







 论文探讨了基于3D CNN和LSTM的人体运动预测问题,提出了一种时间尺度编码和层次编码的深度学习框架。通过在CMU mocap数据库进行实验,证明了该框架在运动预测和分类任务中的优越性,特别是在数据丢失的情况下仍能保持高准确性。
论文探讨了基于3D CNN和LSTM的人体运动预测问题,提出了一种时间尺度编码和层次编码的深度学习框架。通过在CMU mocap数据库进行实验,证明了该框架在运动预测和分类任务中的优越性,特别是在数据丢失的情况下仍能保持高准确性。
论文: Deep representation learning for human motion prediction and classification
论文地址: https://arxiv.org/abs/1702.07486
通过对mocap数据的学习,基于三种不同的 temporal encoder structures, 实现对于人物运动的后几帧预测
Table of Contents(目录)
Background (论文背景)
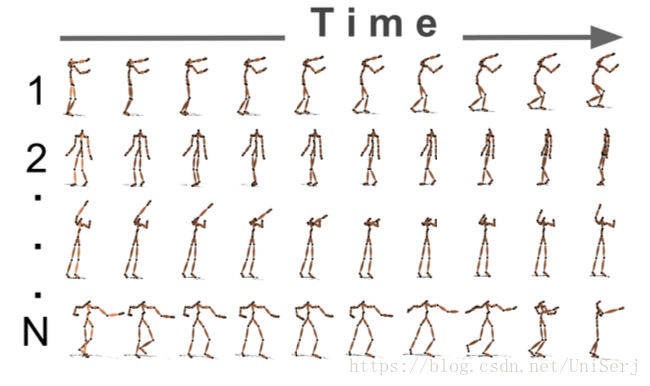
作者在论文开头针对人体运动预测问题,在现阶段使用的技术进行了概述以及分析了它们的优缺点:
3D CNN
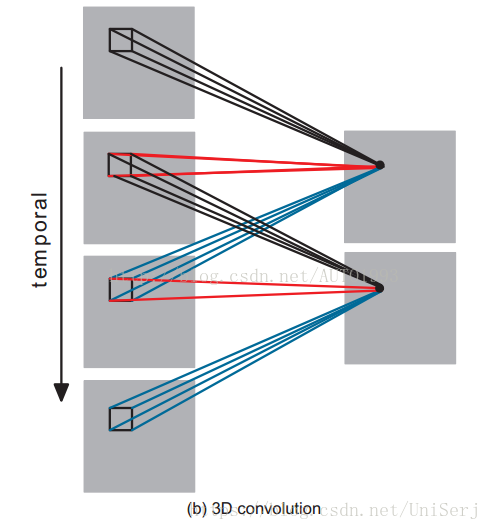
- 不同于单个图片,我们需要得到的是数据在时间上的相关性,所以作者提到了3D CNN,3D CNNs可以在时间和空间上通过三维的卷积核filter对多帧进行卷积,从而抓取特征
- 但是3D CNNs不能直接适用于mocap数据,因为不同于图片,mocap数据记录的是人类骨骼关节而具有了特殊性,比如相同肢体的关节一直相关,而不同肢体的关节可能相关性很低,因此需要将所有的关节结点被卷积核filter所包含
LSTM
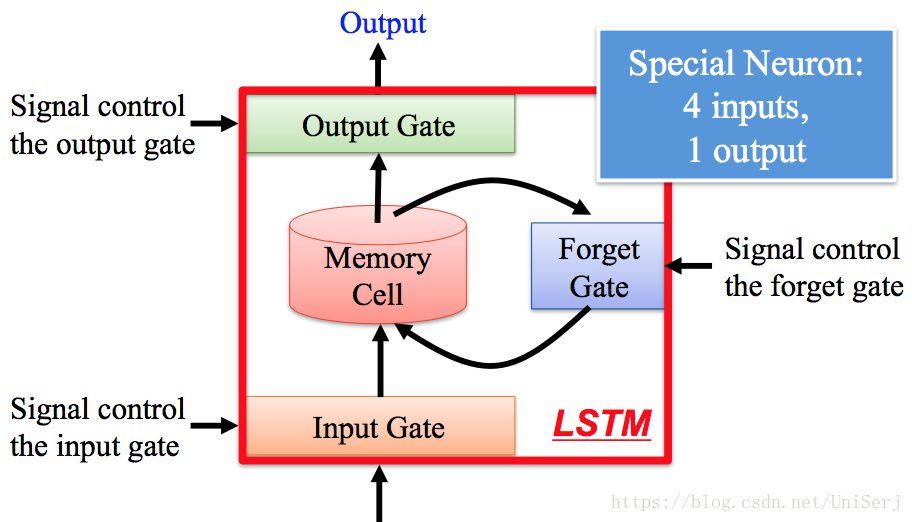
- Long Short-Term Memory networks具有记忆的功能,通过memory cell记忆之前的状态
- 但是LSTM适用于周期性的人物运动,比如走路游泳等,但对于非周期性的运动类型表现不好
Methodology(实现方法)
作者提出了一种框架,encoding-decoding框架,和两种具体的模型Time-scale encoding和Hierarchy encoding,相较于LSTM周期性的结构,作者直接将前几帧的数据作为输入,经由encoder和decoder,输出后几帧的预测值。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 549
549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









