






 本文介绍了如何利用Elasticsearch的diskusageAPI来分析索引存储消耗,强调了映射配置对存储的影响。通过对比有映射和无映射的索引,展示了正确的字段建模如何显著减少存储需求。文章提供了详细步骤,包括数据准备、API调用、结果分析和最佳实践,帮助优化Elasticsearch部署的存储效率。
本文介绍了如何利用Elasticsearch的diskusageAPI来分析索引存储消耗,强调了映射配置对存储的影响。通过对比有映射和无映射的索引,展示了正确的字段建模如何显著减少存储需求。文章提供了详细步骤,包括数据准备、API调用、结果分析和最佳实践,帮助优化Elasticsearch部署的存储效率。
你是否曾经查看过你的索引并想了解更多关于在你的 Elastic 部署中是什么造成你存储消耗的因素? 也许你已经使用默认设置摄取了自定义数据,并且想知道你的数据建模工作在哪里可以产生最大的影响? 在这篇博文中,我们将了解如何使用 Elastic 最近推出的磁盘使用 API (disk usage API)来回答此类问题。
在 Elastic,当我们与客户合作时,最常见的改进领域之一是索引映射配置。 缺少映射或使用错误的类型可能会增加 Elastic 部署中的存储使用量。 这篇文章将帮助你了解哪些字段对驱动你的存储空间影响最大,以及如何通过最佳实践配置来优化损耗。
在如下的展示中,我将使用 Elastic Stack 8.1 来进行展示,尽管其它的界面稍微会有所不同。
入门
如果您尚未使用 Elastic,请使用我们在 Elastic Cloud 上托管的 Elasticsearch 服务创建部署。该部署包括一个用于存储和搜索数据的 Elasticsearch 集群,以及一个用于可视化和管理数据的 Kibana 实例。有关更多信息,请参阅启动 Elastic Stack。我建议在此练习中使用开发或登台环境。
你也可以参考我的文章 “Elastic:开发者上手指南” 来了解更多关于安装 Elasticsearch 及 Kibana 的知识。你可以可以在本地进行部署。
你还需要 Elasticsearch 索引中的一些数据进行分析。如果你创建了一个全新的集群,你可以使用 Kibana 添加一些示例数据。如果你不知道如何添加数据用例,请参考我之前的文章 “Kibana:Kibana 入门 (一)”。
在我的示例中,我使用了一些使用 Filebeat 摄取的日志数据。如果你没有 Filebeat 的数据,请参阅我之前的文章 “Beats:运用 Filebeat module 分析 nginx 日志” 来创建这个日志数据。如果你已经按照文章的步骤进行摄入数据,那么你可以看到如下的数据集:
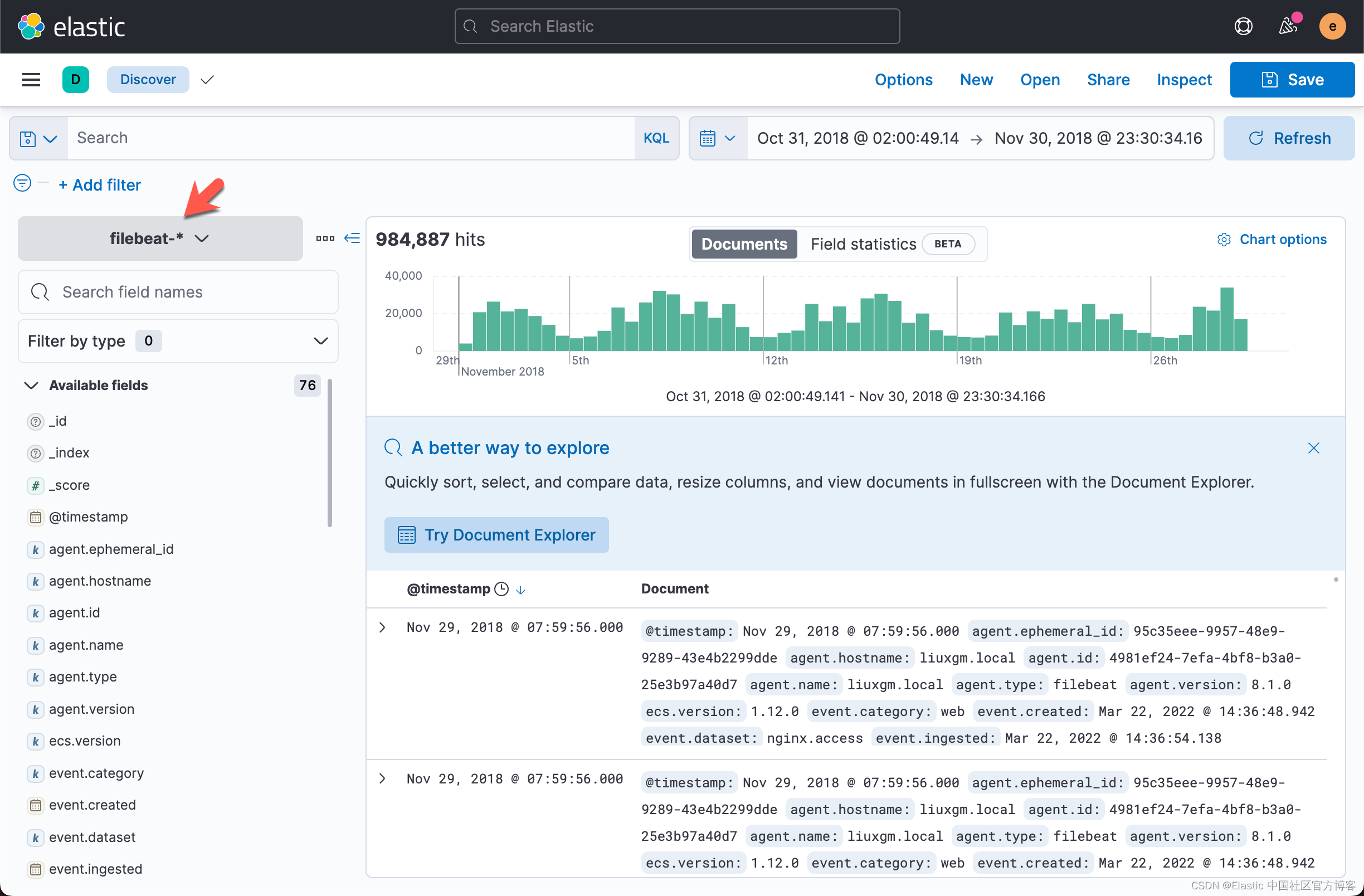
从上面,我们可以看出来它含有 984,887 个文档。
如果你使用 Elastic 的 Beats 或 Elastic Agent 来索引数据,那么很可能已经根据 Elastic 的最佳实践对其进行了建模。这当然很棒,只是它确实让这个练习变得不那么有趣了。幸运的是,我们可以通过将数据模型复制到没有映射配置的索引来轻松丢弃我们的数据模型。我选择了一个索引并使用 Kibana 开发工具执行了以下重新索引操作:
GET .ds-filebeat-8.1.0-2022.03.22-000001/_count或
GET filebeat-*/_count上面显示:
{
"count" : 984887,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}我们使用如下的命令来进行 reindex 操作:
POST _reindex/
{
"source": {
"index": ".ds-filebeat-8.1.0-2022.03.22-000001"
},
"dest": {
"index": "nomapping-filebeat"
}
}请注意,我选择了一个以与 Elastic 的任何标准索引模式都不匹配的前缀开头的目标索引名称 nomapping-filebeat。 这可确保不会从我的索引模板之一自动应用映射。由于文档的数据比较多,在上面的请求中,我们可能会看到 timeout 的返回信息。我稍等一段时间后,使用如下的命令来检查 reindex 的文档数据:
GET nomapping-filebeat/_count{
"count" : 984887,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}它表明我们的文档已经完全被 reindex 了。
通过拥有两份索引副本,一份有适当的映射,一份没有,我们将能够在后面的章节中进行并排比较。
最后的先决条件是 jq,它是一个很好的操作 json 的工具。 我们将使用 jq 将 API 响应转换为文档列表,我们可以使用 Kibana 轻松地将其摄取到 Elasticsearch 中。 这将使通过 Kibana 使用 Discover 接口更容易分析 API 响应。
使用 disk usage API
调用磁盘使用 API很简单,只需转到 Kibana 开发工具并发出类似以下的请求:
POST nomapping-filebeat/_disk_usage?run_expensive_tasks=true请注意 run_expensive_tasks 参数是必需的,通过提供它我承认我在集群上增加了额外的负载。 这也是我之前建议在非生产集群中进行练习的原因。
这是我的回应的顶部:
{
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"nomapping-filebeat" : {
"store_size" : "936.6mb",
"store_size_in_bytes" : 982113614,
"all_fields" : {
"total" : "921.4mb",
"total_in_bytes" : 966255844,
"inverted_index" : {
"total" : "381.3mb",
"total_in_bytes" : 399833939
},
"stored_fields" : "367.7mb",
"stored_fields_in_bytes" : 385623340,
"doc_values" : "134.9mb",
"doc_values_in_bytes" : 141553124,
"points" : "20.1mb",
"points_in_bytes" : 21123346,
"norms" : "17.2mb",
"norms_in_bytes" : 18122095,
"term_vectors" : "0b",
"term_vectors_in_bytes" : 0
},
"fields" : {
"@timestamp" : {
"total" : "5.7mb",
"total_in_bytes" : 6042561,
"inverted_index" : {
"total" : "0b",
"total_in_bytes" : 0
},
"stored_fields" : "0b",
"stored_fields_in_bytes" : 0,
"doc_values" : "2.6mb",
"doc_values_in_bytes" : 2734301,
"points" : "3.1mb",
"points_in_bytes" : 3308260,
"norms" : "0b",
"norms_in_bytes" : 0,
"term_vectors" : "0b",
"term_vectors_in_bytes" : 0
},
"_id" : {
"total" : "10.7mb",
"total_in_bytes" : 11314894,
"inverted_index" : {
"total" : "7mb",
"total_in_bytes" : 7429135
},
"stored_fields" : "3.7mb",
"stored_fields_in_bytes" : 3885759,
"doc_values" : "0b",
"doc_values_in_bytes" : 0,
"points" : "0b",
"points_in_bytes" : 0,
"norms" : "0b",
"norms_in_bytes" : 0,
"term_vectors" : "0b",
"term_vectors_in_bytes" : 0
}该响应提供了索引整体存储使用情况的细分。 我们可以看到倒排索引(inverted_index)是最大的因素,其次是 stored_fields 和文档值(doc_values)。
进一步查看响应,我得到了每个字段的细分,包括 host.name 字段。
"fields" : {
…
"host.name" : {
"total" : "53.6kb",
"total_in_bytes" : 54934,
"inverted_index" : {
"total" : "53.6kb",
"total_in_bytes" : 54934
},
…我们很容易对 API 结果感到满意。 通过在响应 tab 中使用 CTRL-F 功能并搜索“mb”(以兆字节为单位),我们将快速识别索引中的一些大字段。 让我们更进一步,看看我们如何快速重新格式化响应并使用 Kibana 对其进行分析。
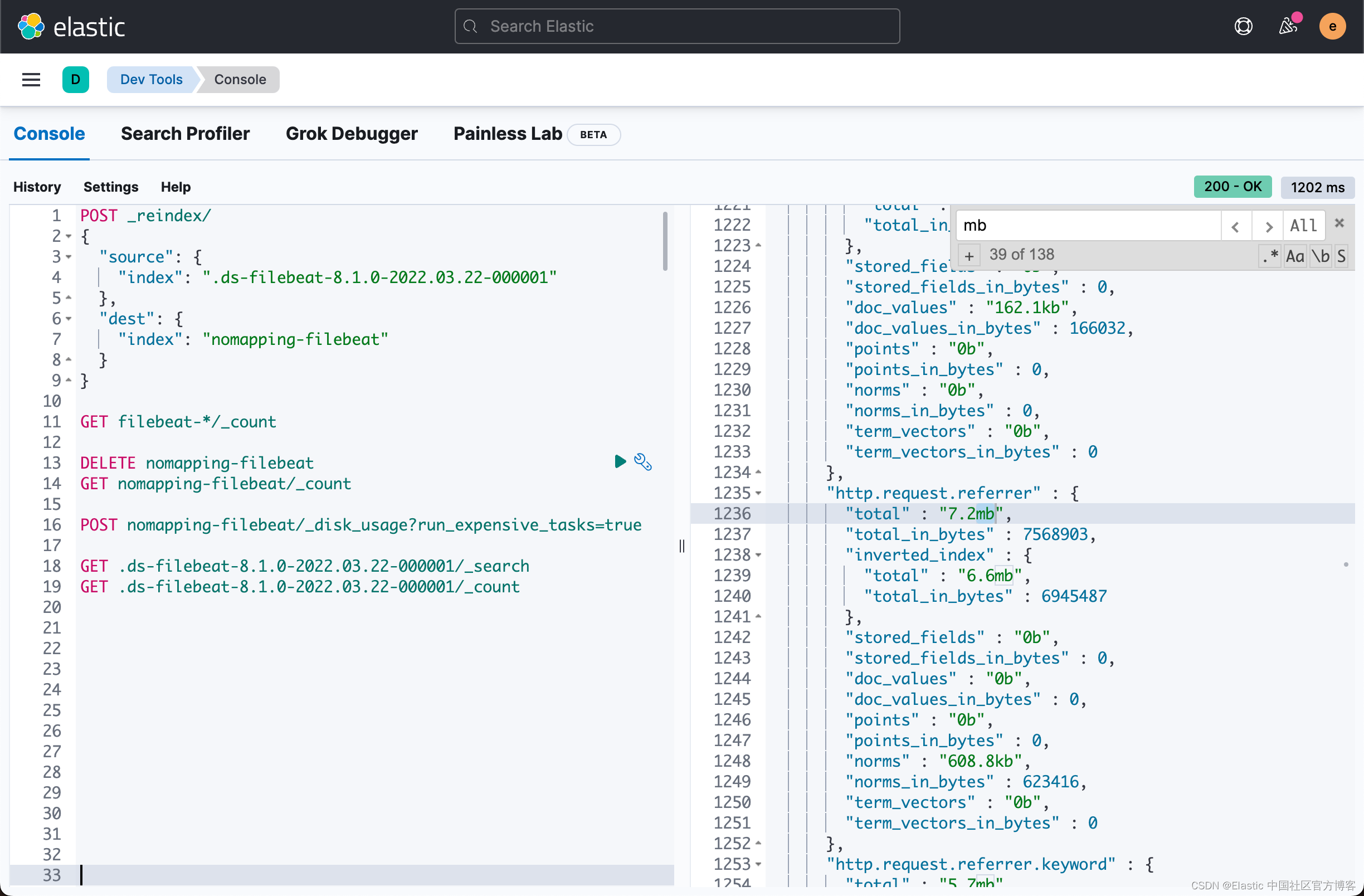
分析 Kibana 中的现场磁盘使用情况
将 API 结果复制粘贴到你喜欢的文本编辑器中并将其保存为文件,在我的例子中是 disk-usage-filebeat.json。 然后运行以下命令,将 nomapping-filebeat 替换为你的索引名称,将 disk-usage-filebeat.json 替换为你最近保存的文件:
jq -c '.["nomapping-filebeat"].fields | to_entries | map({field: .key} + .value) | .[]' disk-usage-filebeat.json > disk-usage-ld.json上面的命令将生成一个叫做 disk-usage-ld.json 文件。它是一个类似如下格式的文件:

该命令将 json 转换为对象列表,每个对象包括字段名称和相关使用数据,并输出换行符分隔的 json。 有关更多信息,请参阅 jq 手册。
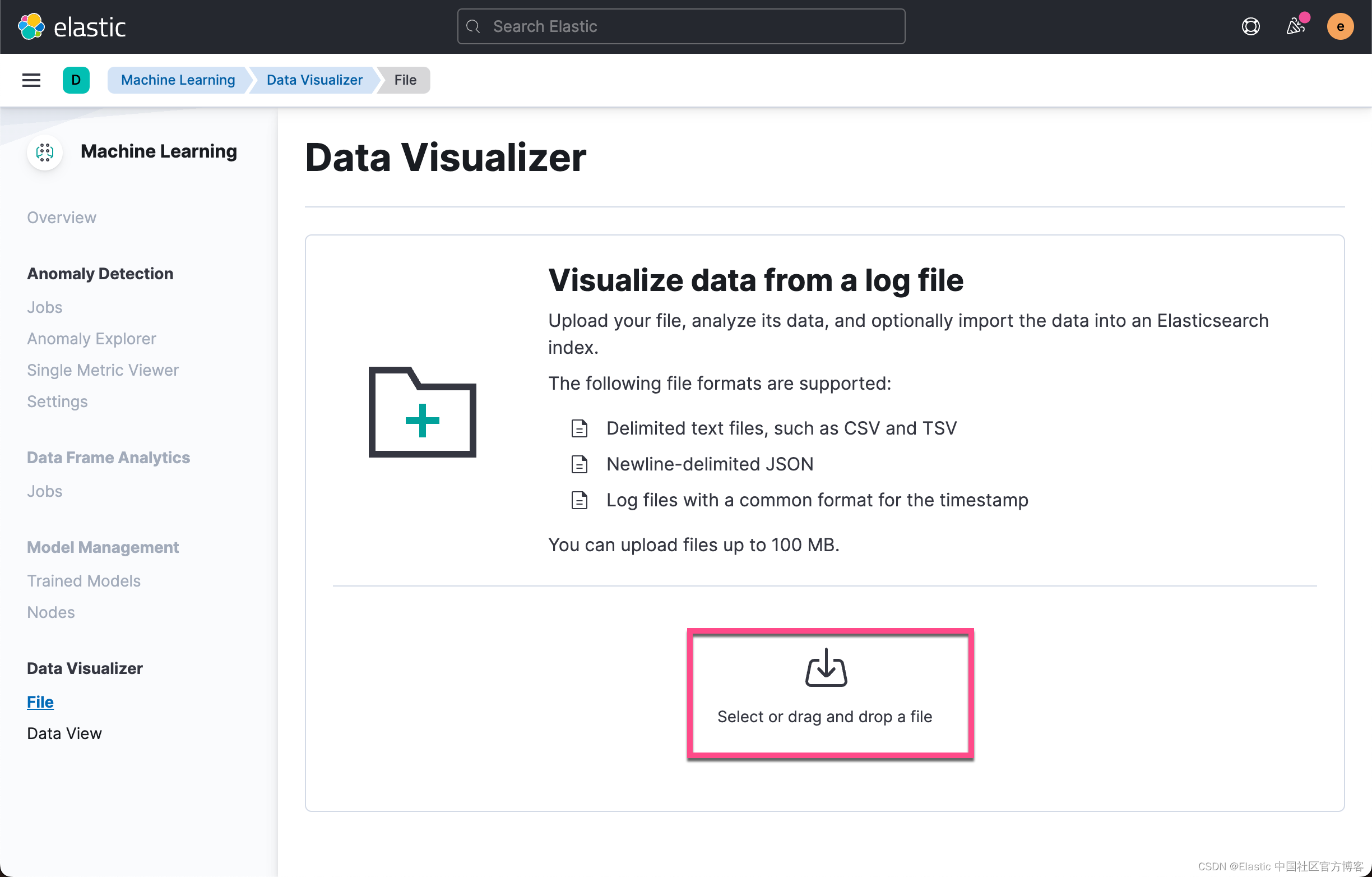
现在,我们可以使用 Kibana 机器学习下的 data visualizer 工具上传数据。 导航到 data visualizer 工具后,单击导入文件并上传你的 disk-usage-ld.json 文件。 结果页面应包含类似于以下屏幕截图的字段,与 API 响应中的字段分析相匹配。


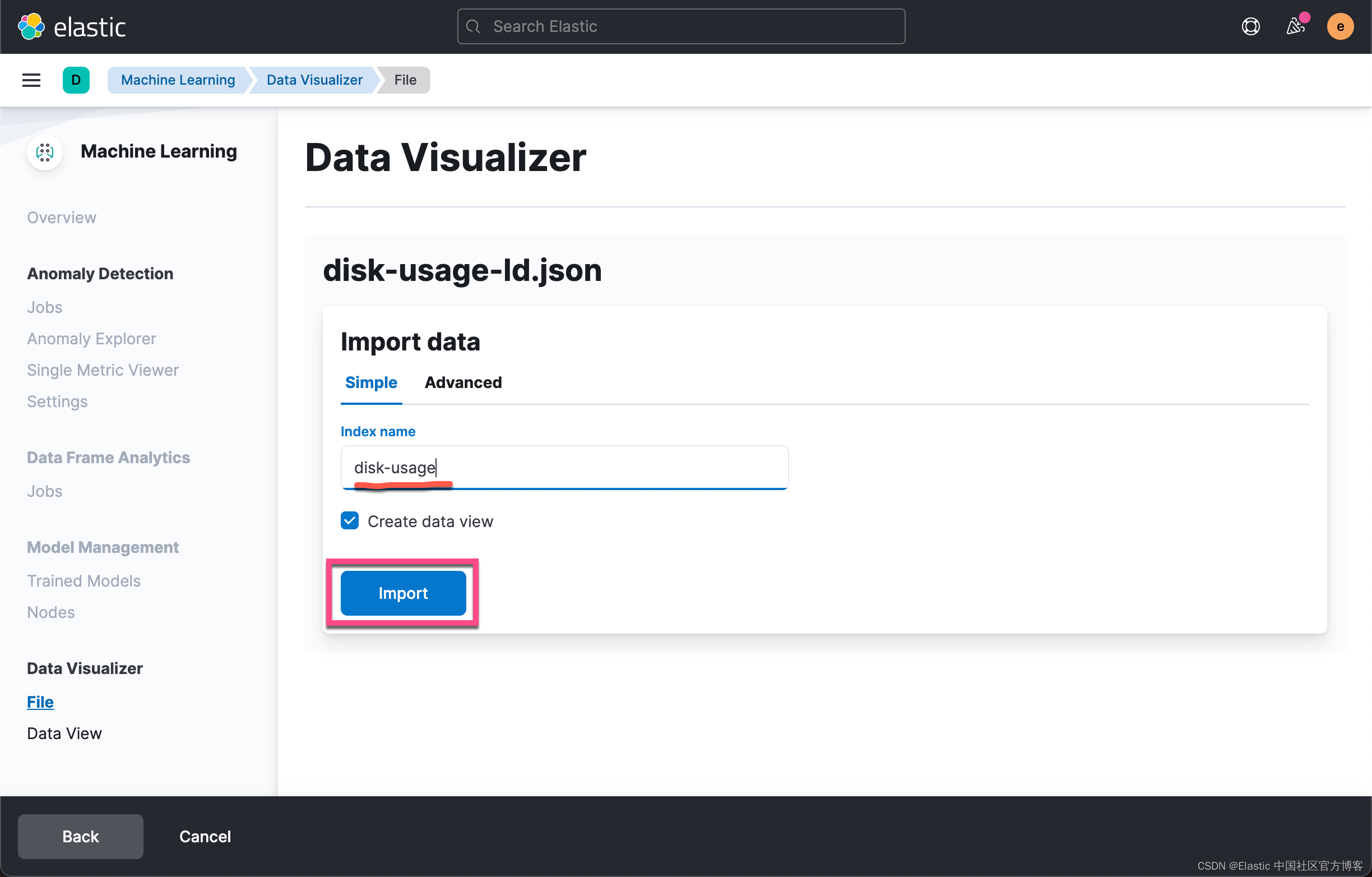


我们发现上面的有些字段的格式并不易于阅读。我们可以通过修改 data view 中的显示格式来提高可读性。
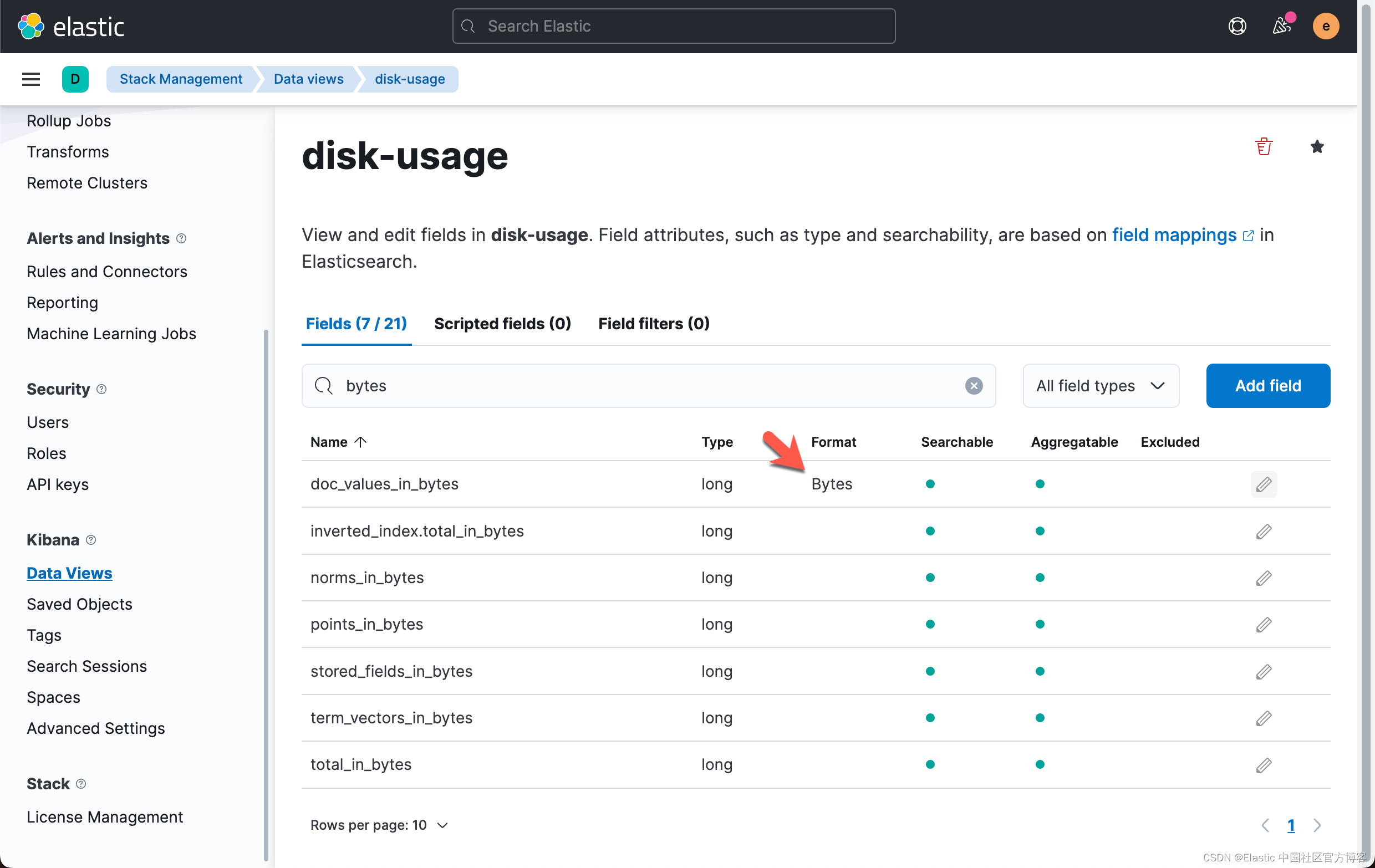
我们将使用 Kibana 中的格式化功能来提高字节字段的可读性。 对于以下每个字段,单击编辑并选择字节作为格式:
- doc_values_in_bytes
- inverted_index.total_in_bytes
- stored_fields_in_bytes
- total_in_bytes
提示:在搜索字段中输入 bytes 以快速查找字段,如下面的屏幕截图所示。



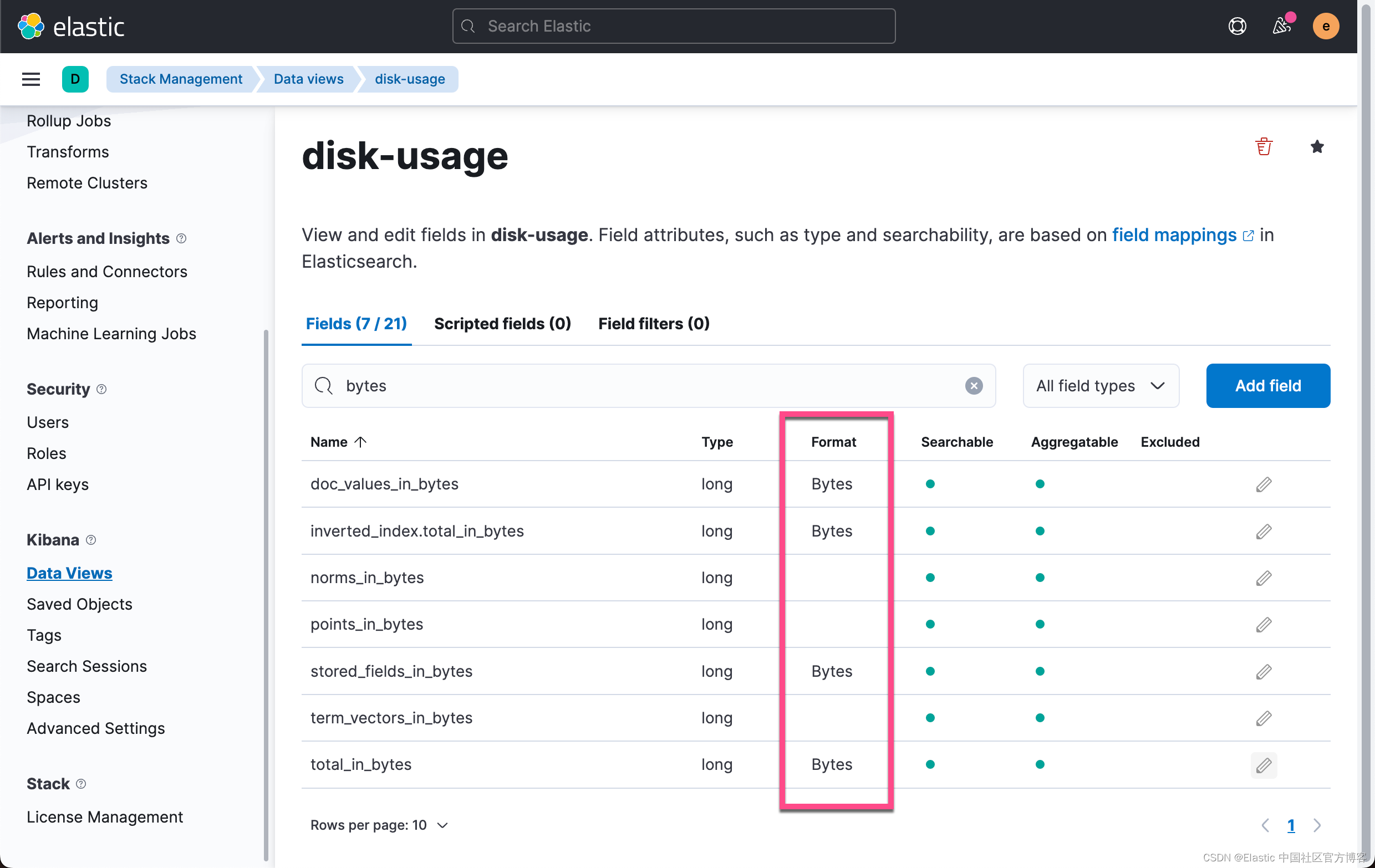
按照同样的套路,我们给上面列出来的其它几个字段做同样的配置:
现在我们准备好可视化我们的现场数据。 导航到发现并选择磁盘使用索引模式。 添加以下列:
- field
- stored_fields_in_bytes
- inverted_index.total_in_bytes
- doc_values_in_bytes
- total_in_bytes
按降序对 total_in_bytes 进行排序。

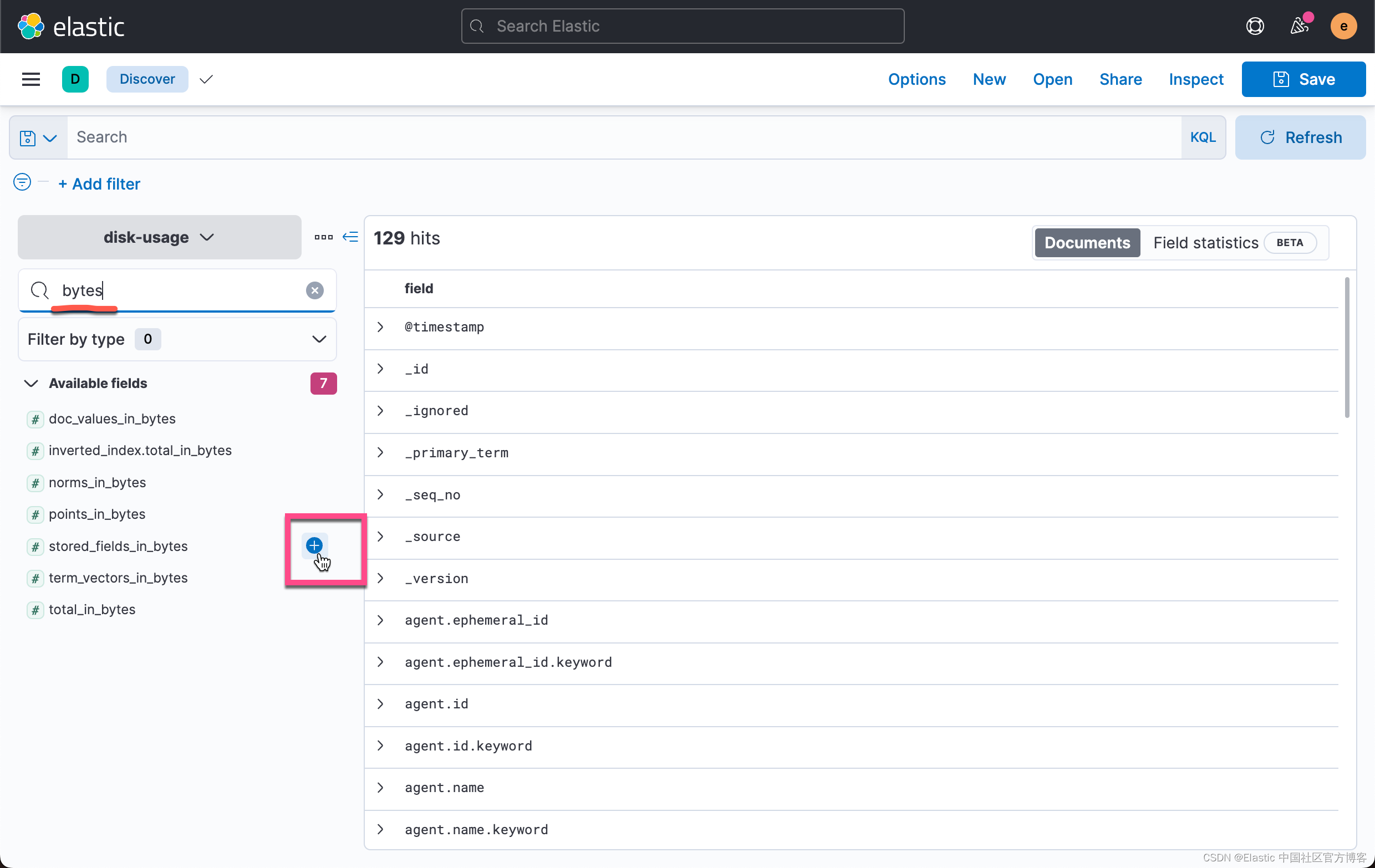
我们按照同样的方法加入下面的其它字段:

如你所见,我最大的字段是 _source。 这是一个存储原始文档的内置字段,也是我们几乎总是想要保留的字段。 接下来的两个字段是 host.mac,event.original.keyword,event.original 及 host.ip。 再往下看,我们还可以看到 ** 带有 .keyword ** 后缀的相同字段。 根据 Elasticsearch 的动态映射默认设置,这些字段已设置为带有 keyword 多字段的文本。 我还注意到文本字段的存储由用于搜索的倒排索引占用,而 keyword 字段的存储由用于聚合和排序的 doc_values 主导。
将文本和关键字大小加在一起,总大小为:
- host.mac + host.mac.keyword = 116.7M + 19M = 135.7M
- host.ip + host.ip.keyword = 30.8M + 6.3M = 37.1M
与最佳实践比较
让我们导航到 Dev Tools 并查看原始 filebeat 索引。 该索引具有开箱即用的 Elastic Common Schema 映射。
我使用以下方法从原始索引中检索磁盘使用信息:
POST .ds-filebeat-8.1.0-2022.03.22-000001/_disk_usage?run_expensive_tasks=true从响应中,我读到了 host.ip 和 host.mac 字段的以下内容:
"host.ip" : {
"total" : "17.6mb",
"total_in_bytes" : 18558341,
"inverted_index" : {
"total" : "0b",
"total_in_bytes" : 0
},
"stored_fields" : "0b",
"stored_fields_in_bytes" : 0,
"doc_values" : "5.6mb",
"doc_values_in_bytes" : 5911203,
"points" : "12mb",
"points_in_bytes" : 12647138,
"norms" : "0b",
"norms_in_bytes" : 0,
"term_vectors" : "0b",
"term_vectors_in_bytes" : 0
},
"host.mac" : {
"total" : "18.9mb",
"total_in_bytes" : 19903862,
"inverted_index" : {
"total" : "1.1mb",
"total_in_bytes" : 1187304
},
"stored_fields" : "0b",
"stored_fields_in_bytes" : 0,
"doc_values" : "17.8mb",
"doc_values_in_bytes" : 18716558,
"points" : "0b",
"points_in_bytes" : 0,
"norms" : "0b",
"norms_in_bytes" : 0,
"term_vectors" : "0b",
"term_vectors_in_bytes" : 0
},正如我们所见,存储使用量降低了 2-5 倍。 要查看映射,我们可以使用以下方法检索它:
GET .ds-filebeat-8.1.0-2022.03.22-000001/_mapping/field/host.ip,host.mac{
".ds-filebeat-8.1.0-2022.03.22-000001" : {
"mappings" : {
"host.ip" : {
"full_name" : "host.ip",
"mapping" : {
"ip" : {
"type" : "ip"
}
}
},
"host.mac" : {
"full_name" : "host.mac",
"mapping" : {
"mac" : {
"type" : "keyword",
"ignore_above" : 1024
}
}
}
}
}
}我可以看到 host.ip 被映射为 ip 而 host.mac 被映射为 keyword。 在大多数情况下,存储在这些字段中的数据类型将用于精确过滤、聚合和排序,这意味着将它们映射为 text 字段不会为分析提供进一步的价值,并且会占用集群中的额外存储空间。
结论和下一步
在这篇博文中,我们了解了如何使用 disk usage API 来了解哪些字段在存储利用率方面最昂贵。 我们使用 jq 格式化 API 响应并使用数据可视化器将其导入回 Elastic,以便我们可以在 Discover 中分析数据。 我们还看到了如何拥有适当的映射可以显着减少存储空间。 那么我们如何优化索引中的存储使用呢?
使用 Elastic integrations
通过使用 Elastic integrations(通过 Beats 或 Elastic Agent),将在摄取数据时自动为你创建字段映射。 请注意,如果你不直接向 Elasticsearch 发送数据,例如通过 Logstash 发送 Filebeat 数据,你可能需要手动加载索引模板。
配置映射
如果你使用自定义数据,你通常需要手动配置映射。 为确保应用你的映射,请在具有适当 index patterns/data views 的索引模板中定义它。
快速映射单个字段变得乏味。 对于大多数机器生成的数据,我们通常希望将大多数字符串映射到关键字类型,因此包括一个动态模板作为下面的示例将节省大量时间。 不要忘记为 ips 和用于自由文本搜索的文本添加特定映射,例如标准字段 “message”。
"mappings": {
"dynamic_templates": [
{
"strings_as_keyword" : {
"match_mapping_type" : "string",
"mapping" : {
"ignore_above" : 1024,
"type" : "keyword"
}
}
}
]
}在为你的字段命名和分配类型时,我们建议你参考 Elastic Common Schema。 它将帮助你构建一致的数据模型,并允许你在 Kibana 的应用程序中查看你的自定义数据。
实施存储层
数据层是优化存储空间的一个略微切线但重要的工具。 通过使用数据层,你可以在数据老化时将数据移动到更便宜的硬件上。 我们的冻结层甚至允许你将数据存储在 blob 存储中,这大大降低了成本,并且专为很少访问或可以接受较慢查询响应的数据而设计。 管理数据层的最简单方法是使用 Elastic Cloud,查看我们管理数据的最佳实践以帮助你入门。


















 1923
1923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









