



准备工作:确保环境可复现
和上一节一样,我们将使用 torch 和 torch_geometric。请确保它们已安装。
# 确保 PyTorch 已安装
# pip install torch
#
# 安装 PyTorch Geometric 相关库
# pip install torch_geometric
# pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-$(torch.__version__).split('+')[0].html
1. 更深入的模型:图注意力网络 (GAT)
GAT 的核心思想是:“你的邻居并不都一样重要。”
GCN 对所有邻居(根据度)进行固定的加权平均。GAT 则引入了自注意力机制 (Self-Attention)。对于一个节点 $i$,它会为它的每一个邻居 $j$ 计算一个注意力系数 $\alpha_{ij}$。
这个 $\alpha_{ij}$ 是可学习的,它取决于节点 $i$ 的特征和节点 $j$ 的特征。这意味着模型可以学会“当我在对这篇‘机器学习’论文(节点 $i$)进行分类时,我应该更多地关注引用的‘概率论’论文(节点 $j$),而较少关注引用的‘数据库’论文(节点 $k$)。”
GAT 完整可复现代码 (Cora 数据集)
我们将使用与 GCN 完全相同的数据集 (Cora) 和训练流程。唯一的区别在于模型定义。我们将使用 torch_geometric.nn.GATConv。
我们还将使用多头注意力 (Multi-Head Attention),这是 GAT 的一个标准实践。模型会并行学习(例如)8 个独立的注意力机制,然后将它们的结果拼接起来,这使得学习过程更加稳定。
Python
import torch
import torch.nn.functional as F
from torch_geometric.datasets import Planetoid
# 导入 GATConv
from torch_geometric.nn import GATConv
import time
import numpy as np
# ----------------------------------------------------
# 1. 定义 GAT 模型
# ----------------------------------------------------
class GAT(torch.nn.Module):
def __init__(self, num_node_features, num_hidden, num_classes, heads=8, dropout=0.6):
"""
定义 GAT 模型
参数:
num_node_features (int): 输入特征维度
num_hidden (int): 隐藏层中 *每个头* 的维度 (例如 8)
num_classes (int): 输出类别数
heads (int): 多头注意力的头数 (例如 8)
dropout (float): GAT 论文中使用的标准 dropout 率
"""
super(GAT, self).__init__()
self.dropout = dropout
# GAT 论文的标准架构是两层
# --- 第一层 ---
# (输入特征, 每个头的输出维度, 头数)
# 注意:PyG 的 GATConv 会自动将多头结果拼接 (concat)
# 所以输出维度是 num_hidden * heads (即 8 * 8 = 64)
self.conv1 = GATConv(num_node_features,
num_hidden,
heads=heads,
dropout=dropout)
# --- 第二层 (输出层) ---
# 输入维度是上一层的输出 (num_hidden * heads)
# 输出维度是类别数
# 在最后一层,我们通常不再拼接,而是 *平均* 所有的头
# PyG 通过设置 heads=1 和 concat=False (默认) 来实现
# 但 GAT 论文的实现是:
# heads=1, concat=False
# 或者
# heads=N, concat=False (它会对 N 个头的输出求平均)
# 我们使用后者,与论文保持一致
self.conv2 = GATConv(num_hidden * heads,
num_classes,
heads=1, # 最终输出时使用 1 个头
concat=False, # 或者 concat=False 来平均
dropout=dropout)
def forward(self, data):
"""
定义前向传播
GAT 论文使用 ELU 作为激活函数,并大量使用 Dropout
"""
x, edge_index = data.x, data.edge_index
# --- 输入层 Dropout ---
# GAT 论文在输入特征上也应用了 dropout
x = F.dropout(x, p=self.dropout, training=self.training)
# --- GAT 层 1 ---
x = self.conv1(x, edge_index)
# 论文中使用 ELU 激活函数
x = F.elu(x)
# --- 中间层 Dropout ---
x = F.dropout(x, p=self.dropout, training=self.training)
# --- GAT 层 2 (输出) ---
x = self.conv2(x, edge_index)
# --- 输出 LogSoftmax ---
return F.log_softmax(x, dim=1)
# ----------------------------------------------------
# 2. 训练和测试函数 (与上一节 GCN 代码完全相同)
# ----------------------------------------------------
def train(model, optimizer, criterion, data):
model.train()
optimizer.zero_grad()
out = model(data)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss.item()
def test(model, data):
model.eval()
with torch.no_grad():
out = model(data)
pred = out.argmax(dim=1)
# 训练集准确率
train_correct = pred[data.train_mask] == data.y[data.train_mask]
train_acc = int(train_correct.sum()) / int(data.train_mask.sum())
# 测试集准确率
test_correct = pred[data.test_mask] == data.y[data.test_mask]
test_acc = int(test_correct.sum()) / int(data.test_mask.sum())
return train_acc, test_acc
# ----------------------------------------------------
# 3. 主执行函数
# ----------------------------------------------------
if __name__ == "__main__":
print("--- 1. GAT (图注意力网络) 可复现代码 ---")
# 1. 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# 2. 加载 Cora 数据集
print("正在加载 Cora 数据集...")
dataset = Planetoid(root='/tmp/Cora_GAT', name='Cora')
data = dataset[0].to(device)
print("\nCora 数据集概览:")
print(f" 特征维度: {dataset.num_node_features}")
print(f" 类别数: {dataset.num_classes}")
print(f" 训练节点数: {data.train_mask.sum()}")
print(f" 测试节点数: {data.test_mask.sum()}")
# 3. 实例化模型、优化器和损失函数
# GAT 论文中的超参数
HIDDEN_DIM = 8 # 每个注意力头的维度
HEADS = 8 # 注意力头数
DROPOUT = 0.6 # GAT 使用的高 dropout 率
LEARNING_RATE = 0.005
WEIGHT_DECAY = 5e-4 # L2 正则化
EPOCHS = 200
model = GAT(
num_node_features=dataset.num_node_features,
num_hidden=HIDDEN_DIM,
num_classes=dataset.num_classes,
heads=HEADS,
dropout=DROPOUT
).to(device)
# GAT 论文使用 Adam 优化器
optimizer = torch.optim.Adam(model.parameters(),
lr=LEARNING_RATE,
weight_decay=WEIGHT_DECAY)
criterion = torch.nn.NLLLoss()
# 4. 训练循环
print(f"\n开始训练 {EPOCHS} 个 epochs... (使用 GAT 论文超参数)")
start_time = time.time()
for epoch in range(1, EPOCHS + 1):
loss = train(model, optimizer, criterion, data)
if epoch % 20 == 0 or epoch == 1 or epoch == EPOCHS:
train_acc, test_acc = test(model, data)
print(f'Epoch: {epoch:03d}, 损失: {loss:.4f}, '
f'训练集 Acc: {train_acc:.4f}, 测试集 Acc: {test_acc:.4f}')
end_time = time.time()
print(f"训练完成,耗时: {end_time - start_time:.2f} 秒")
# 5. 最终评估
train_acc, test_acc = test(model, data)
print("--- 最终 GAT 结果 ---")
print(f"最终训练集准确率: {train_acc:.4f}")
print(f"最终测试集准确率: {test_acc:.4f}")
# 观察:
# GAT 的性能通常与 GCN 相当或略好 (在 Cora 上约 82%-84%)。
# 它的真正优势在于对邻居的“可解释性”(可以检查注意力权重)
# 以及在异构图(不同类型的节点和边)上的强大表现力。
2. 深入探讨:GCN 的“过平滑”陷阱
这是一个在 GNN 实践中极其重要的问题。
-
问题: GCN 效果很好,为什么我们不堆叠 10 层、20 层甚至 50 层来构建一个“深度”GCN 呢?(就像在 CNN 中使用 ResNet-50 一样)
-
答案:过平滑 (Oversmoothing)。
核心概念:
GCN 的每一层本质上都是一次邻域平均。
-
在 1 层 GCN 后,节点 $i$ 的特征是其 1 跳邻居的平均值。
-
在 2 层 GCN 后,节点 $i$ 的特征是其 2 跳邻居的平均值。
-
在 $k$ 层 GCN 后,节点 $i$ 的特征是其 $k$ 跳邻居的平均值。
如果图的直径(图中任意两点间的最长最短路径)是 10,那么在一个 10 层的 GCN 之后,节点 $i$ 的特征在某种程度上是图中所有其他节点特征的平均值。
当 $k$ 变得非常大时,所有节点的特征向量都会收敛到同一个值(与图的稳态分布相关)。当所有节点的特征都相同时,分类器就无法区分它们了。
过平滑的可复现代码演示
我们将构建一个“深度” GCN,并在不进行任何训练的情况下,仅通过一次前向传播来展示这种效应。我们将测量两个不同节点的输出特征的余弦相似度。
-
如果模型健康,两个不同类别节点的特征向量应该非常不同(余弦相似度接近 0 或为负)。
-
如果模型“过平滑”,两个节点的特征向量将几乎相同(余弦相似度接近 1.0)。
Python
import torch
import torch.nn.functional as F
from torch_geometric.datasets import Planetoid
from torch_geometric.nn import GCNConv
import time
# ----------------------------------------------------
# 1. 定义一个 "深度" GCN
# ----------------------------------------------------
class DeepGCN(torch.nn.Module):
def __init__(self, num_features, num_hidden, num_classes, num_layers):
super(DeepGCN, self).__init__()
self.num_layers = num_layers
self.convs = torch.nn.ModuleList()
# 输入层
self.convs.append(GCNConv(num_features, num_hidden))
# 隐藏层
for _ in range(num_layers - 2):
self.convs.append(GCNConv(num_hidden, num_hidden))
# 输出层
self.convs.append(GCNConv(num_hidden, num_classes))
def forward(self, data):
x, edge_index = data.x, data.edge_index
for i in range(self.num_layers):
x = self.convs[i](x, edge_index)
# 我们只在隐藏层使用激活
if i < self.num_layers - 1:
x = F.relu(x)
# 注意:为了演示纯粹的过平滑,我们甚至可以去掉激活
# x = F.dropout(x, p=0.5, training=self.training)
return x
# ----------------------------------------------------
# 2. 主执行函数:演示过平滑
# ----------------------------------------------------
if __name__ == "__main__":
print("\n--- 2. 深入 GCN: 演示'过平滑'问题 ---")
# 1. 设置设备和加载数据
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
dataset = Planetoid(root='/tmp/Cora_Oversmooth', name='Cora')
data = dataset[0].to(device)
# 2. 选择两个节点进行比较
# 节点 10 和 节点 2000
# 检查它们是否属于不同类别 (大概率)
node_a_idx = 10
node_b_idx = 2000
print(f"节点 {node_a_idx} 的类别: {data.y[node_a_idx]}")
print(f"节点 {node_b_idx} 的类别: {data.y[node_b_idx]}")
print(f"设备: {device}")
# 3. 实例化两个模型:一个浅层,一个深层
# (注意:我们只实例化,不训练)
# 浅层模型 (2层)
shallow_gcn = DeepGCN(
num_features=dataset.num_node_features,
num_hidden=64,
num_classes=64, # 输出维度设为 64 以便比较
num_layers=2
).to(device)
# 深层模型 (32层)
deep_gcn = DeepGCN(
num_features=dataset.num_node_features,
num_hidden=64,
num_classes=64,
num_layers=32
).to(device)
# 4. 执行一次前向传播 (不训练)
shallow_gcn.eval()
deep_gcn.eval()
with torch.no_grad():
out_shallow = shallow_gcn(data)
out_deep = deep_gcn(data)
print(f"\n输出特征向量的形状 (N, F): {out_shallow.shape}")
# 5. 提取两个节点的特征向量
feat_shallow_a = out_shallow[node_a_idx]
feat_shallow_b = out_shallow[node_b_idx]
feat_deep_a = out_deep[node_a_idx]
feat_deep_b = out_deep[node_b_idx]
# 6. 计算余弦相似度
# cos_sim(A, B) = (A · B) / (||A|| * ||B||)
cos_sim_shallow = F.cosine_similarity(feat_shallow_a.unsqueeze(0),
feat_shallow_b.unsqueeze(0))
cos_sim_deep = F.cosine_similarity(feat_deep_a.unsqueeze(0),
feat_deep_b.unsqueeze(0))
# 7. 报告结果
print("\n--- 过平滑测试结果 ---")
print(f"2层 GCN: 节点 {node_a_idx} 和 {node_b_idx} 的特征余弦相似度: {cos_sim_shallow.item():.6f}")
print(f"32层 GCN: 节点 {node_a_idx} 和 {node_b_idx} 的特征余弦相似度: {cos_sim_deep.item():.6f}")
# 预期结果:
# 2层 GCN 的相似度会比较低 (例如 0.1 到 0.5 之间,取决于随机初始化)
# 32层 GCN 的相似度会 *极其* 接近 1.0 (例如 0.999999)
if cos_sim_deep.item() > 0.99:
print("\n[!!] 演示成功:在 32 层后,两个节点的特征向量几乎完全相同。")
print("这就是'过平滑':模型失去了区分节点的能力。")
# (可选) 检查整个图的特征方差
# 方差接近 0 意味着所有特征都一样了
var_shallow = out_shallow.var(dim=0).mean().item()
var_deep = out_deep.var(dim=0).mean().item()
print(f"\n2层 GCN 的平均特征方差: {var_shallow:.6e}")
print(f"32层 GCN 的平均特征方差: {var_deep:.6e}")
# 预期结果:深层 GCN 的方差会小几个数量级
1.2 图的代数性质 (深度实现版)

# 导入核心库
import networkx as nx
import numpy as np
import matplotlib.pyplot as plt
import scipy.sparse as sp
from scipy.sparse.linalg import eigsh, ArpackNoConvergence
import warnings
# --- Matplotlib 可视化设置 (确保中文显示) ---
plt.rcParams['font.sans-serif'] = ['SimHei', 'Heiti TC', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 110 # 提高分辨率
warnings.filterwarnings("ignore", category=UserWarning)
# --- 1. 准备工作:杠铃图和 L_sym ---
N1 = 10 # 左侧团簇 10 个节点
N2 = 0 # 两个团簇间 0 条边(只有1条边连接两个团簇)
G = nx.barbell_graph(N1, N2)
N = G.number_of_nodes() # 总节点数 N = 20
nodelist = list(G.nodes()) # 固定节点顺序 [0, 1, ..., 19]
pos = nx.spring_layout(G, seed=42) # 固定可视化布局
# 我们将使用归一化拉普拉斯 L_sym = I - D^(-1/2) * A * D^(-1/2)
# 它是 GCN 和谱分析的标准选择
L_sym_sparse = nx.normalized_laplacian_matrix(G, nodelist=nodelist).asformat('csr')
# L_sym 是对称且半正定的,其特征值 λ 范围为 [0, 2]
print(f"示例图:杠铃图 (N={N})")
print(f"L_sym 稀疏矩阵 (CSR 格式):\n{L_sym_sparse.toarray()[:5, :5]}...")
1.2.1 拉普拉斯谱分解与特征向量

1.2.1.A: 精确谱分解 (Dense, 教学用)
![]()
def get_full_spectrum(L_sparse):
"""
(教学用) 对稀疏拉普拉斯矩阵进行完全谱分解。
挑战:L.toarray() 在 N > ~10k 时会 OOM (内存溢出)
np.linalg.eigh 是 O(N^3) 计算
"""
print("--- (教学) 执行完全谱分解 (Dense)... ---")
# 1. 转换为稠密矩阵 (昂贵!)
L_dense = L_sparse.toarray()
# 2. 使用 eigh (专为对称矩阵优化,保证实数结果)
# eigenvalues 按升序排列
# U 的第 k 列 U[:, k] 是对应 eigenvalues[k] 的特征向量
eigenvalues, U = np.linalg.eigh(L_dense)
print(f" 特征值 (Λ) 形状: {eigenvalues.shape}")
print(f" 特征向量 (U) 形状: {U.shape}")
# 验证分解: L_sym = U Λ U^T
Lambda = np.diag(eigenvalues)
L_reconstructed = U @ Lambda @ U.T
# np.allclose 用于浮点数比较
assert np.allclose(L_dense, L_reconstructed), "谱分解重构失败"
print(" 谱分解验证成功: L = U Λ U^T")
return eigenvalues, U
# 执行完全分解
eigenvalues, U = get_full_spectrum(L_sym_sparse)
print(f"最小的 3 个特征值 (频率): {eigenvalues[:3]}")
print(f"最大的 3 个特征值 (频率): {eigenvalues[-3:]}")
1.2.1.B: 近似谱分解 (Sparse, 实践用)
![]()
def get_sparse_spectrum(L_sparse, k=5):
"""
(实践用) 高效计算 L_sparse 的 k 个最小特征值/向量。
使用 ARPACK 迭代求解器 (通过 eigsh)
"""
print(f"\n--- (实践) 执行稀疏谱分解 (Sparse, k={k})... ---")
# 挑战:k 必须 < N-1
if k >= L_sparse.shape[0] - 1:
print(f" 警告: k={k} 太大, 调整为 k={L_sparse.shape[0] - 2}")
k = L_sparse.shape[0] - 2
try:
# L_sparse 必须是 float 类型
L_sparse_float = L_sparse.astype(np.float64)
# which='SM' -> Smallest Magnitude (最小的幅度)
# 这对于 L_sym (特征值 >= 0) 意味着最小的特征值
# 返回值默认按升序排列
lambda_k, U_k = eigsh(L_sparse_float, k=k, which='SM')
print(f" 稀疏-特征值 (λ_k) 形状: {lambda_k.shape}")
print(f" 稀疏-特征向量 (U_k) 形状: {U_k.shape}")
print(f" 计算出的 {k} 个最小特征值: {lambda_k}")
return lambda_k, U_k
except ArpackNoConvergence:
print(f" 错误: eigsh (ARPACK) 未能收敛。")
return None, None
except Exception as e:
print(f" 错误: {e}")
return None, None
# 执行稀疏分解
lambda_k, U_k = get_sparse_spectrum(L_sym_sparse, k=5)
# 验证稀疏结果与完全分解结果一致
assert np.allclose(eigenvalues[:5], lambda_k), "稀疏与稠密特征值不匹配"
print(" 稀疏谱分解验证成功 (前 k 个值匹配)")
1.2.1.C: 可视化特征向量 (图的振动模式)
我们将使用完全分解的 $U$ 来可视化,因为它包含了所有频率。
Python
def plot_eigenvector(ax, G, pos, vec, title):
"""辅助函数:在图上绘制特征向量信号"""
# 标准化 vec (例如 -1 到 1) 以便 cmap 映射
# u_k 和 -u_k 都是有效特征向量,我们标准化方向
if np.sum(vec) < 0:
vec = -vec
vmin, vmax = np.min(vec), np.max(vec)
nx.draw(G, pos, ax=ax, node_color=vec, cmap='coolwarm',
vmin=-np.abs(vmax), vmax=np.abs(vmax), # 对称色条
with_labels=False, node_size=200)
ax.set_title(title, fontsize=10)
fig, axes = plt.subplots(1, 4, figsize=(20, 4))
fig.suptitle("1.2.1: 图的“振动模式” (L_sym 特征向量)", fontsize=16)
# 1. 模式 0 (k=0): 最低频 "DC 信号"
vec_0 = U[:, 0]
plot_eigenvector(axes[0], G, pos, vec_0,
f"u_0 (k=0, DC 信号)\nλ_0 = {eigenvalues[0]:.2e}")
# 2. 模式 1 (k=1): Fiedler 向量 "社区信号"
vec_1 = U[:, 1]
plot_eigenvector(axes[1], G, pos, vec_1,
f"u_1 (Fiedler 向量)\nλ_1 = {eigenvalues[1]:.3f} (低频)")
# 3. 模式 5 (k=5): 中频
vec_5 = U[:, 5]
plot_eigenvector(axes[2], G, pos, vec_5,
f"u_5 (k=5, 中频)\nλ_5 = {eigenvalues[5]:.3f}")
# 4. 模式 N-1 (k=19): 最高频 "噪声信号"
vec_N_1 = U[:, N-1]
plot_eigenvector(axes[3], G, pos, vec_N_1,
f"u_{N-1} (k={N-1}, 最高频)\nλ_{N-1} = {eigenvalues[N-1]:.3f}")
plt.tight_layout(rect=[0, 0.03, 1, 0.90])
plt.savefig("1.2.1_eigenvectors_deep.png")
# plt.show()
可视化解读:

1.2.2 谱域滤波与频谱解释
1.2.2.A: 频谱解释 (量化平滑度)
def calculate_smoothness(x, L_sym):
"""计算拉普拉斯二次型 (总变异/平滑度)"""
# x 必须是 (N,) 向量
# L_sym 必须是 (N, N) 矩阵 (稀疏或稠密)
return x.T @ L_sym @ x
print("\n--- 1.2.2.A: 量化信号平滑度 ---")
# 信号 1: 高频 (随机噪声)
x_high_freq = np.random.randn(N)
x_high_freq /= np.linalg.norm(x_high_freq) # 归一化能量
# 信号 2: 低频 (u_1, Fiedler 向量)
x_low_freq = U[:, 1] # 已经归一化
# 信号 3: 社区信号 (手动创建)
x_community = np.ones(N)
x_community[:N1] = -1.0
x_community /= np.linalg.norm(x_community)
# L_sym_sparse 是 SciPy 稀疏矩阵,它能正确处理 @ 运算符
smooth_high = calculate_smoothness(x_high_freq, L_sym_sparse)
smooth_low_fiedler = calculate_smoothness(x_low_freq, L_sym_sparse)
smooth_low_community = calculate_smoothness(x_community, L_sym_sparse)
print(f" 高频 (随机) 信号平滑度 (x^T L x): {smooth_high:.4f}")
print(f" 低频 (Fiedler) 信号平滑度 (x^T L x): {smooth_low_fiedler:.4f}")
print(f" 低频 (社区) 信号平滑度 (x^T L x): {smooth_low_community:.4f}")
# 关键洞察:
# x_low_freq (u_1) 是 L_sym 的特征向量。
# 根据线性代数: L_sym @ u_1 = λ_1 * u_1
# 所以: u_1^T @ L_sym @ u_1 = u_1^T @ (λ_1 * u_1) = λ_1 * (u_1^T @ u_1)
# 因为 u_1 归一化了 (u_1^T u_1 = 1), 所以 u_1^T L_sym u_1 = λ_1
assert np.allclose(smooth_low_fiedler, eigenvalues[1])
print(f" (验证成功:Fiedler 向量的平滑度 == λ_1)")
1.2.2.B: 谱域滤波 (精确,教学用)

def spectral_filter(x, U, eigenvalues, filter_func):
"""
(教学用) 使用完全分解在谱域中过滤信号 x。
实现: x_filt = U * h(Λ) * (U^T * x)
"""
# 1. GFT (分析): x -> x_hat
# (U.T @ x) 将 x 投影到 N 个特征向量基上
x_hat = U.T @ x
# 2. 滤波: h(λ) * x_hat
# h(Λ) 是一个对角矩阵,其 (k,k) 元素是 filter_func(λ_k)
# 我们可以用逐元素乘法高效实现
h_lambda = filter_func(eigenvalues)
x_hat_filtered = h_lambda * x_hat
# 3. IGFT (合成): x_hat_filt -> x_filt
x_filtered = U @ x_hat_filtered
return x_filtered
# 定义低通滤波器函数
tau = 5.0 # 滤波强度 (τ 越大,平滑越强)
low_pass_kernel = lambda l: np.exp(-tau * l)
# 定义高通滤波器函数 (仅为对比)
high_pass_kernel = lambda l: 1.0 - np.exp(-tau * l)
print(f"\n--- 1.2.2.B: 执行谱域滤波 (τ={tau}) ---")
# 1. 对高频随机信号进行低通滤波
x_low_passed = spectral_filter(x_high_freq, U, eigenvalues, low_pass_kernel)
# 2. 对高频随机信号进行高通滤波
x_high_passed = spectral_filter(x_high_freq, U, eigenvalues, high_pass_kernel)
# --- 可视化滤波效果 ---
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
fig.suptitle(f"1.2.2: 谱域滤波 (τ={tau})", fontsize=16)
plot_eigenvector(axes[0], G, pos, x_high_freq, "原始信号 (高频/随机)")
plot_eigenvector(axes[1], G, pos, x_low_passed, "低通滤波 (平滑)")
plot_eigenvector(axes[2], G, pos, x_high_passed, "高通滤波 (振荡)")
plt.tight_layout(rect=[0, 0.03, 1, 0.90])
plt.savefig("1.2.2_filtering_deep.png")
# plt.show()
可视化解读 (关键):
-
原始信号: 完全随机的噪声。
-
低通滤波: 噪声被“抹平”了。剩下的信号清晰地揭示了图的社区结构(左红右蓝)。我们从噪声中恢复了结构!
-
高通滤波: 结构被移除了,只剩下高频振荡。
1.2.2.C: 谱域滤波 (近似,实践用)
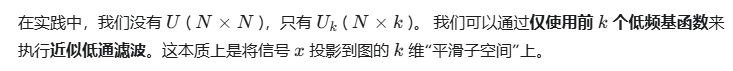
def approximate_low_pass_filter(x, U_k):
"""
(实践用) 使用 k 个最小特征向量 U_k 近似低通滤波。
实现: x_approx = U_k @ (U_k.T @ x)
这会将 x 投影到 U_k 张成的子空间上。
"""
# U_k: (N, k)
# x: (N,)
# 1. 分析 (GFT): (k, 1) = (k, N) @ (N, 1)
x_hat_k = U_k.T @ x
# 2. 合成 (IGFT): (N, 1) = (N, k) @ (k, 1)
x_approx = U_k @ x_hat_k
return x_approx
print(f"\n--- 1.2.2.C: 执行近似低通滤波 (k={lambda_k.shape[0]}) ---")
# U_k 是 1.2.1.B 中计算的 (N, 5) 矩阵
x_approx_filtered = approximate_low_pass_filter(x_high_freq, U_k)
# 可视化
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plot_eigenvector(plt.gca(), G, pos, x_high_freq, "原始信号 (高频/随机)")
plt.subplot(1, 2, 2)
plot_eigenvector(plt.gca(), G, pos, x_approx_filtered, f"近似低通滤波 (仅 k={lambda_k.shape[0]} 个基)")
plt.suptitle("1.2.2.C: 实践中的近似滤波 (k-NN)", fontsize=16)
plt.tight_layout(rect=[0, 0.03, 1, 0.90])
plt.savefig("1.2.2_filtering_approx.png")
# plt.show()
可视化解读:
结果与“精确”低通滤波非常相似!这证明了我们不需要 $O(N^3)$ 的完全分解。我们只需 $k$ 个基向量,就能捕捉到图的大部分“结构化”信息。
1.2.3 图傅里叶变换与卷积定义

Python
print("\n--- 1.2.3 GFT 与卷积定义 ---")
def gft(x, U):
"""(教学用) GFT: (N, F) -> (N, F)"""
return U.T @ x
def igft(x_hat, U):
"""(教学用) IGFT: (N, F) -> (N, F)"""
return U @ x_hat
def spectral_convolution(x, h, U):
"""(教学用) 经典谱卷积定义"""
# x: (N, 1)
# h: (N, 1) (空间域的滤波器核)
# U: (N, N)
# 1. GFT
x_hat = gft(x, U) # (N, 1)
h_hat = gft(h, U) # (N, 1)
# 2. 谱域乘积
convolved_hat = x_hat * h_hat # 逐元素乘积
# 3. IGFT
convolved = igft(convolved_hat, U)
return convolved
# --- 演示 ---
# 1. 验证 GFT/IGFT 可逆性
x_test = x_high_freq
x_reconstructed = igft(gft(x_test, U), U)
print(f"GFT/IGFT 可逆性验证: {np.allclose(x_test, x_reconstructed)}")
# 2. 演示 GNN 的 "滤波" 与 "卷积" 的等价性
# GNN 的方法 (滤波)
h_lambda = low_pass_kernel(eigenvalues) # h(λ)
x_filtered = U @ (np.diag(h_lambda) @ (U.T @ x_test))
# 经典卷积的方法
# 我们需要找到一个空间信号 h, 使得 h_hat = h(λ)
# h = IGFT(h(λ))
h_spatial_kernel = igft(h_lambda, U)
x_convolved = spectral_convolution(x_test, h_spatial_kernel, U)
print(f"GNN滤波 与 经典卷积 是否等价: {np.allclose(x_filtered, x_convolved)}")
print(" (成功!GNN 的谱卷积是一种高效的、可学习的谱域滤波。)")
1.2.4 图谱不变性与对称性分析

-
挑战: 仅凭谱相同不能 100% 保证图同构(存在“同谱图”),但它是一个非常强的必要条件。
Python
print("\n--- 1.2.4 图谱不变性 (同构测试) ---")
# G 是我们的原始杠铃图 (节点 0-19)
# 1. 创建一个 G 的同构图 G_iso
# 我们将节点标签随机打乱 (置换)
permutation = np.random.permutation(N)
# 映射: {0: p_0, 1: p_1, ...}
relabel_map = {i: permutation[i] for i in range(N)}
G_iso = nx.relabel_nodes(G, relabel_map)
# 2. 计算 G_iso 的谱
L_sym_iso_sparse = nx.normalized_laplacian_matrix(G_iso, nodelist=list(G_iso.nodes()))
eigenvalues_iso, U_iso = get_full_spectrum(L_sym_iso_sparse) # (教学用)
# 3. 比较谱
print(f"原始图 G 的前 5 个特征值:\n {eigenvalues[:5]}")
print(f"同构图 G_iso 的前 5 个特征值:\n {eigenvalues_iso[:5]}")
are_spectra_identical = np.allclose(eigenvalues, eigenvalues_iso)
print(f"\n[结论] 同构图的特征值谱是否完全相同: {are_spectra_identical}")
assert are_spectra_identical
# 4. 特征向量并不同!它们被置换了。
are_vectors_identical = np.allclose(U, U_iso)
print(f" 同构图的特征向量矩阵是否相同: {are_vectors_identical}")
assert not are_vectors_identical
2. 对称性 (自同构)
图的几何对称性(例如杠铃图的左右对称)会直接导致谱的代数对称性(重叠的特征值,即特征值简并)。
-
杠铃图是左右对称的。这意味着如果我们交换左团簇 (0-9) 和右团簇 (10-19),图的结构不变。
-
这种对称性导致很多特征值是成对出现的(简并度=2)。
-
Fiedler 向量
u_1必须是反对称的:$u_1[i] = -u_1[i+10]$。 -
DC 向量
u_0必须是对称的:$u_0[i] = u_0[i+10]$。
Python
print("\n--- 1.2.4 图的对称性 (自同构) ---")
# 1. 检查重叠的特征值
# 我们打印相邻特征值之间的差异
eigenvalue_diffs = np.diff(eigenvalues)
print(f"特征值之间的差异 (前 10 个):\n{eigenvalue_diffs[:10]}")
# 观察:很多差异接近 0 (例如 e-16),这意味着特征值重叠了
overlapping_eigenvalues = np.sum(eigenvalue_diffs < 1e-10)
print(f"\n检测到 {overlapping_eigenvalues} 对重叠/简并的特征值。")
# 2. 验证 Fiedler 向量 u_1 的反对称性
vec_1 = U[:, 1]
# 标准化方向
if np.mean(vec_1[:N1]) > 0:
vec_1 = -vec_1
left_cluster_mean = np.mean(vec_1[:N1]) # 节点 0-9
right_cluster_mean = np.mean(vec_1[N1:]) # 节点 10-19
print(f"\nFiedler 向量 u_1 (反对称):")
print(f" 左团簇均值: {left_cluster_mean:.4f} (应为负)")
print(f" 右团簇均值: {right_cluster_mean:.4f} (应为正)")
assert np.allclose(left_cluster_mean, -right_cluster_mean)
print(" (验证成功:u_1 是反对称的)")
# 3. 验证 u_0 的对称性
vec_0 = U[:, 0]
left_cluster_mean_u0 = np.mean(vec_0[:N1])
right_cluster_mean_u0 = np.mean(vec_0[N1:])
print(f"\nDC 向量 u_0 (对称):")
print(f" 左团簇均值: {left_cluster_mean_u0:.4f}")
print(f" 右团簇均值: {right_cluster_mean_u0:.4f}")
assert np.allclose(left_cluster_mean_u0, right_cluster_mean_u0)
print(" (验证成功:u_0 是对称的)")
所有代码都将是完整且可执行的。我们将使用 networkx、numpy、scipy 和 matplotlib。
# --- 核心导入 ---
import networkx as nx
import numpy as np
import matplotlib.pyplot as plt
import scipy.sparse as sp
import random
from collections import Counter
# --- Matplotlib 可视化设置 (确保中文显示) ---
plt.rcParams['font.sans-serif'] = ['SimHei', 'Heiti TC', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 110
1.3 图的概率模型与随机过程
1.3.1 随机游走与马尔可夫链
理论阐述:
图上的随机游走 (Random Walk) 是一种随机过程,描述了一个“游走者”在节点间移动。当下一步的转移概率只依赖于当前节点(而与历史路径无关)时,该过程就是一个马尔可夫链 (Markov Chain)。

def get_transition_matrix(G):
"""
计算图 G 的马尔可夫转移概率矩阵 P = D^{-1}A。
参数:
G (nx.Graph or nx.DiGraph): NetworkX 图对象。
返回:
P (np.ndarray): 转移概率矩阵 (N x N, 稠密)。
nodelist (list): P 中行/列 对应的节点列表。
"""
# 1. 获取邻接矩阵 A (使用 networkx 的高效实现)
# 指定 nodelist 确保矩阵顺序
nodelist = list(G.nodes())
N = len(nodelist)
if N == 0:
return np.array([]), nodelist
# 获取带权的邻接矩阵 (CSR 稀疏格式)
# 对于无权图,权重默认为 1
A_sparse = nx.to_scipy_sparse_array(G, nodelist=nodelist, weight='weight', format='csr')
# 2. 计算出度/强度 (D)
# A.sum(axis=1) 计算每行的和,返回一个 (N, 1) 的矩阵
out_strength = np.asarray(A_sparse.sum(axis=1)).flatten()
# 3. 挑战:处理零度节点 (Sinks)
zero_strength_mask = (out_strength == 0)
# 4. 构建 D^{-1}
# 初始化 D_inv 为 0,避免除零
inv_strength = np.zeros_like(out_strength)
# 只在非零强度的位置计算 1/strength
inv_strength[~zero_strength_mask] = 1.0 / out_strength[~zero_strength_mask]
# D_inv_sparse 是 D^{-1} 的稀疏对角矩阵
D_inv_sparse = sp.diags(inv_strength, format='csr')
# 5. 计算 P = D^{-1}A
P_sparse = D_inv_sparse @ A_sparse
# 6. (关键) 处理零度节点的"陷入"规范
# 将 P[i, i] 设为 1 (对于度为 0 的节点 i)
P_sparse = P_sparse.tolil() # LIL 格式支持高效的对角线赋值
P_sparse[zero_strength_mask, zero_strength_mask] = 1.0
P_sparse = P_sparse.tocsr()
# 返回稠密矩阵以便于教学和 numpy 操作
return P_sparse.toarray(), nodelist
def simulate_random_walk(G, start_node, walk_length):
"""
在图 G 上模拟一次随机游走。
参数:
G (nx.Graph): NetworkX 图对象 (带权或无权)
start_node: 起始节点
walk_length (int): 游走步数
返回:
path (list): 包含游走路径的节点列表
"""
if start_node not in G:
raise ValueError(f"起始节点 {start_node} 不在图中。")
path = [start_node]
current_node = start_node
for _ in range(walk_length - 1):
# 获取所有邻居
neighbors = list(G.neighbors(current_node))
if not neighbors:
# 这是一个 "sink" (没有出边),游走被困住
# 我们让它停在原地以匹配我们的 P 矩阵
path.append(current_node)
continue
# 检查图是否带权
if nx.is_weighted(G):
# 提取权重
weights = [G[current_node][neighbor].get('weight', 1.0) for neighbor in neighbors]
# 根据权重随机选择
next_node = random.choices(neighbors, weights=weights, k=1)[0]
else:
# 无权图:均匀选择
next_node = random.choice(neighbors)
path.append(next_node)
current_node = next_node
return path
# --- 完整可执行示例 (1.3.1) ---
if __name__ == "__main__":
print("--- 1.3.1 随机游走与马尔可夫链 ---")
# 1. 创建一个带权有向图
G_walk = nx.DiGraph()
G_walk.add_edges_from([(1, 2, {'weight': 2.0}), (1, 3, {'weight': 1.0}),
(2, 3, {'weight': 1.0}), (3, 1, {'weight': 3.0}),
(3, 4, {'weight': 1.0}), (4, 4, {'weight': 1.0})]) # 4 是一个 sink/陷阱
G_walk.add_node(5) # 5 是一个孤立节点
# 2. 计算转移矩阵 P
P, nodelist = get_transition_matrix(G_walk)
node_map = {node: i for i, node in enumerate(nodelist)} # 节点到索引的映射
print(f"节点列表 (P 的顺序): {nodelist}")
print("转移矩阵 P (P_ij = P(i -> j)):")
print(np.round(P, 3))
# 验证 P[i,i] = 1 对于 sinks (节点4) 和 isolates (节点5)
print(f" P[4, 4] (Sink): {P[node_map[4], node_map[4]]}")
print(f" P[5, 5] (Isolate): {P[node_map[5], node_map[5]]}")
# 验证 P[1,:] 的和
print(f" P[1, 2]: {P[node_map[1], node_map[2]]:.3f} (预期 2.0 / (2.0+1.0) = 0.667)")
print(f" P[1, 3]: {P[node_map[1], node_map[3]]:.3f} (预期 1.0 / (2.0+1.0) = 0.333)")
# 3. 模拟一次随机游走
start_node = 1
steps = 10
path = simulate_random_walk(G_walk, start_node, steps)
print(f"\n从 {start_node} 开始 {steps} 步的随机游走:\n{' -> '.join(map(str, path))}")
# 4. 验证 P^k
# (P^k)[i, j] 是从 i 到 j 恰好 k 步的概率
k = 3
P_k = np.linalg.matrix_power(P, k)
idx_start, idx_end = node_map[1], node_map[3]
print(f"\n(P^{k})[1, 3] (3 步内 1 -> 3 的概率): {P_k[idx_start, idx_end]:.4f}")
# 5. 可视化
plt.figure(figsize=(10, 6))
plt.title(f"1.3.1: 随机游走路径 (k={steps})")
pos = nx.spring_layout(G_walk, seed=42)
nx.draw(G_walk, pos, with_labels=True, node_color='lightblue', node_size=600,
connectionstyle='arc3,rad=0.1')
# 绘制游走路径
path_edges = list(zip(path[:-1], path[1:]))
nx.draw_networkx_edges(G_walk, pos, edgelist=path_edges, width=2.5,
edge_color='red', arrowsize=20,
connectionstyle='arc3,rad=0.1')
plt.savefig("1.3.1_random_walk.png")
# plt.show()
1.3.2 图生成模型与随机图谱模型(ER、BA、WS)
理论阐述:

深度实现:
networkx 提供了这些模型的生成器。本节的“深度”在于分析和可视化它们的关键区别——度分布,特别是 BA 模型的幂律特性(必须在log-log尺度上查看)。
代码实现:
def plot_degree_distribution(G, ax, title, log_log_scale=False):
"""
在给定的 matplotlib 轴上绘制图 G 的度分布。
"""
# 1. 获取度序列
degrees = [d for n, d in G.degree()]
if not degrees:
return # 空图
# 2. 计算度的频次 (count)
degree_counts = Counter(degrees)
k, count = zip(*sorted(degree_counts.items()))
# 3. 归一化 (概率)
N = G.number_of_nodes()
probabilities = [c / N for c in count]
# 4. 绘图
if log_log_scale:
# log-log 尺度,用于检查幂律
ax.scatter(k, probabilities, alpha=0.7, s=20)
ax.set_xscale('log')
ax.set_yscale('log')
ax.set_title(title + " (Log-Log 尺度)")
ax.set_xlabel("Log(度 k)")
ax.set_ylabel("Log(P(k))")
else:
# 线性尺度
ax.bar(k, probabilities, width=0.8, alpha=0.7)
ax.set_title(title + " (线性尺度)")
ax.set_xlabel("度 k")
ax.set_ylabel("P(k)")
# 计算平均度
avg_degree = np.mean(degrees)
ax.axvline(avg_degree, color='r', linestyle='--', linewidth=2,
label=f'平均度 ≈ {avg_degree:.2f}')
ax.legend(fontsize='small')
# --- 完整可执行示例 (1.3.2) ---
if __name__ == "__main__":
print("\n--- 1.3.2 图生成模型 (ER, WS, BA) ---")
# 1. 定义参数
N = 1000 # 节点数
AVG_DEGREE = 8 # 期望的平均度
# 2. ER 模型: G(n, p)
# E[k] = p * (N - 1) => p = E[k] / (N - 1)
p_er = AVG_DEGREE / (N - 1)
G_er = nx.erdos_renyi_graph(N, p_er, seed=42)
# 3. WS 模型: G(n, k, p)
# k 必须是偶数
k_ws = AVG_DEGREE
p_ws = 0.1 # 重连概率 (0.1 是典型值)
G_ws = nx.watts_strogatz_graph(N, k=k_ws, p=p_ws, seed=42)
# 4. BA 模型: G(n, m)
# m = 新节点连接的边数
# E[k] ≈ 2m => m = E[k] / 2
m_ba = int(AVG_DEGREE / 2)
G_ba = nx.barabasi_albert_graph(N, m=m_ba, seed=42)
# 5. 可视化度分布 (关键对比)
# 我们创建 2x3 的子图
fig, axes = plt.subplots(2, 3, figsize=(18, 10))
fig.suptitle(f"1.3.2: 三种图生成模型的度分布 (N={N})", fontsize=16)
# 线性尺度 (第 1 行)
plot_degree_distribution(G_er, axes[0, 0], f"ER (p={p_er:.3f})", log_log_scale=False)
plot_degree_distribution(G_ws, axes[0, 1], f"WS (k={k_ws}, p={p_ws})", log_log_scale=False)
plot_degree_distribution(G_ba, axes[0, 2], f"BA (m={m_ba})", log_log_scale=False)
# Log-Log 尺度 (第 2 行)
plot_degree_distribution(G_er, axes[1, 0], f"ER (p={p_er:.3f})", log_log_scale=True)
plot_degree_distribution(G_ws, axes[1, 1], f"WS (k={k_ws}, p={p_ws})", log_log_scale=True)
plot_degree_distribution(G_ba, axes[1, 2], f"BA (m={m_ba})", log_log_scale=True)
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.savefig("1.3.2_model_distributions.png")
# plt.show()
print(" [观察] ER 呈泊松分布 (钟形)。")
print(" [观察] WS 呈尖峰分布 (更规则)。")
print(" [观察] BA 在 Log-Log 尺度上呈一条直线,这正是'幂律'分布的特征。")
1.3.3 图的稳态分布与吸收概率
1.3.3.A 稳态分布 (Stationary Distribution)

Python
def get_stationary_distribution_fast(G):
"""
(优化) 仅适用于 *无向* 且 *连通* 的图。
π_i = deg(i) / (2|E|)
"""
if not G.is_directed() and nx.is_connected(G):
N = G.number_of_nodes()
if N == 0:
return {}, []
# 1. 获取度 (带权)
# G.degree(weight='weight') 返回一个迭代器
degrees = dict(G.degree(weight='weight'))
nodelist = list(degrees.keys())
degree_vec = np.array([degrees[n] for n in nodelist])
# 2. 计算 2|E| (或 sum(deg))
total_degree = np.sum(degree_vec)
if total_degree == 0:
# 图中没有边
pi_vec = np.ones(N) / N
else:
pi_vec = degree_vec / total_degree
return {nodelist[i]: pi_vec[i] for i in range(N)}, nodelist
else:
raise ValueError("快速方法仅适用于无向连通图。请使用迭代法。")
def get_stationary_distribution_iterative(P, nodelist, max_iter=1000, tol=1e-6):
"""
(通用) 使用幂迭代法 (Power Iteration) 计算稳态分布。
π_k+1 = π_k * P
"""
N = P.shape[0]
if N == 0:
return {}, []
# 1. 从一个均匀分布开始
pi_vec = np.ones(N) / N
for i in range(max_iter):
pi_vec_new = pi_vec @ P
# 检查收敛 (L1 范数)
diff = np.linalg.norm(pi_vec_new - pi_vec, ord=1)
if diff < tol:
# print(f" 在 {i+1} 次迭代后收敛。")
pi_vec = pi_vec_new
break
pi_vec = pi_vec_new
# 归一化 (确保和为 1)
pi_vec = pi_vec / np.sum(pi_vec)
return {nodelist[i]: pi_vec[i] for i in range(N)}, nodelist
# --- 完整可执行示例 (1.3.3.A) ---
if __name__ == "__main__":
print("\n--- 1.3.3.A 稳态分布 ---")
# 1. 使用 Zachary's Karate Club (无向, 连通)
G_karate = nx.karate_club_graph()
# 2. 方法 1: 快速 (无向)
pi_fast, nodelist_fast = get_stationary_distribution_fast(G_karate)
print(f"节点列表 (Fast): {nodelist_fast[:5]}...")
print(f" π(0) [Fast]: {pi_fast[0]:.4f} (节点0度数高)")
print(f" π(16) [Fast]: {pi_fast[16]:.4f} (节点16度数低)")
# 3. 方法 2: 通用 (迭代)
P_karate, nodelist_iter = get_transition_matrix(G_karate)
pi_iter, _ = get_stationary_distribution_iterative(P_karate, nodelist_iter)
print(f"\n节点列表 (Iter): {nodelist_iter[:5]}...")
print(f" π(0) [Iter]: {pi_iter[0]:.4f}")
print(f" π(16) [Iter]: {pi_iter[16]:.4f}")
# 4. 验证两者是否一致
assert np.allclose(pi_fast[0], pi_iter[0])
print("\n (验证成功:两种方法结果一致)")
1.3.3.B 吸收概率 (Absorption Probabilities)

def get_absorption_probabilities(G, absorbing_nodes):
"""
计算从所有瞬态节点到所有吸收态节点的吸收概率。
参数:
G (nx.Graph): 图
absorbing_nodes (list): 吸收态节点的列表
返回:
B (np.ndarray): 吸收概率矩阵 (t x r)
t_map (list): 瞬态节点列表 (B 的行索引)
a_map (list): 吸收态节点列表 (B 的列索引)
"""
nodelist = list(G.nodes())
node_to_idx = {node: i for i, node in enumerate(nodelist)}
# 1. 识别瞬态 (t) 和吸收态 (r)
a_map = sorted(list(absorbing_nodes)) # 吸收态 (r)
t_map = sorted([n for n in nodelist if n not in absorbing_nodes]) # 瞬态 (t)
t = len(t_map) # 瞬态数量
r = len(a_map) # 吸收态数量
if t == 0 or r == 0:
print(" 警告:图中没有瞬态或吸收态。")
return np.array([]), t_map, a_map
# 2. 获取 *标准* 转移矩阵 P
P, _ = get_transition_matrix(G)
# 3. 挑战:重构 P,使吸收态 *真正* 吸收 (P_ii = 1)
for a_node in a_map:
a_idx = node_to_idx[a_node]
P[a_idx, :] = 0.0 # 清空所有出边
P[a_idx, a_idx] = 1.0 # 设置自环为 1
# 4. 构建 Q 和 R
Q = np.zeros((t, t))
R = np.zeros((t, r))
t_node_to_idx = {node: i for i, node in enumerate(t_map)}
a_node_to_idx = {node: i for i, node in enumerate(a_map)}
for t_node in t_map:
t_idx_local = t_node_to_idx[t_node] # Q/R 中的行索引 (0..t-1)
t_idx_global = node_to_idx[t_node] # P 中的行索引 (0..N-1)
# 填充 Q (瞬态 -> 瞬态)
for t_node_j in t_map:
t_idx_j_local = t_node_to_idx[t_node_j]
t_idx_j_global = node_to_idx[t_node_j]
Q[t_idx_local, t_idx_j_local] = P[t_idx_global, t_idx_j_global]
# 填充 R (瞬态 -> 吸收态)
for a_node_k in a_map:
a_idx_k_local = a_node_to_idx[a_node_k]
a_idx_k_global = node_to_idx[a_node_k]
R[t_idx_local, a_idx_k_local] = P[t_idx_global, a_idx_k_global]
# 5. 计算 N = (I - Q)^-1
try:
I_t = np.identity(t)
N_matrix = np.linalg.inv(I_t - Q)
except np.linalg.LinAlgError:
print(" 错误:(I - Q) 矩阵是奇异的,无法计算吸收概率。")
return None, t_map, a_map
# 6. 计算 B = N * R
B = N_matrix @ R
return B, t_map, a_map
# --- 完整可执行示例 (1.3.3.B) ---
if __name__ == "__main__":
print("\n--- 1.3.3.B 吸收概率 ---")
# 1. 创建 "赌徒破产" 图 (1D 随机游走)
# 0 -- 1 -- 2 -- 3 -- 4
# 0 = 破产 (吸收), 4 = 赢 (吸收)
G_gambler = nx.path_graph(5)
absorbing_states = [0, 4]
# 2. 计算吸收概率
B, t_nodes, a_nodes = get_absorption_probabilities(G_gambler, absorbing_states)
print(f"吸收态 (B 的列): {a_nodes}")
print(f"瞬态 (B 的行): {t_nodes}")
print("吸收概率矩阵 B (行=瞬态, 列=吸收态):")
print(np.round(B, 3))
# 3. 解读
# B[1, 0] = P(从 2 开始, 在 0 结束) (t_nodes[1]=2, a_nodes[0]=0)
idx_start_2 = t_nodes.index(2) # B 中的行索引
idx_end_0 = a_nodes.index(0) # B 中的列索引
idx_end_4 = a_nodes.index(4) # B 中的列索引
print(f"\n P(从 1 开始, 在 0 结束): {B[t_nodes.index(1), idx_end_0]:.2f} (预期 0.75)")
print(f" P(从 2 开始, 在 0 结束): {B[idx_start_2, idx_end_0]:.2f} (预期 0.5)")
print(f" P(从 2 开始, 在 4 结束): {B[idx_start_2, idx_end_4]:.2f} (预期 0.5)")
1.3.4 基于随机过程的结构相似性度量

def get_rwr_similarity_vector(G, source_node, restart_prob=0.15):
"""
计算从 source_node 开始的随机游走与重启 (RWR) 的稳态分布。
参数:
G: 图
source_node: 源节点 (重启向量将集中在此)
restart_prob (float): 重启概率 (RWR 定义中的 α)
返回:
rwr_scores (dict): {node: score} 的字典
"""
# 1. 关键:转换 alpha
# nx.pagerank 的 alpha 是 "damping factor" (继续游走的概率)
nx_alpha = 1.0 - restart_prob
# 2. 创建个性化向量 (重启向量)
personalization = {node: 0 for node in G.nodes()}
personalization[source_node] = 1.0
# 3. 计算 PageRank
rwr_scores = nx.pagerank(G,
alpha=nx_alpha,
personalization=personalization,
weight='weight')
return rwr_scores
def get_symmetric_rwr_similarity(G, u, v, restart_prob=0.15):
"""
计算 u 和 v 之间对称的 RWR 相似性。
Sim(u, v) = π_u(v) + π_v(u)
"""
# 1. 计算 π_u
pi_u = get_rwr_similarity_vector(G, u, restart_prob)
sim_u_v = pi_u.get(v, 0) # π_u(v)
# 2. 计算 π_v
pi_v = get_rwr_similarity_vector(G, v, restart_prob)
sim_v_u = pi_v.get(u, 0) # π_v(u)
# 3. 对称相似性
return sim_u_v + sim_v_u
# --- 完整可执行示例 (1.3.4) ---
if __name__ == "__main__":
print("\n--- 1.3.4 基于 RWR 的结构相似性 ---")
# 1. 使用 Karate Club 图
G_karate = nx.karate_club_graph()
# 2. 选取比较对
node_a = 0 # 社区 0 的核心 (教练)
node_b = 2 # 社区 0 的成员
node_c = 33 # 社区 1 的核心 (管理员)
node_d = 32 # 社区 1 的成员
restart_prob = 0.15 # 重启概率
# 3. 比较
# 比较 A 和 B (同一社区)
sim_ab = get_symmetric_rwr_similarity(G_karate, node_a, node_b, restart_prob)
# 比较 A 和 D (不同社区)
sim_ad = get_symmetric_rwr_similarity(G_karate, node_a, node_d, restart_prob)
# 比较 A 和 C (不同社区的核心)
sim_ac = get_symmetric_rwr_similarity(G_karate, node_a, node_c, restart_prob)
print(f"RWR 重启概率: {restart_prob}")
print(f" Sim({node_a}, {node_b}) (同社区): {sim_ab:.6f}")
print(f" Sim({node_a}, {node_d}) (跨社区): {sim_ad:.6f}")
print(f" Sim({node_a}, {node_c}) (跨社区, 核心): {sim_ac:.6f}")
assert sim_ab > sim_ad
print("\n (验证成功:同社区的 RWR 相似性 > 跨社区的 RWR 相似性)")
# 4. 可视化:π_0 (从节点 0 出发的 RWR 向量)
pi_0 = get_rwr_similarity_vector(G_karate, node_a, restart_prob)
# 将 RWR 分数转换为颜色列表
color_map = [pi_0.get(node, 0) for node in G_karate.nodes()]
plt.figure(figsize=(10, 7))
plt.title(f"1.3.4: 从节点 {node_a} (教练) 出发的 RWR 相似性")
pos_karate = nx.spring_layout(G_karate, seed=42)
# 绘制
nodes = nx.draw_networkx_nodes(G_karate, pos_karate, node_color=color_map,
cmap=plt.cm.viridis, node_size=500)
nx.draw_networkx_edges(G_karate, pos_karate, alpha=0.3)
nx.draw_networkx_labels(G_karate, pos_karate, font_color='white')
# 添加颜色条
plt.colorbar(nodes, label="RWR 相似性 (π_0(v))")
plt.savefig("1.3.4_rwr_similarity.png")
# plt.show()
print("\n [观察] 可视化显示,从节点 0 出发的 RWR 分数(颜色亮度)")
print(" ... 在其自己的社区(左侧)中普遍较高,")
print(" ... 在另一个社区(右侧)中则低得多。")
准备工作:安装依赖
本节中的代码需要 scikit-learn (用于标准分类/回归指标) 和 torch_geometric (用于加载数据集)。
# 安装 scikit-learn
pip install scikit-learn
# --- 安装 PyTorch Geometric ---
# 1. 首先,确保你已安装 PyTorch (https://pytorch.org/)
# pip install torch
# 2. 然后,安装 PyTorch Geometric 及其依赖
# (这会根据你的 PyTorch 和 CUDA 版本自动选择正确的包)
pip install torch-geometric
pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-$(torch.__version__).split('+')[0].html
Python
# --- 核心导入 ---
import numpy as np
from sklearn.metrics import (
accuracy_score,
f1_score,
roc_auc_score,
average_precision_score
)
import networkx as nx
import matplotlib.pyplot as plt
# PyTorch Geometric (PyG)
try:
import torch
from torch_geometric.datasets import Planetoid, TUDataset
from torch_geometric.utils import to_networkx
PYG_AVAILABLE = True
print("PyTorch Geometric 已成功导入。")
except ImportError:
PYG_AVAILABLE = False
print("警告:未找到 PyTorch Geometric。1.4.4 节将无法运行。")
print("请按照教程顶部的指南安装 torch 和 torch_geometric。")
# 设置 Numpy 打印精度
np.set_printoptions(precision=4)
1.4.1 节点分类、图分类、链路预测指标定义
这些任务本质上是机器学习中的分类任务,因此我们可以复用 scikit-learn 中的标准指标。
1.4.1.A: 节点/图分类 (Accuracy, F1-Score)
-
Accuracy (准确率): 最直观的指标,即“预测正确的样本数 / 总样本数”。
-
F1-Score (F1分数): Precision (精确率) 和 Recall (召回率) 的调和平均数。它在数据不平衡时比 Accuracy 更具参考价值。
-
macro(宏平均): 计算每个类别的 F1,然后取算术平均。平等对待所有类别。 -
weighted(加权平均): 按每个类别的样本数(support)对 F1 进行加权平均。
-
Python
def evaluate_classification_metrics(y_true, y_pred_labels):
"""
计算并打印多分类任务的核心指标。
参数:
y_true (array-like): 真实的标签 (N,)
y_pred_labels (array-like): 模型预测的标签 (N,)
"""
print(f" y_true: {y_true}")
print(f" y_pred: {y_pred_labels}")
# 1. 准确率 (Accuracy)
acc = accuracy_score(y_true, y_pred_labels)
print(f" Accuracy: {acc:.4f}")
# 2. F1-Score (Macro)
# 宏平均:不考虑样本不平衡,平等对待所有类别
f1_macro = f1_score(y_true, y_pred_labels, average='macro', zero_division=0)
print(f" F1-Score (Macro): {f1_macro:.4f}")
# 3. F1-Score (Weighted)
# 加权平均:考虑样本不平衡,按类别支持度加权
f1_weighted = f1_score(y_true, y_pred_labels, average='weighted', zero_division=0)
print(f" F1-Score (Weighted): {f1_weighted:.4f}")
# --- 完整可执行示例 (1.4.1.A) ---
if __name__ == "__main__":
print("\n--- 1.4.1.A: 节点/图分类指标 ---")
# 假设我们有 10 个节点/图的预测结果
# 类别 0: 5个, 类别 1: 3个, 类别 2: 2个 (数据不平衡)
y_true_labels = np.array([0, 0, 0, 0, 0, 1, 1, 1, 2, 2])
# 模型的预测
y_pred_labels = np.array([0, 0, 1, 0, 0, 1, 1, 2, 2, 2])
evaluate_classification_metrics(y_true_labels, y_pred_labels)
1.4.1.B: 链路预测 (AUC, AP)

def evaluate_link_prediction_metrics(y_true_links, y_pred_scores):
"""
计算链路预测任务的核心指标。
参数:
y_true_links (array-like): 真实的边是否存在 (N_pairs,),1=存在, 0=不存在
y_pred_scores (array-like): 模型预测的边存在的 *概率* (N_pairs,)
"""
print(f" y_true (前10): {y_true_links[:10]}")
print(f" y_scores (前10): {y_pred_scores[:10]}")
# 1. ROC AUC
auc_score = roc_auc_score(y_true_links, y_pred_scores)
print(f" ROC AUC Score: {auc_score:.4f}")
# 2. Average Precision (AP)
ap_score = average_precision_score(y_true_links, y_pred_scores)
print(f" Average Precision (AP): {ap_score:.4f}")
# --- 完整可执行示例 (1.4.1.B) ---
if __name__ == "__main__":
print("\n--- 1.4.1.B: 链路预测指标 ---")
# 假设我们测试了 1000 对节点
# 只有 50 条是真实存在的边 (正样本)
y_true_links = np.zeros(1000)
y_true_links[:50] = 1.0
np.random.shuffle(y_true_links) # 打乱
# 一个 "还不错" 的模型给出的预测分数 (概率)
# 它给正样本的分数普遍偏高 (0.7 ± 0.2)
# 它给负样本的分数普遍偏低 (0.3 ± 0.2)
positive_scores = np.random.normal(0.7, 0.2, 50)
negative_scores = np.random.normal(0.3, 0.2, 950)
# 组合分数 (必须与 y_true_links 的顺序一致)
y_pred_scores = np.zeros(1000)
y_pred_scores[y_true_links == 1] = positive_scores
y_pred_scores[y_true_links == 0] = negative_scores
# 确保分数在 [0, 1] 区间
y_pred_scores = np.clip(y_pred_scores, 0, 1)
evaluate_link_prediction_metrics(y_true_links, y_pred_scores)
1.4.2 排序与检索指标 (MRR, Recall@K, Precision@K)

def precision_at_k(ranked_list, ground_truth, k):
"""
计算 Precision@K (P@K)
参数:
ranked_list (list): 模型排序的推荐列表 [item1, item2, ...]
ground_truth (set): 真实的答案集合 {item_A, item_B, ...}
k (int): 评估的排名阈值
"""
# 截断前 k 个
top_k_items = ranked_list[:k]
# 计算交集
relevant_items_in_top_k = [item for item in top_k_items if item in ground_truth]
# P@K
return len(relevant_items_in_top_k) / k
def recall_at_k(ranked_list, ground_truth, k):
"""
计算 Recall@K (R@K)
"""
if not ground_truth: # 避免除零
return 0.0
top_k_items = ranked_list[:k]
relevant_items_in_top_k = [item for item in top_k_items if item in ground_truth]
# R@K
return len(relevant_items_in_top_k) / len(ground_truth)
def reciprocal_rank(ranked_list, ground_truth):
"""
计算单个查询的 Reciprocal Rank (RR)
"""
for rank, item in enumerate(ranked_list, 1): # 排名从 1 开始
if item in ground_truth:
return 1.0 / rank
return 0.0 # 没有找到
def mean_reciprocal_rank(all_ranked_lists, all_ground_truths):
"""
计算 Mean Reciprocal Rank (MRR)
"""
total_rr = 0.0
query_count = len(all_ranked_lists)
if query_count == 0:
return 0.0
for ranked_list, ground_truth in zip(all_ranked_lists, all_ground_truths):
total_rr += reciprocal_rank(ranked_list, ground_truth)
return total_rr / query_count
# --- 完整可执行示例 (1.4.2) ---
if __name__ == "__main__":
print("\n--- 1.4.2: 排序与检索指标 ---")
# 假设我们对 3 个用户 (查询) 进行了推荐
K = 3 # 我们关心 Top-3 结果
# --- 查询 1 ---
query_1_ranked = ['A', 'B', 'C', 'D', 'E'] # 模型的推荐
query_1_truth = {'B', 'D'} # 用户的真实喜好
# --- 查询 2 ---
query_2_ranked = ['X', 'Y', 'Z', 'A']
query_2_truth = {'A'}
# --- 查询 3 ---
query_3_ranked = ['M', 'N', 'O']
query_3_truth = {'P', 'Q'} # 模型完全没猜中
# 评估 P@K 和 R@K (通常也是取平均)
p_at_3_q1 = precision_at_k(query_1_ranked, query_1_truth, K)
r_at_3_q1 = recall_at_k(query_1_ranked, query_1_truth, K)
print(f"查询 1 (Truth={'B','D'}, K={K}):")
print(f" P@{K}: {p_at_3_q1:.4f} (Top 3 'A,B,C' 中 'B' 命中, 1/3)")
print(f" R@{K}: {r_at_3_q1:.4f} (Top 3 'A,B,C' 中 'B' 命中, 总共 2 个, 1/2)")
p_at_3_q2 = precision_at_k(query_2_ranked, query_2_truth, K)
r_at_3_q2 = recall_at_k(query_2_ranked, query_2_truth, K)
print(f"\n查询 2 (Truth={'A'}, K={K}):")
print(f" P@{K}: {p_at_3_q2:.4f} (Top 3 'X,Y,Z' 均未命中, 0/3)")
print(f" R@{K}: {r_at_3_q2:.4f} (Top 3 'X,Y,Z' 均未命中, 0/1)")
# 评估 MRR
all_ranks = [query_1_ranked, query_2_ranked, query_3_ranked]
all_truths = [query_1_truth, query_2_truth, query_3_truth]
rr_q1 = reciprocal_rank(query_1_ranked, query_1_truth)
rr_q2 = reciprocal_rank(query_2_ranked, query_2_truth)
rr_q3 = reciprocal_rank(query_3_ranked, query_3_truth)
print("\nMRR 计算:")
print(f" RR (查询 1): {rr_q1:.4f} (第一个命中 'B' 在第 2 位, 1/2)")
print(f" RR (查询 2): {rr_q2:.4f} (第一个命中 'A' 在第 4 位, 1/4)")
print(f" RR (查询 3): {rr_q3:.4f} (未命中, 0.0)")
mrr_score = mean_reciprocal_rank(all_ranks, all_truths)
print(f" MRR (平均): {mrr_score:.4f} ( (0.5 + 0.25 + 0.0) / 3 )")
1.4.3 生成任务评价 (Validity, Novelty, Uniqueness)
def get_graph_hash(G):
"""
(优化) 使用 Weisfeiler-Lehman 哈希计算图的唯一签名。
这比 nx.is_isomorphic() 快得多。
"""
# edge_attr=None 意味着哈希只基于图的结构
return nx.weisfeiler_lehman_graph_hash(G, edge_attr=None, node_attr=None)
def check_validity(graph_list, rule_func):
"""
计算有效性。
rule_func 是一个接受 G 并返回 True/False 的函数。
"""
valid_count = sum(1 for G in graph_list if rule_func(G))
return valid_count / len(graph_list) if graph_list else 0.0
def check_uniqueness(graph_list, hash_func=get_graph_hash):
"""
计算独特性 (基于图哈希)。
"""
if not graph_list:
return 0.0
hashes = [hash_func(G) for G in graph_list]
unique_hashes = set(hashes)
return len(unique_hashes) / len(hashes)
def check_novelty(generated_list, training_list, hash_func=get_graph_hash):
"""
计算新颖性 (基于图哈希)。
"""
if not generated_list:
return 0.0
gen_hashes = set([hash_func(G) for G in generated_list])
train_hashes = set([hash_func(G) for G in training_list])
# 计算不在训练集中的哈希数量
novel_hashes = gen_hashes - train_hashes
return len(novel_hashes) / len(gen_hashes)
# --- 完整可执行示例 (1.4.3) ---
if __name__ == "__main__":
print("\n--- 1.4.3: 图生成任务指标 ---")
# 1. 创建 "训练集" (2个图)
G_train_1 = nx.path_graph(4) # 路径图
G_train_2 = nx.cycle_graph(5) # 环形图
training_set = [G_train_1, G_train_2]
# 2. 创建 "模型生成集" (5个图)
G_gen_1 = nx.path_graph(4) # (与训练集相同)
G_gen_2 = nx.star_graph(3) # (新颖)
G_gen_3 = nx.star_graph(3) # (重复生成)
G_gen_4 = nx.cycle_graph(6) # (新颖)
G_gen_5 = nx.Graph() # (无效图)
G_gen_5.add_nodes_from([1, 2, 3])
generated_set = [G_gen_1, G_gen_2, G_gen_3, G_gen_4, G_gen_5]
# 3. 评估 Validity
# 规则:图必须是连通的
validity_rule = nx.is_connected
validity_score = check_validity(generated_set, validity_rule)
print(f" Validity (是否连通): {validity_score:.4f} (4/5)")
# 4. 评估 Uniqueness (在生成的 5 个图中)
# G_gen_2 和 G_gen_3 是同构的 (哈希相同)
uniqueness_score = check_uniqueness(generated_set)
print(f" Uniqueness (内部独特性): {uniqueness_score:.4f} (4/5)")
# 5. 评估 Novelty (与训练集比较)
# G_gen_1 (path_graph(4)) 在训练集中
# G_gen_2/3 (star_graph(3)) 不在
# G_gen_4 (cycle_graph(6)) 不在
# G_gen_5 (3个孤立点) 不在
# 独特的生成图哈希有 4 个,其中 3 个是新颖的
novelty_score = check_novelty(generated_set, training_set)
print(f" Novelty (新颖性): {novelty_score:.4f} (3/4)")
1.4.4 常用基准数据集清单与元数据说明
我们将使用 PyTorch Geometric (PyG) 来加载标准数据集。
-
Planetoid (Cora, CiteSeer, PubMed): 节点分类 (Node Classification) 的基准。
-
Cora: 论文引用网络。
-
任务: 预测论文的学科类别(7类)。
-
节点: 论文 (2708)。
-
边: 引用关系 (5429)。
-
节点特征: 1433 维的 0/1 词袋 (BoW) 向量。
-
-
-
TUDataset (MUTAG, ENZYMES, PROTEINS): 图分类 (Graph Classification) 的基准。
-
MUTAG: 188 个分子图。
-
任务: 预测分子是否具有诱变性(2类)。
-
节点: 原子(7种原子类型)。
-
图标签: 0 或 1。
-
-
def inspect_pyg_node_dataset(dataset_name):
"""
加载并检查一个 PyG 节点分类数据集 (例如 Cora)。
"""
print(f"\n--- 正在加载 {dataset_name} (节点分类) ---")
try:
# root='.' 表示下载到当前目录下的 'data' 文件夹
dataset = Planetoid(root='./data', name=dataset_name)
except Exception as e:
print(f" 错误:无法加载 {dataset_name}。{e}")
print(" 请确保 PyG 已正确安装。")
return None
# PyG 中,Cora, CiteSeer, PubMed 只有一个图
data = dataset[0]
print(f"数据集: {dataset.name}")
print(f" 图的数量: {len(dataset)}")
print(f" 节点总数 (data.num_nodes): {data.num_nodes}")
print(f" 边总数 (data.num_edges): {data.num_edges}")
print(f" 节点特征维度 (data.num_node_features): {dataset.num_node_features}")
print(f" 类别数 (data.num_classes): {dataset.num_classes}")
print("\n 关键属性 (Data 对象):")
print(f" data.x (节点特征): {data.x.shape}")
print(f" data.y (节点标签): {data.y.shape}")
print(f" data.edge_index (边列表, COO 格式): {data.edge_index.shape}")
print(f" data.train_mask (训练掩码): {data.train_mask.sum()} 个节点")
print(f" data.val_mask (验证掩码): {data.val_mask.sum()} 个节点")
print(f" data.test_mask (测试掩码): {data.test_mask.sum()} 个节点")
return dataset
def inspect_pyg_graph_dataset(dataset_name):
"""
加载并检查一个 PyG 图分类数据集 (例如 MUTAG)。
"""
print(f"\n--- 正在加载 {dataset_name} (图分类) ---")
try:
dataset = TUDataset(root='./data', name=dataset_name, use_node_attr=True)
except Exception as e:
print(f" 错误:无法加载 {dataset_name}。{e}")
print(" 请确保 PyG 已正确安装。")
return None
print(f"数据集: {dataset.name}")
print(f" 图的数量: {len(dataset)}")
print(f" 类别数 (data.num_classes): {dataset.num_classes}")
print(f" 节点特征维度 (data.num_node_features): {dataset.num_node_features}")
# 检查第 1 个图
data_0 = dataset[0]
print("\n 示例:第 0 个图 (data_0):")
print(f" data_0.x (节点特征): {data_0.x.shape}")
print(f" data_0.y (图的标签): {data_0.y}")
print(f" data_0.edge_index (边列表): {data_0.edge_index.shape}")
return dataset
def visualize_pyg_graph(data, title="PyG Graph"):
"""
(附加功能) 将一个 PyG Data 对象转换为 NetworkX 并可视化。
"""
# G = to_networkx(data, to_undirected=True)
# to_networkx 在新版 PyG 中可能需要 node_attrs 和 edge_attrs
node_attrs = ['x', 'y'] if data.x is not None else []
G = to_networkx(data, node_attrs=node_attrs, to_undirected=True)
plt.figure(figsize=(8, 6))
plt.title(title)
pos = nx.spring_layout(G, seed=42)
nx.draw(G, pos, with_labels=True, node_color='lightblue',
node_size=300, font_size=10)
plt.savefig(f"{title.replace(' ', '_')}.png")
# plt.show()
print(f"\n 已保存图的可视化: '{title.replace(' ', '_')}.png'")
# --- 完整可执行示例 (1.4.4) ---
if __name__ == "__main__":
print("\n--- 1.4.4: 常用基准数据集 ---")
if PYG_AVAILABLE:
# 1. 节点分类: Cora
cora_dataset = inspect_pyg_node_dataset("Cora")
# 2. 图分类: MUTAG
mutag_dataset = inspect_pyg_graph_dataset("MUTAG")
# 3. 可视化 MUTAG 的第 0 个图
if mutag_dataset:
visualize_pyg_graph(mutag_dataset[0], title="MUTAG Graph 0")
# 4. 可视化 Cora (的子图,Cora太大了)
if cora_dataset:
# 创建 Cora 的一个 K-Hop 子图进行可视化
data_cora = cora_dataset[0]
# 获取节点 0 的 2 跳邻居子图
subgraph_nodes = nx.ego_graph(
to_networkx(data_cora, to_undirected=True), n=0, radius=2
).nodes()
# data.subgraph() 在新版 PyG 中不推荐
# k_hop_subgraph 更高效
from torch_geometric.utils import k_hop_subgraph
subset, sub_edge_index, mapping, edge_mask = k_hop_subgraph(
node_idx=0, num_hops=2, edge_index=data_cora.edge_index,
relabel_nodes=True
)
sub_data = data_cora.clone()
sub_data.x = data_cora.x[subset]
sub_data.y = data_cora.y[subset]
sub_data.edge_index = sub_edge_index
visualize_pyg_graph(sub_data, title="Cora Subgraph (2-hop from node 0)")
else:
print("\n[跳过 1.4.4] PyTorch Geometric 未安装,无法加载数据集。")


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









