









作者:来自 Elastic Jordyn Short

我最近接触了一部叫《少年谢尔顿》(Young Sheldon)的电视剧。我没看过《生活大爆炸》(The Big Bang Theory),所以不太确定会有什么期待。不过,这篇文章其实不完全是关于这部剧的。我会用一个和它相关的数据集,但其实数据内容可以是任何的:业务相关的、可观测性相关的、安全相关的 —— 随你说。认识我的人都知道,我总会找到办法加入一点半混乱的乐趣。那么,我们开始吧。
Kibana 中最被忽视的功能
我要告诉你一个小秘密。这是 Kibana 中最被忽视的功能之一。我总是鼓励客户使用它,也把它当作最佳实践。
鼓声响起 —— Kibana 中一个出人意料且强大的功能,就是在创建 data view 时能分配自定义的 data view ID。
先不跑题,给你快速介绍下接下来的内容:
-
关于我自己……和我见过的一些情况
-
一个用例作为背景
-
为什么事情常常出问题
-
用《少年谢尔顿》的例子逐步演示
-
团队容易踩的坑
-
一些建议(说实话,你可以跳过其他内容,相信我,直接做这一部分就行)
完毕。释放你的内心 Aaron Pierre,跳起 Mufasa 舞。
作为 Elastic 的咨询架构师,我每天直接和客户打交道。我用过不少类似 SIEM 的工具,知道有些解决方案多复杂 —— 自定义语法像写代码,界面让人望而生畏,上手慢,投资回报慢。这也是我最喜欢用 Kibana 的原因之一:看着用户发现它其实很直观。
数据一导入并能用起来,用户马上进入状态。仪表盘和可视化图表随处出现,大家都充满兴奋和创意。但这股能量也带来一些混乱。
我常看到的情况是:有人建了一个仪表盘来熟悉 Kibana,然后发现它其实很棒,就开始在生产环境用起来。这本身没错!但……问题从这里开始:data view 往往随意创建,属性看起来相似甚至重复,导致混乱。
为什么重复的 data view 很重要
让我通过一个场景说明 data view 及其自定义 data view ID 如何影响可视化和仪表盘。
三个用户,三个 data view,一组数据
认识一下我们的用户:Sheldon、Missy、Georgie 和 Paige。Sheldon、Missy 和 Georgie 是新来的安全分析师,充满热情,渴望探索和贡献。Paige 是经验丰富的管理员和领域专家,注重流程和标准化,非常讨厌数字混乱。他们一起在星际飞船 Enterprise 工作。
星期一 —— Sheldon:
Sheldon 在 Kibana 里探索,特别关注 zeek 日志。他发现没有现成的 data view,便创建了一个叫 Zeek 的,索引模式设为 zeek-*。Kibana 给它随机分配了一个 data view ID,比如 e4f6268b-9c4a-4f36-8a56-49ef18fbd147。他开始构建仪表盘和可视化,对结果很满意,认为可以上线使用。团队也开始使用,大家都很喜欢,认可度很高。
星期二 —— Missy:
Missy 第一次登录 Kibana。她知道 Zeek 数据已经导入,但不知道 Sheldon 已经创建了 data view。她急着探索,也创建了自己的,名为 Zeek Logs,依然指向 zeek-*。Kibana 给它分配了另一个不同的 ID,比如 04851901-723f-41fe-bdc7-3917b41aa1f7。她开始在 Discover 里探索,做了一些可视化,留待以后完善。
星期三 —— Georgie:
Georgie 也是新手,刚登录 Kibana。被界面吸引,直接上手。没错,他又创建了一个 zeek-* 的 data view,这次叫 Dem Zeeky Zeek Logs,ID 又是随机的,比如 b331a8a5-d7e1-412d-b83f-c5d9672ab0c1。他也开始做自己的可视化。
星期四 —— Paige:
团队专家 Paige 发现同一个 Zeek 索引有多个 data view。她觉得重复了,开始清理,删除了 Sheldon 和 Georgie 的 data view。从她角度看,只是整理环境。
星期五 —— 混乱:
Sheldon 和 Georgie 再次登录,发现他们的仪表盘坏了,可视化不再工作。为什么?因为仪表盘里的可视化依赖于那些被删除的、带有唯一随机 data view ID 的 data view。与此同时,Missy 的仪表盘还正常。
为什么会这样?
这源于 Kibana 如何处理保存对象(saved objects)—— 如 data view。
用户创建的可视化、仪表盘、data view 等,都作为保存对象存储在 Kibana 中。这些对象之间有关系。这里,可视化直接关联创建它们时所用的 data view 的 ID。所以当 Paige 删除 data view 时,不知情地破坏了可视化和特定 data view ID 的关联。
重点来了 —— 这也是为什么我认为分配自定义 data view ID 应该被视为最佳实践。
如前所述,默认情况下,Kibana 给 data view 分配长且随机的 ID,这些 ID 很难被用户记住以便重用。问题是,当某个 data view 被删除后,任何用它创建的可视化依然引用那个已不存在的 ID。
技术上,用户可以重新创建已删除的 data view,并手动赋予相同的随机 ID(前提是之前保存过该 ID),这样可恢复损坏的可视化。但注意:即使这样,解决方案也需要自定义 data view ID。
那为什么不从一开始就做呢?
从一开始创建直观的自定义 data view ID(比如 zeek)可以显著优化工作流程:
-
避免重复 data view:Kibana 不允许多个 data view 使用相同的自定义 ID,若尝试创建重复的,会提醒已存在。
-
简化恢复:意外删除后,用户可快速用相同的自定义 ID(如 zeek)重新创建,而不用记复杂的随机 ID。
-
促进可扩展性:环境扩大后,管理成百上千的可视化时,这小习惯带来巨大差异。否则,用户可能不知不觉创建多个 Zeek 相关但 ID 不同的 data view,散布在多个仪表盘中。删除其中部分会导致可视化坏掉,引发混乱和浪费时间。
这看似小细节,但我见过无数团队被它绊倒,问题很快变得一团糟。从一开始分配自定义 data view ID,可以让混乱变得井然有序。
使用 Young Sheldon 数据的操作演示(反正为什么不呢?)
Sheldon 使用 demo-young-sheldon 索引创建了一个 data view。使用的参数如下:
- 名称/Name:demo-young-sheldon
- 索引模式/Index Pattern:demo-young-sheldon
- 自定义 data view ID/Custom Data View ID:demo-young-sheldon
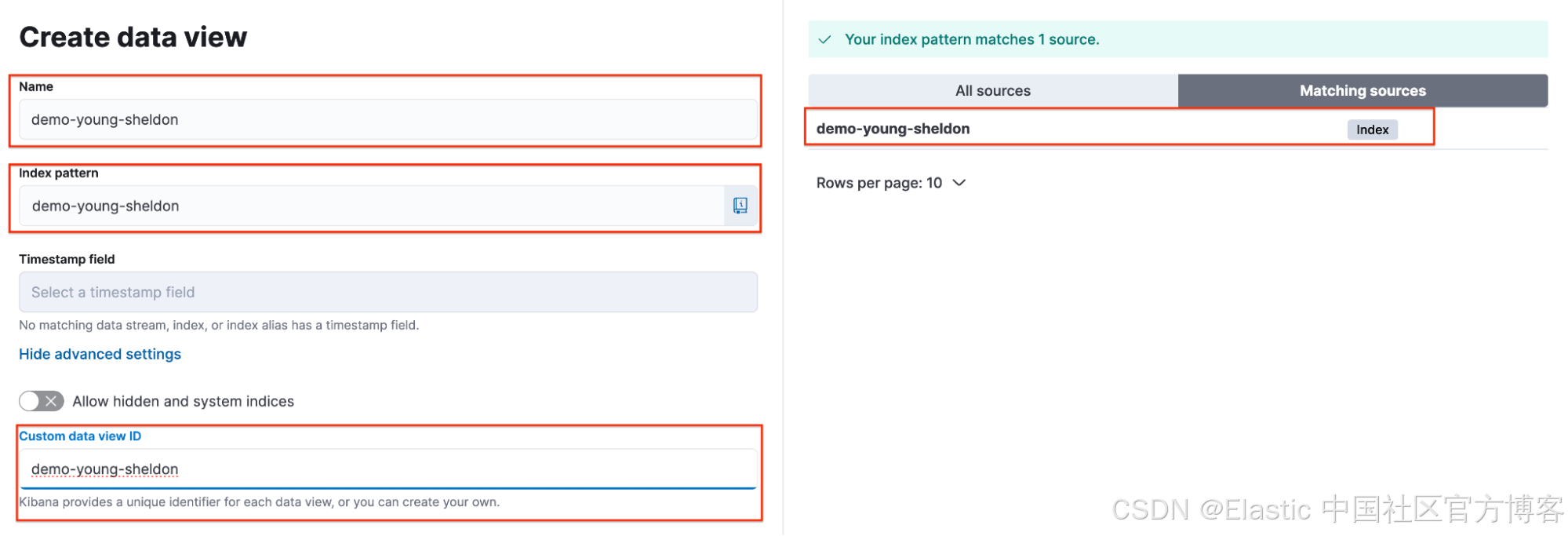
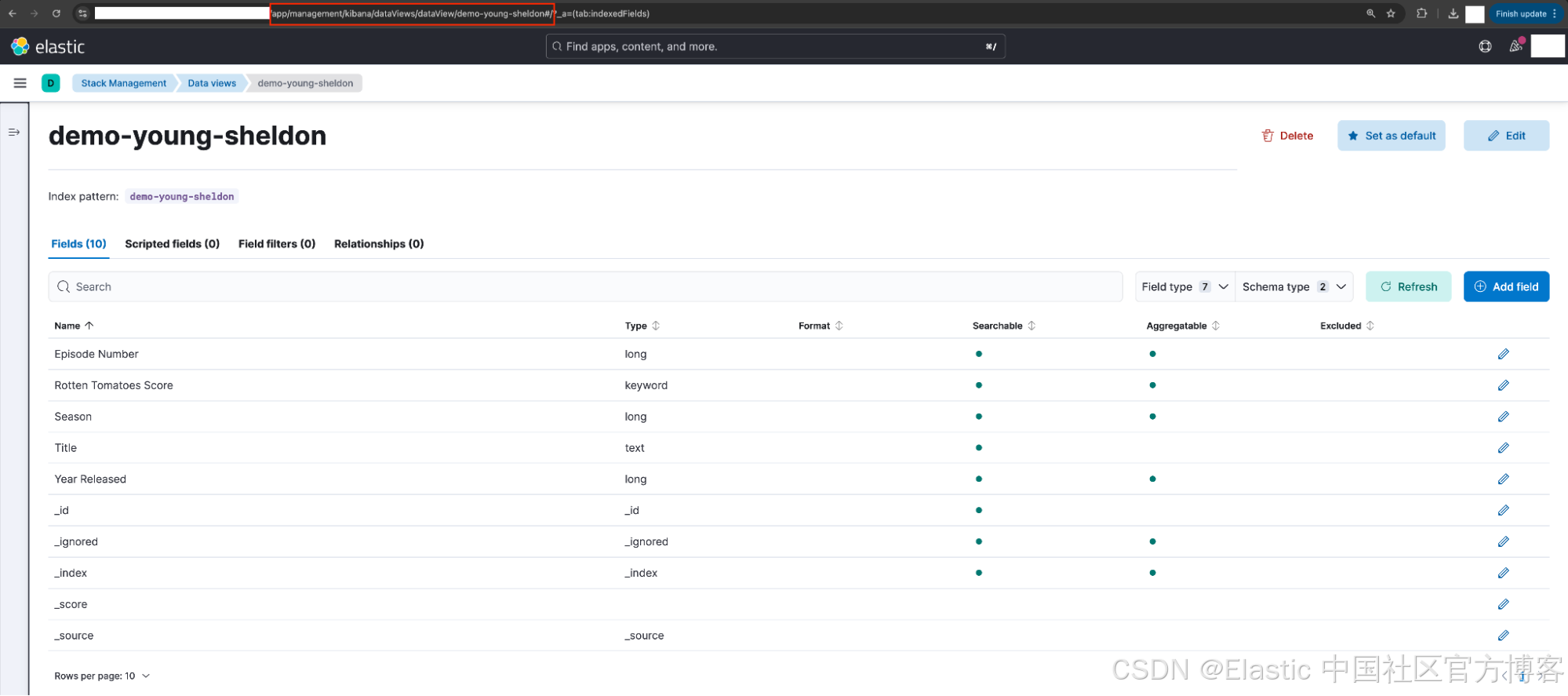
Sheldon 选择了该 data view,并确认自定义 data view ID 已正确设置。
注意:可以通过浏览器 URL 快速验证这一点。
Georgie 使用 demo-young-sheldon 索引创建了一个 data view。使用的参数如下:
- 名称/Name:demo-young-sheldon-test
- 索引模式/Index Pattern:demo-young-sheldon
- 自定义 data view ID/Custom Data View ID:无(空白)
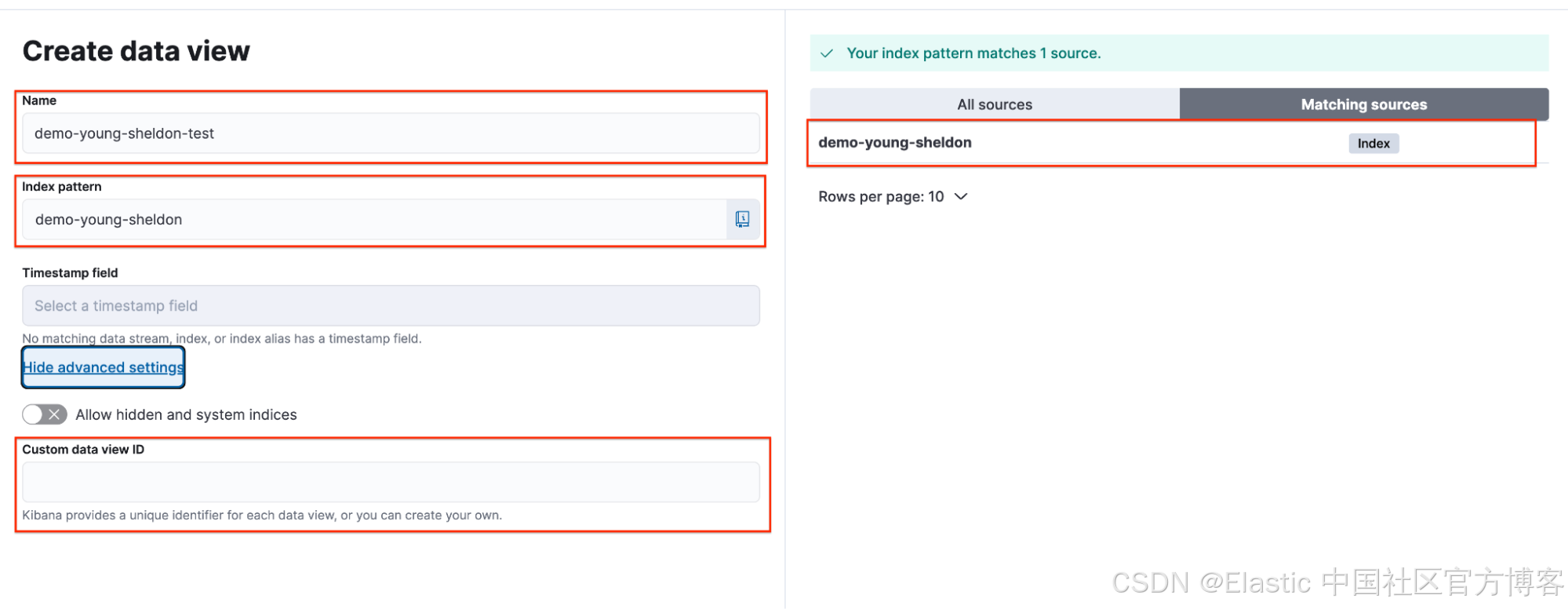
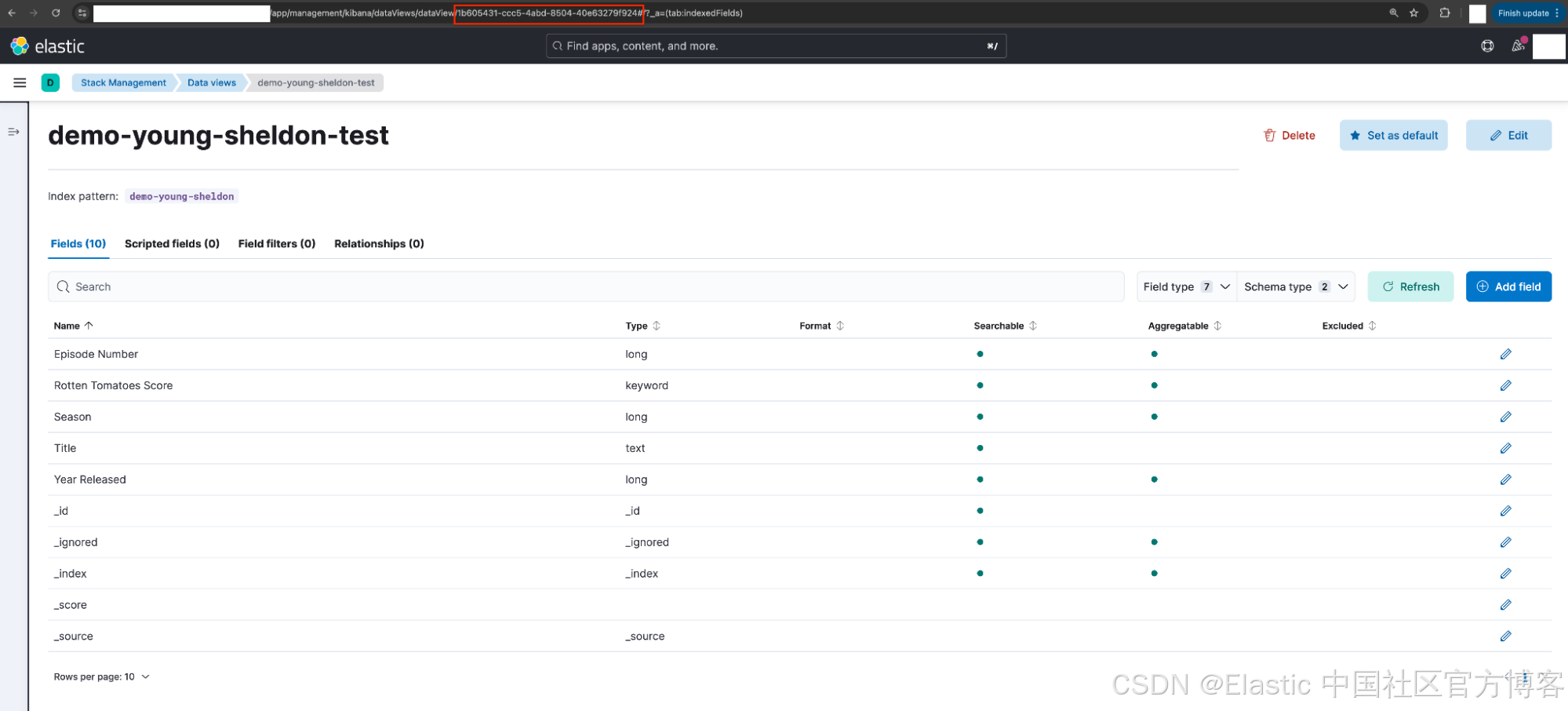
Georgie 选择 data view,并确认 data view ID(由于之前留空)已设置为自动生成的随机字符串。
注意:这可以通过浏览器 URL 快速验证。
Sheldon (demo-young-sheldon) 和 Georgie (demo-young-sheldon-test) 分别使用各自的数据视图创建可视化效果并将其添加到共享仪表板。
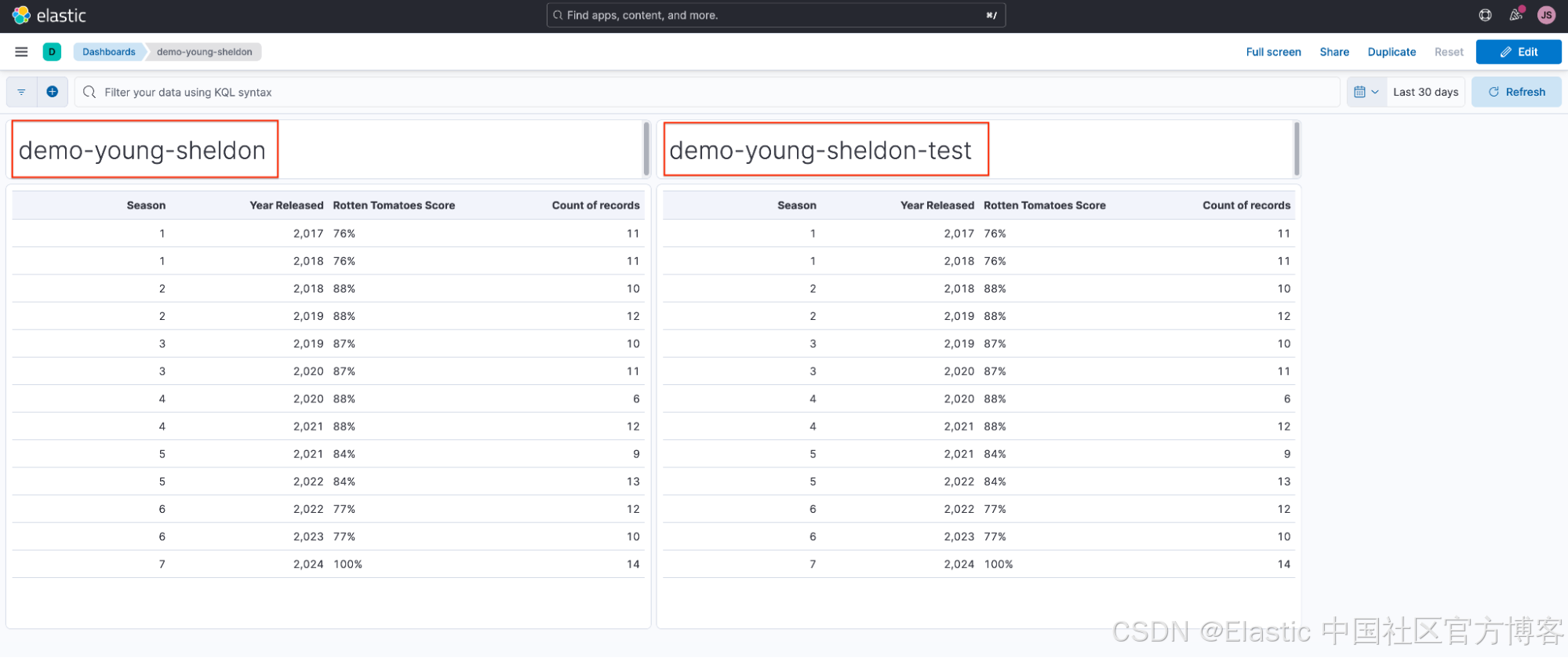
谢尔顿 (Sheldon) 和乔治 (Georgie) 意外删除了他们的数据视图,当他们导航回仪表板时,他们发现他们的可视化效果已损坏。
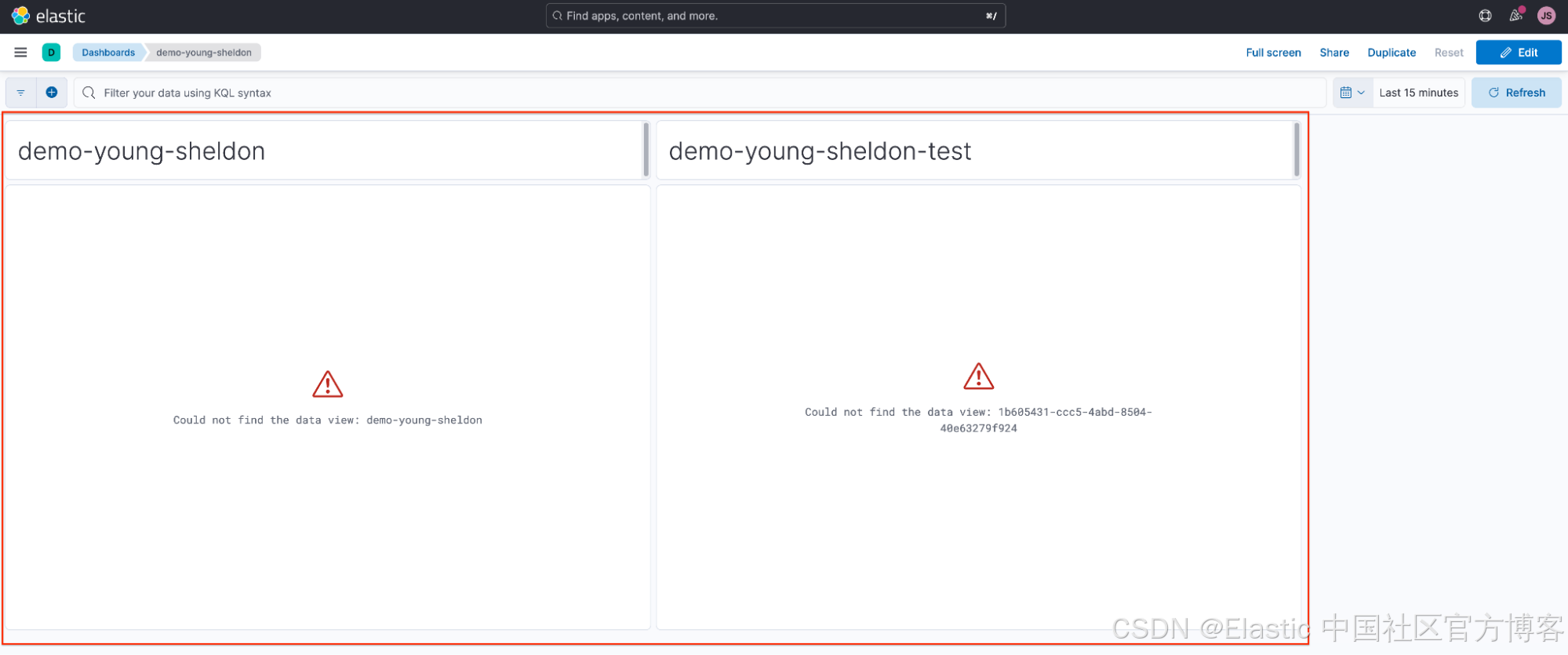
Sheldon 策略性地为其数据视图分配了一个自定义数据视图 ID,从而简化了恢复过程。要恢复可视化效果,他只需重新创建数据视图并使用相同的自定义数据视图 ID:demo-young-sheldon。
使用以下参数:
- 名称/Name:demo-young-sheldon-recreated
- 索引模式/Index Pattern:demo-young-sheldon
- 自定义数据视图 ID/Custom Data View ID:demo-young-sheldon
注意:在本演示中,我略微修改了数据视图名称,以便清晰易懂并与之前的步骤区分开来(名称:demo-young-sheldon → demo-young-sheldon-recreated)。
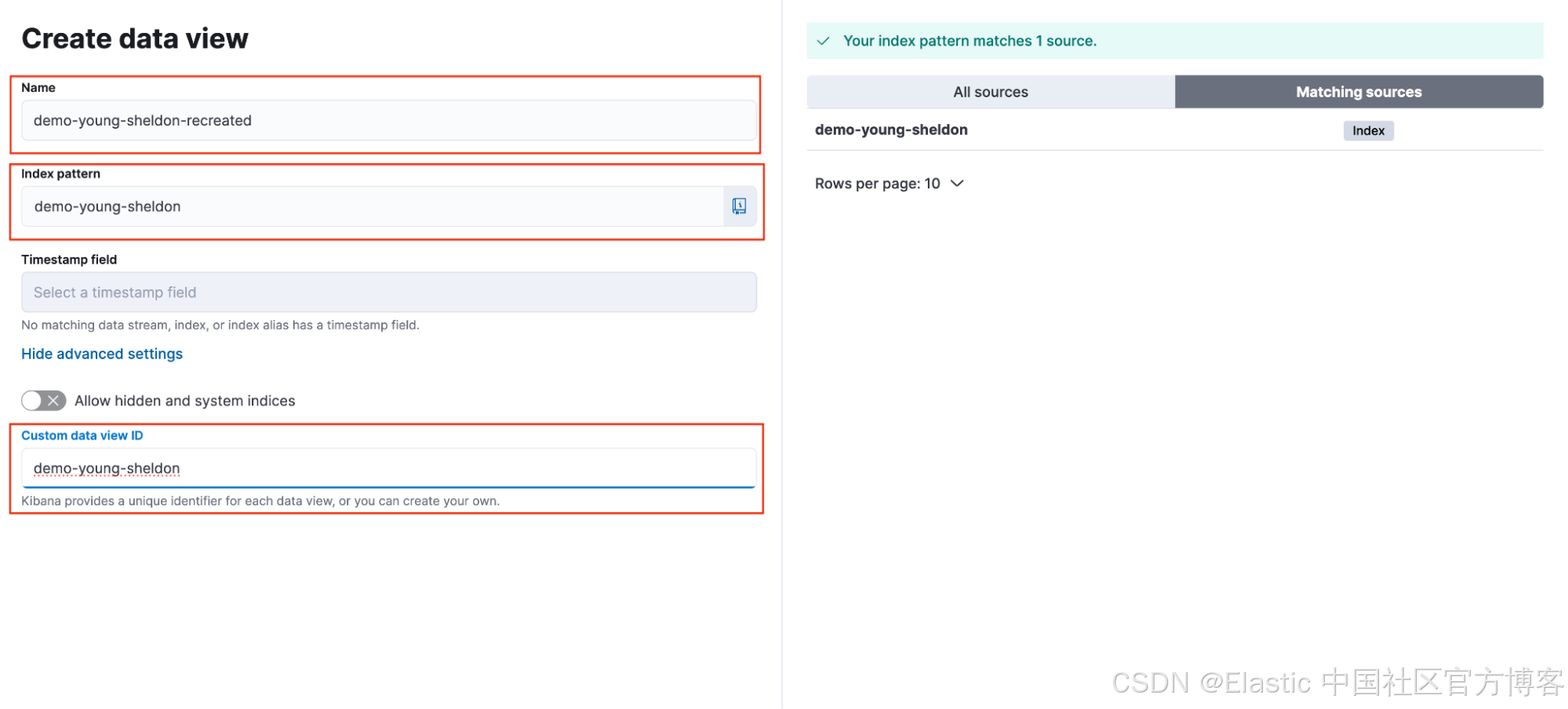
Sheldon 返回共享仪表板,确认他的可视化已成功恢复。
Georgie 可以按照类似的流程恢复他的可视化。但是,他必须设置 custom data view ID,使其与右图所示的随机生成的字符串匹配。
你正在这么想,而且你说得没错(但也不完全正确)。
你可能会想:“好吧,我可以重新创建 `demo-young-sheldon-test` 数据视图,并手动分配可视化中引用的相同随机生成的数据视图 ID。”

你说得完全正确。这种方法理论上确实有效。
但现在,让我们扩展一下场景。
假设您有 30 位用户,其中 10 位分别创建了 demo-young-sheldon 数据视图的变体,每个视图都有一个随机生成的不同数据视图 ID。他们使用这些数据视图构建了数百个可视化效果,然后分布在多个仪表板上。
后来,有人在查看环境时发现 10 个数据视图的名称相似,并且所有视图都关联了相同的索引模式。他们假设这些视图是重复的,于是删除了其中 9 个,却没有意识到每个视图都通过数据视图 ID 唯一地与特定的可视化效果关联。
现在,你遇到了一个问题。许多可视化效果分布在多个仪表板上,而且在很多情况下,用户并不知道单个仪表板中的可视化效果使用的并非同一个数据视图。例如,用户注意到以下数据视图:zeek-1、zeek-2、zeek-3、zeek-4 和 zeek-5。
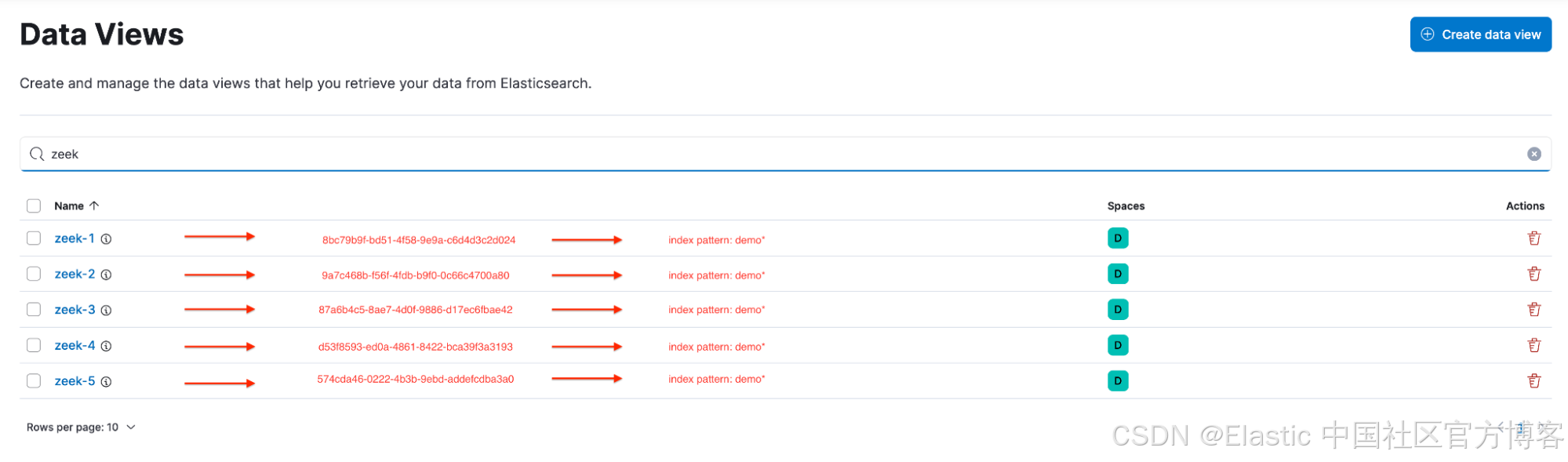
由于所有数据视图都指向相同的索引模式,因此用户在构建可视化并将其添加到共享仪表板时通常不会再三考虑。
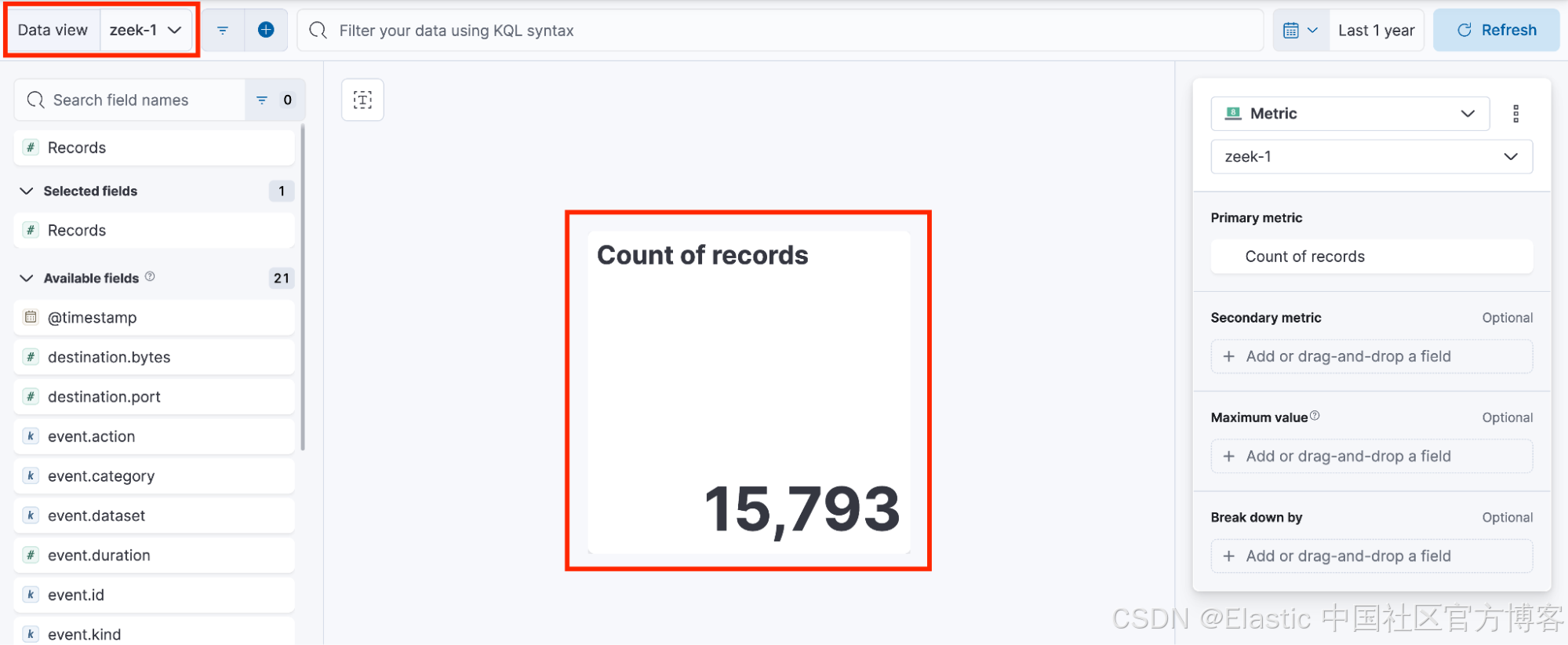
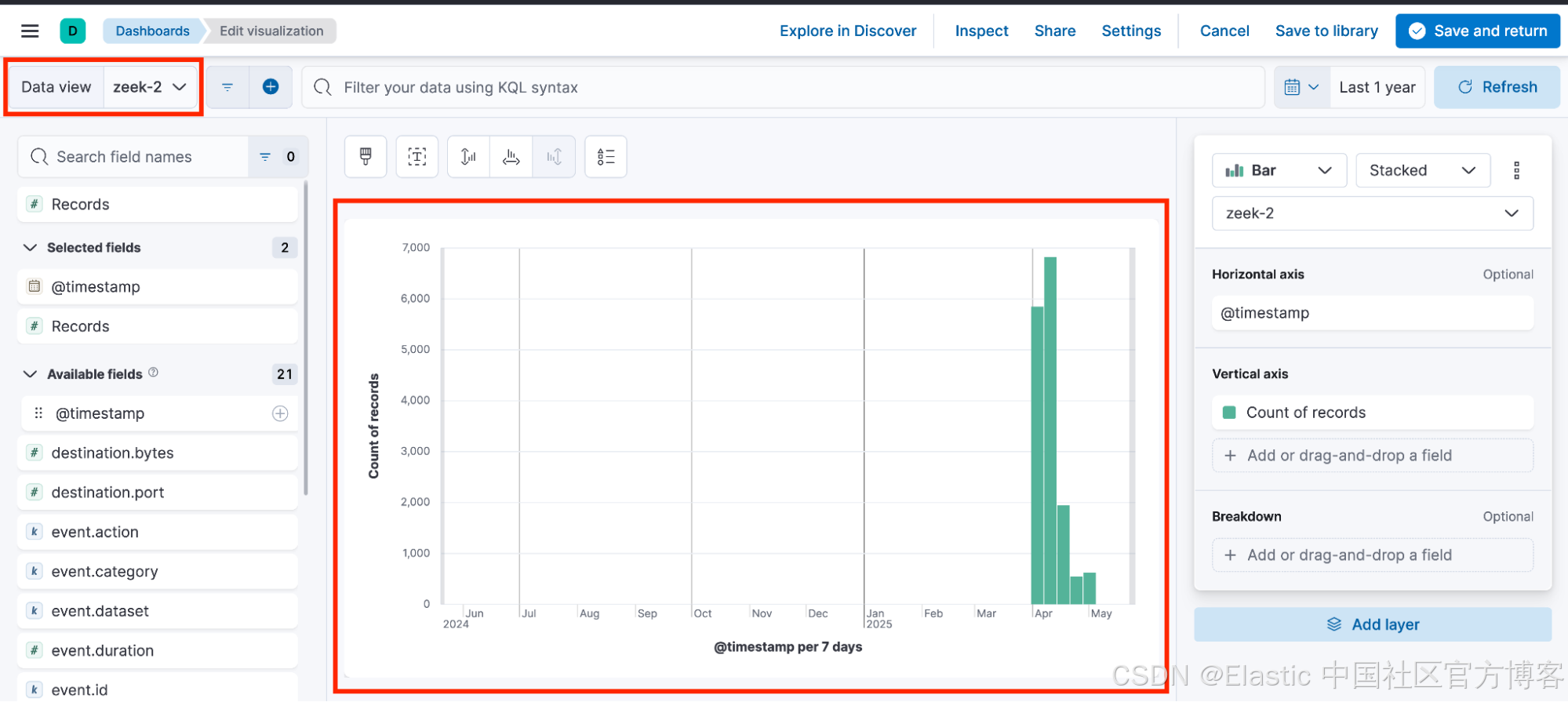
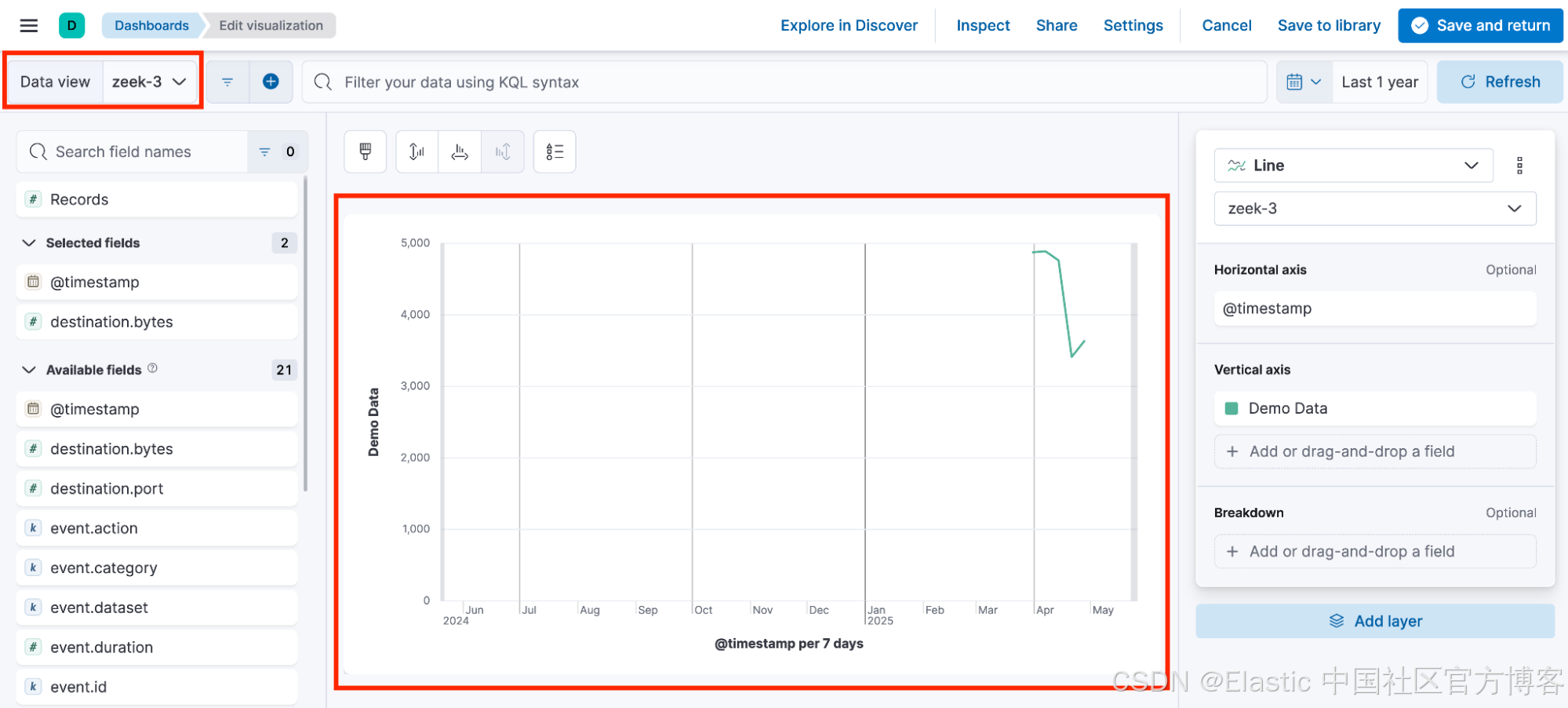
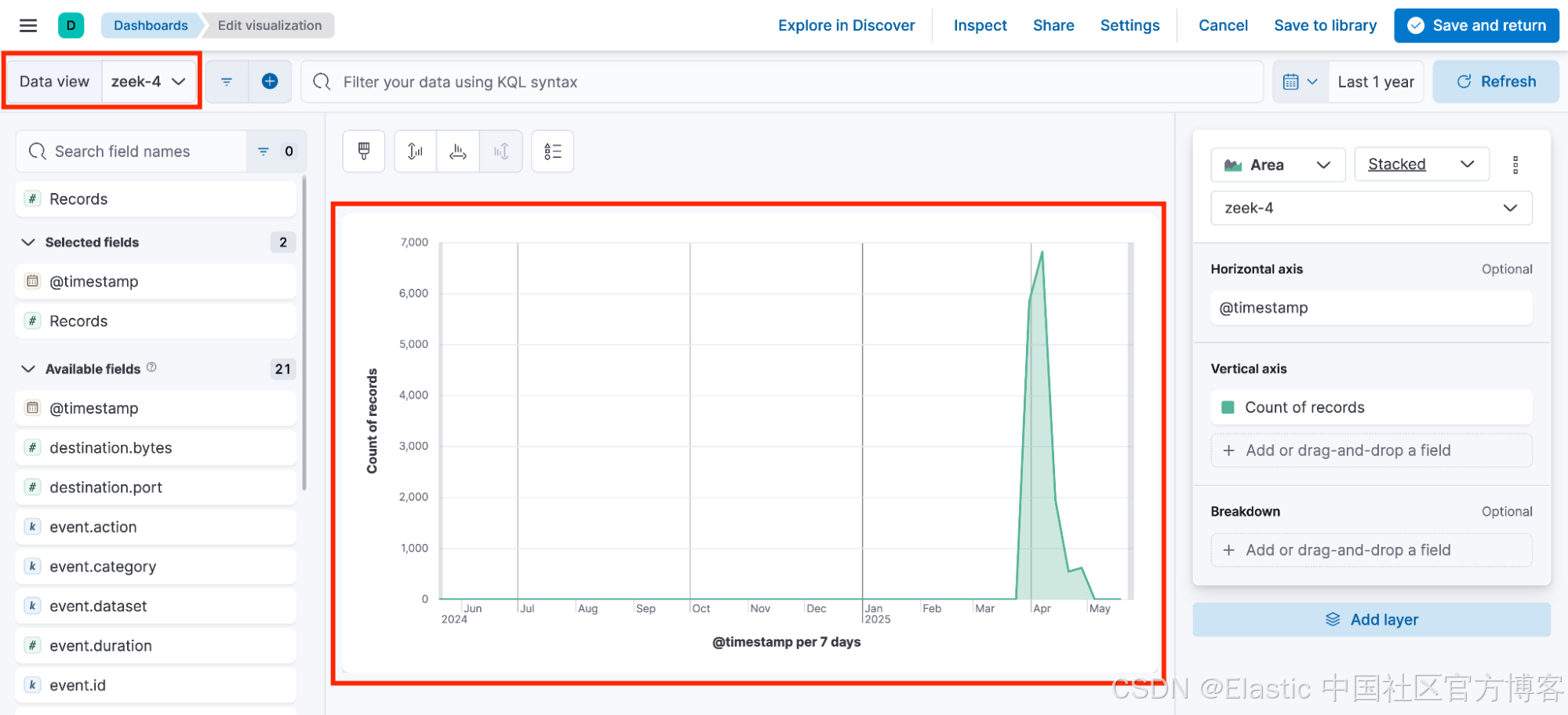
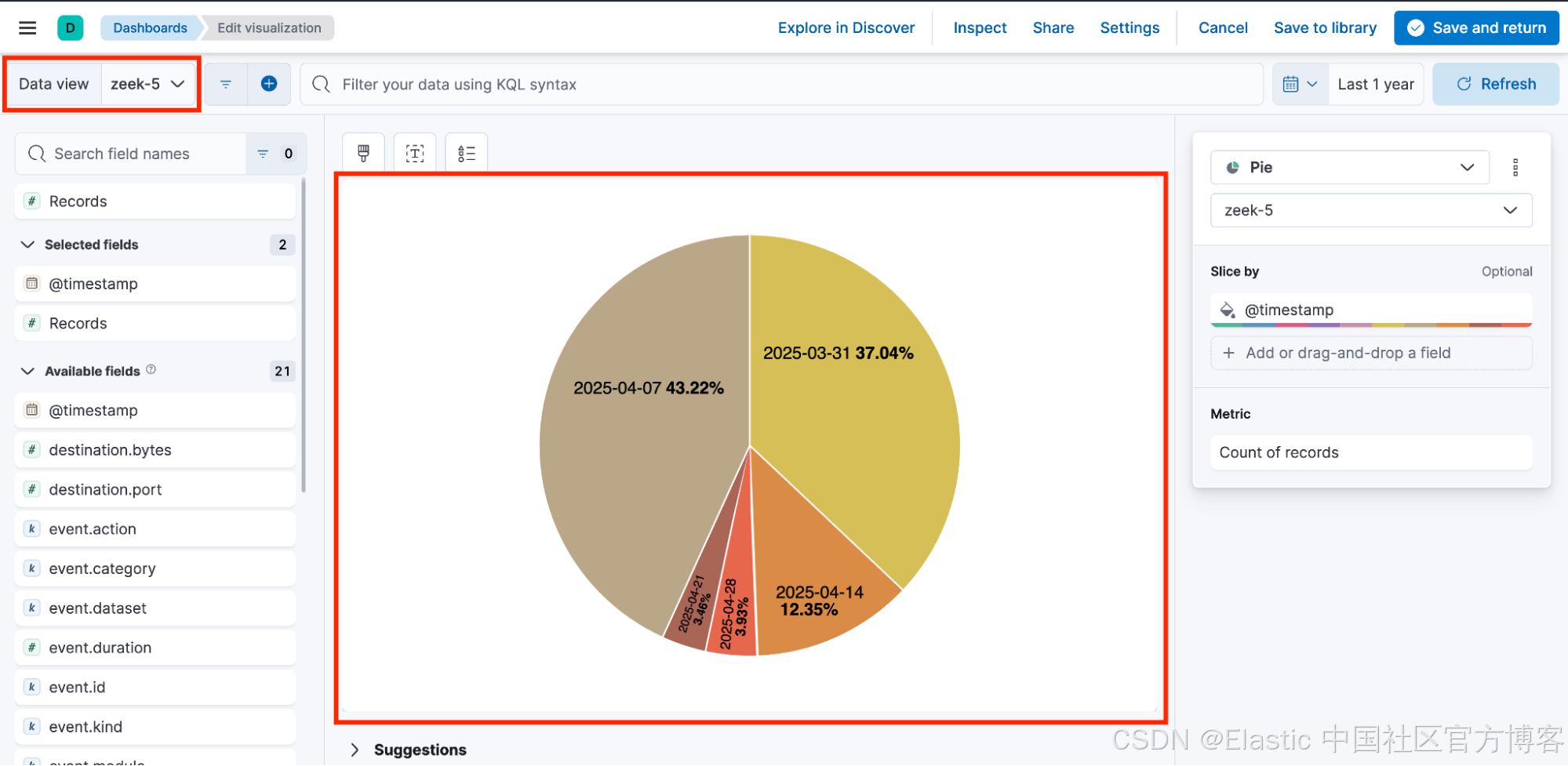
因此,仪表板最终包含依赖于不同数据视图的可视化效果,每个数据视图都有自己随机生成的 ID。
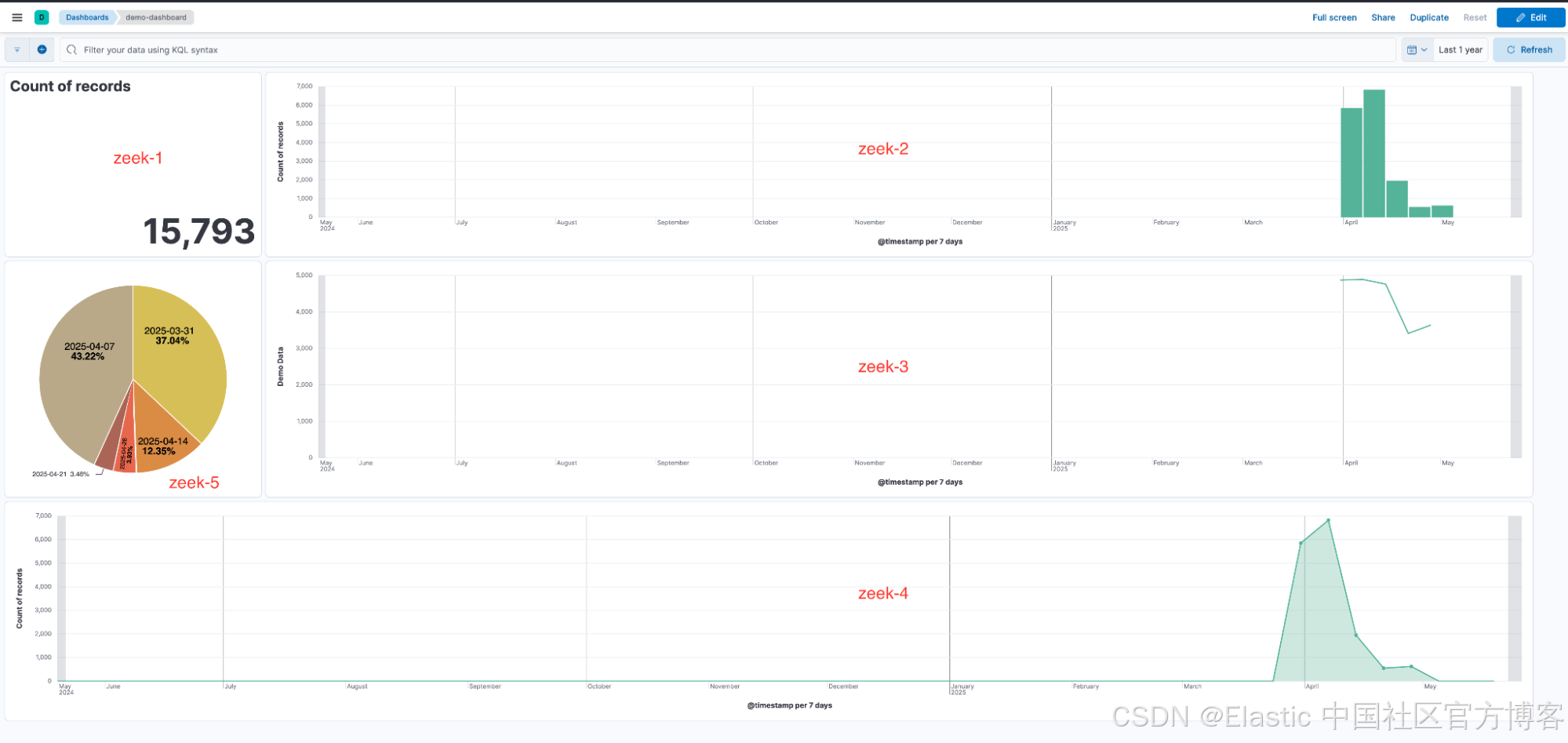
这些不一致可能会导致可视化在删除其中一个关联数据视图时中断,正如之前在《少年谢尔顿》演示中演示的那样。
协作环境中的常见问题
这是协作环境中的常见问题。要修复这些问题,你需要手动重新创建 9 个已删除的数据视图,并以某种方式恢复并重新分配原始 UUID,或者修改每个可视化以使用剩余的一个数据视图 —— 这是一项繁琐且容易出错的任务。
与此相比,如果所有用户都使用共享的自定义数据视图 ID(例如 demo-young-sheldon),则只需重新创建一个具有相同 ID 的数据视图即可恢复所有内容。无需猜测,无需处理分散的 ID,也无需进行不必要的清理工作。
简而言之:自定义数据视图 ID 可显著降低协作环境中的复杂性和风险。
一些建议
如果你已经读到这里,我相信你已经准备好开始使用这个被严重低估的自定义数据视图 ID 功能了。你做出了一个明智的决定。我为您感到骄傲!
既然你已经加入团队,是时候让我来告诉你关键点了。
自定义数据视图 ID 策略有几种方法。我推荐的方法简单、可扩展且易于管理。
步骤 1:选择一个清晰易记、能够反映数据集的名称
使其一目了然。
示例:将 “Demo Young Sheldon Data” 更改为 “demo-young-sheldon”
步骤 2:添加创建数据视图的空间名称
这有助于区分环境并避免命名冲突。
示例:demo-young-sheldon-demo
步骤 3:记录并保持简洁
将命名约定和策略记录在共享知识库中,以便于访问和参考。一致的命名方法有助于保持环境井然有序,并使重新创建或识别数据视图变得更加容易,尤其是在协作团队中。
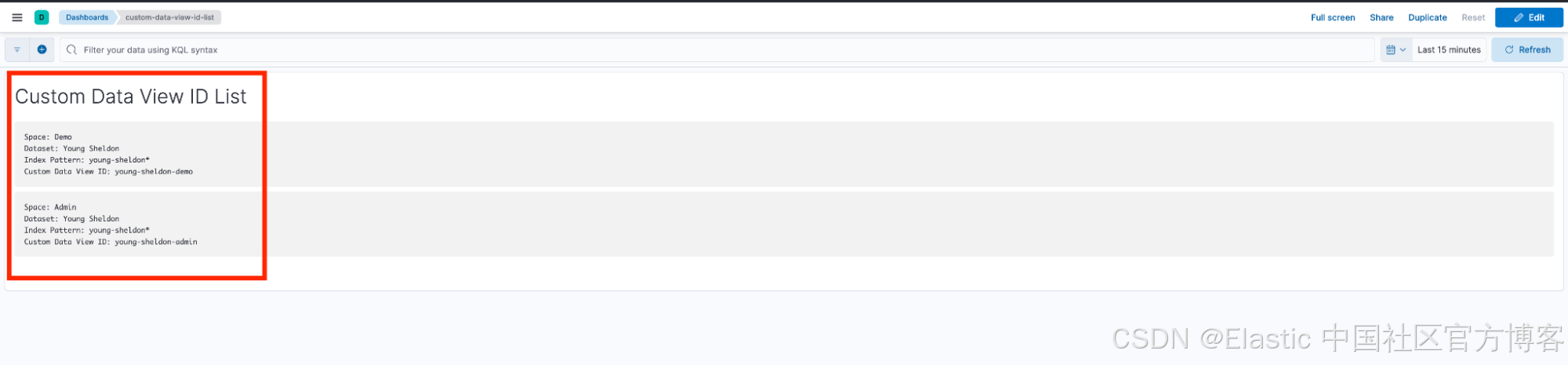
注意:如果您想更进一步,可以直接在 Kibana 中使用文本面板记录策略,如上图所示。或者,你也可以使用团队 Wiki、GitHub 代码库,甚至是简单的电子表格(任何适合你工作流程的方式均可)。
总结
发生了很多事情,所以以下是整篇博文的 TL;DR 版本:
自定义数据视图 ID 功能在你的环境中应该扮演重要角色。就像《少年谢尔顿》中的 Georgie 一样 —— 他已经存在了七季,直到粉丝们意识到他是故事的核心人物。现在,Georgie 和 Mandy 已经独立成篇了。自定义数据视图 ID 也是如此;它们一直都很重要,但现在才得到应有的重视。
当你与更大的团队合作时,自定义数据视图 ID 会变得非常有价值。如果关键数据视图被删除,它们可以让用户快速恢复可视化。依赖随机自动生成的 ID 会使恢复工作变得令人沮丧且耗时。自定义 ID 让一切更简洁、更快捷、更少混乱。
此外,我们还讲解了一个用例,逐步演示了一个实际操作示例,甚至分享了我的个人建议(也就是我自称的最佳实践)。这看似一个小细节,但根据我的经验,忽略这一点会导致一些非常实际甚至非常严重的问题。
你已经看到最后了。太棒了。感谢你的关注。继续,登录 Kibana 并尝试一下自定义数据视图 ID 策略。我相信您会喜欢的。
想要自动创建自定义数据视图 ID?请查看这个 Terraform 资源。
本文中描述的任何特性或功能的发布和时间均由 Elastic 自行决定。任何目前不可用的特性或功能可能无法按时交付,甚至根本无法交付。
原文:Why assigning custom data view IDs matters in Kibana | Elastic Blog


















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









