




 本文介绍了如何通过安装htop指令来优化系统资源,然后利用awk命令分析Nginx的access.log日志,进行Pageview(PV)和Unique Visitor(UV)的统计。通过awk的substr函数对日期进行分组,统计每天的PV量,并详细解释了awk的用法。此外,还展示了如何通过IP地址统计UV,以及编写shell脚本来分组分析UV。
本文介绍了如何通过安装htop指令来优化系统资源,然后利用awk命令分析Nginx的access.log日志,进行Pageview(PV)和Unique Visitor(UV)的统计。通过awk的substr函数对日期进行分组,统计每天的PV量,并详细解释了awk的用法。此外,还展示了如何通过IP地址统计UV,以及编写shell脚本来分组分析UV。
前言
文章的内容来源拉钩教育上的课程学习,通过写博客的方式,更好的提高对该知识的掌握。
一、准备
安装htop指令
sudo yum install htop
下载目标文件
#centos
#安装git
sudo yum install git
#下载access.log资源
git clone https://github.com/nickwang6/pv.git
查看目标文件
- 查看大小
ls -l access.log --block-size=M
- 查看文件
less access.log
- 相关参数
- IP地址
- 时间
- HTTP请求方法、路径、协议版本、返回状态码
- User Agent
二、Page view
PV分析
- 所谓PV分析(Page view),用户每访问一个页面就是一次Page View 对于nginx的access_log来说,分析PV非常简单
wc -l access.log

PV分组
-
通常一个日志可能有几天的PV,为了数据直观,有时候需要按天进行分组,为了简化这个问题,查看日志有哪些天的日志。
-
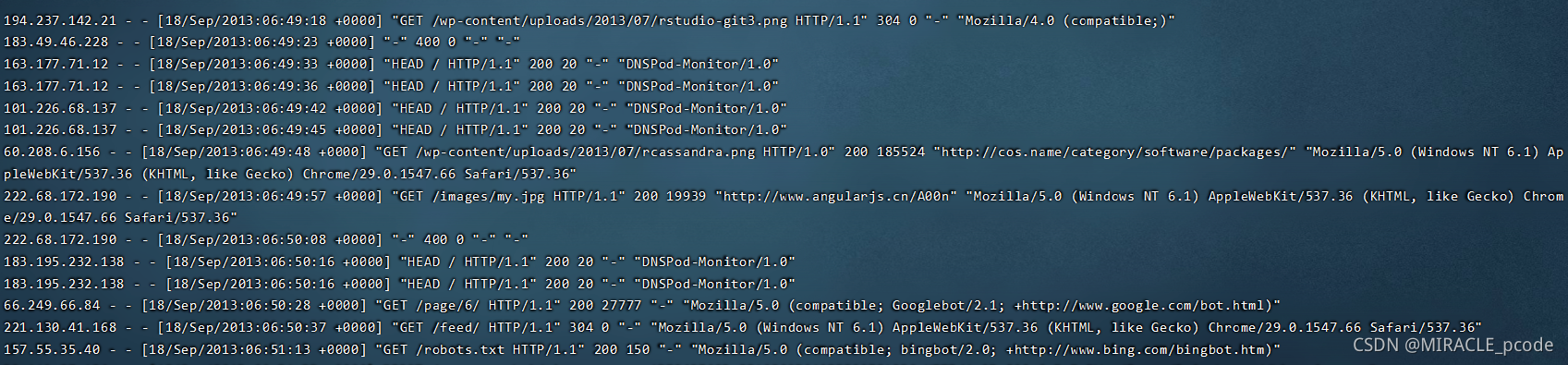
使用awk ‘{print $4}’ access.log | less可以看到如下结果。
-
awk是一个处理文本的领域专有语言。这里就牵扯到领域专有语言这个概念,英文是Domain Specific Language。领域专有语言,就是为了处理某个领域专门设计的语言。比如awk是用来分析处理文本的DSL,html是专门用来描述网页的DSL,SQL是专门用来查询数据的DSL……
-
awk '{print $4}' access.log | less
-
按天统计
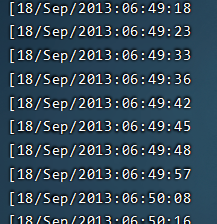
awk '{print substr($4,2,11)} ' access.log | head -n 10
 上图中,我们使用awk的substr函数,数字2代表从第 2 个字符开始,数字11代表截取 11 个字符。
上图中,我们使用awk的substr函数,数字2代表从第 2 个字符开始,数字11代表截取 11 个字符。 -
awk '{print substr($4,2,11)} ' access.log | sort | uniq -c
 可以看出18号的pv量为11347,19号的pv量为3272
可以看出18号的pv量为11347,19号的pv量为3272
分析UV
-
UV(uniq visitor),也就是统计访问人数,可以通过IP访问来统计UV
-awk '{print $1 } ' access.log | sort |uniq | wc -l
 可以得出日志文件中一共有1050个IP
可以得出日志文件中一共有1050个IP -
分组分析UV
- 创建 sum.sh文件
#!/usr/bin/bash
awk '{print substr($4, 2, 11) " " $1}' access.log |\
sort | uniq |\
awk '{uv[$1]++;next}END{for (ip in uv) print ip, uv[ip]}'
- 文件首部使用#! 表示我们将使用后面的 /usr/bin/bash执行这个文件
- 第一次awk 我们将第四列日期和第一列的IP地址拼接起来
- sort 把整个文件进行一次排序,相当根据日期排序,再根据IP排序
- 接下来我们用uniq去重,日期+ip相同的就只保留一个
- 最后的awk我们再根据第 1 列的时间和第 2 列的 IP 进行统计。
awk本身是逐行进行处理的。因此我们的next关键字是提醒awk跳转到下一行输入。 对每一行输入,awk会根据第 1 列的字符串(也就是日期)进行累加。之后的END关键字代表一个触发器,就是 END 后面用 {} 括起来的语句会在所有输入都处理完之后执行——当所有输入都执行完,结果被累加到uv中后,通过foreach遍历uv中所有的key,去打印ip和ip对应的数量。
#终端输入该命令
bash sum.sh
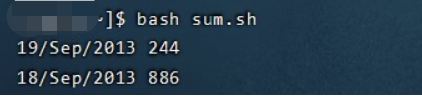

















 2523
2523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









