



两种一致性的定义
数据复制是导致数据一致性问题的唯一原因,需要复制的原因包括不限于:
- 当数据库的一部分故障时,系统仍能正常工作;
- 通过数据的多副本分散读请求,提高吞吐量;
强一致性
写请求提交以后立即改变集群的状态,任何时刻通过所有方式读取到的数据都是严格一致的。
弱一致性(最终一致性)
不保证写请求提交以后立即改变集群的状态,但是在一定的事件之后最终状态是一致的。
事务一致性指的是ACID,本文讨论范围为数据一致性。
CAP理论
Consistency(一致性):数据一致更新,所有数据变动都是同步的,如果不能一致,就会直接失败;
Availability(可用性):每个请求都能保证及时响应,但不保证返回最新数据;
Partition Tolerance(分区容错性):系统内部出现任何数据同步问题时,仍然能提供服务。
一个分布式系统最多只能满足两项指标。
只要有网络交互就一定可能发生节点间的延迟和数据丢失,所以分区容错是必须要保证的指标,一般情况下分布式系统分为两种:CP和AP。
CP:如果不能保证数据在所有节点的强一致,直接写入失败,读取时数据将会不存在。几乎所有的分布式算法,如两阶段提交、三阶段提交、Paxos、Raft都实现了CP,传统的分布式数据库HBase、Redis(存疑)、etcd、zk等都实现了CP。
AP:读请求返回的数据并不完全一致,可能在短时间内会出现脏数据,但系统总是能返回数据的。注册中心Eureka、Nacos等实现了AP。
Nacos在不同场景下使用了不同的协议,注册中心使用了AP协议(自研协议Distro),尽可能保障服务能对外提供,允许部分延迟,而配置中心使用了强一致的CP协议(Raft),避免重要配置丢失导致故障。
BASE 理论本质上是对 CAP 理论的延伸:
BA:Basically Available 基本可用,分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。
S:Soft State 软状态,允许系统存在中间状态,而该中间状态不会影响系统整体可用性。
E:Consistency 最终一致性,系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
两阶段提交(2PC、XA)
流程
第一阶段 (prepare):协调者向所有参与者发起事务执行请求,所有参与者都将事务是否能执行的信息反馈发给协调者。
第二阶段 (commit/rollback):协调者根据所有参与者的反馈,通知所有参与者,步调一致地在所有分支上commit或者rollback。
问题
同步阻塞:在提交执行过程中,各个参与者在等待其他参与者响应的过程中,将无法执行其他操作。
单点故障:协调者出现故障时整个系统不可用。
数据不一致:在阶段二,协调者发送了commit请求后,发生了网络故障,导致只有部分参与者收到commit请求,并执行提交操作,其他参与者并未commit成功。
不确定性:参与者发生故障时,协调者只能通过超时等机制来中断事务。
三阶段提交
加入预询阶段避免非健康参与者直接执行事务导致阻塞时间过长;超时策略减少阻塞时间。
流程
预询阶段 (can_commit):协调者询问所有参与者是否能正常执行事务,参与者依据自身情况回复预估状态。
预提交阶段 (pre_commit):当所有参与者返回确定信息时,发送事务执行请求,如果有参与者返回否定信息或等待超时,发送abort通知参与者退出预备状态,中断事务。
提交阶段 (do_commit):协调者根据所有参与者的反馈,通知所有参与者,步调一致地在所有分支上commit或者rollback。如果参与者在第二阶段执行完且超时后还没收到commit通知,则自行commit。
问题
效率较低、数据不一致、单点故障
Paxos
Paxos和2PC所起的作用并不相同,Paxos用于保证同一个数据分片的多个副本之前的数据一致性,2PC用于保证属于多个数据分片上的操作的原子性,分布在不同服务器上的数据分片的操作要么全部成功,要么全部失败。
流程
Prepare 阶段:Proposer 选择一个提案编号 n,向所有的 Acceptor 广播 Prepare(n) 请求。
Promise 阶段:Acceptor 接收到 Prepare(n) 请求,此时有两种情况:
- 如果 n 大于之前接受到的所有 Prepare 请求的编号,则返回
Promise()响应,并承诺将不会接收编号小于 n 的提案。如果有提案被 Chosen (已经完全结束一轮选择)的话,Promise()响应还应包含前一次提案编号和对应的值。 - 否则(即 n 小于等于 Acceptor 之前收到的最大编号)忽略,但常常会回复一个拒绝响应。
所以,Acceptor 需要持久化存储 max_n、accepted_N 和 accepted_VALUE 。
Propose 阶段:当 Proposer 收到超过半数 Acceptor 的 Promise() 响应后,Proposer 向所有节点发起 Accept(n, value) 请求并带上提案编号和值。如果前面的 Promise 响应有返回 accepted_VALUE,那就使用这个值作为 value。如果没有返回 accepted_VALUE,那可以自由决定提案值 value。
Accept阶段:Acceptor 收到 Accept() 请求,在这期间如果 Acceptor 没有对比 n 更大的编号另行 Promise,则接受该提案。
详细图解参考 图解超难理解的 Paxos 算法(含伪代码)_分布式_多颗糖_InfoQ写作社区。
活锁问题
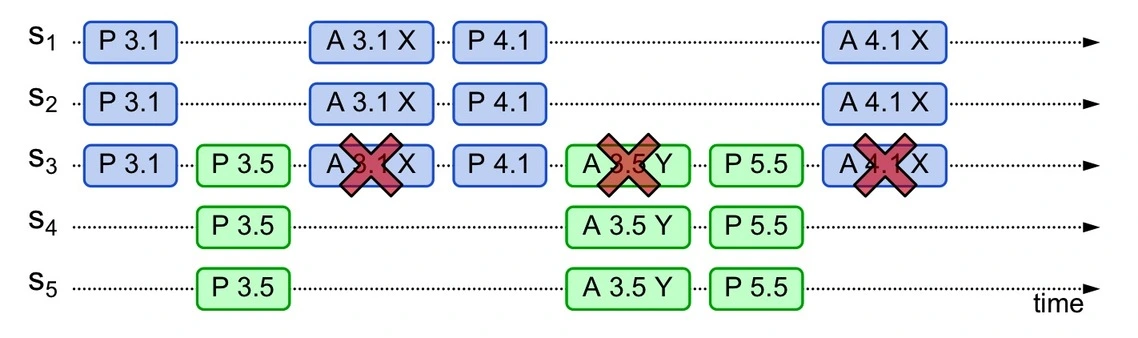
当 Proposer 在第一轮 Prepare 发出请求,还没来得及后续的第二轮 Accept 请求,紧接着第二个 Proposer 在第一阶段也发出编号更大的请求。如果这样无穷无尽,Acceptor 始终停留在决定顺序号的过程上,那大家谁也成功不了。
解决活锁最简单的方式就是引入随机超时,这样可以让某个 Proposer 先进行提案,减少一直互相抢占的可能。
Multi-Paxos
只有一个Proposer/Leader,所有的写请求都在Leader上执行并同步到其他Acceptor上。
详细参考:
- Paxos 的变种(一):Multi-Paxos 是如何劝退大家去选择 Raft 的_分布式_多颗糖_InfoQ写作社区
- 理解分布式一致性:Paxos协议之Multi-Paxos-腾讯云开发者社区-腾讯云
Raft
节点的三种角色:
Leader
- 响应客户端的写请求,将写请求同步写入到其他节点中。
Follower
- 响应客户端的读请求,负责将写请求引入到Leader节点;
- 响应Leader和Candidate的其他请求,如投票,数据同步等。
Candidate
- 在Election Timeout时间内还没有收到Leader的心跳时,Follower会认为已经没有Leader了,会变成Candidate参与竞争Leader。
时间周期Term:
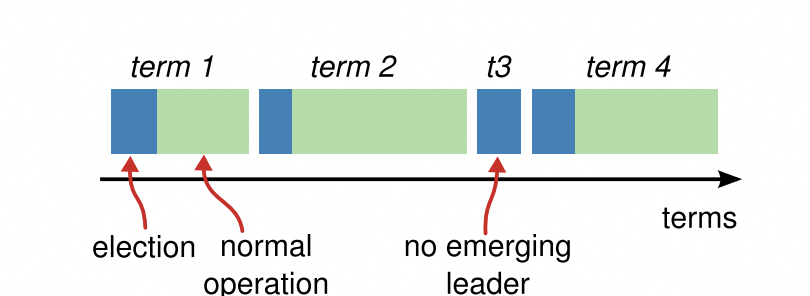
每一个Term都开始于选举,即竞选Leader,在选出Leader之后进入漫长的数据同步阶段。
选举
开始选举时,一个Follower会把Term加1,然后把自己切换到候选者状态,并向其他所有节点发起RequestVote,如果收到集群中大多数节点的回应,那么当前Candidate切换到Leader状态。
Raft节点间通过RPC的方式交流,实现一个基本的Raft只需要两种RPC类型:RequestVotes和AppendEntries。RequestVotes用于候选者在选举阶段向其他节点发送投票请求,AppendEntries用于心跳和Leader节点向其他节点复制数据(日志)。
每一个Follower节点只会遵循FIFO的原则给一个Candidate节点投票,在一个Term内只能投一次,它将投给第一个满足条件的RequestVote,并拒绝其他的候选者请求。
节点在Candidate阶段可能会收到来自Leader节点的AppendEntries请求,此时节点会检查Leader节点的term,如果比自己的高,则回退到follower状态,否则直接拒绝AppendEntries请求并继续完成由自己开启的选举。
当大多数节点同时成为Candidate时,可能出现没有任何候选者获得大多数节点支持的情况,此时节点会等待选举超时,之后重新开启新term选举。为了确保选举不会一直死循环,超时时间在节点上随机生成。
为什么不为节点设置优先级,让性能好的节点永远当Leader?原因是优先级不好控制,超时太快或太慢都可能让系统陷入循环。
复制
由Leader接收数据写入请求,并将数据同步到集群其他节点中。
Leader决定一条数据是否commit的依据是:大多数节点认为可以commit的时候,Leader就认为可以commit了。在Raft中,集群数据一致的基本规则是Leader强制要求Follower跟随其数据保持一致。
Leader会先把数据写入到自身的log中,并通过如前所述的AppendEntries远程调用发起RPC请求,尝试通知其他节点写入此数据。当所有节点都写入成功后,Leader会把状态更新为写入成功,并返回此结果给客户端。
如果Follower崩溃、失败或超时,或者数据包丢失导致RPC并未执行成功,Leader会重试AppendEntries(甚至在响应客户端之后也会继续重试)直到所有的Follower都成功写入数据。
为了保证安全性,Raft规定日志必须连续地提交,不允许出现空洞,如果给定位置的记录已经提交,那么所有前面的记录也都已经提交,这是Raft和Paxos的不同之处。
通过Term和Index编号可以用来唯一确定一条数据,当Follower和Leader的数据不一致时,下一次AppendEntries的一致性检查会返回失败,之后的AppendEntries会尝试让Index递减以寻求找到Leader和Follower数据一致的Index位置,从而通过增删操作把Leader的最新数据同步到Follower中。
选举投票的限制
选举时节点不会投票给log序号(对比log中最后一条数据的Term和Index)小于自身的RequestVote请求。这一限制用来保证Leader节点最终保存所有已经commit的数据。
考虑如下图所示S1崩溃的场景:
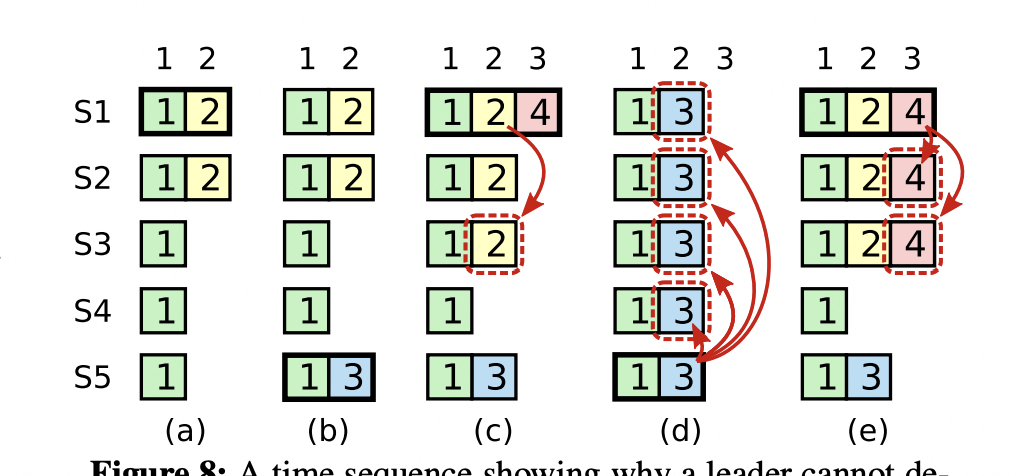
在图a的情况下S1作为Leader,如果在Term1中把数据2复制到S2就崩溃了(还没来得及commit),即图b的阶段,此时S5成为Candidate尝试发出RequestVote请求,由于其他节点都不“新”于S5,S5将会成为新的Leader,如图d所示写入数据5;如果S1在Term1中把数据2复制到大多数节点后commit再崩溃,此时S5发出RequestVote请求,根据前述限制,其将会竞选失败,因为其已提交的最后一条数据的Index皆小于S1-S3,只有S4会投票。

















 2223
2223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









