




 本文探讨了数据爬虫面临的主要挑战,包括软件、封锁、速度与规模化、数据准确性,以及针对这些问题的解决方案。测试了Bright Data的Web Unlocker和不同代理策略,以提高数据收集的准确性和效率。结论指出,Web Unlocker通过其请求管理、用户环境模拟和内容验证等功能,提供了更高效、稳定的数据爬取服务。
本文探讨了数据爬虫面临的主要挑战,包括软件、封锁、速度与规模化、数据准确性,以及针对这些问题的解决方案。测试了Bright Data的Web Unlocker和不同代理策略,以提高数据收集的准确性和效率。结论指出,Web Unlocker通过其请求管理、用户环境模拟和内容验证等功能,提供了更高效、稳定的数据爬取服务。
引言
"数据爬虫",也就是网络数据收集,在网站没有规模化之前曾经是相对容易完成的,但是现在却变得越来越具有挑战性。本文将通过在数据爬虫中普遍会遇到的4个问题,详细解释每种爬取途径的优点和缺点,以及如何最有效、快速且准确地收集真实数据。
4个常见挑战
当你想从一个网站上收集内容,在设计方案的阶段或已开始着手进行收集的时候,你可能需要考虑以下四个主要挑战
挑战一:软件
使用第三方供应商还是建立自己的软件基础设施?
定制化开发 (DIY)
你可以建立软件开发团队编写专有代码来创建一个数据爬虫。有多个开源的Python软件包,例如。
- BeautifulSoup
- Scrapy
- Selenium
定制化的好处是,软件是根据你目前的需要定制的。然而,其成本也很高。
- 数百或数千小时的编码工作
- 软件和硬件的购买和许可
- 代理ip基础设施和带宽仍将花费你的成本,更严重的是,即使数据收集失败,也会计费
软件维护是最大的挑战之一。当目标网站改变其页面结构时。这种情况经常发生,爬虫就会中断,代码就需要修复并重新上线。而且你还需要克服下面列出的另外三个挑战。
数据收集工具
你也可以使用第三方供应商,专门从事这一数据收集领域的工作,这样企业可以尽可能关注数据本身,而不是数据爬取过程中可能遇到的问题(反爬虫),下面详细介绍。
另外互联网上的其他软件可能是旧的和过时的。选型时需要注意,如果该网站看起来像是在上个世纪创建的,这可能反映在他们的软件上。需要强调的一点是,如果选型该类工具,注意供应商是否支持按成功收集数据收费
挑战之二:封锁
当我们试图收集一个网站数据时,往往会遇到目标网站机器人智能风控策略控制(“圈中”),以下是一些网站"流行"的反爬虫策略:
对IP的速率限制
当你从同一个IP地址向一个目标网站发送多个请求时,这可以被归类为可疑的活动。无论该网站设置了什么限制(可能是15个请求或1,500个),一旦超过这个限制,你的数据收集操作将被验证码或错误信息打断,需要人工/人为干预进行恢复,认为干预在规模化数据收集过程中显然是不可行的。
客户端指纹检测(浏览器,手机等终端设备或软件)
“指纹”是指通过获取本地机器各种信息,例如系统字体、分辨率、浏览器模式、语言、时区、UerAgent、计算机硬件,一些计算机的综合信息来计算出一个唯一值,这个唯一值就是指纹。很多大型网站为了保证数据质量等原因,会利用此类指纹来判断账号是否在同一台电脑等,检测到了就将违规批量操作的账号进行封停
用户代理的检测
网站使用不同的标头(headers),例如一些网站可能利用 "HTTP "标头来限制第三方爬虫并阻止或限制访问,保防止数据在互联网传输过程泄漏。
IP地理位置检测
一些网站实际上会根据你当前的地理位置来阻止你。这通常是由于他们希望根据地理位置定制内容、政府对某些信息的限制或内容许可,基于与当地电视频道签署的协议的内容许可限制,以及类似情况。
挑战之三:速度与规模化
数据爬取的速度和规模都是受底层代理基础设施影响的:
- 许多数据收集项目开始时只有几万个网页,但很快就扩展到几百万个。
- 大多数工具的收集速度很慢,每秒同时请求次数有限。请确保你的供应商的收集速度,考虑所需的页面数量,并考虑收集频率。如果您只需要抓取少量的页面,而且您可以将其安排在晚上运行,那么这对您来说可能不是一个问题
挑战之四:数据的准确性
爬虫程序可能只能成功收集部分数据。更具挑战的是网站页面结构的不定期变化可能会破坏数据收集程序,导致数据的不完整或不准确。
除了数据集的准确性和完整性之外,还要检查数据将如何交付以及以何种形式交付。这些数据必须与你现有的系统无缝整合。通过定制你的数据库模式,加快ETL 数据分析的进程。
风控解锁方案测试
根据上述分析,对于一些企业来说,定制化开发程序必不可少,但是是否有更好的方案帮助我们解决数据提取目标网站封锁的挑战。今天我们介绍一种方案的测试评估,利用Bright Data 的亮数据解锁器(以下称Web Unlocker )来绕过网站的风控策略,降低爬虫软件开发成本,从而提高数据的准确性以及效率
什么是Bright Data Web Unlocker
Web Unlocker是 Bright Data 提供的一个自动化模块,可以为你以极高的成功率(通常是100%)解锁被封禁的目标网站,所有你需要做的就是发送一个请求,而这个工具会处理其余的事情,包括适应不断变化的目标网站的风控策略。
Web Unlocker能够自动化、透明化处理以下内容:
- IP 自动轮换
- 请求错误重试
- 请求http header
- 用户代理 User agent
- 客户端指纹
另外使用这个工具的一个关键优势是,你只需要为成功获取数据的请求付费。这也是上文提到工具选型的重要因素之一。
Bright Data Web Unlocker 原理
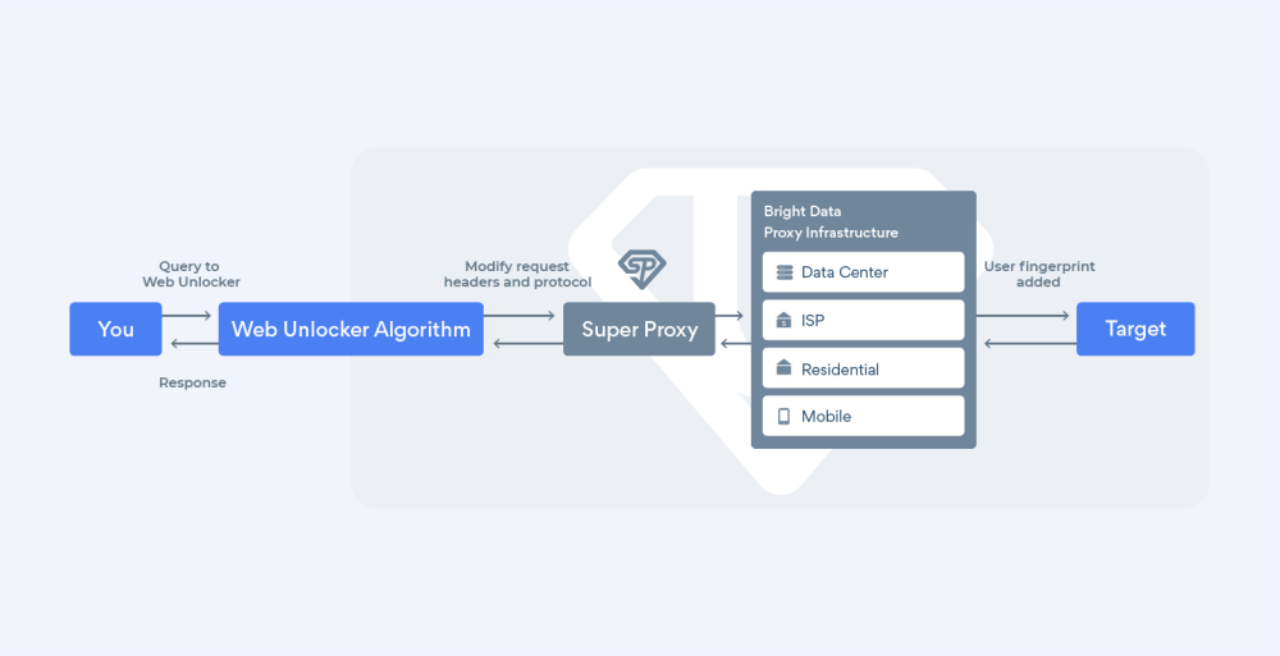
如下图,
客户端发送请求到带有Web Unlocker处理引擎的超级代理(Super proxy),超级代理是Bright Data 提供的代理工具
Web Unlocker引擎会调整请求头,请求协议等,
超级代理会基于Bright Data 提供的 4 大类全球 IP 池进行代理请求,请求过程附加客户端指纹信息,尽可能确保不会被封禁,如果请求成功,返回客户端
如果失败, Web Unlocker,进行其他策略尝试,如 IP 切换,指纹模拟等,进行请求重试
数据爬虫方案测试
测试用例设计
我将对比两家代理供应商,以及不同的产品,以同一个网站为目标进行测试。
代理提供商 |
代理类型 |
测试用例 |
smartproxy |
动态代理 |
获取亚马逊首页数据 循环执行100次 |
BrightData |
动态代理 |
获取亚马逊首页数据 循环执行100次 |
BrightData |
Unblocker |
获取亚马逊首页数据 循环执行100次 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2724
2724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









