






作者:来自 Elastic Alex Salgado

学习如何使用四种实用方法在 Elasticsearch 中重命名索引。
想获得 Elastic 认证?看看下一期 Elasticsearch Engineer 培训什么时候开始!
Elasticsearch 拥有丰富的新功能,帮助你根据使用场景构建最佳搜索方案。深入了解我们的示例笔记本,开始免费云试用,或立即在本地机器上体验 Elastic。
你是否曾尝试在 Elasticsearch 中重命名索引,却发现根本没有 rename 的 API 接口?很多人都会遇到这种情况,因为与操作系统中的普通文件不同,Elasticsearch 的索引是复杂且分布式的结构。因此,你不能直接更改名称。如果你想了解如何创建、列出、查询和删除索引,可以查看这篇指南。
在本文中,我们将解释为什么会这样,并介绍四种实用方法来应对这个限制,具体包括:
-
别名,是最轻量的选项;
-
Clone API,可以快速复制索引;
-
快照与恢复,用于基于完整备份的复制;
-
Reindex API,功能最强大,但资源消耗也最大。
为什么 Elasticsearch 不允许直接重命名索引?
Elasticsearch 将数据组织成索引,而索引由分布在集群多个节点上的分片组成。每个分片本质上是一个独立的 Lucene 引擎实例,负责物理存储数据。
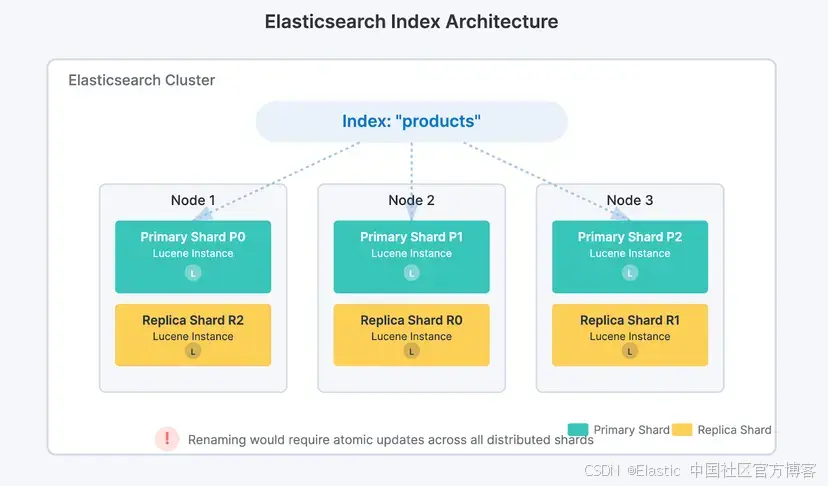
如果可以直接重命名索引,系统就必须在所有节点的所有分片中以绝对原子的方式更新索引名称,以避免不一致。这种复杂性以及数据损坏的风险让开发者决定不实现这个功能。
然而,在很多场景下确实有重命名索引的需求,例如更改字段映射或数据类型、使命名符合公司新标准、解决多租户集群中的冲突,或替换从旧系统继承的名称。
别名:最简单且最灵活的解决方案
当我们只需要让应用程序通过另一个名字访问索引时,最好的解决方案是使用别名(alias)。可以把别名看作索引的昵称。它们不会复制数据,也不会更改磁盘上的任何内容 —— 它们只是更新集群中的元数据,使新名称 “指向” 真实索引。这种更改几乎是瞬时完成的,因为它只更新集群元数据,不会影响查询性能,无论索引有多大。
例如,如果我们有一个名为 old_index 的索引,并希望应用程序开始使用 new_index,只需添加如下别名:
POST /_aliases
{
"actions": [
{
"add": {
"index": "old_index",
"alias": "new_index"
}
}
]
}如果你的应用程序通过别名写入数据,你可能需要指定写入索引(write index):
POST /_aliases
{
"actions": [
{
"add": {
"index": "new_index",
"alias": "production_alias",
"is_write_index": true
}
}
]
}关于写入索引的行为及其适用场景的更多详情,请参阅 Write index 文档。
这种方式为我们的应用程序提供了灵活性,有助于实现平滑过渡和逻辑隔离,尤其适用于基于微服务的架构,每个服务可能需要不同的访问数据方式或命名约定。
Clone API:快速复制,但有一些限制
如果不能使用别名,并且需要一个具有新名称的索引,下一步可以使用 Clone API。这一功能会创建原始索引的物理副本,但不会复制数据,而是通过文件系统中的硬链接重用数据文件。这使得操作比完全重建索引要快得多。
重要提示: Clone API 有多个限制。它不会复制索引元数据,如别名、ILM 策略或 CCR 设置。目标索引必须不存在,并且两个索引必须拥有相同数量的主分片。完整的要求与限制请参见 Clone Index API 文档。
在克隆之前,原始索引需要处于只读模式且健康状态为 green,以确保操作期间数据不会被修改:
PUT /old_index/_settings
{
"settings": {
"index.blocks.write": true
}
}然后,只需执行克隆操作:
POST /old_index/_clone/new_index最后,如有需要,我们可以解除新索引的写入限制:
PUT /new_index/_settings
{
"settings": {
"index.blocks.write": false
}
}即使数据通过硬链接被重用,确保有足够的磁盘空间仍然很重要,因为新索引需要保持独立。
快照/恢复:基于备份的重命名
如果你需要索引的完整且独立的副本,快照和恢复提供了一个有趣的替代方案,尤其对于大索引来说,可能比重建索引更快。此方法利用了 Elasticsearch 的备份功能,并且在恢复过程中支持重命名索引。
这种方法特别适合已经将快照作为备份策略一部分的情况。它也适用于处理大索引时重建索引过于耗时、在集群间迁移数据,或需要保证数据的时间点一致性副本的场景。
首先,确保你已经配置了快照仓库。如果没有,而这是使用此方法的前提条件,请参阅快照仓库文档。你可以用以下命令检查现有仓库:
GET /_snapshot接下来,创建索引的快照:
PUT /_snapshot/my_repository/rename_snapshot?wait_for_completion=true
{
"indices": "old_index",
"include_global_state": false
}重要提示:和重建索引一样,确保在快照过程中索引没有写操作,以保证数据一致性。
最后,使用 rename_pattern 和 rename_replacement 以新名称恢复快照:
POST /_snapshot/my_repository/rename_snapshot/_restore
{
"indices": "old_index",
"rename_pattern": "old_index",
"rename_replacement": "new_index"
}对于更复杂的重命名模式,你可以使用正则表达式:
POST /_snapshot/my_repository/rename_snapshot/_restore
{
"indices": "logs-*",
"rename_pattern": "logs-(.+)",
"rename_replacement": "archived-logs-$1"
}重建索引:最强大且灵活的工具
当需要超越简单复制或重命名时,应该使用 Reindex API。它不仅允许我们将数据从一个索引复制到另一个索引,还可以执行转换、过滤、结构调整、合并多个索引等复杂操作。
可选的安全步骤:重建索引操作本身不会修改或影响原始索引。但如果你计划在重建后删除原索引(如本文后面所示),建议先创建备份:
PUT /_snapshot/my_backup/snapshot_before_reindex?wait_for_completion=true
{
"indices": "old_index"
}对于大索引,考虑使用 wait_for_completion=false 来避免超时,然后通过 GET /_snapshot/my_backup/snapshot_before_reindex/_status 监控快照进度。
接下来,我们获取原始索引的设置和映射,以正确创建目标索引:
GET /old_index 这个命令会同时返回设置和映射。
现在,我们需要用这些设置创建目标索引。如果你没有配置索引模板,必须在重建索引之前手动创建索引:
PUT /new_index
{
"settings": {
// paste the settings obtained from the original index here, but remove any system-generated settings like index.provided_name, etc.
},
"mappings": {
// paste the mappings obtained from the original index here
}
}重要注意事项:
- 复制设置时,删除所有只读和系统生成的属性。只保留可配置的设置,如 number_of_replicas、refresh_interval、analysis 等。关于哪些设置可以在创建索引时指定,详见索引设置文档。
- 如果跳过这一步且没有模板,Elasticsearch 会在重建索引时自动创建索引,使用动态映射,可能导致字段数据类型错误。
- 正确创建目标索引后,按如下方式执行基本的重建索引操作:
POST /_reindex
{
"source": { "index": "old_index" },
"dest": { "index": "new_index" }
}对于大索引,我们可以通过后台运行、使用 slices 并行处理,以及控制吞吐量来优化操作,避免集群过载。还可以应用脚本,在复制数据时修改内容。
例如:
POST /_reindex?slices=auto&wait_for_completion=false&refresh=false
{
"source": { "index": "old_index" },
"dest": {
"index": "new_index"
},
"conflicts": "proceed",
"script": {
"source": "ctx._source.status = 'migrated';"
}
}让我们了解每个参数的作用:
-
slices=auto:通过将任务分成多个片(线程)实现并行处理。auto 让 Elasticsearch 根据分片数量自动决定最佳线程数。
-
wait_for_completion=false:后台执行操作,立即返回任务 ID,而不是等待完成。
-
"refresh": false:复制期间禁用目标索引的自动刷新,显著提升性能。数据只有在手动刷新后才可被搜索。重建完成后,运行:POST /new_index/_refresh。
-
"conflicts": "proceed":遇到文档版本冲突时继续执行重建,而不是在第一个错误停止。
-
"script":在复制时对每个文档应用转换。例如,在此示例中,给所有文档添加了一个值为 "migrated" 的字段 "status"。
控制传输速率(限流)
为了避免集群过载,我们可以限制重建索引的速度:
POST /_reindex?requests_per_second=500
{
"source": { "index": "old_index" },
"dest": { "index": "new_index" }
}使用 wait_for_completion=false 时,响应会立即返回一个任务 ID:
{
"task": "oTUltX4IQMOUUVeiohTt8A:12345"
}保存这个 ID,因为你需要用它来跟踪进度,尤其是当你同时运行多个重建索引操作时。
要跟踪特定任务的进度,可以这样使用任务 ID:
GET /_tasks/oTUltX4IQMOUUVeiohTt8A:12345 或者,要查看所有正在进行的重建索引操作:
GET /_tasks?actions=*reindex&detailed=true如果你丢失了任务 ID,可以列出所有活动任务并查找你的任务:
GET /_tasks?actions=*reindex&detailed=true&group_by=parents 在修改别名前,先确认重建索引是否成功。检查文档数量、索引大小和健康状态,并运行一些测试搜索,确保数据正确。
-
比较文档数量:
GET /old_index/_count GET /new_index/_count -
检查索引大小和健康状态:
GET /_cat/indices/old_index,new_index?v&h=index,docs.count,store.size,health -
运行一些测试搜索,确保数据正确:
GET /new_index/_search { "size": 5, "query": { "match_all": {} } }确认并验证无误后,更新别名指向新索引,确保应用程序持续正常运行:
POST /_aliases { "actions": [ { "remove": { "index": "old_index", "alias": "production_alias" } }, { "add": { "index": "new_index", "alias": "production_alias", "is_write_index": true } } ] }只有在确认无误后,才能安全地删除旧索引:
DELETE /old_index
什么时候使用 Reindex API?
这个工具适用于多种日常场景。它可以用来迁移遗留数据到新结构、修正字段或值的数据类型、将多个索引的数据合并到一个索引中、只重建符合特定条件的文档,甚至在迁移过程中应用 ingest pipeline 来丰富数据。
尽管功能多样,重建索引消耗资源较大,因此务必先进行测试并密切监控集群。
各方法特点总结:
| 方法 | 什么时候使用 | 速度 | 集群影响 |
|---|---|---|---|
| Alias | 只需要更改访问名称 | Instantaneous | None |
| Clone | 需要完全相同的物理副本 | Fast (hard links) | Low |
| Snapshot/Restore | 需要硬拷贝或跨集群复制 | Moderate | Low |
| Reindex | 需要转换数据或结构 | Slow (copies everything) | High |
结论
在 Elasticsearch 中,不能直接重命名索引。这个限制源自系统的分布式架构,索引由分布在集群节点上的多个分片组成。
如果只需更改应用访问索引的名称,可以使用别名 —— 速度快、安全且无影响。需要完全相同的物理副本时,使用克隆。对于完整的硬拷贝或跨集群操作,快照/恢复提供可靠方案。只有在必须转换数据或结构时,才使用重建索引,但需谨慎操作。
无论哪种情况,都要在操作后验证数据、记录变更,并保持备份更新,以确保操作的完整性和连续性。
参考资料
有关本文讨论概念的详细信息,请参阅官方 Elasticsearch 文档:
-
Aliases API — 创建和管理索引别名的完整指南
-
Clone Index API — 使用硬链接克隆索引的文档
-
Reindex API — 重建索引操作的全面指南,包括限流和异步执行
-
Task Management API — 如何监控重建等长时间运行的操作
-
Index Settings — 了解索引设置,包括只读限制
-
Restore a snapshot — 恢复 API 的完整指南,包括 rename_pattern 的使用
-
Snapshot and restore overview — 覆盖快照/恢复整个流程的综合指南


















 1263
1263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









