




 本文详细介绍如何使用Selenium和Chrome WebDriver进行自动化测试,包括环境搭建、基本操作及数据采集实践,通过具体案例演示如何实现网页元素定位和信息抓取。
本文详细介绍如何使用Selenium和Chrome WebDriver进行自动化测试,包括环境搭建、基本操作及数据采集实践,通过具体案例演示如何实现网页元素定位和信息抓取。
数据采集——爬虫篇(三):selenium+Chrome实现自动化测试—爬取数据
.
1.selenium环境安装部署
首先安装Chrome谷歌浏览器
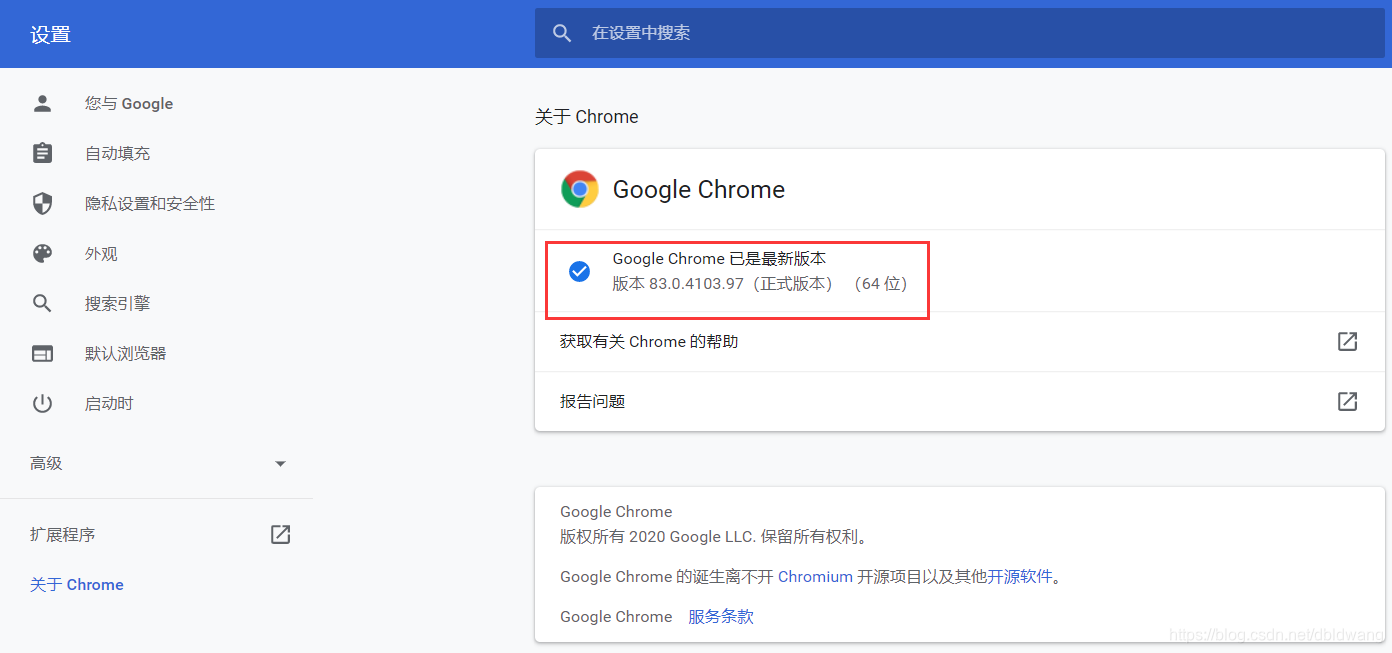
查看设置系统版本:
然后下载Chrome对应的webdriver
地址:http://npm.taobao.org/mirrors/chromedriver/
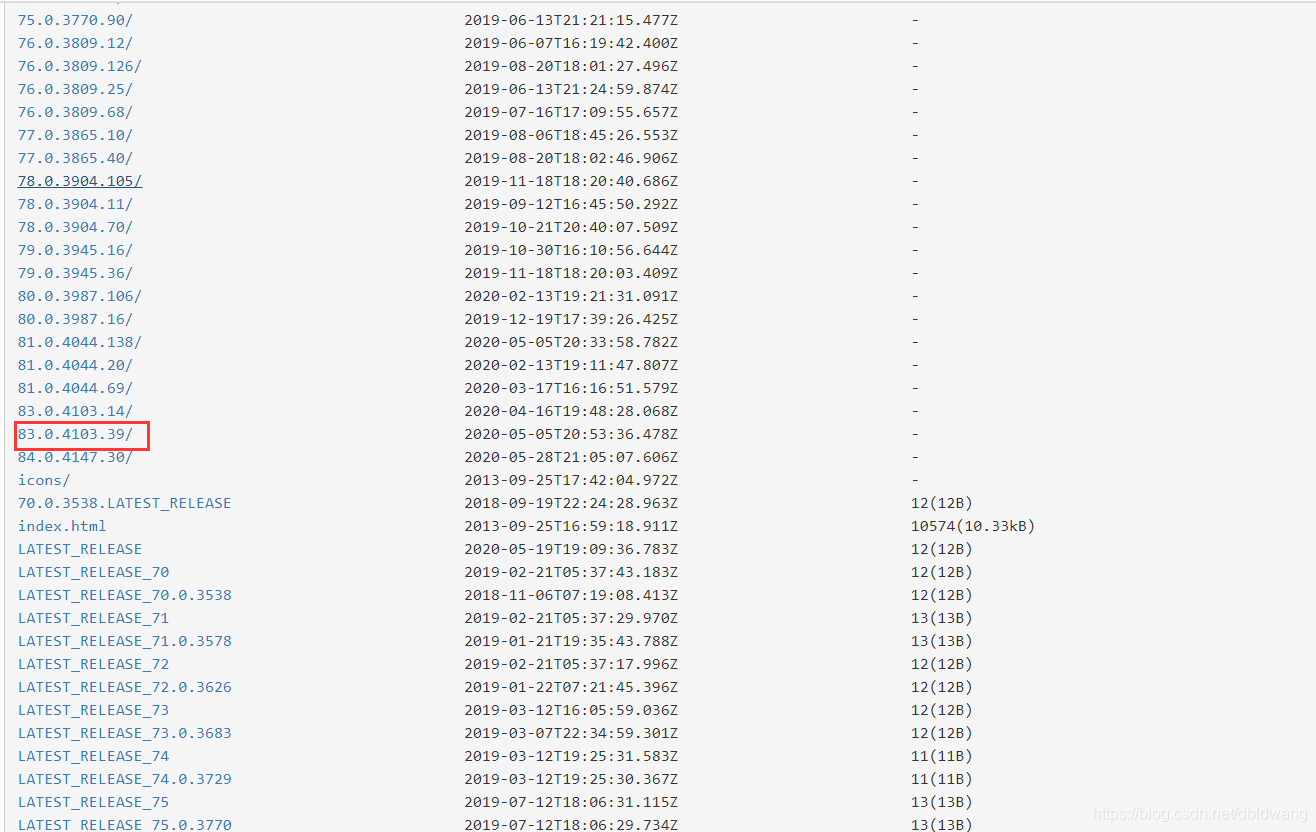
选择对应版本,我的版本是83.0.4103.97:
注:基本没有完全对应的版本,选择与当前版本最接近的即可
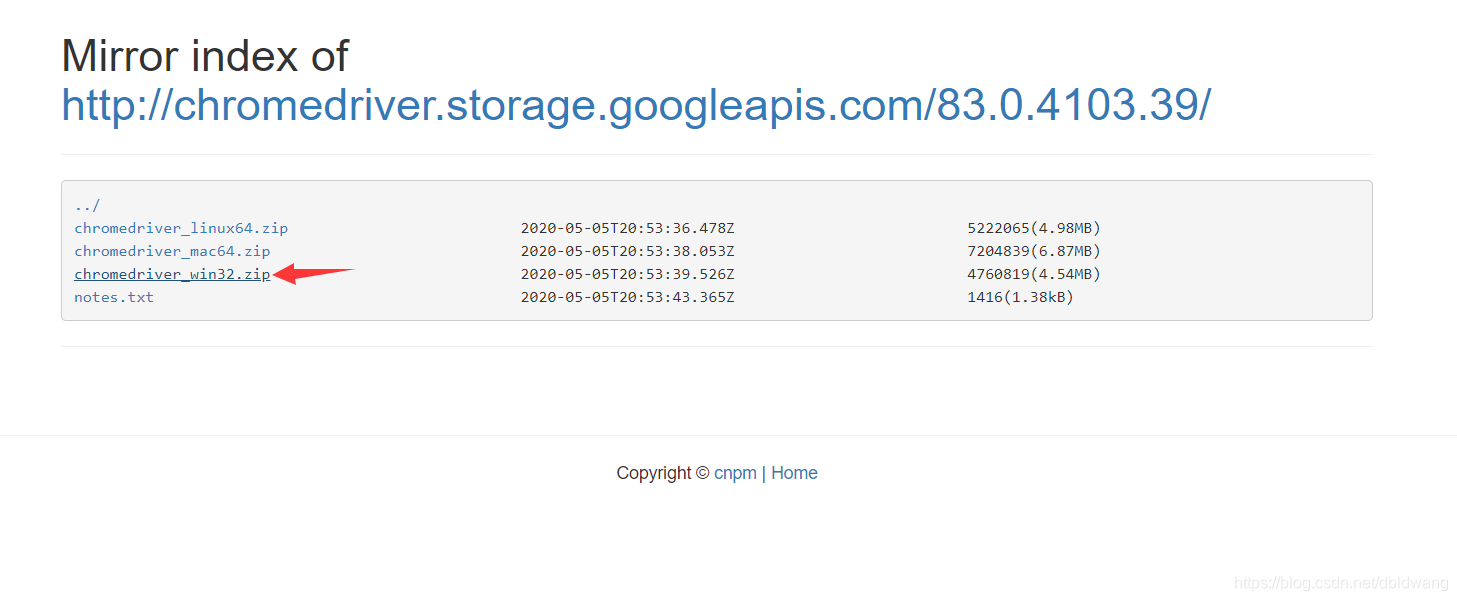
根据操作系统不同,选择对应驱动(选择为Windows):
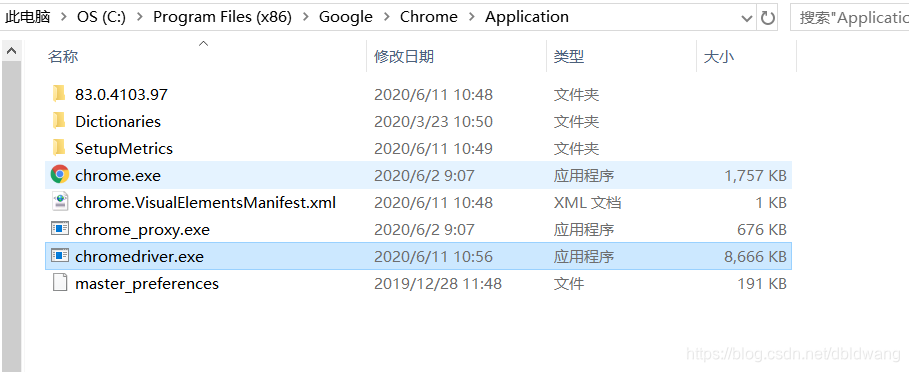
下载解压并复制到chrome浏览器的安装路径Google/Chrome/Application下
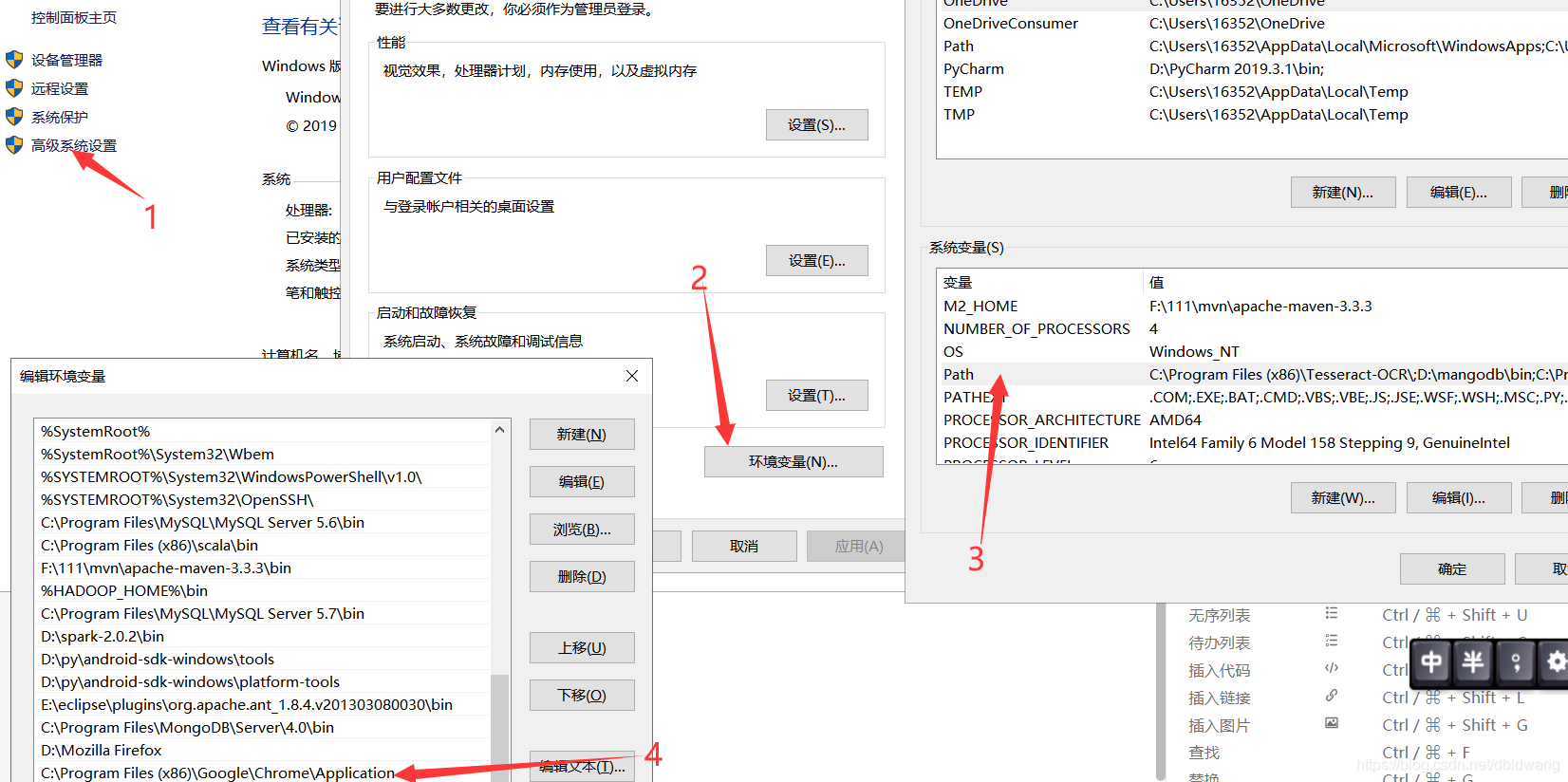
复制当前路径,右击我的电脑打开属性,选择高级系统设置,再次选择环境变量,选择path变量,添加我们复制的application路径,之后全部点击确定,确保环境变量能够保存
之后打开dos命令,使用pip安装selenium库:
pip install selenium
等待安装完成,环境准备已经完成。
**
2.使用selenium
**
selenium编写
from selenium import webdriver #导入模块
Google = webdriver.Chrome() #导入谷歌浏览器,使用Google变量调用
编写采集步骤
(1)跳转到指定采集网站:
Google.get('https://www.baidu.com')
如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









