



目录
序列化
概念
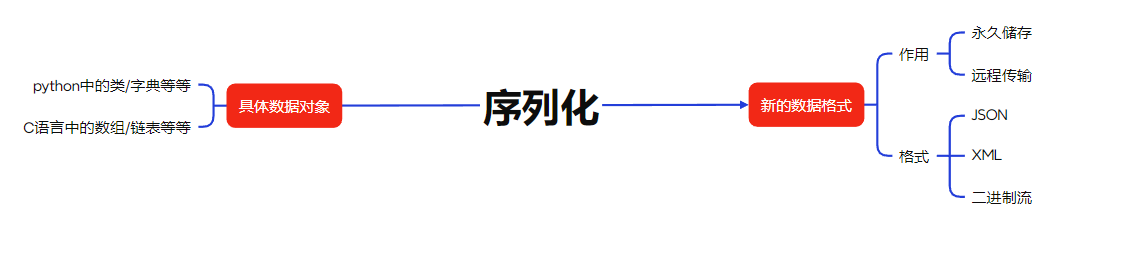
序列化是将内存中的数据对象(如 Python 的列表、字典、类实例等)转换为一种可以永久存储(如写入文件)或远程传输(如通过网络发送)的格式(JSON、XML、二进制流等)。
解释
-
具体数据对象:各种编程语言对数据对象的结构和表示方式有各自的定义和实现方式。比如同样的列表或数组,在 Python 和 C 中就有不同的写法和结构。因此在跨平台或跨语言的数据交换中,需要对这些数据对象进行统一格式的转换。
-
新的数据格式:在程序运行时,变量、对象等数据是保存在内存中的,属于临时数据,程序一结束,内存被释放,这些数据就会消失。为了让这些数据可以被“保存下来”或者“发送出去”,我们需要将其转换成一种可读、可写、可传输的格式,这就是序列化的作用。序列化后生成的“数据格式”,如 JSON、XML、或二进制,不再依赖于语言的内存结构,而是变成了纯粹的文本或字节流。
JSON
概念
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它使用易于人阅读和编写的文本格式,同时也易于机器解析和生成。虽然源自 JavaScript,但 JSON 已成为跨编程语言广泛支持的标准格式,尤其在 Web 开发、网络通信、配置文件、数据库等场景中被广泛使用。
JSON的数据形式
JSON的value可以是以下类型
| 类型 | 示例 |
|---|---|
| 字符串 | "hello" |
| 数字 | 123, 3.14 |
| 布尔值 | true, false |
| 空值 | null |
| 对象 | { "name": "Alice", "age": 25 } |
| 数组 | [1, 2, 3, "four", true] |
JSON 的两种基本数据结构
对象(Object)
-
本质:一组键值对的无序集合
-
格式:
{"key":value,...} -
注意点:
-
"key"必须严格的用双引号包裹
-
字符串必须严格的用双引号包裹
-
无序意味着不能用下标索引(index)来访问,只能通过键来查找值
-
数组(Array)
-
本质:一组值的有序列表
-
格式:
[value1,value2,...]
常见编程语言使用JSON的方法
| 编程语言 | 引用库 / 方法 | 示例代码 |
|---|---|---|
| Python | import json | json_str = json.dumps(data)``data = json.loads(str) |
| JavaScript | 原生支持 | JSON.stringify(obj)``JSON.parse(str) |
| Java | import org.json.* 或使用 Gson 库 | new JSONObject() / Gson gson = new Gson(); |
| C# | using System.Text.Json; | JsonSerializer.Serialize(obj) / Deserialize<T>() |
| PHP | 内置函数 | json_encode($array) / json_decode($string) |
| Go | import "encoding/json" | json.Marshal(data) / json.Unmarshal(jsonStr, &data) |
Python 内置类型与 JSON 类型的对应关系
因为本文主要介绍python反序列化,因此很有必要单独列出此关系
| Python 类型 | JSON 类型 | 示例 |
|---|---|---|
dict | object(对象) | {"name": "Alice"} |
list, tuple | array(数组) | [1, 2, 3] |
str | string(字符串) | "hello" |
int, float | number(数字) | 42, 3.14 |
bool | boolean(布尔) | true, false |
None | null(空) | null |
反序列化
概念
反序列化是将序列化后的数据(还原成原始对象或数据结构的过程。
解释
序列化后得到的是一种通用格式的数据(例如 JSON 字符串或二进制流),不能直接用于程序逻辑。反序列化用来恢复原始对象,使程序能继续处理数据。

python中的序列化操作
Python 提供了多个内置模块来支持不同场景下的序列化需求,比如 json(通用文本格式)、pickle(Python 专用格式)以及 marshal(底层用途)等。
JSON模块
dumps函数
作用:将 Python 对象序列化为 JSON 格式的字符串。
json.dumps(obj, *, skipkeys=False, ensure_ascii=True, indent=None, separators=None, default=None, sort_keys=False)import json
data = {'name': '小明', 'age': 20}
json_str = json.dumps(data, ensure_ascii=False, indent=2)
print(json_str)
| 参数名 | 含义 |
|---|---|
obj | 要序列化的 Python 对象(如 dict、list) |
skipkeys | 如果为 True,则跳过 dict 中不支持为 key 的类型(如元组) |
ensure_ascii | 默认为 True,所有输出内容将被转为 ASCII(中文会变成 Unicode 编码)设为 False 可正常显示中文 |
indent | 设置缩进级别 |
separators | 设置分隔符,默认是 (', ', ': ') |
default | 遇到无法序列化的对象时,使用此函数进行处理 |
sort_keys | 是否按键名排序输出 JSON 对象 |
补充一点:python中,*作用是限制从这个位置开始的所有参数必须通过“关键字参数”的形式传入,而不能用位置参数传入。
json.dumps(obj, ensure_ascii=False) # 正确,用关键字传参
json.dumps(obj, False) # 错误,用位置参数传参
dump函数
作用:将对象直接序列化写入文件对象fp中
json.dump(obj, fp, **kwargs)-
obj:要写入的 Python 对象 -
fp:一个已打开的文件对象,以写模式('w')打开 -
**kwargs:与dumps()支持的参数一样,如indent、ensure_ascii等
import json
with open('out.json', 'w', encoding='utf-8') as f:
json.dump({'a': 1, 'b': 2}, f, indent=2, ensure_ascii=False)
pickle模块
dumps函数
pickle.dumps(obj, protocol=None, *, fix_imports=True,buffer_callback=None)作用:将 Python 对象序列化为二进制数据(bytes)
| 参数名 | 含义 |
|---|---|
obj | 要序列化的对象 |
protocol | 协议版本(0~5),推荐 protocol=pickle.HIGHEST_PROTOCOL |
fix_imports | 用于跨 Python 2/3 时修复模块名(一般不用管) |
buffer_callback | 用于高级内存优化(用于支持大型对象),通常不用 |
import pickle
data = {'a': 1}
b = pickle.dumps(data)
dump函数
作用:将 Python 对象以二进制格式写入文件。
pickle.dump(obj, file, protocol=None)import pickle
with open('data.pkl', 'wb') as f:
pickle.dump(data, f)
python中的反序列化操作
JSON模块
loads函数
作用:将JSON字符串反序列化为python对象
json.loads(s, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None)| 参数名 | 含义 |
|---|---|
s | JSON 格式的字符串 |
cls | 自定义反序列化时使用的类(高级用法) |
object_hook | 用于定制 JSON 对象转 Python 时的转换规则(如变为自定义类) |
parse_float | 替换默认的 float 类型(如用 Decimal) |
parse_int | 替换默认的 int 类型 |
parse_constant | 处理特殊的 JSON 常量如 NaN、Infinity |
import json
json_str = '{"x": 1, "y": 2.5}'
data = json.loads(json_str)
print(data)
load函数
作用:从文件对象 fp 中读取 JSON 数据并反序列化为 Python 对象。
json.load(fp)import json
with open('out.json', 'r', encoding='utf-8') as f:
data = json.load(f)
print(data)
pickle模块
loads函数
作用:将 bytes_obj(二进制数据类型对象) 中的二进制数据反序列化为 Python 对象。
pickle.loads(bytes_obj, *, fix_imports=True, encoding="ASCII", errors="strict", buffers=None)import pickle
data = {'a': 1}
b = pickle.dumps(data)
obj = pickle.loads(b)
print(obj) # 输出:{'a': 1}
load函数
作用:从二进制文件中反序列化出对象。
pickle.load(file)import pickle
with open('data.pkl', 'rb') as f:
obj = pickle.load(f)
无论是JSON模块还是pickle模块,序列化操作均是dump/dumps函数;反序列化均是load/loads函数。而dumps/loads针对文件,dump/load针对除文件外的对象。

















 2635
2635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









