




前言
- 需要下载安装OpenCV工具包的朋友,请前往 此处 ;
- 系统要求:Windows系统,LabVIEW>=2018,兼容32位和64位。
机器学习
OpenCV 的机器学习算法位于 ml 模块,主要由基于统计学的 StatModel 类实现。
StatModel 是一个基类,根据不同的算法,衍生出一系列子类。
选板如下,子目录下的函数,是子类私有方法,外部的是共有方法。

例1:支持向量机(SVM)做平面向量二分类
- 第1步:准备训练数据(TrainData)
训练数据需要两个矩阵:Samples 和 Responses,即 样本矩阵 和 响应矩阵。
在本例中,随机生成(300 * 300)平面中的200个 (x, y) 坐标,组成 (200 * 2) 的二维 Mat 作为 Samples。
然后,按照某种线性规则将上述200个坐标分成两类(用 1 和 2 代表),组成 (200 * 1)的二维 Mat 作为 Responses。
注意,Samples 矩阵的数据类型须是浮点数,Responses 矩阵的数据类型须是整型数(CV_32S)。
插入一个 TrainData 类的 create 函数,输入上述的 Samples 和 Responses,并将布局设为“ROW_SAMPLE”,即每行一个样本。由此创建的 TrainData 对象,作为将来 SVM 算法的训练数据。

- 第2步:创建SVM,设置参数并训练
插入一个 StatModel 类的 create 函数,切换多态标签至 “SVM”。
接着,插入多个 SVM 子类的私有函数 SVM_set,通过切换模式,设置不同的参数。
然后,插入一个 StatModel 类的公共函数 train,切换模式为 “TrainData”,并连接第1步准备好的TrainData对象。

- 第3步:用新样本进行预测,评估训练效果
本例遍历(300 * 300)平面的每一个像素坐标,组成(90000 * 2) 的二维 Mat 作为测试样本矩阵。
插入一个 StatModel 类的公共函数 predict,输入上述测试样本矩阵,运行后获得预测结果矩阵。
可视化:根据预测结果(1或2),对(300 * 300)平面的每一个像素进行染色。
同时把训练时的200个散点也绘制在平面上,根据分类用不同的颜色进行区分。
完整过程如下图(可视化过程略),详见范例:examples/Molitec/OpenCV/ml/ml_1(StatModel_SVM).vi


从上图中可以看出,SVM 用线性边界将平面分割成了两类,而且在靠近边界的区域,允许存在一定的样本误差。
以上是一个简单的 SVM 应用,样本是二维向量。其实 SVM 还可以用在多维向量分类上,比如一张图片的特征向量。通过 SVM 找出多维向量样本在 “超平面” 上的最佳分割方案,进而对图片进行二分类。
感兴趣的读者,可以提前看一看 features2d 模块的范例:
examples/Molitec/OpenCV/features2d/features2d_5(BOW_SVM_train).vi
例2: K邻近算法(KNearest)实现分类
K近邻算法是一种基于实例的学习方法,主要用于分类和回归任务。其核心思想是:对于一个新的、未知类别的数据点,通过计算其与已知类别训练集中的数据点的距离,找出与其最近的K个邻居,并依据这K个邻居的多数类别来决定新数据点的类别归属。
- 第1步:准备训练数据
训练数据需要两个矩阵:Samples 和 Responses,即 样本矩阵 和 响应矩阵。
本例围绕平面上的两个中心点,分别生成 50 个随机 (x, y) 坐标,组成 (100 * 2) 的二维 Mat 作为 Samples。
根据所属中心的不同,将上述100个点分类成1或2,组成 (100 * 1)的二维 Mat 作为 Responses。
数据类型要求与上文相同。本次不创建 TrainData 对象,直接使用 Samples 和 Responses 参与将来的训练。

- 第2步:创建KNearest,设置参数并训练
插入一个 StatModel 类的 create 函数,切换多态标签至 “KNearest”。
接着,插入一个或多个 KNearest子类的私有函数 KNearest_set,通过切换模式,设置不同的参数。
然后,插入一个 StatModel 类的公共函数 train,切换模式为 “Samples”,连接第1步准备好的 Samples 和 Responses ,并将布局设为“ROW_SAMPLE”。

- 第3步:引入新的样本,进行K邻近分类
插入一个 KNearest 子类的私有函数 KNearest_findNearest,设置K=5,输入新样本,运行后获得预测分类结果。
KNearest_findNearest 还有两个可选输入输出:neighborResponses 和 dist,可以返回K个相邻点的分类和距离。
完整过程如下图(可视化过程略),详见范例:examples/Molitec/OpenCV/ml/ml_2(StatModel_KNearest).vi


在上图中,新引入的样本点(150,150)位于画面中心的 “+” 标识,与其相邻的 K (5) 个点中,有3个属于1类(蓝色),有2个属于2类(红色),所以新样本的分类结果为1类。
KNearest 同样可以用于多维向量分类。通过找出 “超平面” 上K个最相邻的已知样本,对新样本进行分类。
例3:人工神经网络 — 多层感知器(ANN_MLP)
-
概念解读
ANN 即 Artificial Neural Network, MLP 即 Multi Layer Perceptron。
多层感知器(MLP)是由多个全连接层构成的前馈神经网络,是一种最简单的 ANN 结构,也是所有复杂网络的理论基石。此内容虽为 “机器学习”,但其实已初窥 “深度学习” 之门径。 -
网络结构
如下图,是一个神经元的模型,它接收上一级的所有输入量,并进行线性运算(加权求和),得到的结果再通过某种激活函数(如Sigmoid)映射得到本神经元的最终输出量,传递给下一级。

如下图,将多个神经元按层排列,每个神经元只接收前一层的输入,并将计算结果输出给下一层,就形成了最简单的多层感知机器,也叫前馈神经网络。它通常由一个输入层,一或多个隐藏层(中间层),以及一个输出层组成。
由于神经元中同时包含了线性运算与非线性运算(激活函数),因此只要神经元数量与网络层数足够多,理论上神经网络可以模拟任何数学模型。当然,太多了也会降低训练时的收敛速度。

-
训练过程
神经网络的训练过程,就是通过不断优化更新权重值 (W,b),使得对于给定的输入量,经过网络运算后,得到的实际输出量与预期值的偏差尽可能小。常用的算法如:反向传播(Back Prop)。 -
编程范例
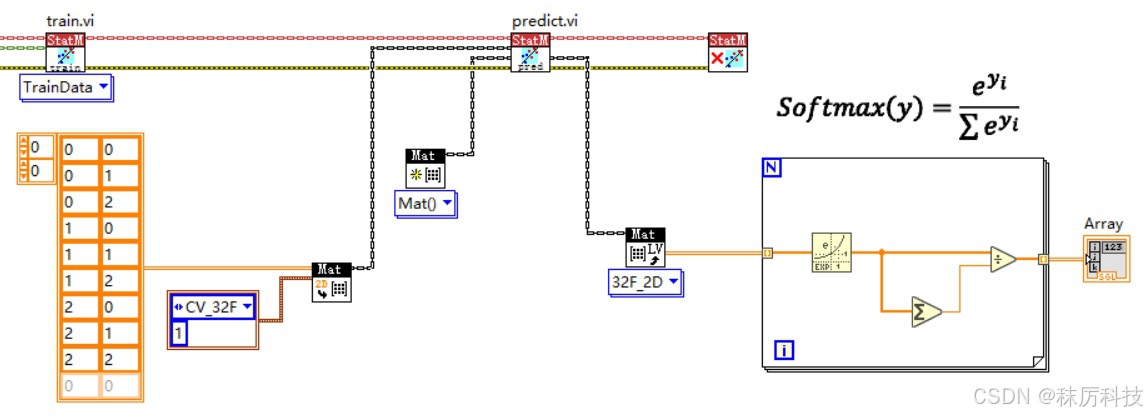
我们用 ANN_MLP 来做一个 “石头、剪刀、布” 的游戏裁判。
输入量是A、B两个人的猜拳结果,0代表石头,1代表剪刀,2代表布。
输出量是三种胜负结果,(1,0,0)代表A胜,(0,1,0)代表B胜,(0,0,1)代表平局。
本例简单,可以通过穷举法,列出所有可能的输入输出,如下表。
| 输入 | 输出 |
|---|---|
| 石 - 石 (0,0) | (0,0,1) 平局 |
| 石 - 剪 (0,1) | (1,0,0) A胜 |
| 石 - 布 (0,2) | (0,1,0) B胜 |
| 剪 - 石 (1,0) | (0,1,0) B胜 |
| 剪 - 剪 (1,1) | (0,0,1) 平局 |
| 剪 - 布 (1,2) | (1,0,0) A胜 |
| 布 - 石 (2,0) | (1,0,0) A胜 |
| 布 - 剪 (2,1) | (0,1,0) B胜 |
| 布 - 布 (2,2) | (0,0,1) 平局 |
通过LabVIEW随机抽取1000组输入输出,作为训练使用的 Samples 和 Responses,如下图。

接下来搭建网络。
插入一个 StatModel 类的 create 函数,切换多态标签至 “ANN_MLP”;
插入一个 ANN_MLP 子类的私有函数 ANN_MLP_set,切换多态标签至 “LayerSizes”,设置网络层数及神经元数。
本例输入层神经元数为2,输出层神经元数为3,隐藏层可以根据模型复杂度自由设置,这里设为一个隐藏层且包含10个神经元。于是,setLayerSizes 需要输入的 Mat 为 { { 2,10,3 } },如下图。

再插入一个ANN_MLP_set,切换多态标签至 “ActivationFunction”,设置激活函数。
我们这里设为 SIGMOID_SYM,它是一种 “对称型S生长曲线” ,表达式及图像如下:

另外两个参数 param1 和 param2 分别对应表达式中的 α 和 β。设param1=0.6,param2=1.0,这样的激活函数输出区间为 (-1,1)。如下图。

再插入一个ANN_MLP_set,切换多态标签至 “TrainMethod”,设置训练方法。
我们这里设为BACKPROP,即反向传播,相应的 param1 和 param2 分别代表权重和动量缩放比例,均设为0.1,如下图。

再插入一个ANN_MLP_set,切换多态标签至 “TermCriteria”,设置终止条件。
训练终止条件有两种,一是训练(迭代)次数达到了maxCount,二是误差值小于epsilon。
当 type=MAX_ITER 时,采用最大次数终止;当 type=EPS 时,采用误差值终止;当 type=MAX_ITER+EPS 时,二者任一满足条件时,都将终止。
参数设置完成,开始训练。
插入一个 StatModel 类的公共函数 train,切换模式为 “TrainData”,传入上文准备好的训练样本。

训练完成,我们来测试一下效果。
插入一个 StatModel 类的公共函数 predict,输入一组A、B猜拳,运行得到输出。

注意,每行的三个输出值,可以作为三种胜负结果的 “分数”,其最大值所在索引,就对应着最终的裁决结果。
但不可以认为这三个值是 “概率”,首先它们相加不等于1,其次由于激活函数的设置,导致它们的理论取值范围都是(-1,1)。
如果想要近似得到概率,可以用 softmax 算法,转化为概率分布。
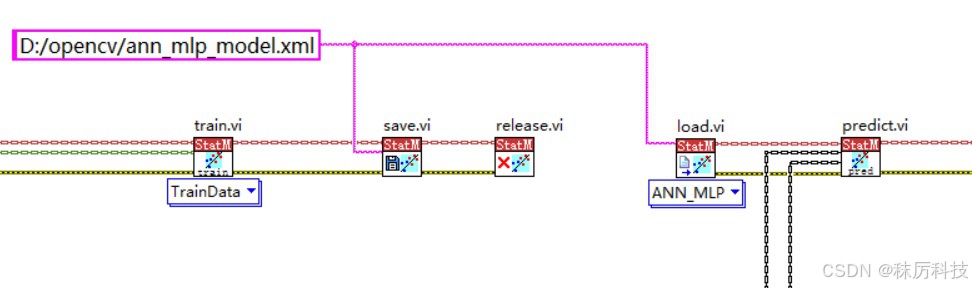
如果对本次训练结果满意,可以调用 StatModel 类的公共函数 save,将模型保存成 xml 格式的文件。
该模型文件,可以通过 load 函数再次载入,然后直接进行 predict 等用法。
- 应用延展
对于其他应用,比如 “手写数字识别”,同样可以使用 ANN_MLP 来实现:
输入图像是 28 x 28 的矩阵,可以将其压缩成一行,作为输入层的 784 个神经元;
输出层设为10个神经元,分别代表数字 0~9 这十种结果的分数;
中间的隐藏层,可以再复杂一些,比如两层,每层50个神经元。
那么,更加复杂的应用呢?输入图像尺寸很大,分类数量多,需要的神经元与隐藏层数也爆炸式增长。这种情况下,采用全连接的 ANN_MLP 的弊端就显现出来了,不但计算量巨大,而且随着网络深度的增加,发生 “梯度消失” 与 “梯度爆炸” 的风险也大大增加。
随着技术发展,卷积神经网络(RNN)应运而生,比较良好地解决了这个问题。
此内容超出了 OpenCV 机器学习模块的范围,感兴趣的读者可以自行查阅资料进行学习。
总结
- 本系列博文作为LabVIEW工具包—OpenCV的教程,将以专栏的形式陆续发布和更新。
- 对工具包感兴趣的朋友,欢迎下载试用:秣厉科技 - LabVIEW工具包 - OpenCV
- 各位看官有什么想法、建议、吐槽、批评,或新奇的需求,也欢迎留言讨论。


















 9211
9211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











