



循环神经网络:掌握序列数据处理的艺术
学习目标
本课程将带领学员深入了解循环神经网络(RNN)及其变体(如LSTM和GRU)的基本概念,通过实际操作学习如何使用TensorFlow构建和训练RNN模型,以处理序列数据。学员将能够理解RNN的工作原理,掌握使用TensorFlow实现RNN的方法,并能够应用这些模型解决实际问题。
相关知识点
- 循环神经网络
学习内容
1 循环神经网络
1.1 循环神经网络(RNN)基础
循环神经网络(Recurrent Neural Network, RNN)是一种用于处理序列数据的神经网络模型。与传统的前馈神经网络不同,RNN具有内部状态(记忆),可以捕捉序列中的时间依赖关系。这种特性使得RNN在自然语言处理、语音识别、时间序列预测等领域中表现出色。
RNN的基本结构
RNN的基本结构包括输入层、隐藏层和输出层。隐藏层中的每个神经元不仅接收来自输入层的信息,还接收来自上一时间步的隐藏状态信息。这种结构允许网络在处理当前输入时考虑之前的信息,从而捕捉序列中的时间依赖性。
RNN的计算过程
在每个时间步,RNN接收一个输入向量 xtx_txt 和上一时间步的隐藏状态 ht−1h_{t-1}ht−1,计算当前时间步的隐藏状态 hth_tht和输出 yty_tyt计算公式如下:
ht=σ(Whhht−1+Wxhxt+bh)h_t = \sigma(W_{hh} h_{t-1} + W_{xh} x_t + b_h)ht=σ(Whhht−1+Wxhxt+bh)
yt=Whyht+byy_t = W_{hy} h_t + b_yyt=Whyht+by
其中,WhhW_{hh}Whh、WxhW_{xh}WxhWhyW_{hy}Why 是权重矩阵,bhb_hbh和 byb_yby偏置项,σ\sigmaσ是激活函数(如tanh或ReLU)。
RNN的训练
RNN的训练通常使用基于时间的反向传播(Backpropagation Through Time, BPTT)算法。BPTT将RNN在时间上的展开视为一个深层网络,然后应用标准的反向传播算法来更新权重。然而,RNN在训练过程中容易遇到梯度消失和梯度爆炸的问题,这限制了其在长序列上的表现。
1.2 长短期记忆网络(LSTM)
长短期记忆网络(Long Short-Term Memory, LSTM)是一种特殊的RNN,旨在解决梯度消失和梯度爆炸的问题。LSTM通过引入门控机制来控制信息的流动,从而有效地捕捉长距离依赖关系。
LSTM的结构
LSTM的核心是细胞状态(Cell State),它贯穿整个序列,允许信息在时间上流动。LSTM通过三个门控机制来控制细胞状态的更新和输出:
- 遗忘门(Forget Gate):决定丢弃细胞状态中的哪些信息。
- 输入门(Input Gate):决定添加到细胞状态中的新信息。
- 输出门(Output Gate):决定细胞状态的哪些部分作为输出。
LSTM的计算过程
LSTM的计算过程可以分为以下几个步骤:
-
遗忘门:计算遗忘门的输出 ftf_tft决定丢弃细胞状态中的哪些信息。
ft=σ(Wf[ht−1,xt]+bf)f_t = \sigma(W_f [h_{t-1}, x_t] + b_f)ft=σ(Wf[ht−1,xt]+bf) -
输入门:计算输入门的输出 iti_tit和候选细胞状态 C~t\tilde{C}_tC~t
it=σ(Wi[ht−1,xt]+bi)i_t = \sigma(W_i [h_{t-1}, x_t] + b_i)it=σ(Wi[ht−1,xt]+bi)
C~t=tanh(WC[ht−1,xt]+bC)\tilde{C}_t = \tanh(W_C [h_{t-1}, x_t] + b_C)C~t=tanh(WC[ht−1,xt]+bC) -
细胞状态更新:更新细胞状态 CtC_tCt
Ct=ft⊙Ct−1+it⊙C~tC_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_tCt=ft⊙Ct−1+it⊙C~t -
输出门:计算输出门的输出 oto_tot和隐藏状态 hth_tht
ot=σ(Wo[ht−1,xt]+bo)o_t = \sigma(W_o [h_{t-1}, x_t] + b_o)ot=σ(Wo[ht−1,xt]+bo)ht=ot⊙tanh(Ct)h_t = o_t \odot \tanh(C_t)ht=ot⊙tanh(Ct)
使用TensorFlow实现LSTM
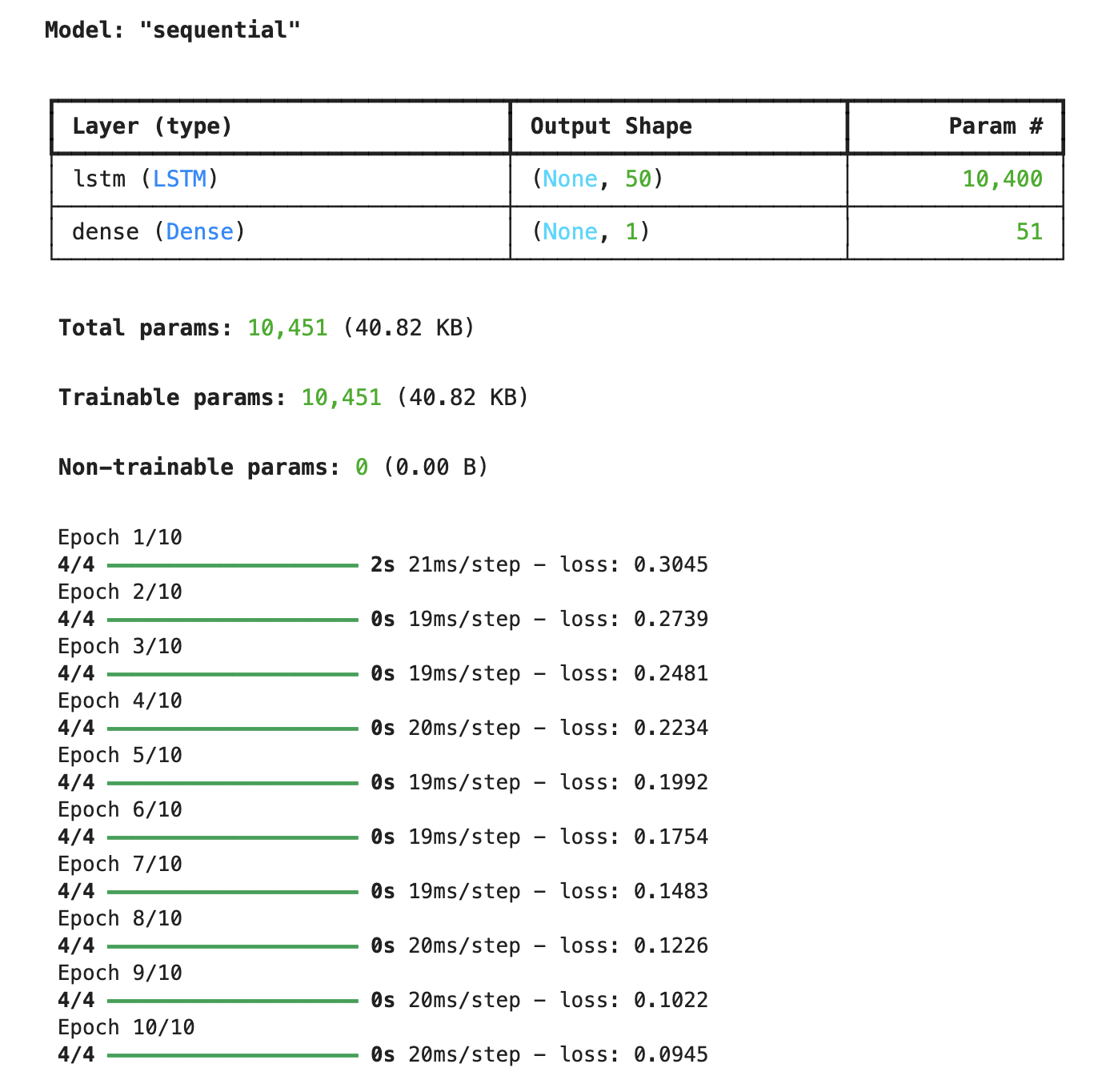
下面是一个使用TensorFlow实现LSTM的示例代码:
%pip install tensorflow
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# 定义模型
model = Sequential()
model.add(LSTM(50, activation='relu', input_shape=(10, 1)))
model.add(Dense(1))
# 编译模型
model.compile(optimizer='adam', loss='mse')
# 打印模型结构
model.summary()
# 生成示例数据
import numpy as np
X = np.random.rand(100, 10, 1)
y = np.random.rand(100, 1)
# 训练模型
model.fit(X, y, epochs=10, batch_size=32)
1.3 门控循环单元(GRU)
门控循环单元(Gated Recurrent Unit, GRU)是另一种改进的RNN模型,旨在简化LSTM的结构,同时保持其捕捉长距离依赖关系的能力。GRU通过合并遗忘门和输入门,减少了模型的复杂性。
GRU的结构
GRU的核心是更新门(Update Gate)和重置门(Reset Gate)。更新门决定细胞状态的哪些部分需要更新,重置门决定细胞状态的哪些部分需要重置。
GRU的计算过程
GRU的计算过程可以分为以下几个步骤:
- 重置门:计算重置门的输出 rtr_trt。
rt=σ(Wr[ht−1,xt]+br)r_t = \sigma(W_r [h_{t-1}, x_t] + b_r)rt=σ(Wr[ht−1,xt]+br) - 更新门:计算更新门的输出 ztz_tzt。
zt=σ(Wz[ht−1,xt]+bz)z_t = \sigma(W_z [h_{t-1}, x_t] + b_z)zt=σ(Wz[ht−1,xt]+bz) - 候选隐藏状态:计算候选隐藏状态 h~t\tilde{h}_th~t。
h~t=tanh(Wh[rt⊙ht−1,xt]+bh)\tilde{h}_t = \tanh(W_h [r_t \odot h_{t-1}, x_t] + b_h)h~t=tanh(Wh[rt⊙ht−1,xt]+bh) - 隐藏状态更新:更新隐藏状态 hth_tht。
ht=(1−zt)⊙ht−1+zt⊙h~th_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_tht=(1−zt)⊙ht−1+zt⊙h~t
使用TensorFlow实现GRU
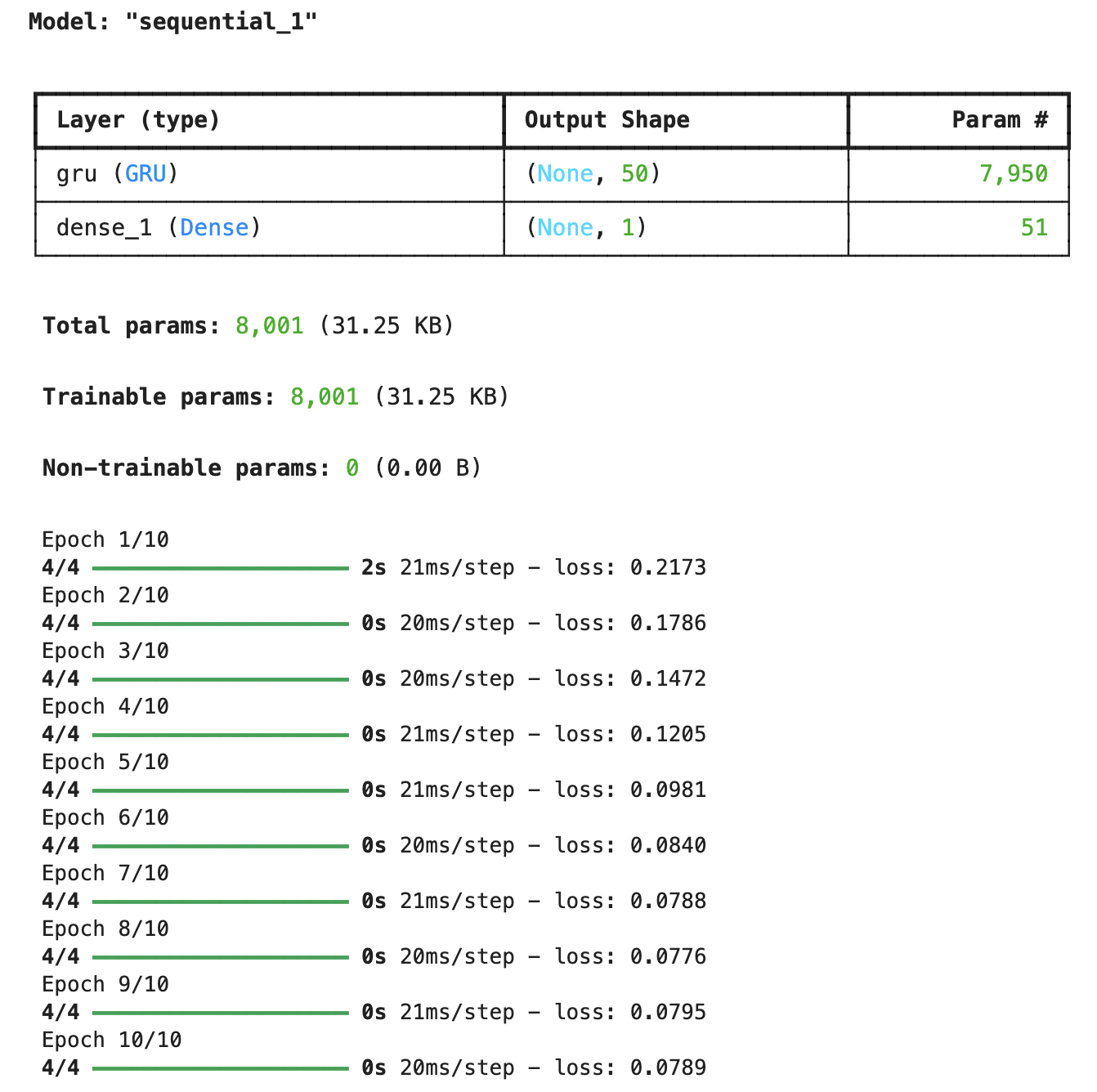
下面是一个使用TensorFlow实现GRU的示例代码:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import GRU, Dense
# 定义模型
model = Sequential()
model.add(GRU(50, activation='relu', input_shape=(10, 1)))
model.add(Dense(1))
# 编译模型
model.compile(optimizer='adam', loss='mse')
# 打印模型结构
model.summary()
# 生成示例数据
import numpy as np
X = np.random.rand(100, 10, 1)
y = np.random.rand(100, 1)
# 训练模型
model.fit(X, y, epochs=10, batch_size=32)
附录
1.LSTM计算过程详解:
要理解这段 LSTM(长短期记忆网络)代码对应的计算过程,需先明确 LSTM 的核心目标——通过门控机制(遗忘门、输入门、输出门) 解决传统 RNN 的梯度消失问题,实现对长序列信息的长期记忆。以下从「符号定义→逐门计算→细胞状态更新→隐藏状态输出」逐步拆解,并结合公式推导计算逻辑。
一、核心符号定义(先明确每个变量的含义)
在计算前,需先理解公式中每个符号代表的对象(以单时间步为例):
| 符号 | 含义说明 | 维度示例(假设) |
|---|---|---|
| xtx_txt | 当前时间步的输入数据(如序列中第 t 个单词的嵌入向量) | (输入特征数, ) = (100, ) |
| ht−1h_{t-1}ht−1 | 上一个时间步(t-1)的隐藏状态(携带历史信息的输出) | (隐藏单元数, ) = (64, ) |
| Ct−1C_{t-1}Ct−1 | 上一个时间步(t-1)的细胞状态(LSTM 的「长期记忆」核心,类似“传送带”) | (隐藏单元数, ) = (64, ) |
| Wf,Wi,WC,WoW_f, W_i, W_C, W_oWf,Wi,WC,Wo | 门控权重矩阵(遗忘门、输入门、候选细胞、输出门各自的权重,可训练参数) | 见下文“参数维度推导” |
| bf,bi,bC,bob_f, b_i, b_C, b_obf,bi,bC,bo | 门控偏置向量(对应上述四门的偏置,可训练参数) | (隐藏单元数, ) = (64, ) |
| σ\sigmaσ | Sigmoid 激活函数(输出范围 [0,1],用于门控“开关”:1=全打开,0=全关闭) | - |
| tanh\tanhtanh | Tanh 激活函数(输出范围 [-1,1],用于压缩数值,避免梯度爆炸) | - |
| ⊙\odot⊙ | 元素-wise 乘法(对应位置元素相乘,而非矩阵乘法) | - |
| ft,it,otf_t, i_t, o_tft,it,ot | 遗忘门、输入门、输出门的输出(门控信号,范围 [0,1]) | (隐藏单元数, ) = (64, ) |
| C~t\tilde{C}_tC~t | 候选细胞状态(当前时间步的新记忆,需通过输入门筛选后加入细胞状态) | (隐藏单元数, ) = (64, ) |
| CtC_tCt | 当前时间步的细胞状态(更新后的长期记忆) | (隐藏单元数, ) = (64, ) |
| hth_tht | 当前时间步的隐藏状态(LSTM 对外部的输出,携带筛选后的当前+历史信息) | (隐藏单元数, ) = (64, ) |
二、逐步骤计算过程(结合公式拆解)
LSTM 的计算围绕「更新长期记忆(细胞状态 CtC_tCt)」和「生成当前输出(隐藏状态 hth_tht)」展开,分为 4 个关键步骤:
步骤 1:遗忘门(决定“丢弃多少历史记忆”)
作用:筛选上一轮细胞状态 Ct−1C_{t-1}Ct−1 中的有用信息——通过 Sigmoid 输出 ftf_tft(0~1),值越接近 1 保留越多历史,越接近 0 丢弃越多。
公式:ft=σ(Wf[ht−1,xt]+bf)f_t = \sigma(W_f [h_{t-1}, x_t] + b_f)ft=σ(Wf[ht−1,xt]+bf)
计算拆解:
- 拼接历史与当前信息:[ht−1,xt][h_{t-1}, x_t][ht−1,xt] 表示将上一轮隐藏状态 ht−1h_{t-1}ht−1(64 维)与当前输入 xtx_txt(100 维)在特征维度拼接,得到拼接向量维度 = 64 + 100 = 164 维。
- 权重与偏置计算:WfW_fWf 是遗忘门的权重矩阵,维度为「隐藏单元数 × 拼接后维度」= 64 × 164(每个隐藏单元对应 1 组权重,作用于拼接向量);bfb_fbf 是偏置向量(64 维,每个隐藏单元 1 个偏置)。
矩阵乘法结果:Wf[ht−1,xt]W_f [h_{t-1}, x_t]Wf[ht−1,xt] 维度 = 64 维,加偏置 bfb_fbf 后仍为 64 维。 - Sigmoid 激活:将上述结果输入 Sigmoid 函数,输出 ftf_tft(64 维,每个元素 ∈ [0,1]),即遗忘门的“开关信号”。
示例:若 ftf_tft 中某元素为 0.9,说明该位置的历史细胞状态 Ct−1C_{t-1}Ct−1 几乎全部保留;若为 0.1,则几乎全部丢弃。
步骤 2:输入门(决定“新增多少当前记忆”)
作用:分两步筛选当前时间步的新信息——先通过输入门 iti_tit 决定“哪些新信息要保留”,再生成候选细胞状态 C~t\tilde{C}_tC~t 作为“待加入的新记忆”。
对应两个公式:
- 输入门开关信号:it=σ(Wi[ht−1,xt]+bi)i_t = \sigma(W_i [h_{t-1}, x_t] + b_i)it=σ(Wi[ht−1,xt]+bi)
- 候选细胞状态:C~t=tanh(WC[ht−1,xt]+bC)\tilde{C}_t = \tanh(W_C [h_{t-1}, x_t] + b_C)C~t=tanh(WC[ht−1,xt]+bC)
计算拆解(以 iti_tit 为例,C~t\tilde{C}_tC~t 逻辑类似):
- 拼接与权重计算:[ht−1,xt][h_{t-1}, x_t][ht−1,xt] 仍为 164 维;WiW_iWi 是输入门权重矩阵(维度 64×164),bib_ibi 是输入门偏置(64 维)。
矩阵乘法 + 偏置:Wi[ht−1,xt]+biW_i [h_{t-1}, x_t] + b_iWi[ht−1,xt]+bi 维度 = 64 维。 - Sigmoid 激活:输出 iti_tit(64 维,∈ [0,1]),值越接近 1 表示该位置的新信息越要保留。
C~t\tilde{C}_tC~t 计算差异:
- 权重矩阵为 WCW_CWC(64×164),偏置为 bCb_CbC(64 维),激活函数改用 Tanh(输出 ∈ [-1,1]),目的是将新信息压缩到合理范围,避免后续计算数值溢出。
- C~t\tilde{C}_tC~t 是“原始新记忆”,需结合 iti_tit 的“开关”才能决定最终加入多少到细胞状态。
步骤 3:细胞状态更新(更新“长期记忆”)
作用:结合遗忘门的“历史筛选”和输入门的“新信息筛选”,更新得到当前时间步的细胞状态 CtC_tCt(LSTM 的核心,长期记忆的载体)。
公式:Ct=ft⊙Ct−1+it⊙C~tC_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_tCt=ft⊙Ct−1+it⊙C~t
计算拆解:
- 保留历史有效信息:ft⊙Ct−1f_t \odot C_{t-1}ft⊙Ct−1(元素-wise 乘法)——遗忘门 ftf_tft 对历史细胞状态 Ct−1C_{t-1}Ct−1 逐元素“筛选”,保留有用的历史记忆。
示例:若 ft[0]=0.8f_t[0] = 0.8ft[0]=0.8、Ct−1[0]=5C_{t-1}[0] = 5Ct−1[0]=5,则该位置保留 0.8×5=40.8×5 = 40.8×5=4 的历史信息。 - 加入当前有效信息:it⊙C~ti_t \odot \tilde{C}_tit⊙C~t(元素-wise 乘法)——输入门 iti_tit 对候选细胞状态 C~t\tilde{C}_tC~t 逐元素“筛选”,保留有用的当前新记忆。
示例:若 it[0]=0.5i_t[0] = 0.5it[0]=0.5、C~t[0]=3\tilde{C}_t[0] = 3C~t[0]=3,则该位置加入 0.5×3=1.50.5×3 = 1.50.5×3=1.5 的新信息。 - 更新细胞状态:将上述两部分相加,得到当前时间步的细胞状态 CtC_tCt(64 维),完成“长期记忆”的更新。
步骤 4:输出门(生成“当前输出”)
作用:从更新后的细胞状态 CtC_tCt 中筛选信息,生成当前时间步的隐藏状态 hth_tht(LSTM 对外的输出,可用于后续预测或传递到下一时间步)。
对应两个公式:
- 输出门开关信号:ot=σ(Wo[ht−1,xt]+bo)o_t = \sigma(W_o [h_{t-1}, x_t] + b_o)ot=σ(Wo[ht−1,xt]+bo)
- 当前隐藏状态:ht=ot⊙tanh(Ct)h_t = o_t \odot \tanh(C_t)ht=ot⊙tanh(Ct)
计算拆解:
- 输出门开关计算:逻辑与遗忘门/输入门一致——[ht−1,xt][h_{t-1}, x_t][ht−1,xt](164 维)× WoW_oWo(64×164) + bob_obo(64 维),经 Sigmoid 激活得到 oto_tot(64 维,∈ [0,1]),即“哪些细胞状态信息要输出”的开关。
- 筛选细胞状态:先将 CtC_tCt 输入 Tanh(压缩到 [-1,1]),再与 oto_tot 做元素-wise 乘法,得到 hth_tht(64 维)。
示例:若 ot[0]=0.6o_t[0] = 0.6ot[0]=0.6、tanh(Ct[0])=0.8\tanh(C_t[0]) = 0.8tanh(Ct[0])=0.8,则 ht[0]=0.6×0.8=0.48h_t[0] = 0.6×0.8 = 0.48ht[0]=0.6×0.8=0.48,即该位置的细胞状态信息以 60% 的比例输出。
三、关键补充:可训练参数维度(以示例维度为例)
LSTM 的可训练参数集中在 4 个门的权重矩阵(Wf,Wi,WC,WoW_f, W_i, W_C, W_oWf,Wi,WC,Wo)和偏置向量(bf,bi,bC,bob_f, b_i, b_C, b_obf,bi,bC,bo),总参数个数计算如下:
假设输入特征数 = 100,隐藏单元数 = 64:
- 每个权重矩阵维度:隐藏单元数 ×(隐藏单元数 + 输入特征数)= 64 × (64 + 100) = 64 × 164 = 10496
- 4 个权重矩阵总参数:4 × 10496 = 41984
- 每个偏置向量维度:隐藏单元数 = 64,4 个偏置总参数:4 × 64 = 256
- LSTM 单时间步总可训练参数:41984 + 256 = 42240
四、总结:LSTM 计算的核心逻辑
LSTM 通过「三门控+一细胞状态」实现对信息的精准筛选与长期记忆,计算流程可简化为:
- 遗忘门:丢历史无用信息 → ftf_tft
- 输入门:选当前有用信息 → iti_tit 和 C~t\tilde{C}_tC~t
- 细胞状态:更新长期记忆 → Ct=ft∗Ct−1+it∗C~tC_t = f_t*C_{t-1} + i_t*\tilde{C}_tCt=ft∗Ct−1+it∗C~t
- 输出门:生成当前输出 → ht=ot∗tanh(Ct)h_t = o_t*\tanh(C_t)ht=ot∗tanh(Ct)
这一过程解决了传统 RNN 中“历史信息随时间步衰减”的问题,让模型能处理更长的序列(如文本、时序数据)。
2.GRU计算过程详解:
GRU(Gated Recurrent Unit,门控循环单元)是 LSTM 的简化版本,通过重置门(Reset门)和更新门**两个核心门控机制,实现对序列信息的选择性记忆与遗忘,同时减少了参数数量,计算更高效。以下结合公式拆解其计算过程,并解释各步骤的作用。
一、核心符号定义(单时间步)
| 符号 | 含义说明 | 维度示例(假设) |
|---|---|---|
| xtx_txt | 当前时间步的输入数据(如序列中第 t 个元素的特征向量) | (输入特征数, ) = (100, ) |
| ht−1h_{t-1}ht−1 | 上一个时间步(t-1)的隐藏状态(携带历史信息的输出) | (隐藏单元数, ) = (64, ) |
| Wr,Wz,WhW_r, W_z, W_hWr,Wz,Wh | 重置门、更新门、候选隐藏状态的权重矩阵(可训练参数) | 见下文“参数维度推导” |
| br,bz,bhb_r, b_z, b_hbr,bz,bh | 重置门、更新门、候选隐藏状态的偏置向量(可训练参数) | (隐藏单元数, ) = (64, ) |
| σ\sigmaσ | Sigmoid 激活函数(输出范围 [0,1],用于门控“开关”) | - |
| tanh\tanhtanh | Tanh 激活函数(输出范围 [-1,1],用于压缩数值) | - |
| ⊙\odot⊙ | 元素-wise 乘法(对应位置元素相乘) | - |
| rtr_trt | 重置门输出(控制“是否遗忘历史信息”,值越接近 0 越倾向于忽略历史) | (隐藏单元数, ) = (64, ) |
| ztz_tzt | 更新门输出(控制“历史信息与新信息的融合比例”,值越接近 1 越倾向于新信息) | (隐藏单元数, ) = (64, ) |
| h~t\tilde{h}_th~t | 候选隐藏状态(基于筛选后的历史信息和当前输入计算的新状态) | (隐藏单元数, ) = (64, ) |
| hth_tht | 当前时间步的隐藏状态(GRU 的输出,传递到下一时间步或用于预测) | (隐藏单元数, ) = (64, ) |
二、逐步骤计算过程(结合公式)
GRU 的计算核心是通过两个门控信号动态调整历史信息与当前信息的融合比例,最终生成当前隐藏状态,分为 4 个步骤:
步骤 1:重置门(筛选历史信息)
作用:决定“是否需要忽略上一时间步的隐藏状态 ht−1h_{t-1}ht−1”——通过 rtr_trt 控制历史信息的保留比例,rtr_trt 越接近 0,越倾向于“忘记”历史,仅用当前输入计算新状态。
公式:rt=σ(Wr[ht−1,xt]+br)r_t = \sigma(W_r [h_{t-1}, x_t] + b_r)rt=σ(Wr[ht−1,xt]+br)
计算拆解:
- 拼接历史与当前信息:[ht−1,xt][h_{t-1}, x_t][ht−1,xt] 是上一轮隐藏状态 ht−1h_{t-1}ht−1(64 维)与当前输入 xtx_txt(100 维)的特征拼接,维度 = 64 + 100 = 164 维。
- 权重与偏置计算:WrW_rWr 是重置门的权重矩阵,维度为「隐藏单元数 × 拼接后维度」= 64 × 164(每个隐藏单元对应一组权重);brb_rbr 是偏置向量(64 维)。
矩阵乘法结果:Wr[ht−1,xt]W_r [h_{t-1}, x_t]Wr[ht−1,xt] 维度为 64 维,加偏置 brb_rbr 后仍为 64 维。 - Sigmoid 激活:输出 rtr_trt(64 维,每个元素 ∈ [0,1]),即重置门的“筛选信号”。
示例:若 rtr_trt 中某元素为 0.2,说明该位置的历史隐藏状态 ht−1h_{t-1}ht−1 仅保留 20%;若为 0.9,则保留 90%。
步骤 2:更新门(控制新旧信息融合比例)
作用:决定“上一时间步的隐藏状态 ht−1h_{t-1}ht−1 与当前候选状态 h~t\tilde{h}_th~t 的融合权重”——ztz_tzt 越接近 1,当前隐藏状态 hth_tht 越依赖新信息(h~t\tilde{h}_th~t);越接近 0,越依赖历史信息(ht−1h_{t-1}ht−1)。
公式:zt=σ(Wz[ht−1,xt]+bz)z_t = \sigma(W_z [h_{t-1}, x_t] + b_z)zt=σ(Wz[ht−1,xt]+bz)
计算拆解:
- 逻辑与重置门完全一致:[ht−1,xt][h_{t-1}, x_t][ht−1,xt](164 维)× WzW_zWz(64×164 权重矩阵) + bzb_zbz(64 维偏置),经 Sigmoid 激活得到 ztz_tzt(64 维,∈ [0,1])。
步骤 3:候选隐藏状态(计算新信息)
作用:基于“重置门筛选后的历史信息”和“当前输入”,计算当前时间步的候选隐藏状态 h~t\tilde{h}_th~t(代表“新信息”)。
公式:h~t=tanh(Wh[rt⊙ht−1,xt]+bh)\tilde{h}_t = \tanh(W_h [r_t \odot h_{t-1}, x_t] + b_h)h~t=tanh(Wh[rt⊙ht−1,xt]+bh)
计算拆解:
- 筛选历史信息:rt⊙ht−1r_t \odot h_{t-1}rt⊙ht−1(元素-wise 乘法)——用重置门 rtr_trt 对上一轮隐藏状态 ht−1h_{t-1}ht−1 进行筛选,得到“需要保留的历史信息”(64 维)。
- 拼接筛选后的历史与当前输入:[rt⊙ht−1,xt][r_t \odot h_{t-1}, x_t][rt⊙ht−1,xt] 是筛选后的历史信息(64 维)与当前输入 xtx_txt(100 维)的拼接,维度 = 64 + 100 = 164 维。
- 权重与偏置计算:WhW_hWh 是候选状态的权重矩阵(64×164),bhb_hbh 是偏置向量(64 维),矩阵乘法 + 偏置后结果为 64 维。
- Tanh 激活:输出 h~t\tilde{h}_th~t(64 维,∈ [-1,1]),即基于筛选后历史和当前输入计算的“新状态候选”。
步骤 4:隐藏状态更新(融合新旧信息)
作用:根据更新门 ztz_tzt 的权重,将历史隐藏状态 ht−1h_{t-1}ht−1 与候选隐藏状态 h~t\tilde{h}_th~t 融合,得到当前时间步的隐藏状态 hth_tht。
公式:ht=(1−zt)⊙ht−1+zt⊙h~th_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_tht=(1−zt)⊙ht−1+zt⊙h~t
计算拆解:
- 公式可理解为“加权平均”:
- (1−zt)⊙ht−1(1 - z_t) \odot h_{t-1}(1−zt)⊙ht−1:历史信息的保留部分(1−zt1 - z_t1−zt 是历史信息的权重)。
- zt⊙h~tz_t \odot \tilde{h}_tzt⊙h~t:新信息的保留部分(ztz_tzt 是新信息的权重)。
- 两者相加得到 hth_tht(64 维),完成隐藏状态的更新。
示例:若 zt[0]=0.7z_t[0] = 0.7zt[0]=0.7,则该位置的 ht[0]=0.3×ht−1[0]+0.7×h~t[0]h_t[0] = 0.3×h_{t-1}[0] + 0.7×\tilde{h}_t[0]ht[0]=0.3×ht−1[0]+0.7×h~t[0],即主要依赖新信息。
三、GRU 与 LSTM 的对比及参数计算
与 LSTM 的核心区别:
- GRU 用 2 个门(重置门、更新门)替代 LSTM 的 3 个门,且没有单独的“细胞状态”,直接通过隐藏状态 hth_tht 传递信息,结构更简洁。
- 减少了参数数量(比 LSTM 少约 1/3),训练速度更快,适合数据量有限或对效率要求高的场景。
可训练参数计算(示例维度):
假设输入特征数 = 100,隐藏单元数 = 64:
- 每个权重矩阵维度:隐藏单元数 ×(隐藏单元数 + 输入特征数)= 64 × 164 = 10496
- 3 个权重矩阵(Wr,Wz,WhW_r, W_z, W_hWr,Wz,Wh)总参数:3 × 10496 = 31488
- 3 个偏置向量(br,bz,bhb_r, b_z, b_hbr,bz,bh)总参数:3 × 64 = 192
- GRU 单时间步总可训练参数:31488 + 192 = 31680
四、总结
GRU 的计算逻辑可简化为:
- 重置门(rtr_trt):筛选需要保留的历史信息 → 决定“用多少历史算新信息”。
- 更新门(ztz_tzt):决定历史信息与新信息的融合比例 → “历史留多少,新信息加多少”。
- 候选状态(h~t\tilde{h}_th~t):基于筛选后的历史和当前输入,计算新信息。
- 隐藏状态(hth_tht):按更新门的权重融合历史与新信息,输出当前状态。
通过这种机制,GRU 在保持对长序列建模能力的同时,实现了更高效的计算,是时序数据(如文本、语音、时间序列)建模的常用选择。


















 4782
4782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









