







@TOC

写在最前面
版权声明:本文为原创,遵循 CC 4.0 BY-SA 协议。转载请注明出处。
太好了,终于定位并解决了问题 🎉
📌关键词:PyTorch、CUDA OOM、模型输入尺寸、图像预处理、对抗样本
🗓️ 日期:2025年4月
在使用 PyTorch 进行模型训练或推理时,CUDA Out Of Memory(OOM) 是不少人经常遇到的问题之一。虽然常见的原因是 batch size 太大、模型结构复杂等,但在最近一次调试过程中,我发现了一个 更隐蔽但致命的原因:输入图像尺寸异常。
这篇文章就带你看看如何通过一步步排查,定位出导致 OOM 的真正“幕后黑手”。
| 问题 | 说明 |
|---|---|
| 原因 | 攻击生成的图像尺寸为 299x299,模型只能接受 32x32 |
| 后果 | VGG forward 时爆显存,导致 CUDA OOM |
| 解决方法 | resize 图像至 32x32 或在读取时加 assert |
| 预防 | 编写图像尺寸检测脚本做预处理 |
💥 场景还原
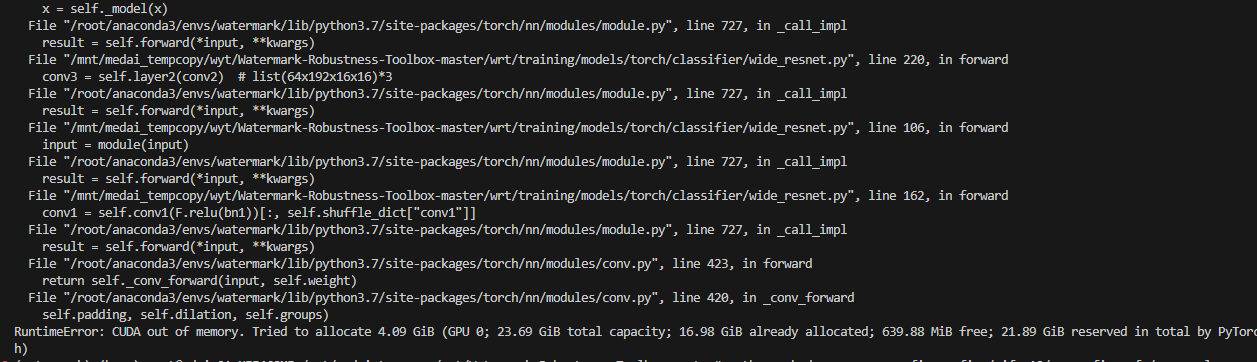
当我们在对模型进行某种任务(比如水印嵌入、水印验证或对抗样本生成)时,执行代码报出以下错误:
RuntimeError: CUDA out of memory. Tried to allocate 4.09 GiB ...
同时,调试信息中打印了输入张量的尺寸:
x_adv shape: (200, 3, 299, 299)
这是一个非常关键的线索。
🧠 模型真的吃了这么多显存吗?
让我们假设你正在使用 VGG、ResNet 等常见的轻量级网络,并且是在 CIFAR-10 这类小图像数据集(32×32)上进行训练。
正常情况下,处理 32x32 的图像不会造成显存崩溃。但如果输入尺寸变成了 299x299,显存消耗将迅速增加几十倍。
| 图像尺寸 | 单张显存占用 (大致) |
|---|---|
| 32×32 | 几 MB |
| 299×299 | 数百 MB 甚至更多 |
在 batch size = 200 时,299×299 的输入甚至会让高端 24GB 显卡都吃不消。
🧪 问题根源:输入图像尺寸异常
我们常见的图像预处理流程如下:
img = Image.open(img_path).convert('RGB')
img = img.resize((32, 32))
img_tensor = ToTensor()(img)
但是,如果你遗漏了 .resize(),就会把原始图片尺寸直接送进模型。而有些图像可能是在使用预训练模型(如 Inception v3)时被生成为 299x299 尺寸,结果在后续被不加检查地送入其他模型(比如 VGG-16),直接引发爆显存。
🔍 如何排查?
✅ 方法一:打印张量尺寸
在模型 forward 前加入如下调试代码:
print(f"输入图像尺寸: {input_tensor.shape}")
✅ 方法二:添加断言
assert input_tensor.shape[-1] == 32, f"图像尺寸不匹配: {input_tensor.shape}"
🔧 如何修复?
✅ 正确地 resize 图像:
from PIL import Image
img = Image.open("example.png").convert("RGB").resize((32, 32))
✅ 在 PyTorch pipeline 中:
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor()
])
🧰 Bonus 工具:检查一个文件夹内所有图片尺寸
from PIL import Image
import os
def check_image_sizes(folder, expected_size=(32, 32)):
for fname in os.listdir(folder):
if fname.endswith(".png") or fname.endswith(".jpg"):
path = os.path.join(folder, fname)
try:
with Image.open(path) as img:
if img.size != expected_size:
print(f"[异常] {fname} 尺寸为 {img.size}")
except Exception as e:
print(f"[错误] 无法读取 {fname}: {e}")
# 示例使用
check_image_sizes("path/to/images")
✅ 总结
| 项目 | 正确做法 |
|---|---|
| 模型输入尺寸 | 与模型训练尺寸严格一致 |
| 加载图像 | 使用 .resize() 保证尺寸一致 |
| 图像管道 | 配置 transforms.Resize() |
| 调试方法 | 打印/断言 tensor.shape |
| 防御手段 | 批量检查图像尺寸脚本 |
✍️ 最后的话
显存不足的问题,并不总是 batch size 或模型太大造成的。
有时,一个没有 resize 的输入图像,就能让你的显卡崩溃。
保持每一环节的数据一致性,才是深度学习中最可靠的“优化技巧”。
❤️ 后记
这个问题提醒我:模型输入和攻击生成的图像尺寸一定要严格一致,哪怕是在已知的数据集下,依旧要检查每一环节的数据预处理!
📣 欢迎转发、点赞、收藏,也欢迎在评论区交流你遇到的 CUDA OOM 问题!
hello,我是 是Yu欸 。如果你喜欢我的文章,欢迎三连给我鼓励和支持:👍点赞 📁 关注 💬评论,我会给大家带来更多有用有趣的文章。
原文链接 👉 ,⚡️更新更及时。
欢迎大家点开下面名片,添加好友交流。


















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











