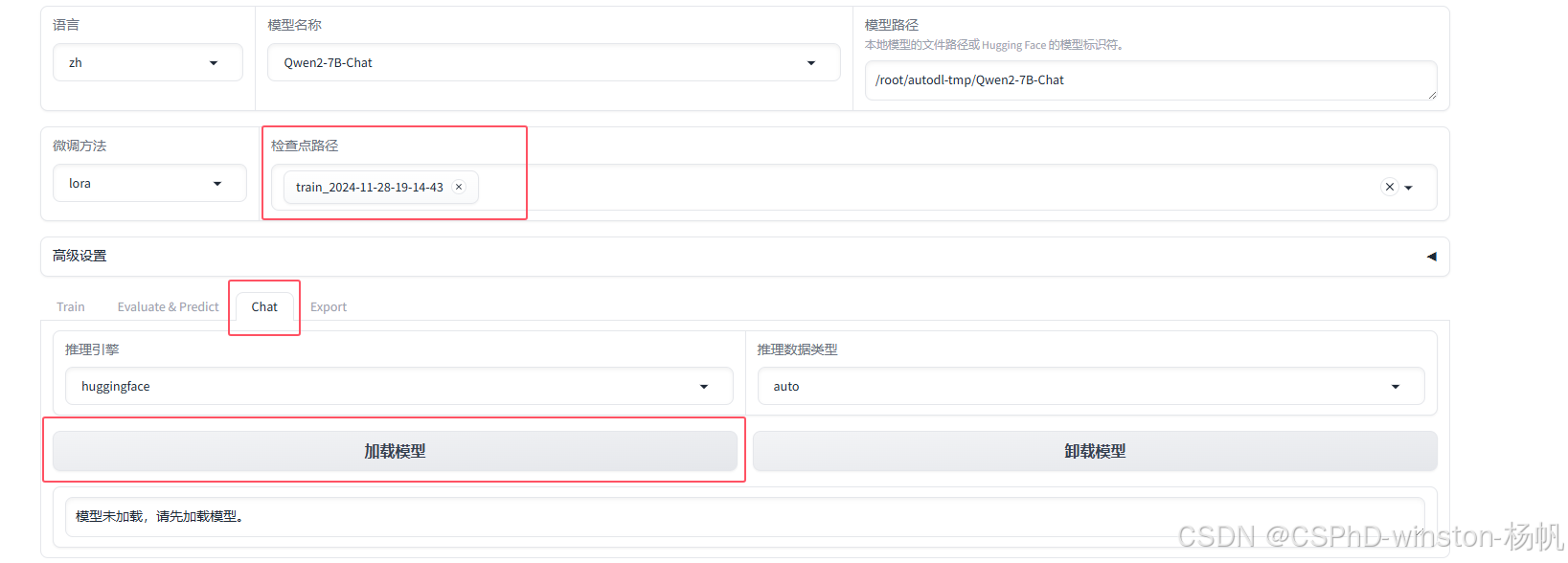
7 加载训练模型进行chat
COIG训练后的模型

部分cmmlu+全部COIG训练后的模型

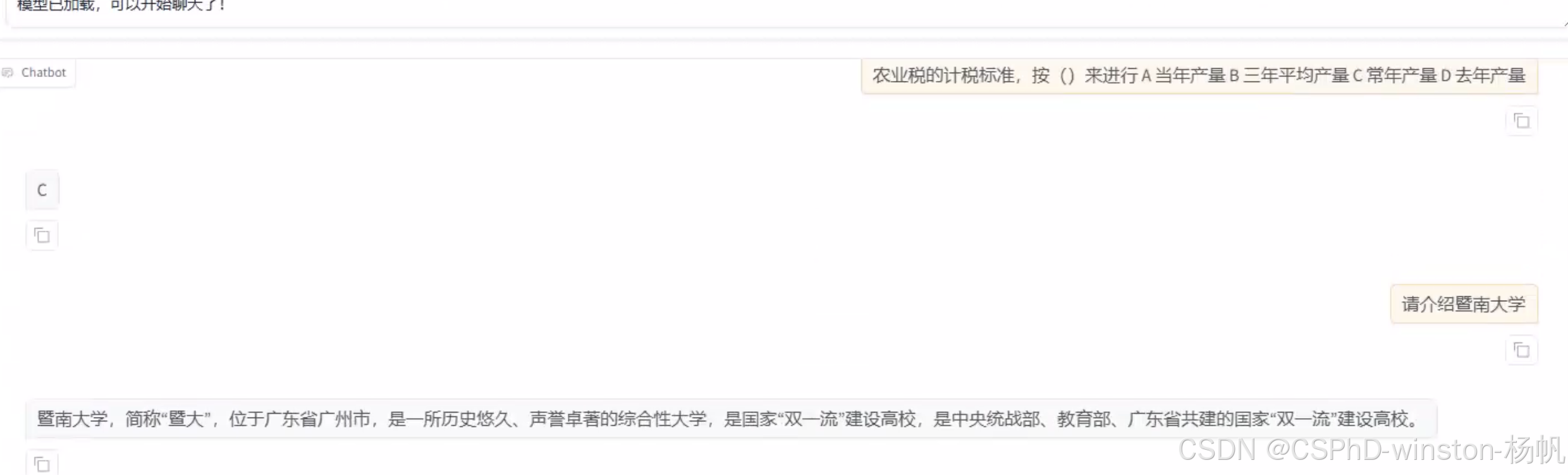
8 调用训练的模型,并本地化api
在6.2中,保存了微调后模型在autodl-tmp/Qwen2-7B-Chat2中
然后在api.sh进行修正
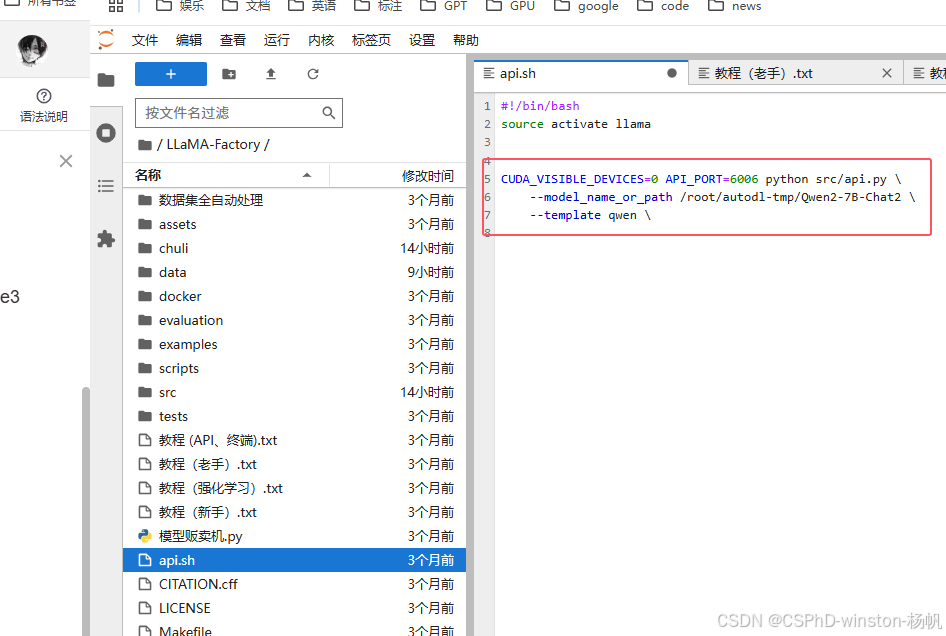
#!/bin/bash
source activate llama
CUDA_VISIBLE_DEVICES=0 API_PORT=6006 python src/api.py \
--model_name_or_path /root/autodl-tmp/Qwen2-7B-Chat2 \
--template qwen \
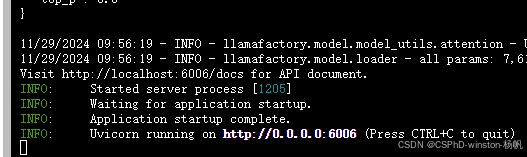
开启API
bash /root/LLaMA-Factory/api.sh
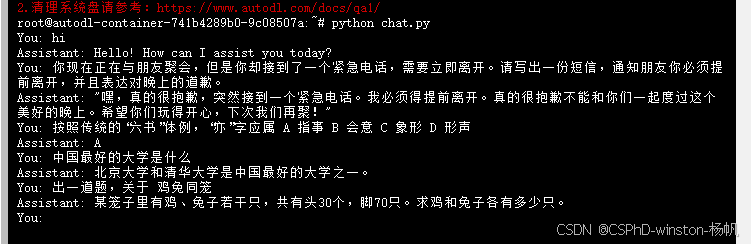
调用API
就在autodl上直接写个脚本调用
从自定义服务中拿到api的链接,然后填入如下脚本:
import openai
import sys
api_key = "EMPTY"
openai.api_base = "http://0.0.0.0:6006/v1"
def chat_with_gpt3_5(messages):
response = openai.ChatCompletion.create(
model="Qwen2-7B-Chat",
messages=messages,
api_key=api_key,
stream=True # 启用流式输出
)
full_response = ""
for chunk in response:
if 'choices' in chunk and len(chunk['choices']) > 0:
content = chunk['choices'][0].get('delta', {}).get('content', '')
if content:
print(content, end='', flush=True)
full_response += content
print()
return full_response
conversation = [
{"role": "system", "content": "你是一个聪明的AI"}
]
while True:
user_input = input("You: ")
if user_input.lower() == '退出':
print("Assistant: 再见!")
break
conversation.append({"role": "user", "content": user_input})
print("Assistant: ", end='', flush=True)
assistant_message = chat_with_gpt3_5(conversation)
conversation.append({"role": "assistant", "content": assistant_message})
9 Llama3-8B-chat模型的微调
前面都是采用Qwen 7B这个模型
现在采用其他模型,具体由哪些模型,镜像文档里提了:
https://www.codewithgpu.com/i/hiyouga/LLaMA-Factory/LLaMA-Factory
1.Qwen-7B-Chat
2.Qwen-14B-Chat
3.Qwen1.5-1.8B-Chat
4.Qwen1.5-7B-Chat
5.Qwen1.5-14B-Chat
6.Qwen1.5-32B-int4-Chat
7.Qwen2-7B-Chat
8.Qwen2-0.5B
9.glm-4-9b
10.glm-4-9b-chat
11.chatglm3-6b
12.Llama3-8B-chat
13.Llama3-8B-Chinese-Chat
14.Orion-14B-Chat
这次我们就采用:Llama3-8B-chat
搭建镜像后先删除原有的模型:
cd /root
rm -r Qwen2-7B-Chat/
执行:
python /root/LLaMA-Factory/模型贩卖机.py
然后输入:
Llama3-8B-chat
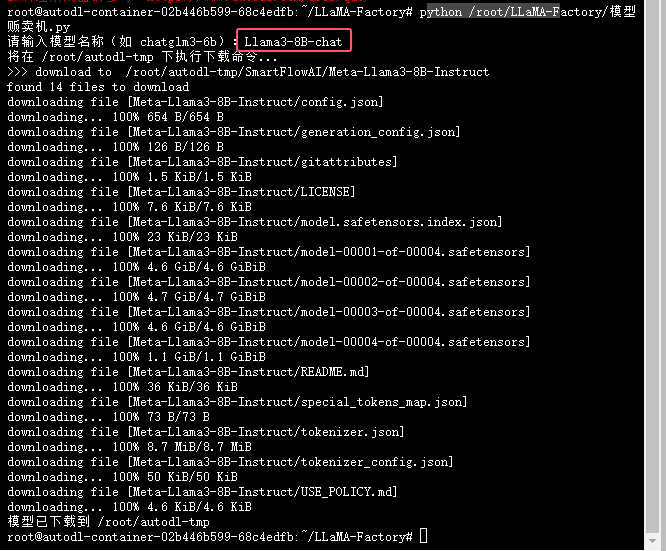
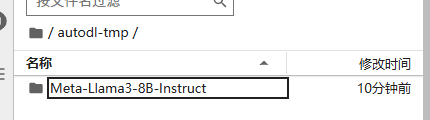
这样模型就下载好了
后面的微调的操作就是基本一致的了
生成/上传train.json, 位于:LLaMA-Factory/data/train.json
然后开启web界面:bash /root/LLaMA-Factory/chuli/one.sh
设置参数开始训练:
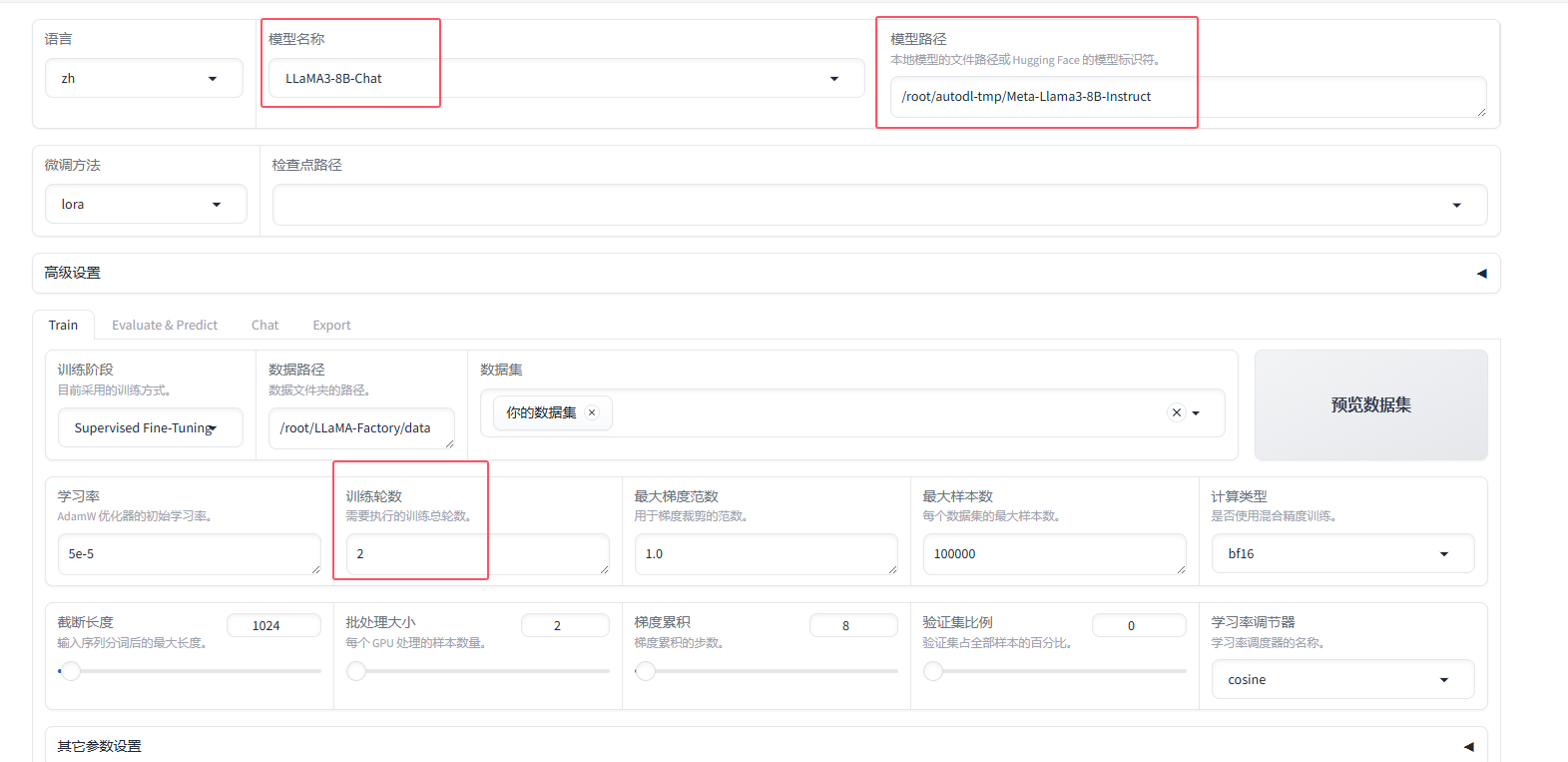
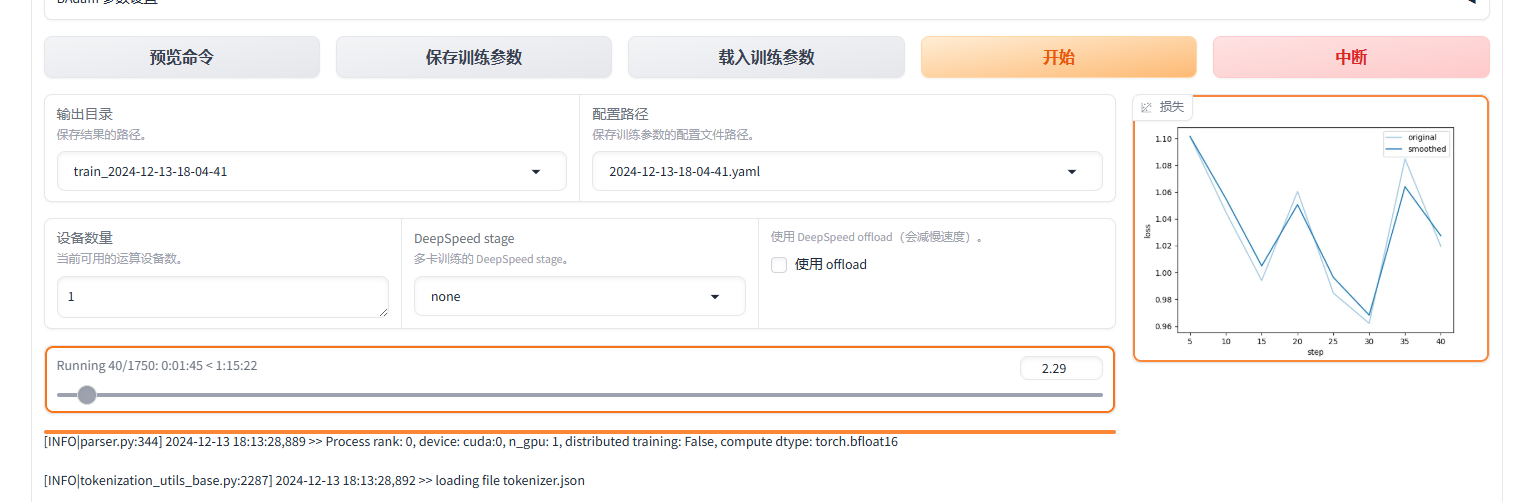


















 430
430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











