




 该论文对比了ResNet、纯Transformer模型ViT及混合模型Hybrid在图像识别任务上的表现。ViT通过将图像划分为patches并转换为线性向量,然后输入Transformer编码器进行处理。实验表明,ViT在大量训练样本下优于Hybrid。论文提供了ViT模型的详细结构和参数配置,包括Embedding层、TransformerEncoder层和MLPHead层。
该论文对比了ResNet、纯Transformer模型ViT及混合模型Hybrid在图像识别任务上的表现。ViT通过将图像划分为patches并转换为线性向量,然后输入Transformer编码器进行处理。实验表明,ViT在大量训练样本下优于Hybrid。论文提供了ViT模型的详细结构和参数配置,包括Embedding层、TransformerEncoder层和MLPHead层。
论文: An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
论文下载:https://arxiv.org/abs/2010.11929
原论文源码:https://github.com/google-research/vision_transformer
文章目录
摘要
在这篇文章中,作者主要拿ResNet、ViT(纯Transformer模型)以及Hybrid(卷积和Transformer混合模型)三个模型进行比较。
Vision Transformer
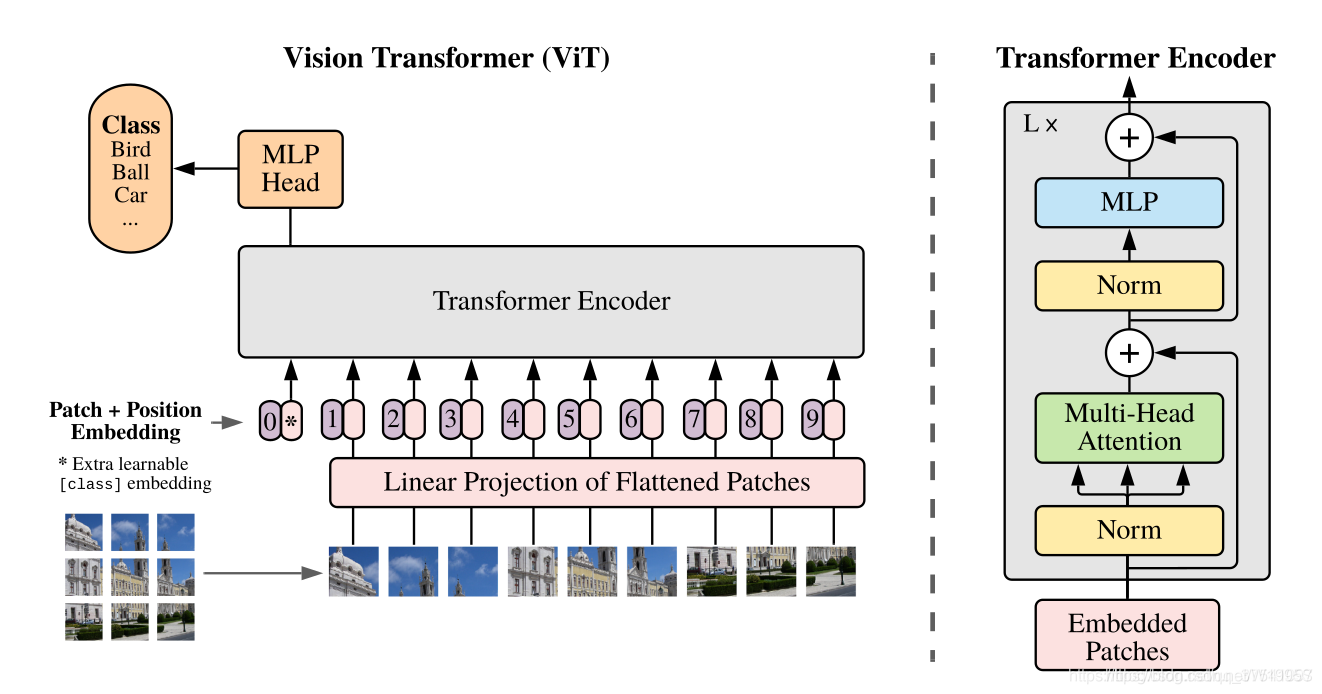
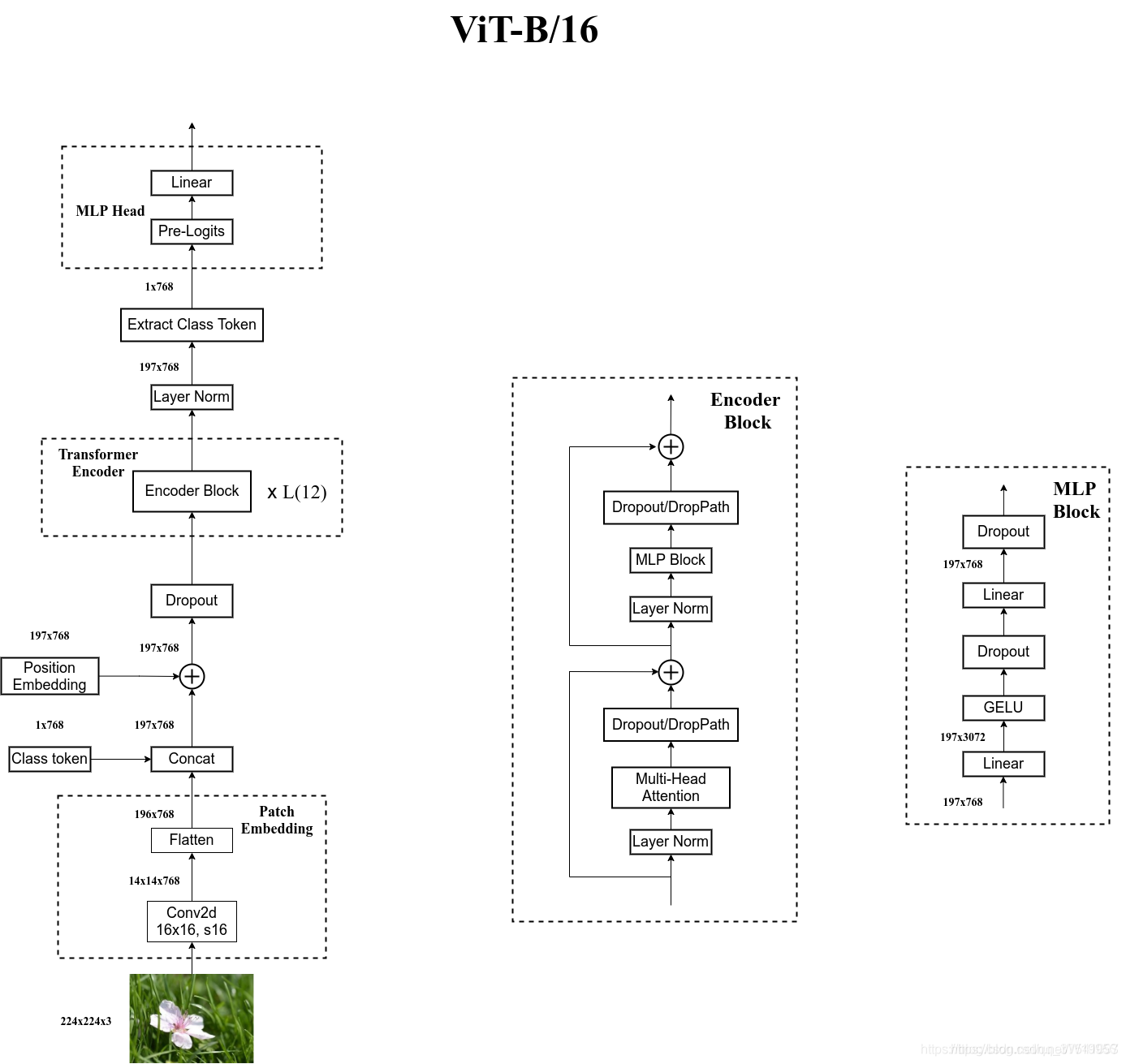
- Linear Projection of Flattened Patches(Embedding层)
- Transformer Encoder(图右侧有给出更加详细的结构)
- MLP Head(最终用于分类的层结构)
Embedding层
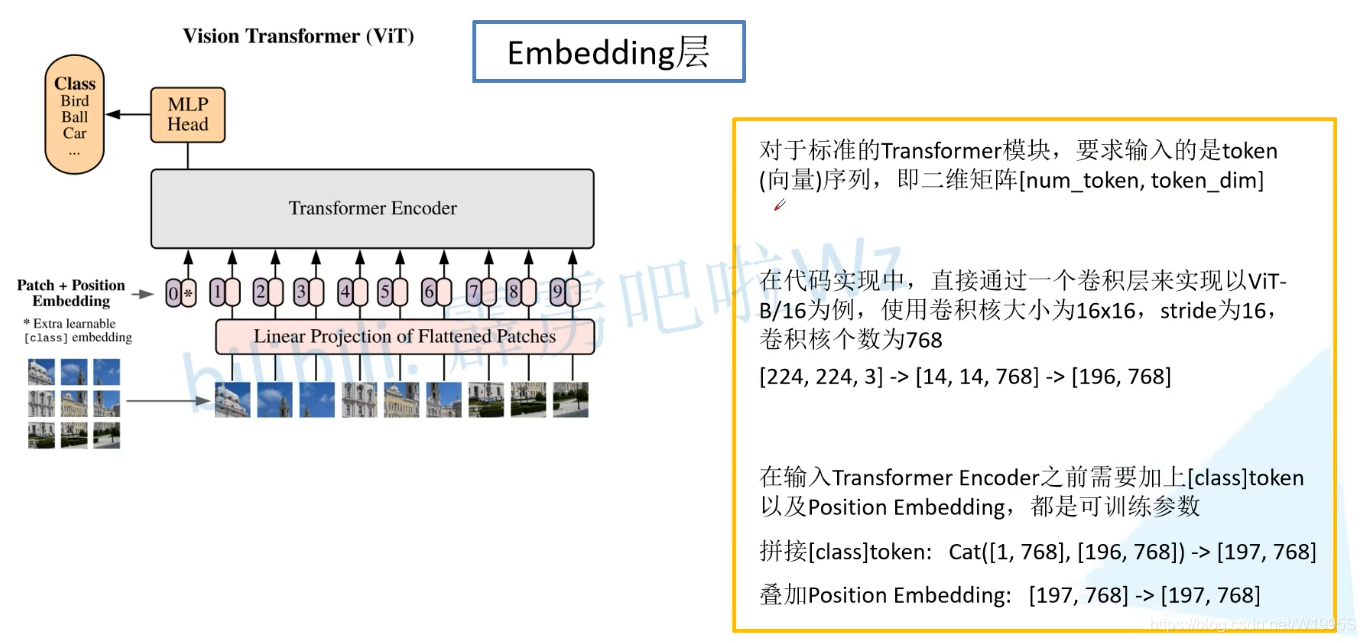
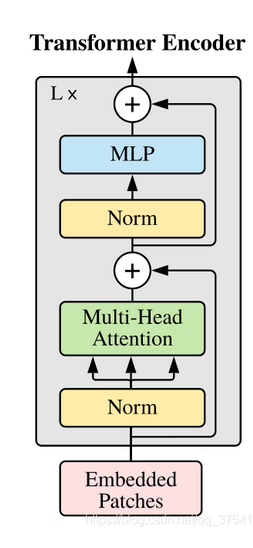
Transformer Encoder层
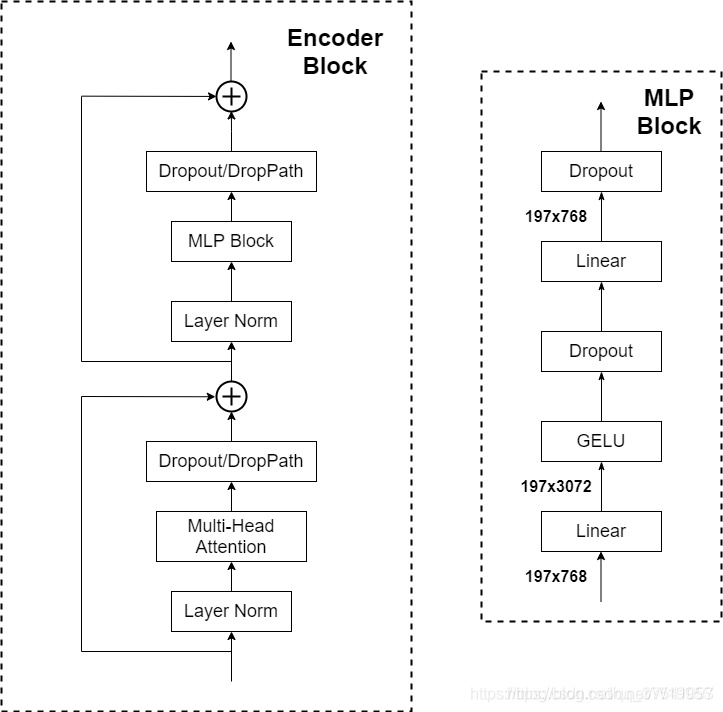
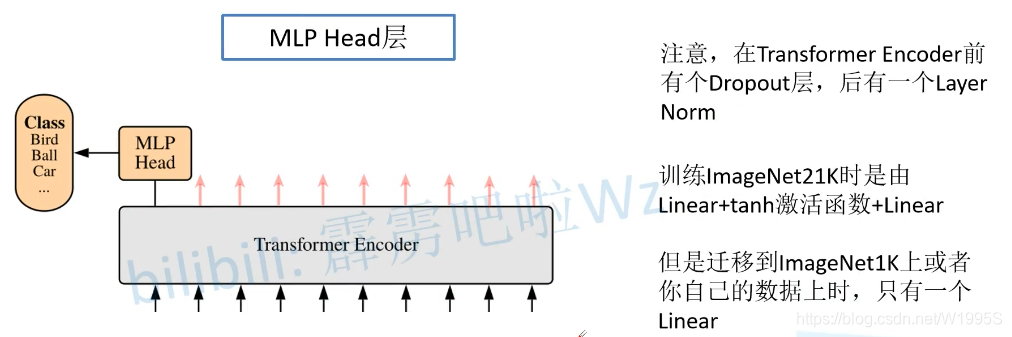
MLP Head层
Vision Transformer网络结构
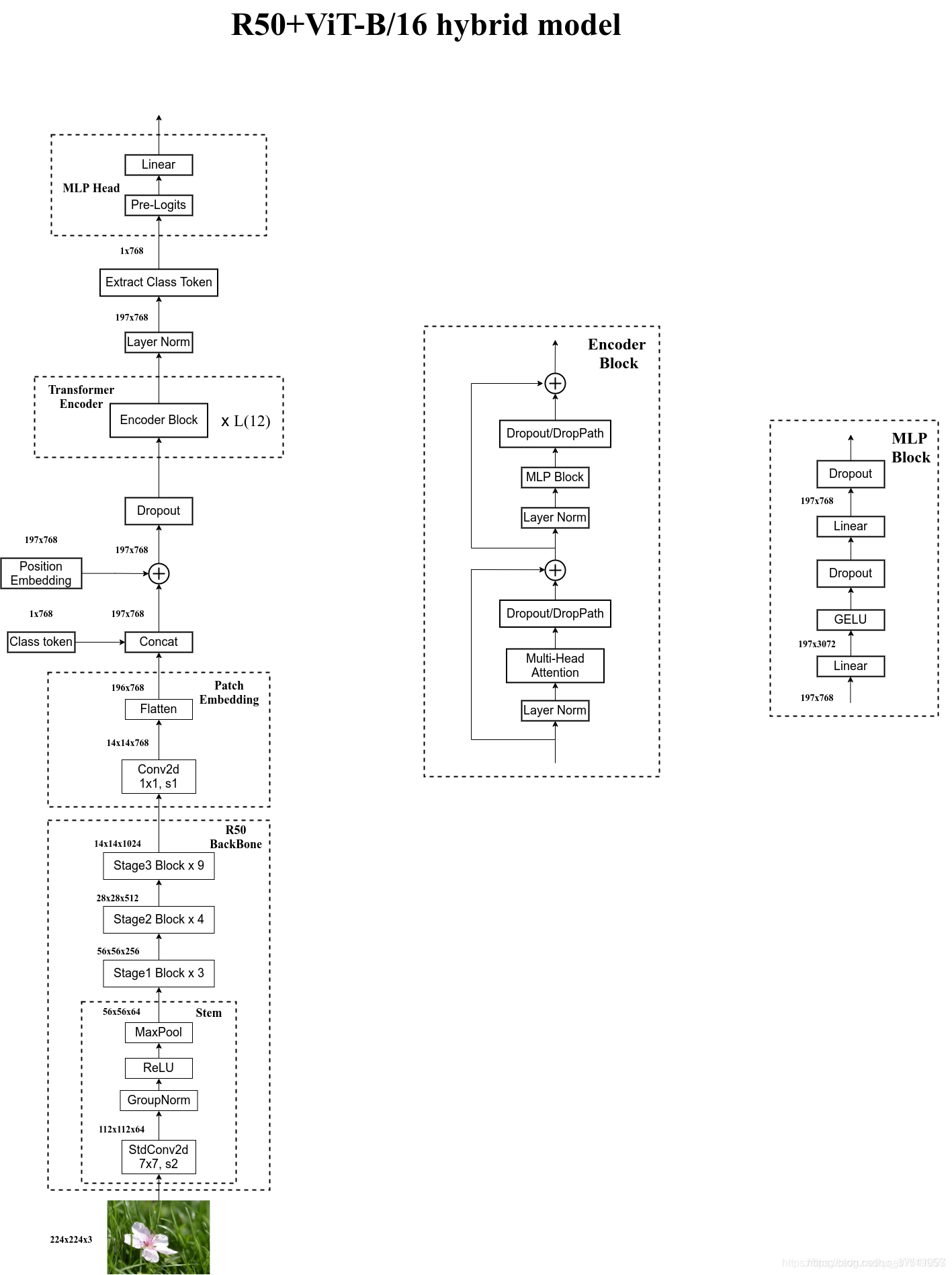
以ViT-B/16为例
Hybrid模型
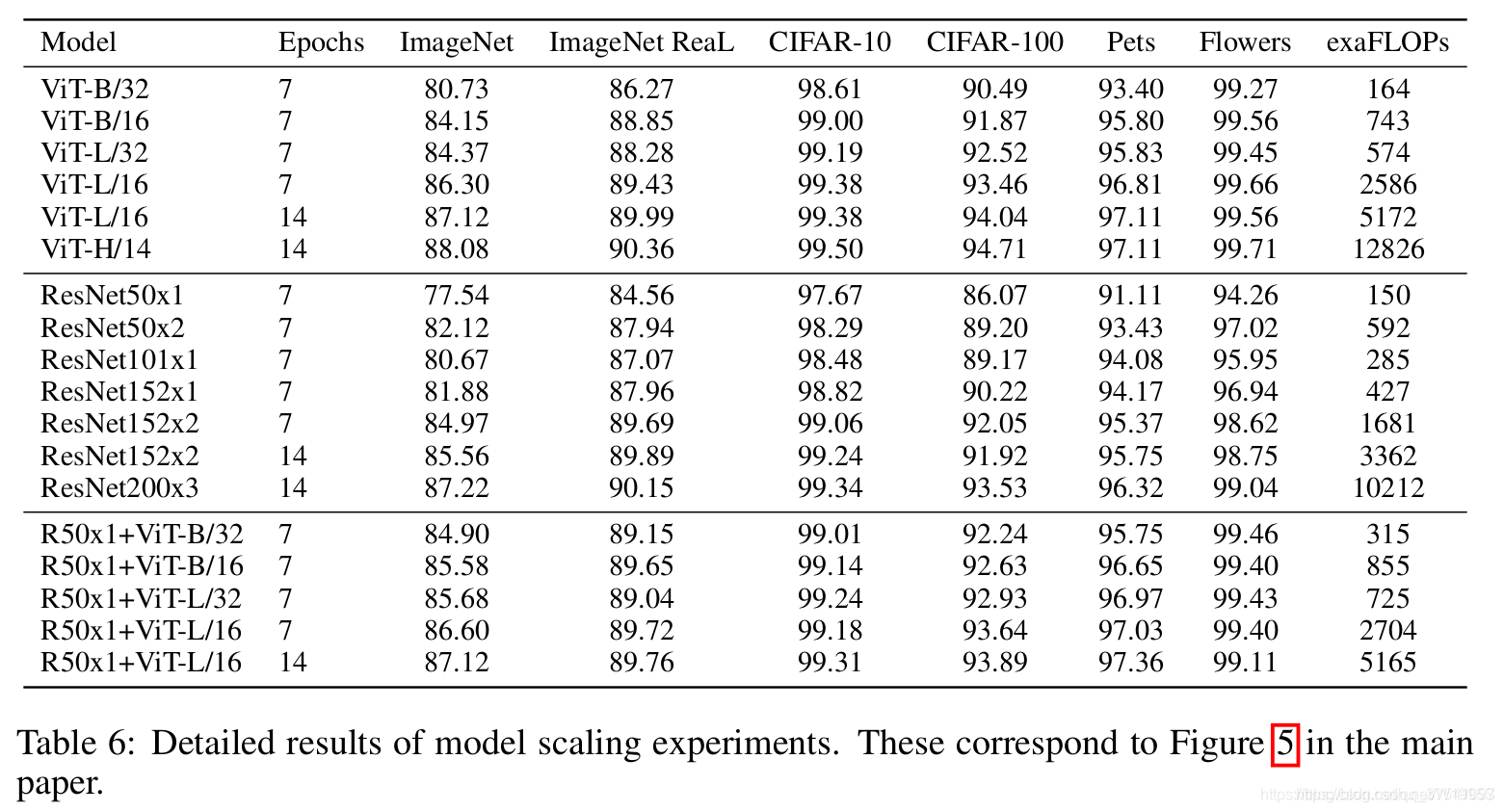
 下表是论文用来对比ViT,Resnet(和刚刚讲的一样,使用的卷积层和Norm层都进行了修改)以及Hybrid模型的效果。通过对比发现,在训练epoch较少时Hybrid优于ViT,但当epoch增大后ViT优于Hybrid。
下表是论文用来对比ViT,Resnet(和刚刚讲的一样,使用的卷积层和Norm层都进行了修改)以及Hybrid模型的效果。通过对比发现,在训练epoch较少时Hybrid优于ViT,但当epoch增大后ViT优于Hybrid。
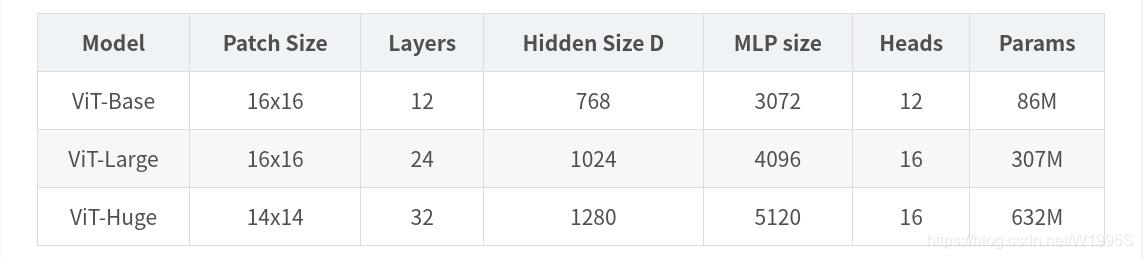
ViT模型搭建参数
在论文的Table1中有给出三个模型(Base/ Large/ Huge)的参数,在源码中除了有Patch Size为16x16的外还有32x32的。其中的Layers就是Transformer Encoder中重复堆叠Encoder Block的次数,Hidden Size就是对应通过Embedding层后每个token的dim(向量的长度),MLP size是Transformer Encoder中MLP Block第一个全连接的节点个数(是Hidden Size的四倍),Heads代表Transformer中Multi-Head Attention的heads数。
参考大佬:https://blog.youkuaiyun.com/qq_37541097/article/details/118242600


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









