



把时间戳当成版本号
按时间戳排序
在P1和P2上分别写入不同的x值,P1先写入,P2后写入,为了这两个写入操作同步到发送到P3的时候,保证最终一致(x=2),在消息里面加上时间。
先执行的“set x=1”因为消费延迟、网络不稳定等因素,比“set x=2”更晚到达P3,但是在消息中加上了事件发生的时间戳,通过比较时间大小,丢弃掉已经过期的数据,从而保证最终的值不会被已过期的老数据覆盖。
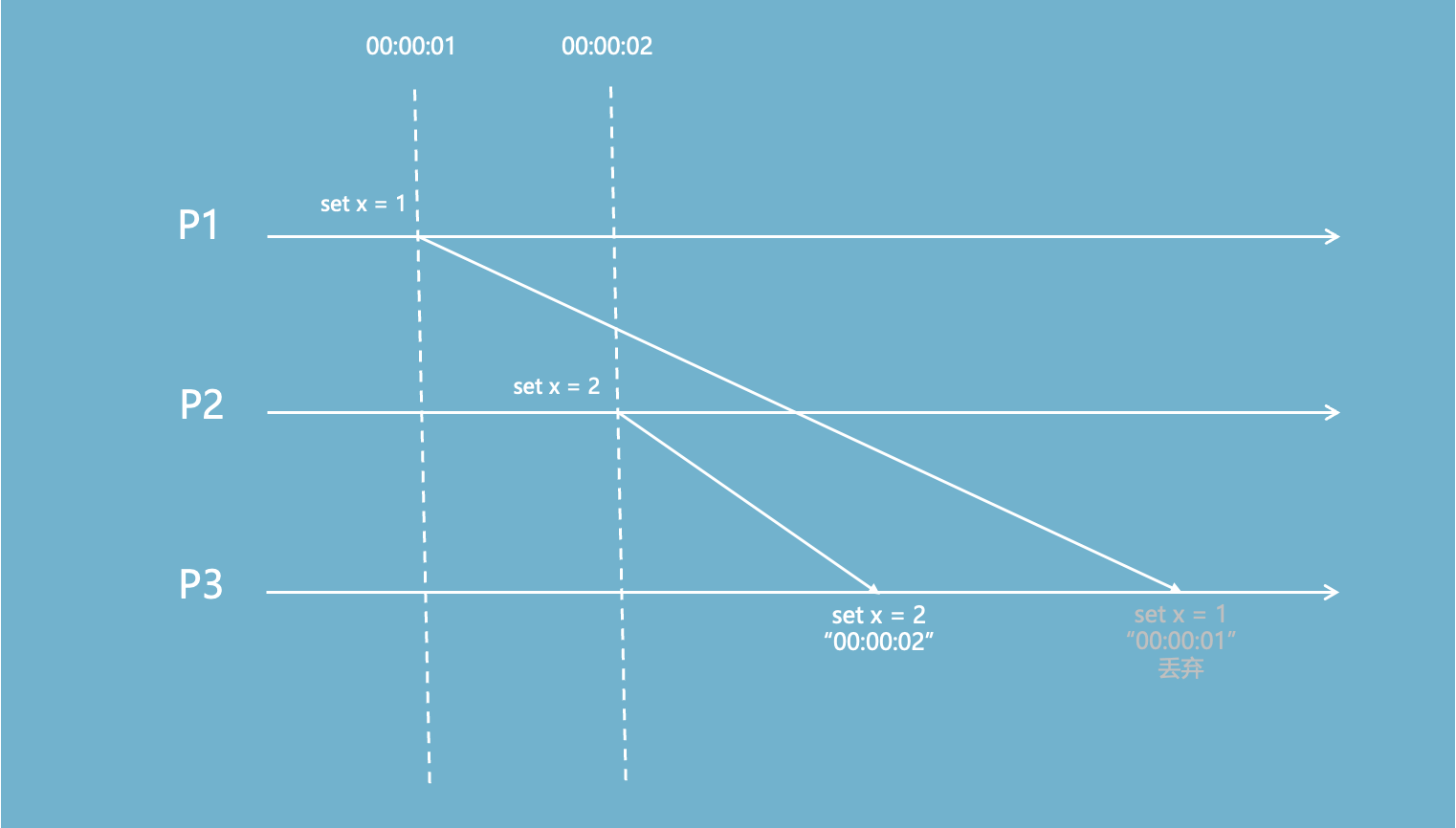
但是由于每台机器上的时间(P1、P2)并不一定完全相同,可能出现以下情况:
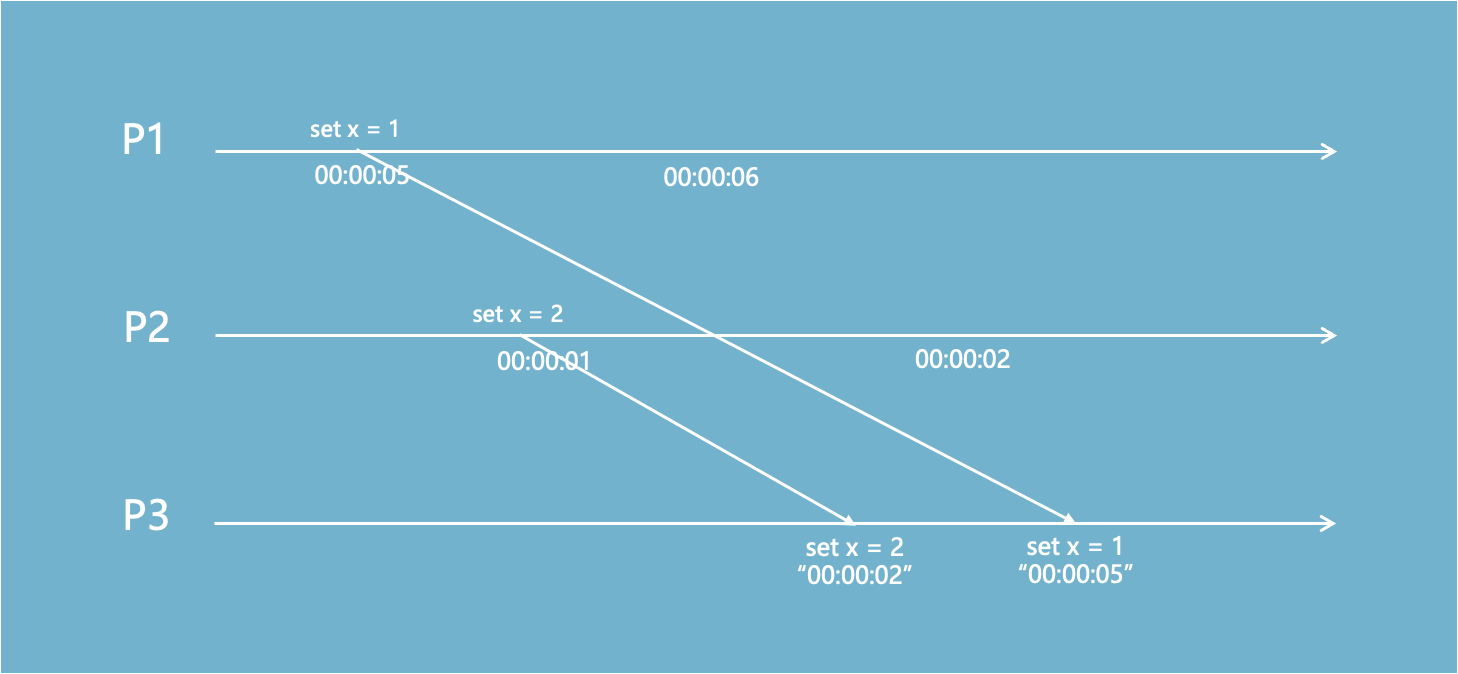
P1的本地时间比P2快5秒(或者毫秒),在P3上仍然使用时间戳判断先后顺序会产生错误结果。
需要通过NTP(Network Time Protocol)网络时间协议,让所有客户端和一台具有标准时间的服务端校准,更正本地时间。
校准本地时间
客户端A通过一次请求,把本地的时间和一个时间更准确的服务端对齐:
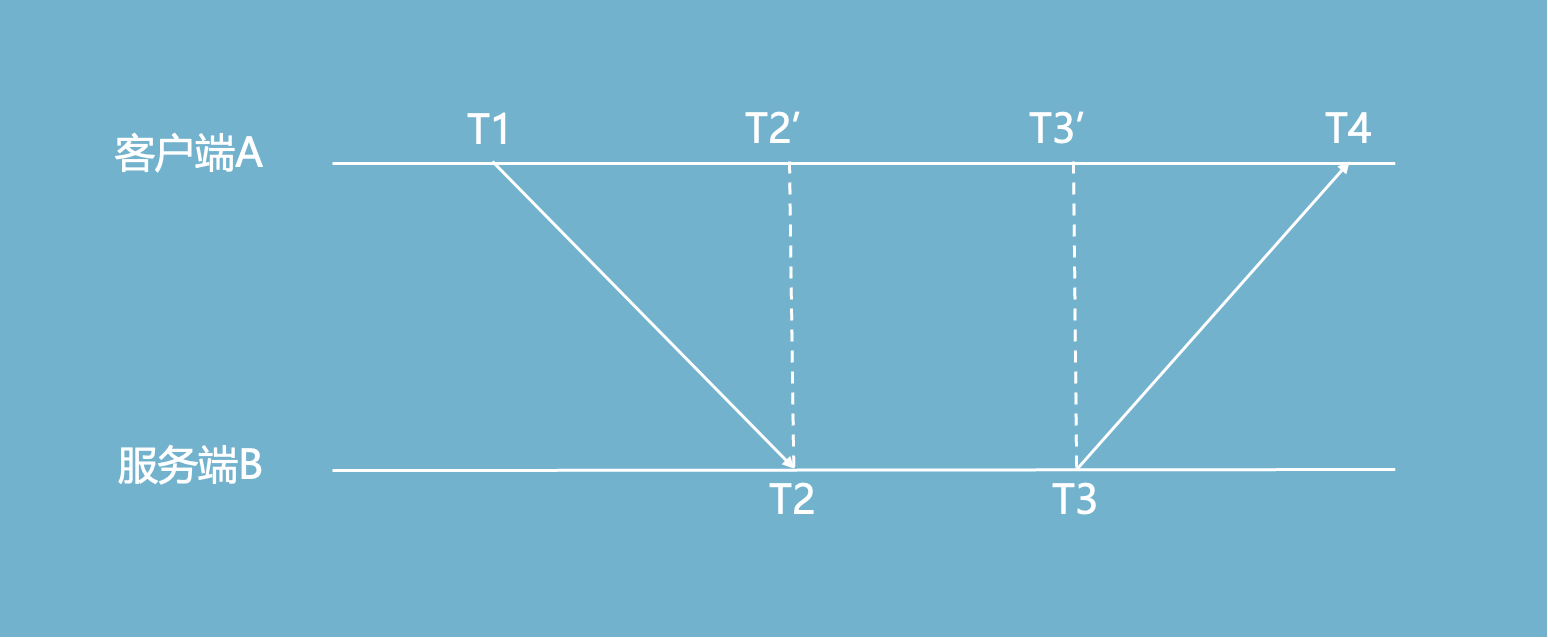
T1 : 客户端发出请求
T2:服务端收到请求
T3:服务端处理完成,发出响应
T4:服务端收到响应
计算方法:
已知:客户端获取到T1、T2、T3、T4
求:T2 - T2’
解:
可知两次网络传输的时间为 2 * a = (T4 - T1) - (T3 - T2)
那么时间偏移 = T2 - T2’ = T2 - (T1 + a) = ((T2 - T1) + (T3 - T4)) / 2
例如:
客户端经过一轮请求后,得到 T1、T2、T3、T4 四个时间点:
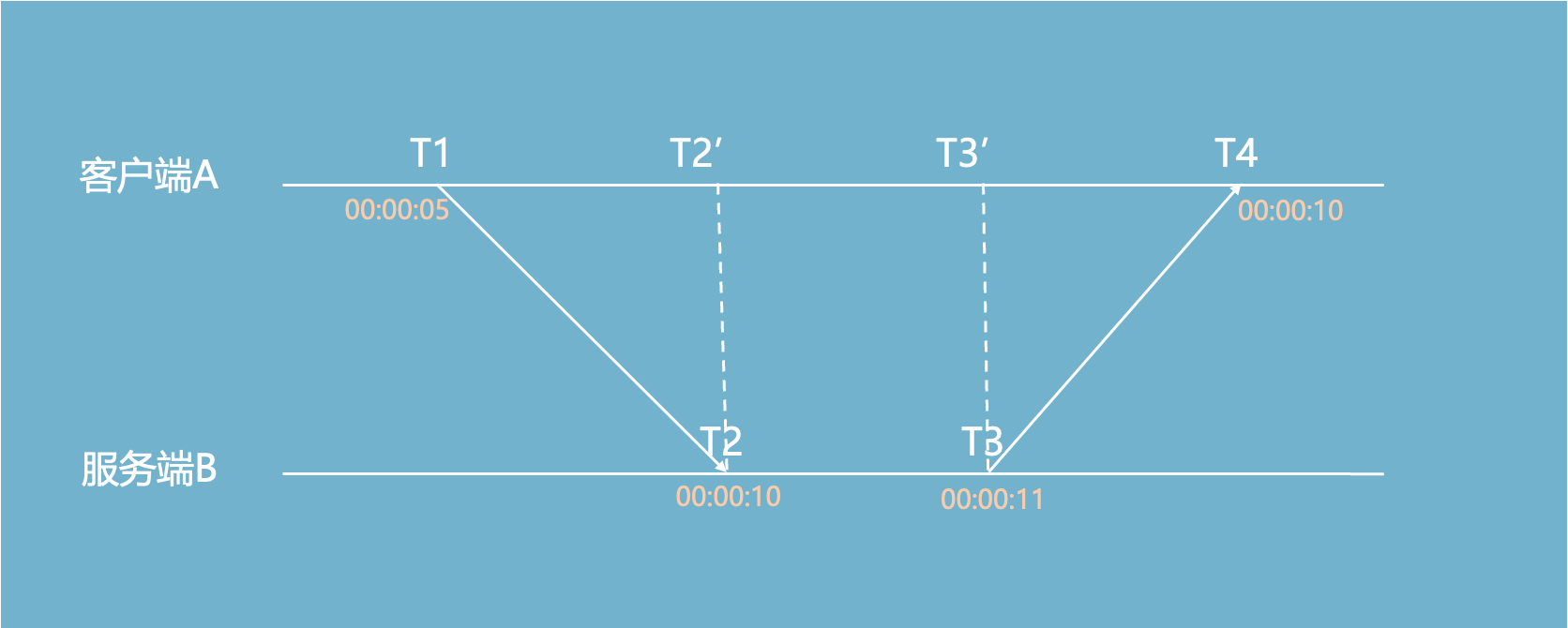
计算出2次网络传输时间一共为 (T4 - T1) - (T3 - T2) = 5秒 - 1秒 = 4秒。
那么1次网络传输时间为2秒。
T1和T2之间绝对差值(5秒)为:时间偏移量 + 1次网络传输时间,可以算出时间偏移为3秒。
当客户端A发出请求的时候,是00:00:05,当时服务端B的时间为00:00:08。
全局视角看这一次网络交互的过程:
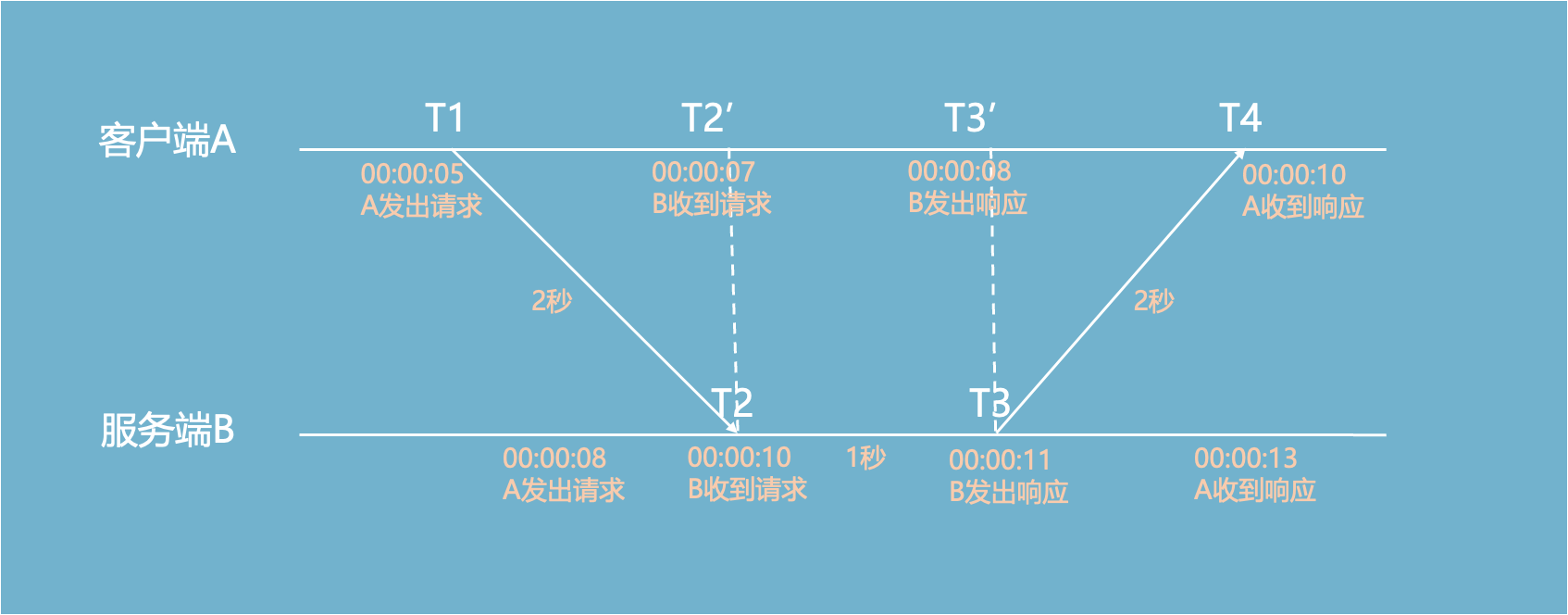
误差来源于:假定两次网络传输的时间相等
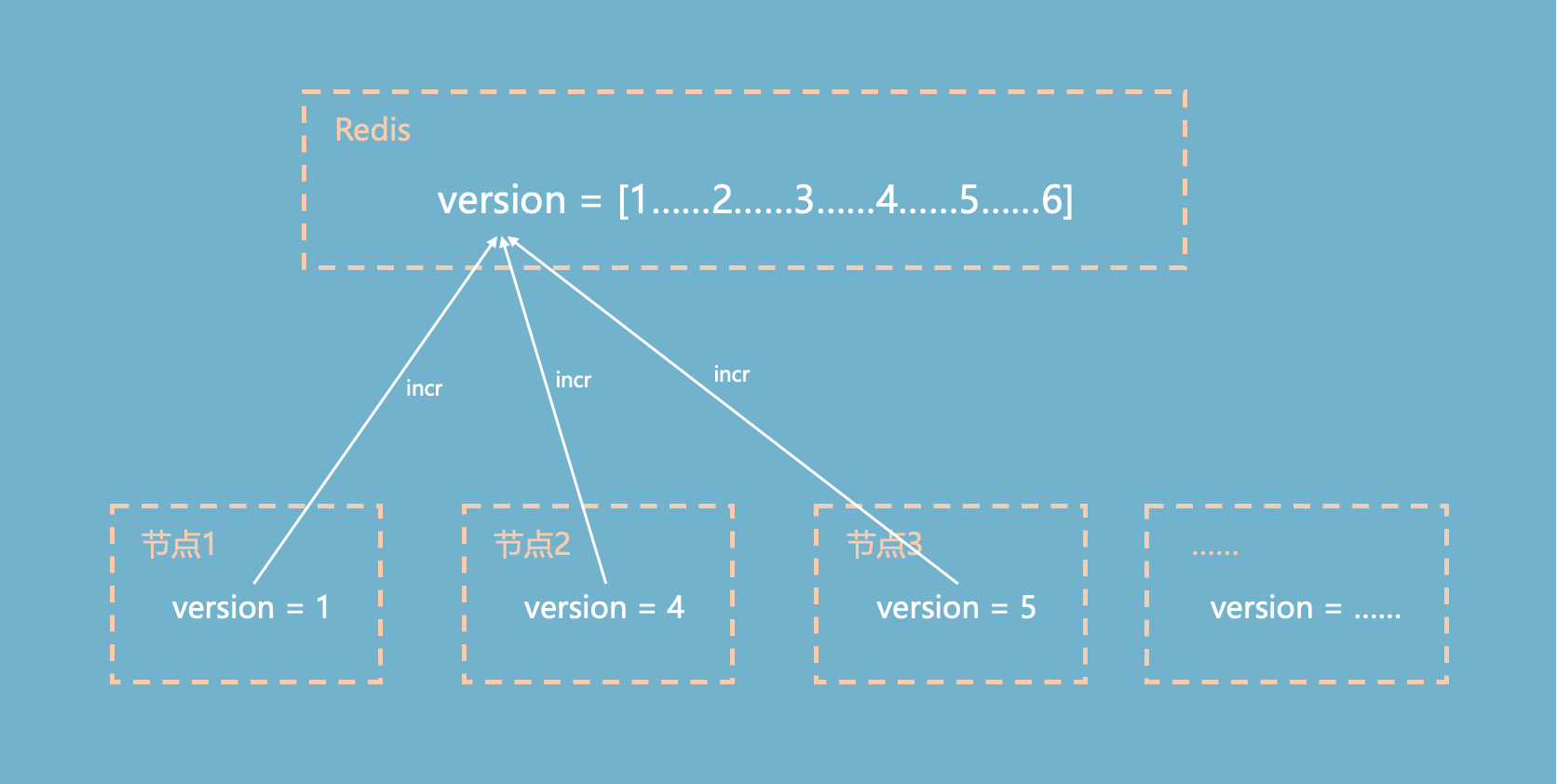
从中心获取版本号
Redis作为中心节点
- 初始化 set version = 0;
- 所有节点都incr访问同一个version,得到的结果是全序的。
全局授时
全局版本号 = 物理时间戳(long) + 逻辑版本号(long)

- 读取当前时间戳并写入内存,初始化逻辑版本号为0;
- 物理时间戳随着系统时间递增,逻辑版本号被动地随着授时请求原子增加;
扩展:Snowflake算法,时间戳+版本号生成全局唯一且可排序的ID

去中心化的版本号
逻辑时钟
逻辑时钟虽然名字里面有“时钟”两个字,但其实只关注事件发生的前后顺序,不关注绝对时间。
- P1和P2分别维护一个本地计数器C1和C2,初始值为0。
- 每次执行一个事件,计数器C的值加1。
- P1发送消息给P2时,需要带上自己的计数器C1的值。
- 当P2接收到消息时,更新自己的计数器 C2 = max(C1, C2) + 1。
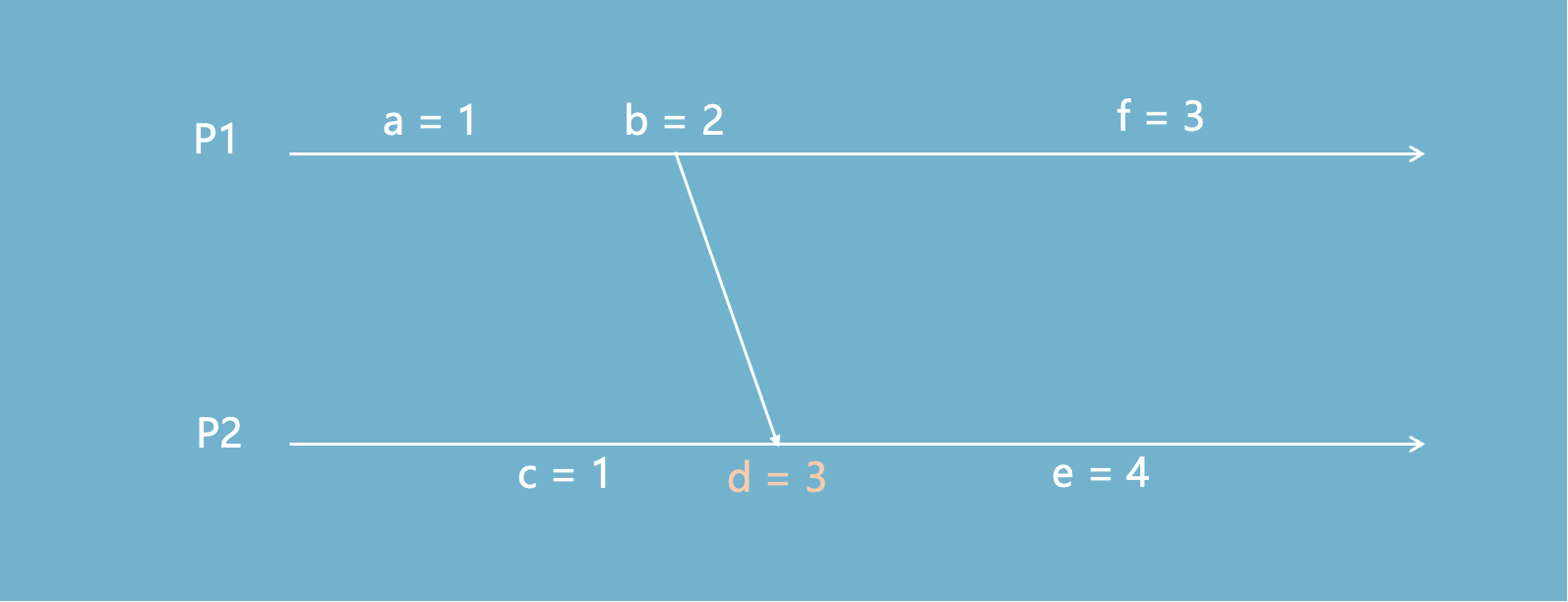
当集群中的节点从2个扩展到3个时,同样可以判断时间的执行顺序。
集群中有P1、P2、P3三个节点,在P1上先后产生了两个事件并将其传播到P3时,计数器值的变化如下图所示。
尽管由于网络原因,事件2比事件1早到达P3,但是P3会根据计数器的值丢弃 x=1,保证最终一致性。
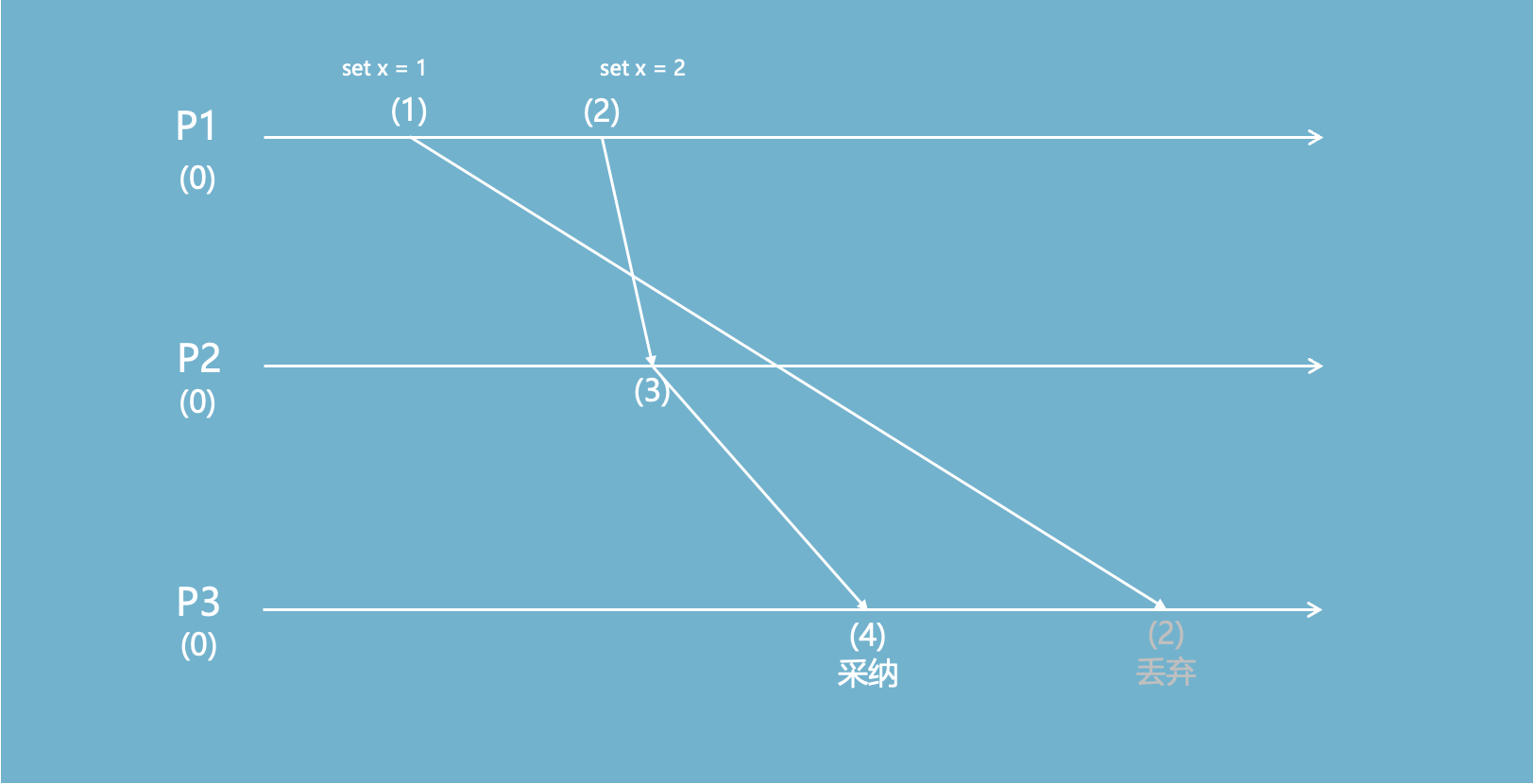
但逻辑时钟不适用的情况很多,比如:
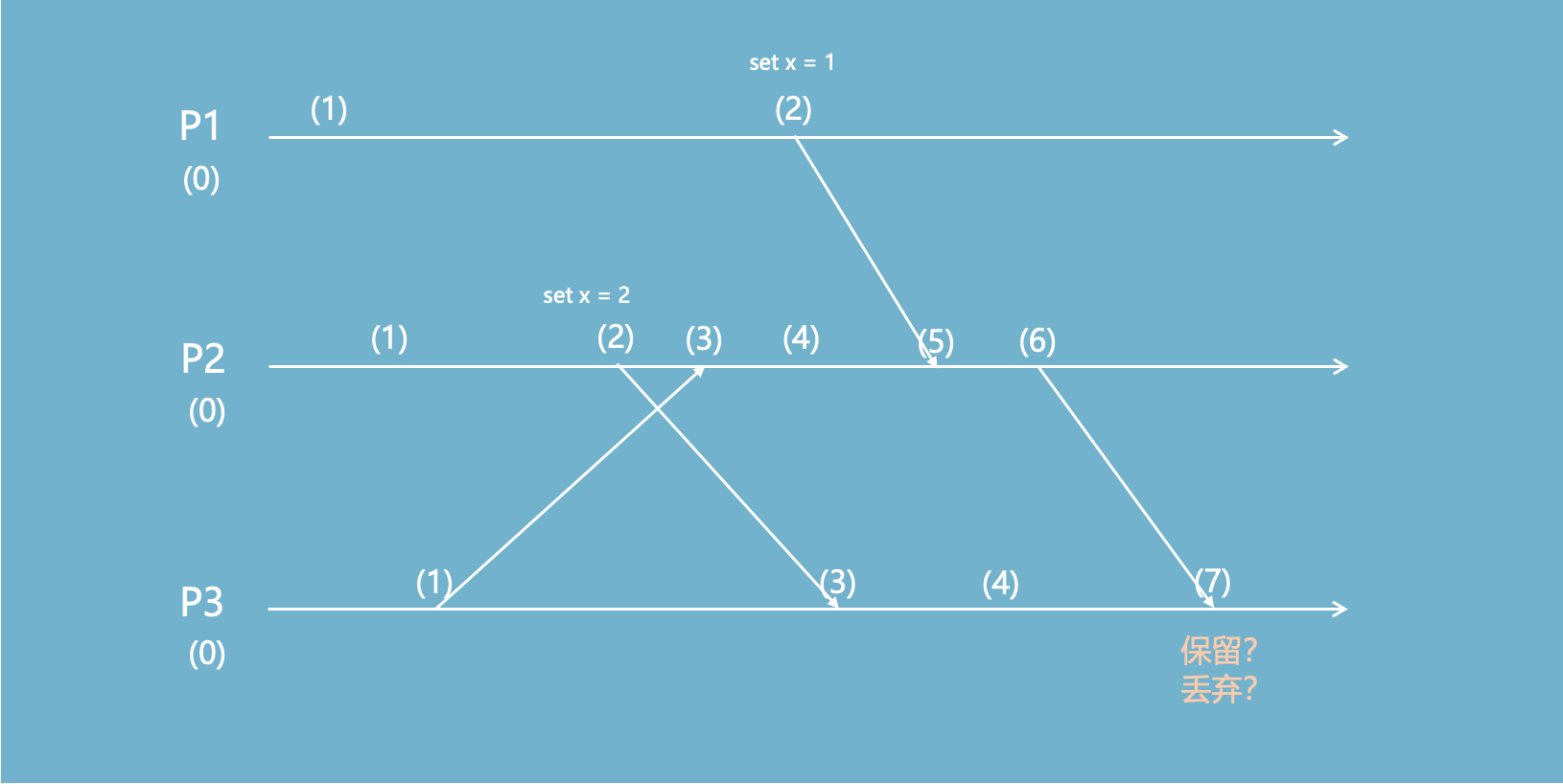
从P3的视角看,如果按照逻辑时钟的判断,从P1->P2->P3的传播而来的x=1应该覆盖从P2->P3的x=2,而事实上x=1发生在x=2之后。
错误来源于:P1上的(2)和P2上的(3)不一定存在先后关系,只有当P2上的(3)是由P1上的(2)生成的时候,才具备先后关系。
P1的(2)和P2的(2)不是同一个维度,不能混淆在一起。
向量时钟
为了把P1的(2)和P2的(2)分成不同维度,从逻辑时钟衍生出了向量时钟。
- P1、P2、P3分别维护一个向量计数器,初始值都为[0,0,0]。
- 当前节点每次执行事件后,向量对应位置的值加1,比如P2执行一次事件后,向量变成[0,1,0]。
- 节点P1发送消息给P2时,需要带上自己的向量VC1。
- 节点P2接收到消息时,需要做两步操作:
- 把自己的向量VC2里面每一个位置的值更新成 max(VC1, VC2)。
- 把VC2中对应自己的位置的值加1
当向量a所有位置的值都小于向量b时,那么事件a肯定比事件b先发生。
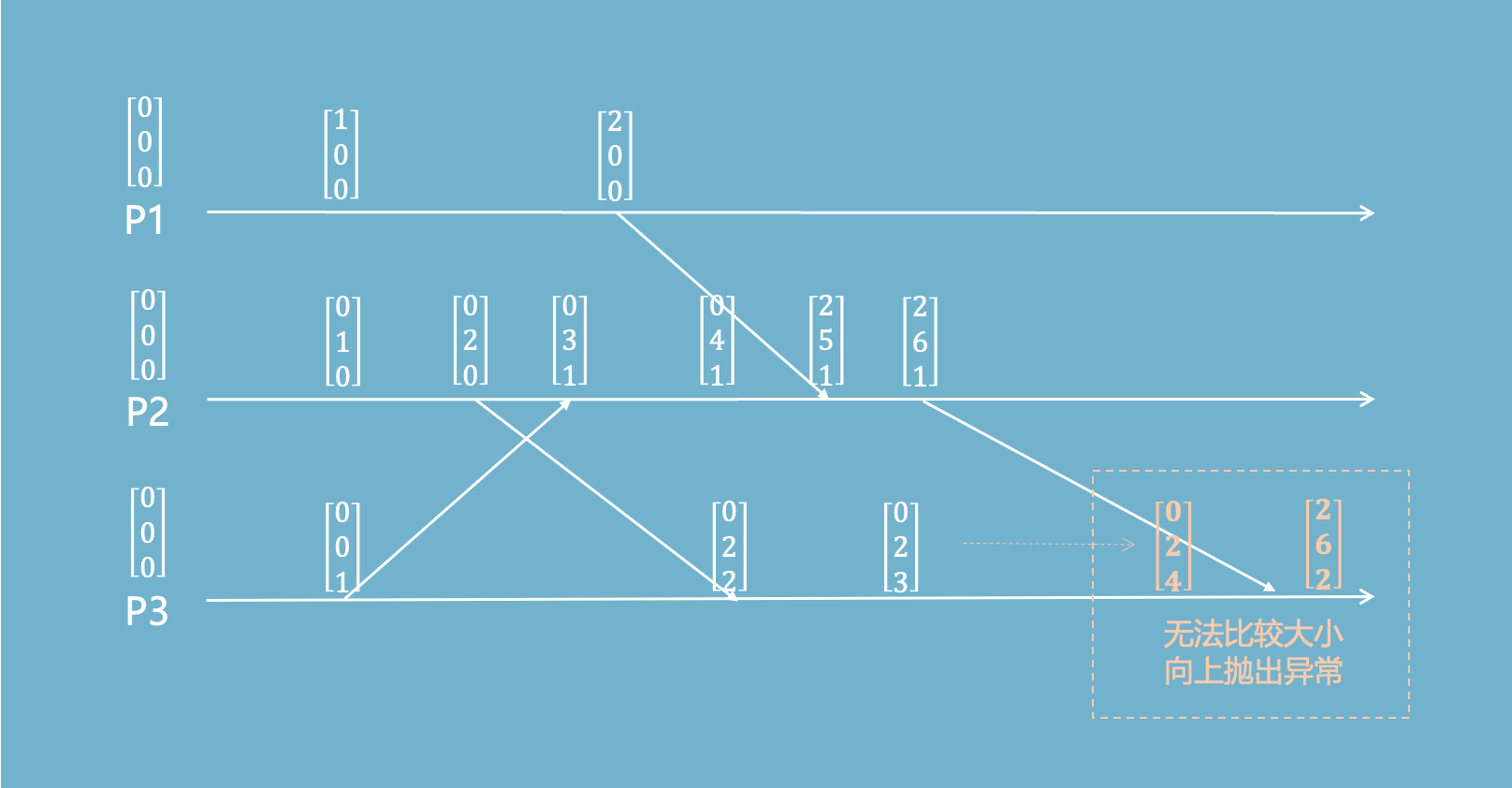
向量时钟在逻辑时钟上的改进是:
-
让每一个节点都具有全局视角,每个节点都知道其他节点的时间状态。
-
在可以比较大小的时候比较大小,不能比较大小的时候抛出异常,让外部调用方自己处理。

















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









