




 本文介绍TensorBoardX工具如何应用于PyTorch框架,实现多种数据类型的可视化,包括标量、图像、直方图等,助力深度学习模型训练的监控与调试。
本文介绍TensorBoardX工具如何应用于PyTorch框架,实现多种数据类型的可视化,包括标量、图像、直方图等,助力深度学习模型训练的监控与调试。
我们都知道tensorflow框架可以使用tensorboard这一高级的可视化的工具,为了使用tensorboard这一套完美的可视化工具,未免可以将其应用到Pytorch中,用于Pytorch的可视化。这里特别感谢Github上的解决方案: https://github.com/lanpa/tensorboardX。
TensorboardX支持scalar, image, figure, histogram, audio, text, graph, onnx_graph, embedding, pr_curve and videosummaries等不同的可视化展示方式,具体介绍移步至项目Github 观看详情。
标量scalar(重要)
add_scalar(tag, scalar_value, global_step=None, walltime=None)
参数
- tag (string): 数据名称,不同名称的数据使用不同曲线展示
scalar_value (float): 数字常量值
global_step (int, optional): 训练的 step
walltime (float, optional): 记录发生的时间,默认为 time.time()
scalar_value 如果是 PyTorch scalar tensor,则需要调用 .item() 方法获取其数值。我们一般会使用 add_scalar 方法来记录训练过程的 loss、accuracy、learning rate 等数值的变化,直观地监控训练过程。
from tensorboardX import SummaryWriter
writer = SummaryWriter('runs/scalar_example')
for i in range(10):
writer.add_scalar('quadratic', i**2, global_step=i)
writer.add_scalar('exponential', 2**i, global_step=i)
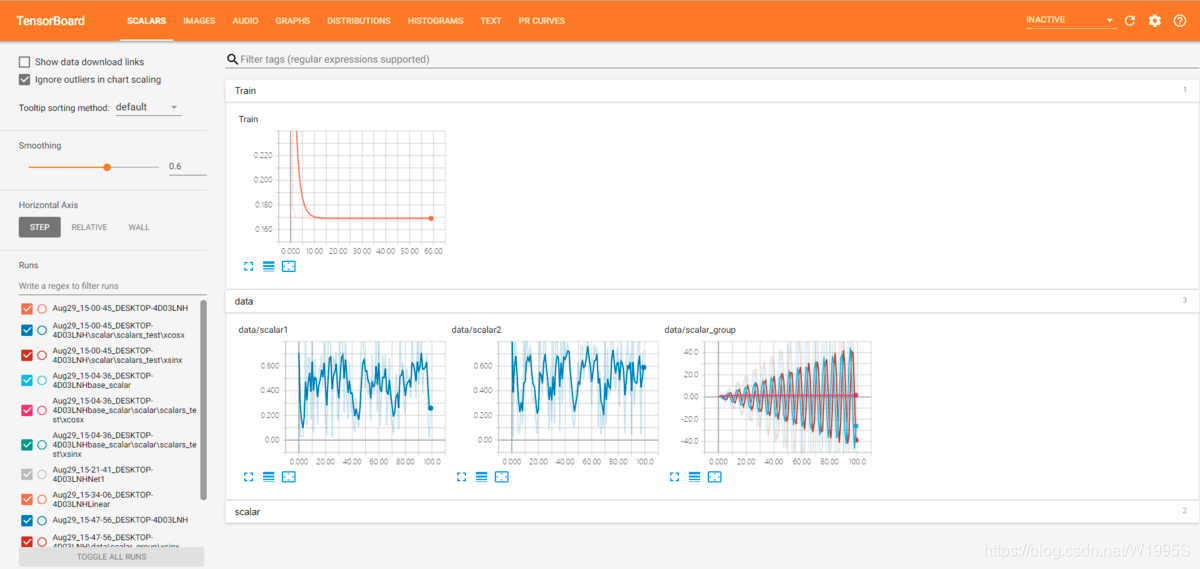
这里,我们在一个路径为 runs/scalar_example 的 run 中分别写入了二次函数数据 quadratic 和指数函数数据 exponential,在浏览器可视化界面中效果如下:
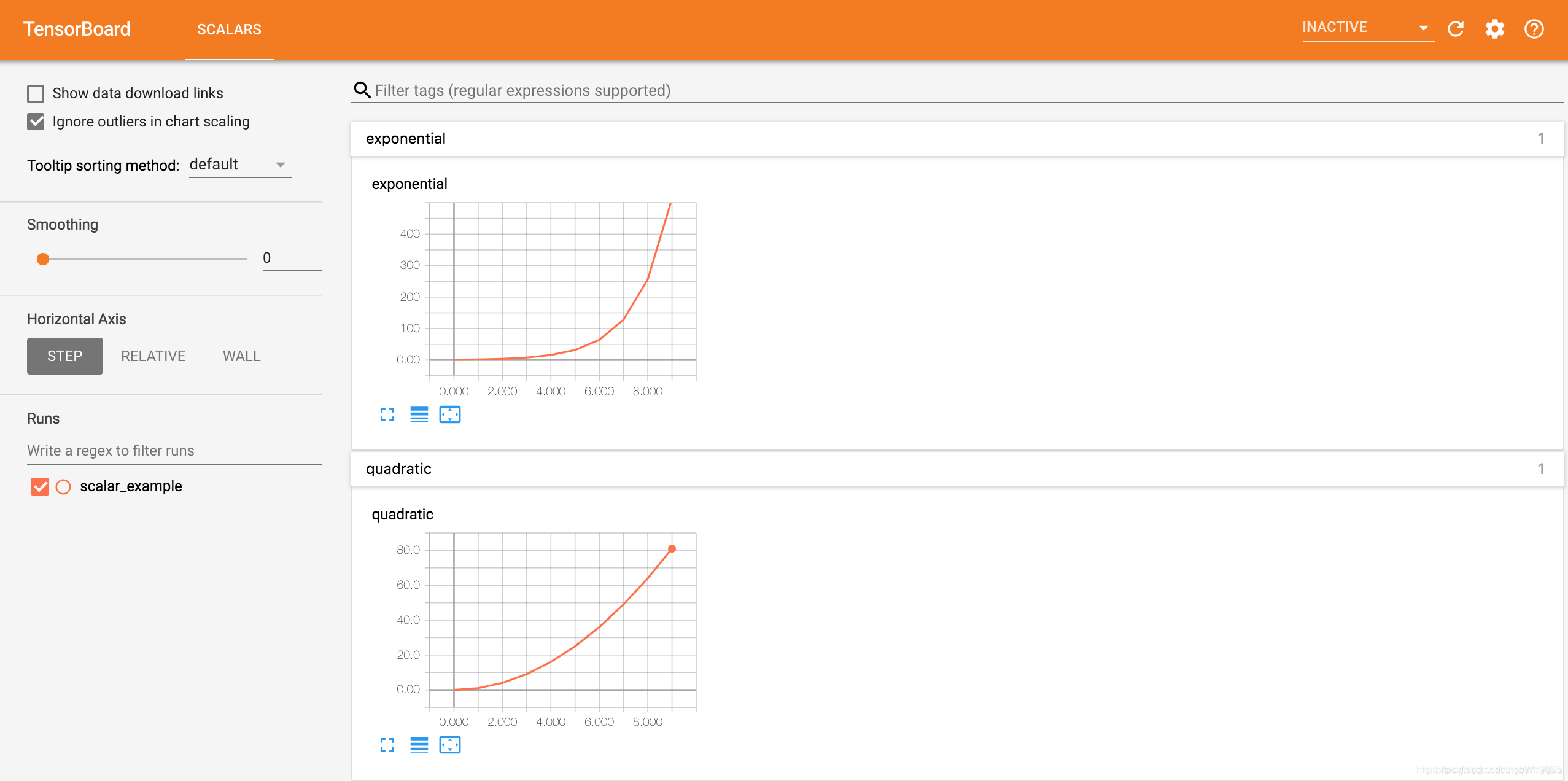 SummaryWriter()
SummaryWriter()
def __init__(self, logdir=None, comment='', purge_step=None, max_queue=10,
flush_secs=120, filename_suffix='', write_to_disk=True, log_dir=None, **kwargs):
参数:
- 其中
log_dir为生成的文件所放的目录,comment为文件名称。默认目录为生成runs文件夹目录。
import numpy as np
from tensorboardX import SummaryWriter
writer = SummaryWriter(log_dir='scalar')
for epoch in range(100):
writer.add_scalar('scalar/test', np.random.rand(), epoch)
writer.add_scalars('scalar/scalars_test', {'xsinx': epoch * np.sin(epoch), 'xcosx': epoch * np.cos(epoch)}, epoch)
writer.close()
定义一个SummaryWriter() 实例writer。 我们运行上述代码:生成结果为:
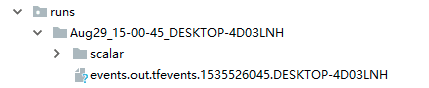
当我们为SummaryWriter(log_dir='scalar') 添加log_dir参数,生成结果目录为:
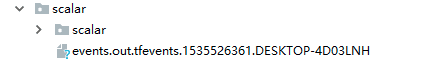
writer.add_scalar('scalar/test', np.random.rand(), epoch),这句代码的作用就是,将我们所需要的数据保存在文件里面供可视化使用。
第一个参数可以简单理解为保存图的名称,第二个参数是可以理解为Y轴数据,第三个参数可以理解为X轴数据。当Y轴数据不止一个时,可以使用writer.add_scalars().运行代码之后生成文件之后,我们在runs同级目录下使用命令行:tensorboard --logdir runs. 当SummaryWriter(log_dir='scalar')的log_dir的参数值 存在时,将tensorboard --logdir runs 改为 tensorboard --logdir 参数值

最后调用writer.close()。
点击链接即可看到我们的最终需要的可视化结果。
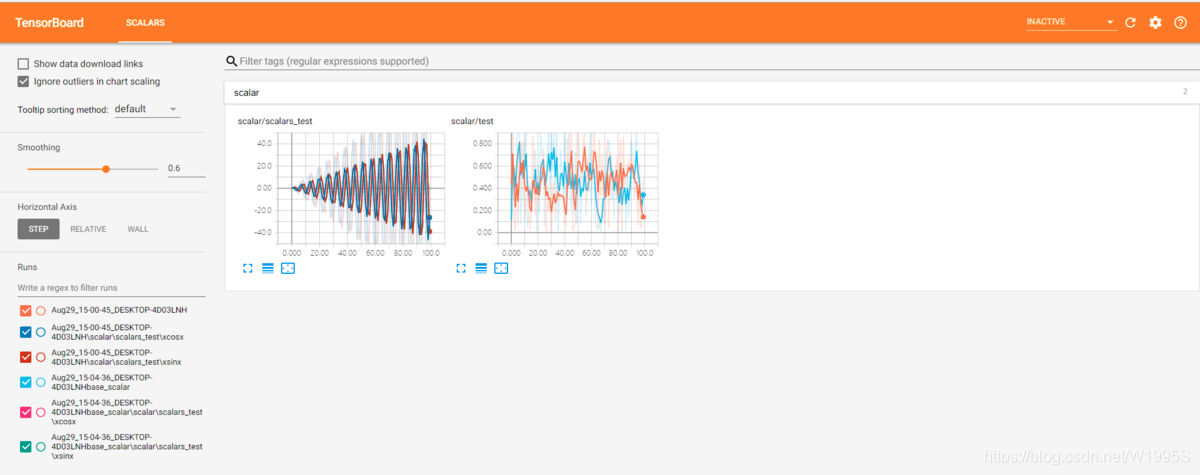 可以分别点击对应的图片查看详情。可以看到生成的Scalar名称为’scalar/test’与’scalar/test’一致。注:可以使用左下角的文件选择你想显示的某个或者全部图片。
可以分别点击对应的图片查看详情。可以看到生成的Scalar名称为’scalar/test’与’scalar/test’一致。注:可以使用左下角的文件选择你想显示的某个或者全部图片。
image
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
参数
- tag (string): 数据名称
img_tensor (torch.Tensor / numpy.array): 图像数据
global_step (int, optional): 训练的 step
walltime (float, optional): 记录发生的时间,默认为 time.time()
dataformats (string, optional): 图像数据的格式,默认为 ‘CHW’,即 Channel x Height x Width,还可以是 ‘CHW’、‘HWC’ 或 ‘HW’ 等
我们一般会使用 add_image 来实时观察生成式模型的生成效果,或者可视化分割、目标检测的结果,帮助调试模型。
from tensorboardX import SummaryWriter
import cv2 as cv
writer = SummaryWriter('runs/image_example')
for i in range(1, 6):
writer.add_image('countdown',
cv.cvtColor(cv.imread('{}.jpg'.format(i)), cv.COLOR_BGR2RGB),
global_step=i,
dataformats='HWC')
opencv 读入的图片通道排列是 BGR,因此需要先转成 RGB 以保证颜色正确,并且 dataformats 设为 'HWC',而非默认的 ‘CHW’。调用这个方法一定要保证数据的格式正确,像 PyTorch Tensor 的格式就是默认的 ‘CHW’。
add_image 方法只能一次插入一张图片。如果要一次性插入多张图片,有两种方法:
- 使用 torchvision 中的 make_grid 方法 将多张图片拼合成一张图片后,再调用 add_image 方法。
使用 SummaryWriter 的 add_images 方法 ,参数和 add_image 类似,在此不再另行介绍。
直方图 (histogram)
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
参数
- tag (string): 数据名称
values (torch.Tensor, numpy.array, or string/blobname): 用来构建直方图的数据
global_step (int, optional): 训练的 step
bins (string, optional): 取值有 ‘tensorflow’、‘auto’、‘fd’ 等, 该参数决定了分桶的方式,详见这里。
walltime (float, optional): 记录发生的时间,默认为 time.time()
max_bins (int, optional): 最大分桶数
我们可以通过观察数据、训练参数、特征的直方图,了解到它们大致的分布情况,辅助神经网络的训练过程。
from tensorboardX import SummaryWriter
import numpy as np
writer = SummaryWriter('runs/embedding_example')
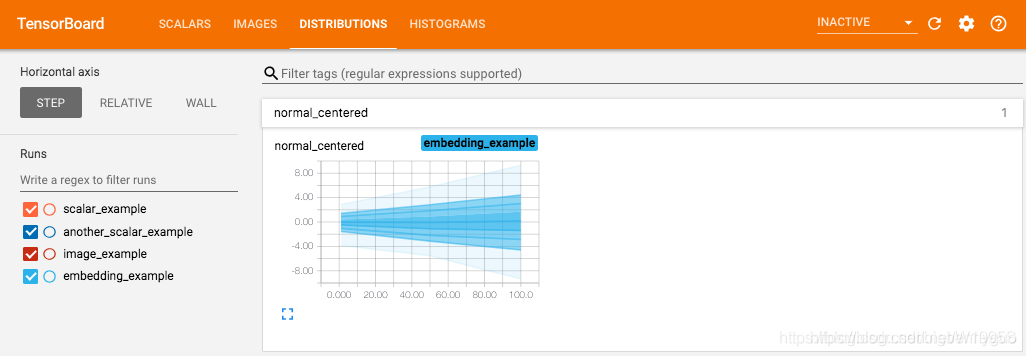
writer.add_histogram('normal_centered', np.random.normal(0, 1, 1000), global_step=1)
writer.add_histogram('normal_centered', np.random.normal(0, 2, 1000), global_step=50)
writer.add_histogram('normal_centered', np.random.normal(0, 3, 1000), global_step=100)
我们使用 numpy 从不同方差的正态分布中进行采样。打开浏览器可视化界面后,我们会发现多出了"DISTRIBUTIONS"和"HISTOGRAMS"两栏,它们都是用来观察数据分布的。其中在"HISTOGRAMS"中,同一数据不同 step 时候的直方图可以上下错位排布 (OFFSET) 也可重叠排布 (OVERLAY)。上下两图分别为"DISTRIBUTIONS"界面和"HISTOGRAMS"界面。
运行图 (graph)
add_graph(model, input_to_model=None, verbose=False, **kwargs)
参数
- model (torch.nn.Module): 待可视化的网络模型
input_to_model (torch.Tensor or list of torch.Tensor, optional): 待输入神经网络的变量或一组变量
import torch
import torch.nn as nn
import torch.nn.functional as F
from tensorboardX import SummaryWriter
class Net1(nn.Module):
def __init__(self):
super(Net1, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
self.bn = nn.BatchNorm2d(20)
def forward(self, x):
x = F.max_pool2d(self.conv1(x), 2)
x = F.relu(x) + F.relu(-x)
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = self.bn(x)
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
x = F.softmax(x, dim=1)
return x
dummy_input = torch.rand(13, 1, 28, 28)
model = Net1()
with SummaryWriter(comment='Net1') as w:
w.add_graph(model, (dummy_input,))
首先我们定义一个神经网络取名为Net1。然后将其添加到tensorboard可是可视化中。
with SummaryWriter(comment='Net1')as w:
w.add_graph(model, (dummy_input,))
我们重点关注最后两句话,其中使用了python的上下文管理,with 语句,可以避免因w.close未写造成的问题。推荐使用此方式。
因为这是一个神经网络架构,所以使用 w.add_graph(model, (dummy_input,)),其中第一个参数为需要保存的模型,第二个参数为输入值,元组类型。
官方Demo
import torch
import torchvision.utils as vutils
import numpy as np
import torchvision.models as models
from torchvision import datasets
from tensorboardX import SummaryWriter
resnet18 = models.resnet18(False)
writer = SummaryWriter()
sample_rate = 44100
freqs = [262, 294, 330, 349, 392, 440, 440, 440, 440, 440, 440]
for n_iter in range(100):
dummy_s1 = torch.rand(1)
dummy_s2 = torch.rand(1)
# data grouping by `slash`
writer.add_scalar('data/scalar1', dummy_s1[0], n_iter)
writer.add_scalar('data/scalar2', dummy_s2[0], n_iter)
writer.add_scalars('data/scalar_group', {'xsinx': n_iter * np.sin(n_iter),
'xcosx': n_iter * np.cos(n_iter),
'arctanx': np.arctan(n_iter)}, n_iter)
dummy_img = torch.rand(32, 3, 64, 64) # output from network
if n_iter % 10 == 0:
x = vutils.make_grid(dummy_img, normalize=True, scale_each=True)
writer.add_image('Image', x, n_iter)
dummy_audio = torch.zeros(sample_rate * 2)
for i in range(x.size(0)):
# amplitude of sound should in [-1, 1]
dummy_audio[i] = np.cos(freqs[n_iter // 10] * np.pi * float(i) / float(sample_rate))
writer.add_audio('myAudio', dummy_audio, n_iter, sample_rate=sample_rate)
writer.add_text('Text', 'text logged at step:' + str(n_iter), n_iter)
for name, param in resnet18.named_parameters():
writer.add_histogram(name, param.clone().cpu().data.numpy(), n_iter)
# needs tensorboard 0.4RC or later
writer.add_pr_curve('xoxo', np.random.randint(2, size=100), np.random.rand(100), n_iter)
dataset = datasets.MNIST('mnist', train=False, download=True)
images = dataset.test_data[:100].float()
label = dataset.test_labels[:100]
features = images.view(100, 784)
writer.add_embedding(features, metadata=label, label_img=images.unsqueeze(1))
# export scalar data to JSON for external processing
writer.export_scalars_to_json("./all_scalars.json")
writer.close()
参考(感谢)
https://blog.youkuaiyun.com/bigbennyguo/article/details/87956434
https://www.jianshu.com/p/46eb3004beca


















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









