




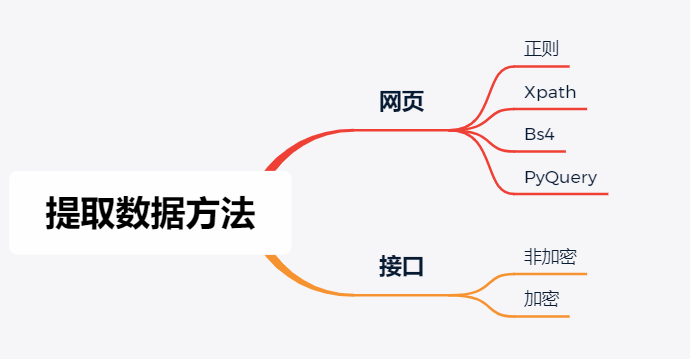
**
网页
![]()
正则表达式
正则表达式(Regular Expression):使用一种表达式的方法对字符串进行匹配的语法规则。
| 常用的元字符 | |
|---|---|
| . | 匹配除换行以外的任意字符 |
| \w | \W | 匹配字母数字或下划线 | 匹配非字母数字或下划线 |
| \s | \S | 匹配任意空白符 | 匹配非空白符 |
| \d | \D | 匹配数字 | 匹配非数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| a | b | 匹配字符a或b |
| () | 匹配包括内的表达式 |
| [........] | 匹配字符串组的字符 |
| [^......] | 匹配除字符串组的字符 |
| 量词 | |
|---|---|
| * | 重复零次或更多 |
| + | 重复一次或更多 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多 |
| {n,m} | 重复n到m次 |
| .* | 贪婪匹配,尽可能多的去匹配 |
| .*? | 非贪婪匹配,尽可能少的匹配 |
Python内置模块re。
| re修饰符 | |
|---|---|
| 修饰符 | 描述 |
| re.l | 使匹配对大小写不敏感 |
| re.L | 对本地化识别匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使匹配包括行内所有的字符 |
| re.U | 根据 Unicode 字符集解析字符。这个标志影响 \w、\W、\b 和 \B |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
| re常用方法 | |
|---|---|
| re.findall | 查找返回所有,返回list |
| re.finditer | 查找返回所有,返回一个迭代器 |
| re.search | 返回第一个结果 |
| re.match | 从第一个字符串开始匹配,没匹配到,返回None |
案例,获取2021年第四季度全国星级饭店统计调查报告发布时间。
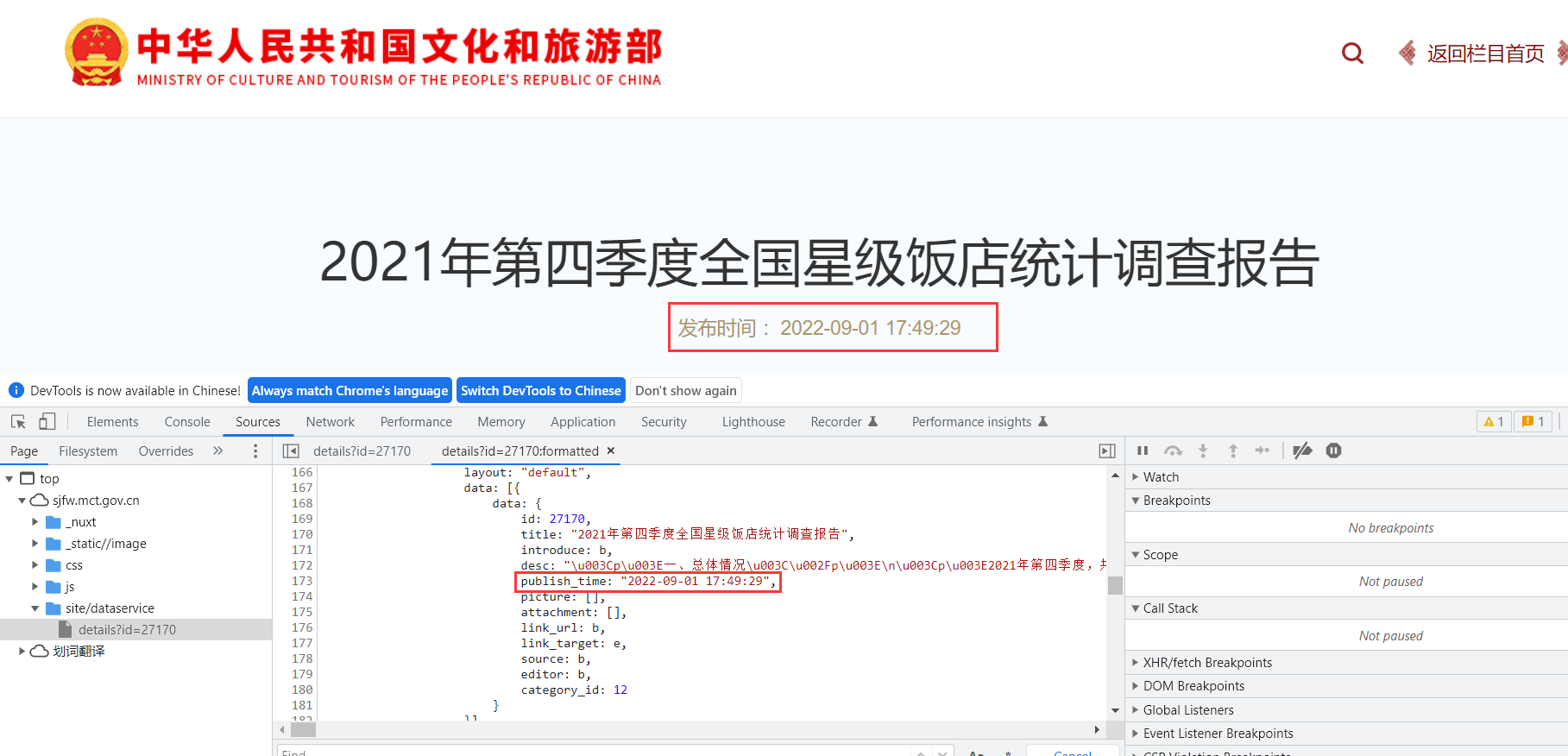
发布时间的数据在<script></script>中,可以利用正则表达式获取。
# -*- encoding:utf- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1203
1203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









