




学习参考UP主 我是土堆
0. 快速掌握新函数
1)关注输入和输出,查看官方文档
2)查看文档,看需要输入的参数
def __init__(self, mean, std, inplace=False):
这里需要输入的是mean和std,inplace有默认值
3)然后就查看参数Args,确认输入的参数数据类型

4)不知道返回值的时候,运行后用print()查看或者打断点调试查看
1. TensorBoard
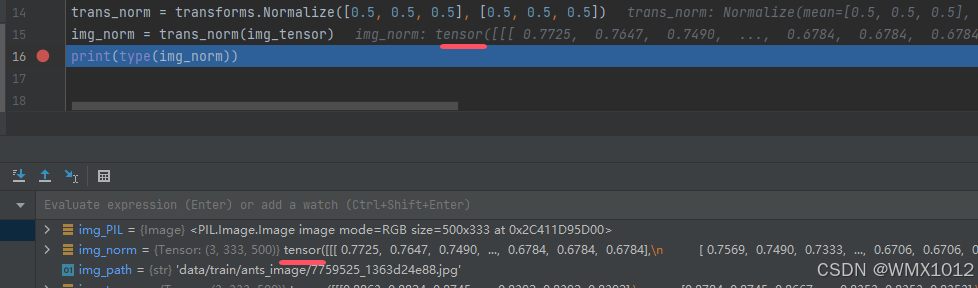
add_image()
add_scalar()
标题 纵轴 横轴
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs") # 创建一个logs文件夹,writer写的文件都在该文件夹下
image_path = "data/train/ants_image/6240329_72c01e663e.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL) #将格式转换为numpy.array形式
print(type(img_array)) # <class 'numpy.ndarray'>
print(img_array.shape) # (369, 500, 3)
# 标题 纵轴 横轴
# add_image()函数的shape默认设置为'CHW'形式,此出需要通过dataformats进行修改
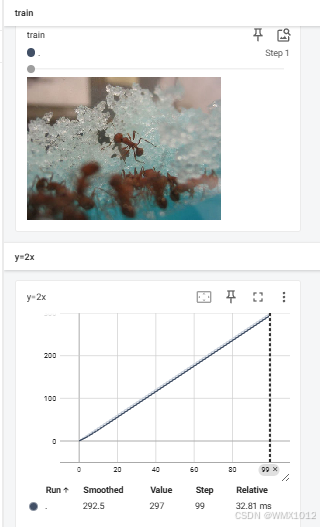
writer.add_image("train", img_array, 1, dataformats='HWC')
# y = 3x
for i in range(100):
writer.add_scalar("y=3x", 3*i, i)
writer.close()
在pycharm终端输入代码,查看日志显示
tensorboard --logdir=D:\00_learn\learn\logs
日志显示结果:
2. transforms
transforms可以看成是一个工具箱,里面的class就是不同的工具
把一些特定类型的图片转换成我们想要的结果
1)transforms.ToTensor()
可以将PIL和、ndarray类型图片转换为tensor类型
2)Normalize
归一化处理
3)Resize
设置图片大小
4)Compose
将多个转换组合到一起 ,这里将ToTensor和Resize组合在一起
5)RandomCrop
在任意位置裁剪图像
代码如下:
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
img_path = "images/rabbit.jpg"
img_PIL = Image.open(img_path)
# img_PIL = Image.open(img_path).convert("RGB") # 将图片转为RGB三通道格式
writer = SummaryWriter("logs")
# ToTensor
# 可以将PIL和、ndarray类型图片转换为tensor类型
trans_tensor = transforms.ToTensor()
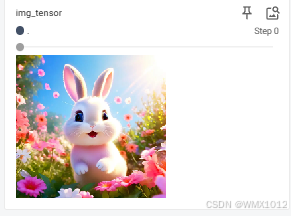
img_tensor = trans_tensor(img_PIL)
print(img_tensor)
writer.add_image("img_tensor", img_tensor)
# Normalize
# 第0层第0行第0列
print(img_tensor[0][0][0])
# 计算方式``output[channel] = (input[channel] - mean[channel]) / std[channel]``
# mean:每个通道的均值序列 std:每个通道的标准差序列
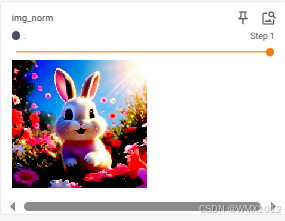
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("img_norm", img_tensor, 0)
writer.add_image("img_norm", img_norm, 1)
# Resize
print(img_PIL.size)
# 图片设置为512*512大小
trans_resize = transforms.Resize((512, 512))
img_resize = trans_resize(img_PIL)
# 将PIL类型转为tensor类型
img_resize = trans_tensor(img_resize)
print(img_resize)
writer.add_image("Resize", img_tensor, 0)
writer.add_image("Resize", img_resize, 1)
# Compose
trans_compose = transforms.Compose([trans_resize, trans_tensor])
img_resize2 = trans_compose(img_PIL)
writer.add_image("Resize", img_resize2, 2)
# RandomCrop
trans_random = transforms.RandomCrop(100)
trans_compose2 = transforms.Compose([trans_random, trans_tensor])
for i in range(10):
img_random = trans_compose2(img_PIL)
writer.add_image("RandomCrop", img_random, i)
writer.close()
日志显示结果:
totensor
normalize
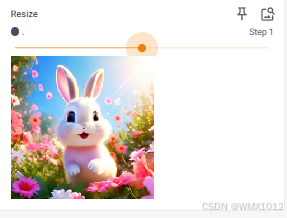
resize
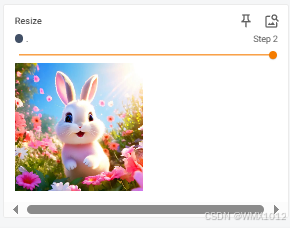
compose
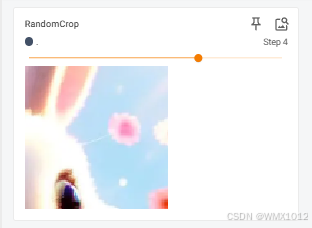
RandomCrop
3. DataLoader
1)torchvision数据集
2)DataLoader是在数据集中抓取数据
从test_set取出batch_size个数据,shuffle=True每轮取出数据不同,
drop_last=True最后一步中,图片的数量比我们设置的batch_size值小,则最后一步省去
test_set 数据集
batch_size=64 抓取图片数量
shuffle=True 每轮取出数据不同
num_workers=0
drop_last=True 最后一次抓取,若图片的数量比我们设置batch_size值小,则最后一步省去
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
trans_dataset = transforms.ToTensor()
# 下载数据集, 数据集是PIL类型,需要转为tensor类型
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=trans_dataset, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=trans_dataset, download=True)
# 测试数据集中第一张图片及target
img, target = test_set[0]
print(img.shape)
print(target)
# 从test_set取出batch_size个数据,shuffle=True每轮取出数据不同,
# drop_last=True最后一步中,图片的数量比我们设置的batch_size值小,则最后一步省去
test_loader = DataLoader(test_set, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
writer = SummaryWriter("dataloader")
# 取出2轮
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape) #torch.Size([64, 3, 32, 32])
# print(targets)
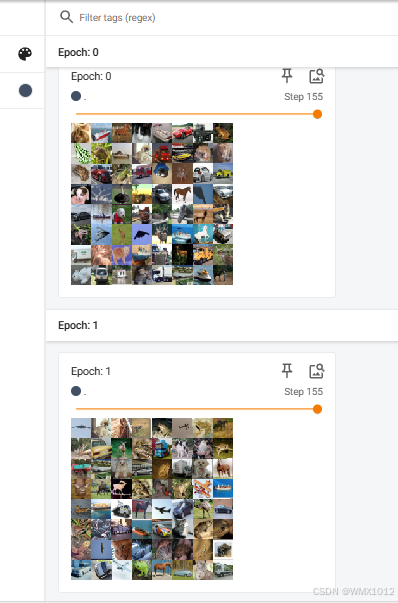
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()
日志显示结果:
4. 神经网络
4.1 卷积操作
torch.nn.functional.conv2d()
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 卷积核(权值)
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# 改变给定张量的形状,而不改变其数据和元素总数,此处是将input改为四维张量
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
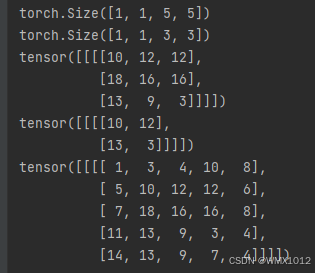
print(input.shape)
print(kernel.shape)
# 卷积计算,stride=1卷积核每次移动距离为1,padding在输入边缘填充
output = F.conv2d(input, kernel, stride=1)
print(output)
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)
输出为:
4.2 卷积层
in_channels 输入通道
out_channels=6 输出通道
kernel_size=3 卷积核大小
stride=1 卷积核窗口滑动步长
padding=0 填充大小
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_set = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(test_set, batch_size=64)
class Learn(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
learn = Learn()
writer = SummaryWriter("./logs")
step = 0
for data in dataloader:
imgs, targets = data
output = learn(imgs)
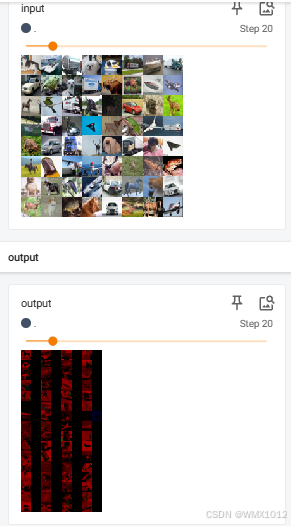
print(imgs.shape) # torch.Size([64, 3, 32, 32])
print(output.shape)
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30]
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = step + 1
writer.close()
日志显示结果:
4.3 最大池化
不改变通道数
保留特征,减少数据量
kernel_size:池化核窗口大小
stride:移动的步长,默认值是kernel_size
padding:输入的每一条边补充0的层数
ceil_mode:为True时,池化核没有完全覆盖图像,找一个最大值。为False丢弃
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, download=False,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Learn(nn.Module):
def __init__(self):
super(Learn, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpool1(input)
return output
learn = Learn()
writer = SummaryWriter("./logs_maxpool")
step = 0
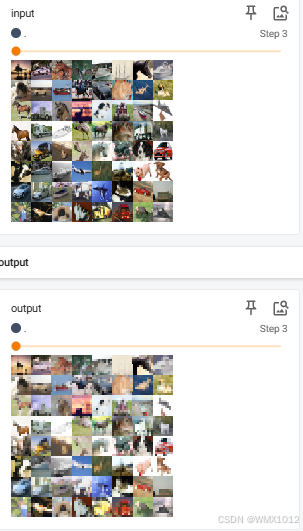
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = learn(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
日志显示结果:
4.4 非线性激活函数
在网络中引入非线性,更容易训练出符合特征的模型
ReLU()
inplace = False: 默认不改变输入值
Sigmoid() 这里图片用Sigmoid()进行效果展示
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, download=False,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Learn(nn.Module):
def __init__(self):
super(Learn, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
learn = Learn()
writer = SummaryWriter("./logs_relu")
step = 0
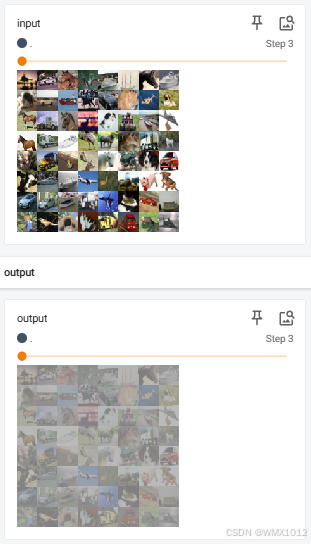
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, global_step=step)
output = learn(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()
日志显示结果:
4.5 线性层及其它层
变换特征维度
flatten(): 将数据展开成一维
BathNorm2d: 批量归一化
Recurrent: 用于文字识别
Transformer: 注意力机制
Dropout: 防止过拟合
Sparse: 用于自然语言
Distance Functions: 误差
Loss Functions
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, download=False,
transform=torchvision.transforms.ToTensor(),
)
dataloader = DataLoader(dataset, batch_size=64, drop_last=True)
class Learn(nn.Module):
def __init__(self):
super(Learn, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
learn = Learn()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
output = torch.flatten(imgs)
print(output.shape)
output = learn(output)
print(output.shape)
代码运行后部分结果如下:
torch.Size([64, 3, 32, 32])
torch.Size([196608])
torch.Size([10])
5.6 搭建神经网络及Sequential的使用
CIFAR10 model 模型结构如图所示:
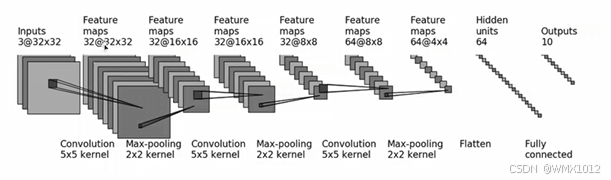
展示模型每层结构
add_graph(learn, input)
Sequential() 使模型结构易于管理,代码更简洁
代码实现如下:
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.tensorboard import SummaryWriter
class Learn(nn.Module):
def __init__(self):
super(Learn, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
learn = Learn()
print(learn)
input = torch.ones((64, 3, 32, 32))
output = learn(input)
print(output.shape)
writer = SummaryWriter("./logs_seq")
writer.add_graph(learn, input)
writer.close()
日志显示结果(Learn模型可以展开查看每层输入输出大小):
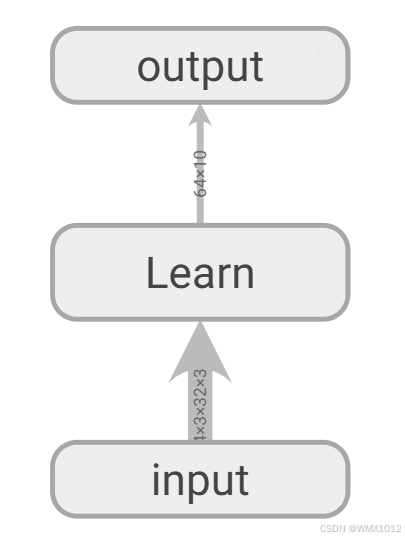
5.7 损失函数与反向传播
损失函数:注意输入与输出大小
计算实际输出与目标值之间的差距,为更新输出提供依据(梯度grad)
5.7.1 新建矩阵作为输入
实现效果如图所示:
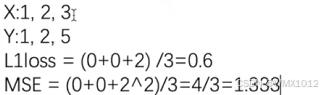
计算是四维NCHW,所以用了reshape函数
代码实现如下:
import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
# 差值求和
loss1_sum = L1Loss(reduction='sum')
result1_sum = loss1_sum(inputs, targets)
print(result1_sum)
# 差值求和后再平均
loss1 = L1Loss()
result1 = loss1(inputs, targets)
print(result1)
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)
print(result_mse)
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)
运行结果如下:
tensor(2.)
tensor(0.6667)
tensor(1.3333)
tensor(1.1019)
5.7.2 用图片作为输入
用上一小节的网络结构
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./data", train=False,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=1)
class Learn(nn.Module):
def __init__(self):
super(Learn, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
learn = Learn()
for data in dataloader:
imgs, targets = data
outputs = learn(imgs)
result_loss = loss(outputs, targets)
print(result_loss)
result_loss.backward()
print("ok")
代码运行后部分结果如下:
tensor(2.3045, grad_fn=< NllLossBackward0>)
5.7.2 反向传播(查看梯度grad)
在这行代码result_loss.backward()打断点,Debug运行
若没有这行代码,梯度将没有值
找到模型learn
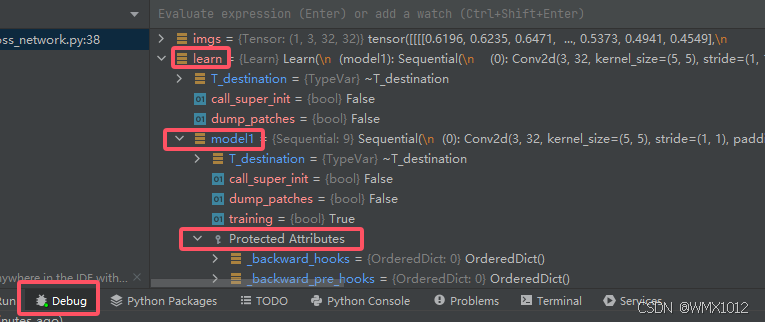
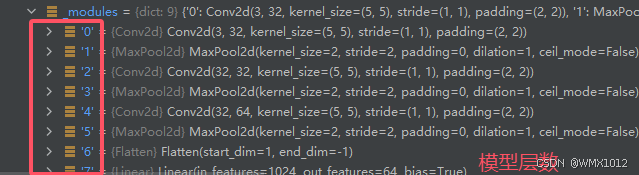
点开其中某一层,找到weight->grad
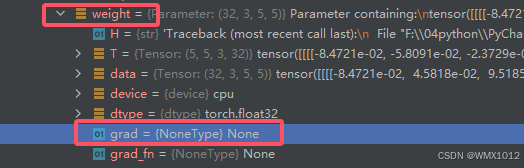
data是权重参数
grad是梯度值
点击运行下一步
即可查看梯度grad大小

5.8 优化器
梯度清零
反向传播
优化参数
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, download=False,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=1)
class Learn(nn.Module):
def __init__(self):
super(Learn, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
learn = Learn()
optim = torch.optim.SGD(learn.parameters(), lr=0.01) # 建立优化器, 学习率调小,更容易收敛
for epoch in range(20): # 训练20轮
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = learn(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad() # 梯度清零
result_loss.backward() # 获得梯度值
optim.step() # 对权重矩阵参数调优
running_loss = running_loss + result_loss
print(f'第{epoch+1}轮误差为{ running_loss}')
可在以下三行代码处打断点,查看权重参数和梯度值的变化
optim.zero_grad() # 梯度清零
result_loss.backward() # 获得梯度值
optim.step() # 对权重矩阵参数调优
代码运行后部分结果如下:
第1轮误差为18782.328125
第2轮误差为16135.9482421875
第3轮误差为15389.71875
6. 现有网络模型
6.1 下载数据集
在pytorch官网上查看想要的数据集
ImageNet数据集官网
这个数据集的下载可参考博文
import torchvision
train_data = torchvision.datasets.ImageNet("./data_image_net", split='train', download=True,
transform=torchvision.transforms.ToTensor())
运行出错
RuntimeError: The archive ILSVRC2012_devkit_t12.tar.gz is not present in the root directory or is corrupted. You need to download it externally and place it in ./data_image_net.
需要在网上搜索ImageNet数据集,下载在该路径里
6.2 现有网络模型使用及修改
模型默认下载地址
C:\Users\PC/.cache\torch\hub\checkpoints\vgg16-397923af.pth
修改下载路径的方法:
import os
os.environ['TORCH_HOME'] = r"新地址"
1)添加模型层数
import torchvision
from torch import nn
vgg16_true = torchvision.models.vgg16(weights=torchvision.models.VGG16_Weights.DEFAULT) # 下载vgg16模型(参数已训练好)
print(vgg16_true)
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_true)
代码运行后部分结果如下:
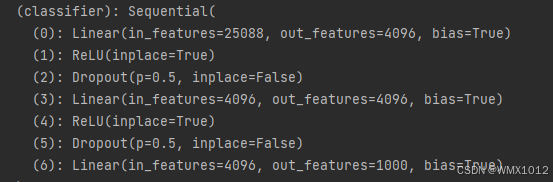
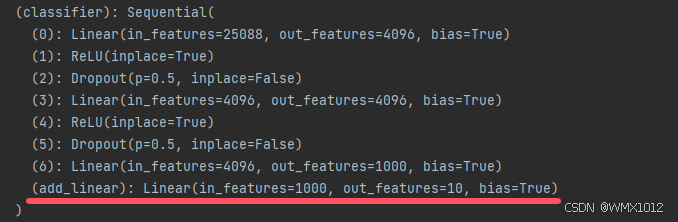
2)修改模型层数
import torchvision
from torch import nn
vgg16_false = torchvision.models.vgg16(weights=None) # 下载vgg16模型(初始参数)
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
代码运行后部分结果如下:
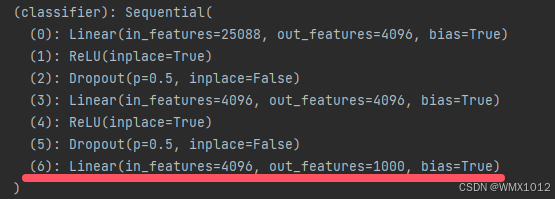
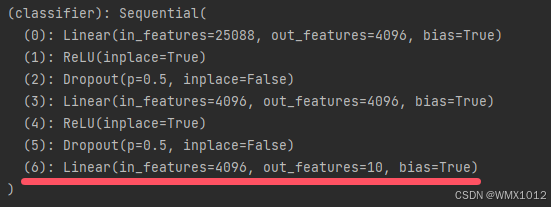
6.3 现有网络模型保存及读取
1)保存
import torch
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16(weights=None)
# 保存方式1,模型结构+模型参数
torch.save(vgg16, "vgg16_method1.pth")
# 保存方式2,模型参数(官方推荐)
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
# 陷阱(保存方式1)
class Learn(nn.Module):
def __init__(self):
super(Learn, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
learn =Learn()
torch.save(learn, "learn_method1.pth")
2)读取(与上述保存方式一 一对应)
import torch
# from model_save import *
# 方式1-》保存方式1,加载模型
import torchvision
from torch import nn
model1 = torch.load("vgg16_method1.pth")
print(model1)
# 方式2,加载模型
model2 = torchvision.models.vgg16(pretrained=False)
model2.load_state_dict(torch.load("vgg16_method2.pth"))
print(model2)
# 陷阱(保存方式1)
class Learn(nn.Module):
def __init__(self):
super(Learn, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
# 加载此模型时需要将模型结构放在此文件里,或者导入from model_save import *
model3 = torch.load('learn_method1.pth')
print(model3)
7. 模型训练套路
以CIFAR10 数据集为例,模型结构与5.6小结一致
7.1 建立model.py文件
model.py文件
import torch
from torch import nn
# 搭建神经网络
class Learn(nn.Module):
def __init__(self):
super(Learn, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == '__main__':
# 测试模型输出大小是否正确
learn = Learn()
input = torch.ones((64, 3, 32, 32))
output = learn(input)
print(output.shape)
7.2 建立train.py文件
代码解释:
1)loss.item()
loss.item() # 结果为loss真实值
loss() # 结果为loss的tensor类型值
2)argmax()
返回第一个最大值的索引
argmax(1) # 按行计算
argmax(0) # 按列计算
import torch
outputs = torch.tensor([[0.1, 0.2],
[0.3, 0.4]])
print(outputs.argmax(1)) #tensor([1, 1])
preds = outputs.argmax(1)
targets = torch.tensor([0, 1])
print(preds == targets) #tensor([False, True])
print((preds == targets).sum()) #tensor(1)
3)本次示例中没有learn.train()和learn.eval(),也不影响结果
因为train()和eval()只在有Dropout和BatchNorm层有作用
learn.train()
learn.eval()
4)with torch.no_grad():
使用with torch.no_grad():表明当前计算不需要反向传播
示例中测试数据集时不需要反向传播
train.py文件:
import torchvision
from torch.utils.tensorboard import SummaryWriter
# 导入模型
from model import *
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
learn = Learn()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(learn.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("./logs_train")
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i+1))
# 训练步骤开始
learn.train()
for data in train_dataloader:
imgs, targets = data
outputs = learn(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
learn.eval()
total_test_loss = 0
# 每轮测试时正确的次数
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = learn(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy.item()
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(learn, "learn_{}.pth".format(i+1))
print("模型已保存")
writer.close()
日志显示结果:
深色线平滑处理,浅色线真实值
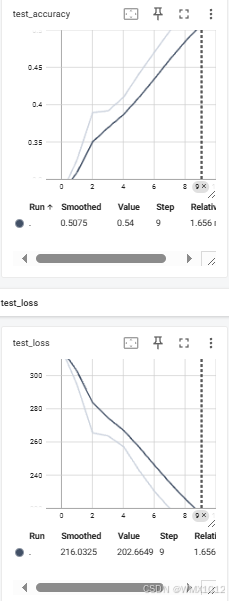
7.3 利用GPU训练
7.3.1 .cuda()
找到以下三种变量,再调用.cuda()即可
网络模型
learn = Learn()
if torch.cuda.is_available():
tudui = learn .cuda()
数据(输入,标注)
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
损失函数
loss_fn = nn.CrossEntropyLoss()
torch.cuda.is_available():
loss_fn = loss_fn.cuda()
为了方便比较用时,这里将网络模型复制到了训练文件里
train_gpu1文件:
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
import time
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Learn(nn.Module):
def __init__(self):
super(Learn, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
learn = Learn()
if torch.cuda.is_available():
tudui = learn .cuda()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(learn.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("./logs_train")
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i+1))
start_time = time.time()
# 训练步骤开始
learn.train()
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = learn(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
end_time = time.time()
print(f"训练时长为{end_time-start_time}")
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
learn.eval()
total_test_loss = 0
# 每轮测试时正确的次数
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = learn(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy.item()
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(learn, "learn_{}.pth".format(i+1))
print("模型已保存")
writer.close()
代码运行部分结果如下:
-------第 1 轮训练开始-------
训练次数:100, Loss: 2.29361629486084
训练时长为0.7722277641296387
7.3.2 .to(device)推荐使用_方便修改运行设备
1)先定义训练设备
device = torch.device("cuda")
#device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 这行代码更常用
2)找到以下三种变量,再调用.to(device)即可
网络模型
learn = Learn()
learn = learn.to(device)
#learn.to(device) #这行代码与上行代码等效
数据(输入,标注)
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
#loss_fn.to(device) #这行代码与上行代码等效
为了方便比较用时,这里将网络模型复制到了训练文件里
train_gpu2文件:
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
import time
from torch import nn
from torch.utils.data import DataLoader
# 定义训练的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Learn(nn.Module):
def __init__(self):
super(Learn, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
learn = Learn()
learn = learn.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(learn.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("./logs_train")
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i+1))
start_time = time.time()
# 训练步骤开始
learn.train()
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = learn(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
end_time = time.time()
print(f"训练时长为{end_time-start_time}")
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
learn.eval()
total_test_loss = 0
# 每轮测试时正确的次数
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = learn(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy.item()
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(learn, "learn_{}.pth".format(i+1))
print("模型已保存")
writer.close()
代码运行部分结果如下:
cuda
Files already downloaded and verified
Files already downloaded and verified
训练数据集的长度为:50000
测试数据集的长度为:10000
-------第 1 轮训练开始-------
训练次数:100, Loss: 2.3054232597351074
训练时长为0.47981905937194824
7.4 验证已经训练好的模型
7.4.1 查看分类
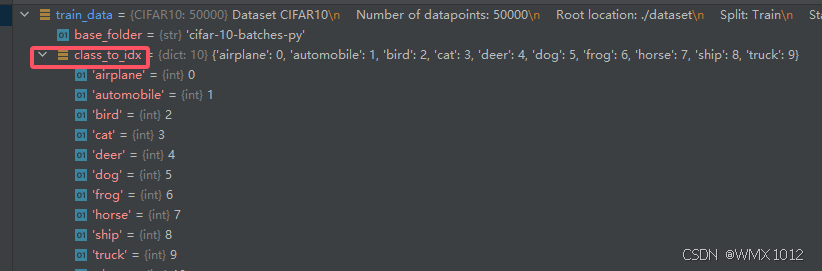
1)在train.py文件里打断点,Debug运行

2)
7.4.1 验证
这里是将训练时下载的模型进行验证
test.py
import torch
import torchvision
from PIL import Image
from torch import nn
image_path = "./images/dog.jpg"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class Learn(nn.Module):
def __init__(self):
super(Learn, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model = torch.load("learn_20_gpu.pth", map_location=torch.device('cpu'))
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
8. 开源项目
github
1)阅读README
2)看项目结构,先看train.py
数据集



















 37万+
37万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









