



张量介绍
学习目标
通过本课程,学员将通过直接从数据、从 NumPy 数组、从另一个张量以及使用随机或常量值等不同方式初始化张量,全面了解张量的基本概念和特性。学员将学习如何查看和理解张量的形状、数据类型及存储设备等属性信息,掌握张量在 CPU 和加速器上的操作方法,包括索引、切片、连接以及算术运算等操作,并理解原地操作的内存节省优势及潜在风险。此外,学员还将深入探究张量与 NumPy 数组之间的桥梁作用,实现两者之间的高效转换与共享内存操作。
相关知识点
- 张量介绍
学习内容
1 张量介绍
张量是一种专门的数据结构,与数组和矩阵非常相似。在 PyTorch 中,我们使用张量来编码模型的输入和输出,以及模型的参数。
张量与 NumPy 的 ndarrays 类似,但张量可以在 GPU 或其他硬件加速器上运行。事实上,张量和NumPy数组通常可以共享相同的基本内存,从而无需复制数据。张量还针对自动微分进行了优化(我们将在稍后的Autograd部分了解更多)。如果你熟悉ndarrays,你将很快熟悉张量API。如果不熟悉,请继续跟随!
1.1 初始化张量
import torch
import torch_npu
import numpy as np
注意:#没有NPU的可以不用引入,默认会使用CPU,MacBook AMD GPU芯片可以使用mps
张量可以通过多种方式初始化。查看以下示例:
直接从数据创建
张量可以直接从数据创建。数据类型会自动推断。
data = [[1, 2],[3, 4]]
x_data = torch.tensor(data)
从 NumPy 数组
张量可以从 NumPy 数组创建
np_array = np.array(data)
x_np = torch.from_numpy(np_array)
从另一个张量
新张量保留参数张量的属性(形状、数据类型),除非明确覆盖。
x_ones = torch.ones_like(x_data) # retains the properties of x_data
print(f"Ones Tensor: \n {x_ones} \n")
x_rand = torch.rand_like(x_data, dtype=torch.float) # overrides the datatype of x_data
print(f"Random Tensor: \n {x_rand} \n")
使用随机或常量值:
shape 是一个包含张量维度的元组。在下面的函数中,它决定了输出张量的维数。
shape = (2,3,)
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)
print(f"Random Tensor: \n {rand_tensor} \n")
print(f"Ones Tensor: \n {ones_tensor} \n")
print(f"Zeros Tensor: \n {zeros_tensor}")
1.2 张量的属性
张量属性描述了它们的形状、数据类型以及它们存储的设备。
tensor = torch.rand(3,4)
print(f"Shape of tensor: {tensor.shape}")
print(f"Datatype of tensor: {tensor.dtype}")
print(f"Device tensor is stored on: {tensor.device}")
1.3 张量操作
这里全面介绍了超过 1200 种张量操作,包括算术、线性代数、矩阵操作(转置、索引、切片)、采样等。
这些操作可以在 CPU 和加速器(如NPU、CUDA、MPS、MTIA 或 XPU)上运行。如果你使用的是 Colab,可以通过转到“运行时”>“更改运行时类型”>“GPU”来分配加速器。
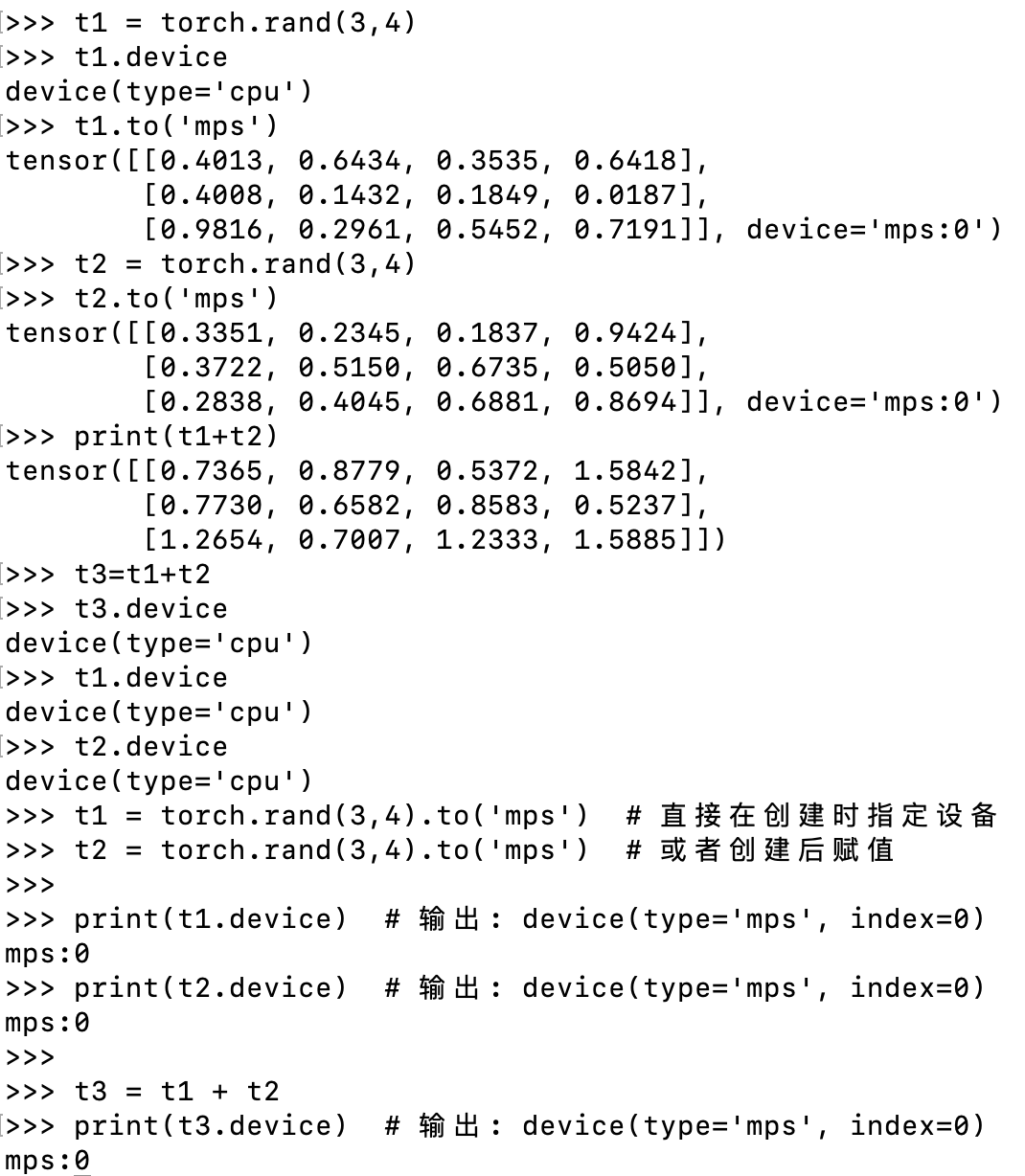
默认情况下,张量在 CPU 上创建。我们需要使用 .to 方法显式地将张量移动到加速器上(在检查加速器可用性之后)。请注意,跨设备复制大张量在时间和内存方面可能非常昂贵!
# We move our tensor to npu
tensor = tensor.to('npu:0')
尝试使用列表中的一些操作。如果你熟悉 NumPy API,你会发现 Tensor API 非常容易使用。
标准的 numpy 样式的索引和切片:
tensor = torch.ones(4, 4)
print(f"First row: {tensor[0]}")
print(f"First column: {tensor[:, 0]}")
print(f"Last column: {tensor[..., -1]}")
tensor[:,1] = 0
print(tensor)
连接张量 可以使用 torch.cat 来沿着给定维度连接一系列张量。另请参见 torch.stack,这是另一个与 torch.cat 微妙不同的张量连接操作符。
t1 = torch.cat([tensor, tensor, tensor], dim=1)
print(t1)
算术运算
# This computes the matrix multiplication between two tensors. y1, y2, y3 will have the same value
# ``tensor.T`` returns the transpose of a tensor
y1 = tensor @ tensor.T
y2 = tensor.matmul(tensor.T)
y3 = torch.rand_like(y1)
torch.matmul(tensor, tensor.T, out=y3)
# This computes the element-wise product. z1, z2, z3 will have the same value
z1 = tensor * tensor
z2 = tensor.mul(tensor)
z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3)
单元素张量 如果你有一个单元素张量,例如通过聚合张量的所有值到一个值,你可以使用 item() 将其转换为 Python 数值::
agg = tensor.sum()
agg_item = agg.item()
print(agg_item, type(agg_item))
原地操作 将结果存储到操作数的操作称为原地操作。它们用 _ 后缀表示。例如: x.copy_(y), x.t_(), 将改变 x.
print(f"{tensor} \n")
tensor.add_(5)
print(tensor)
原地操作可以节省一些内存,但在计算导数时可能会因为立即丢失历史记录而出现问题。因此,不建议使用它们。
1.4 与 NumPy 的桥梁
CPU 上的张量和 NumPy 数组可以共享它们的底层内存位置,改变其中一个会改变另一个。
t = torch.ones(5)
print(f"t: {t}")
n = t.numpy()
print(f"n: {n}")
张量的变化会反映在 NumPy 数组中。
t.add_(1)
print(f"t: {t}")
print(f"n: {n}")
NumPy 数组转换为张量。
n = np.ones(5)
t = torch.from_numpy(n)
NumPy 数组的变化会反映在张量上。
np.add(n, 1, out=n)
print(f"t: {t}")
print(f"n: {n}")



















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









