






作者:来自 Elastic Jeffrey Rengifo
学习如何使用 LangGraph.js 和 Elasticsearch 构建一个由 AI 驱动的金融搜索工作流,把自然语言查询转换为用于投资和市场分析的动态条件过滤器
Elasticsearch 具有与业内领先的 Gen AI 工具和提供商的原生集成。查看我们的网络研讨会,了解如何超越 RAG 基础,或使用 Elastic 向量数据库构建可用于生产的应用。
要为你的用例构建最佳搜索解决方案,请开始免费云试用,或在本地机器上尝试 Elastic。
构建 AI 搜索应用通常需要协调多个任务、数据检索和数据提取,使其成为一个无缝的工作流。LangGraph 通过让开发者使用节点结构来编排 AI agent,从而简化了这个过程。在本文中,我们将使用 LangGraph.js 构建一个金融解决方案
什么是 LangGraph
LangGraph 是一个用于构建 AI agent 并将它们编排进工作流以创建 AI 辅助应用的框架。LangGraph 具有节点架构,我们可以声明代表任务的函数,并将它们指定为工作流的节点。多个节点相互交互的结果就是一个图。LangGraph 属于更广泛的 LangChain 生态系统,它为构建模块化和可组合的 AI 系统提供工具。
为了更好地理解 LangGraph 为什么有用,我们来用它解决一个问题场景。
解决方案概述
在一家风险投资公司中,投资人可以访问一个包含许多过滤选项的大型数据库,但当需要组合多个条件时,会变得困难且缓慢。这可能导致一些相关的初创公司无法被发现,从而失去投资机会。最终会花费许多小时来识别最佳候选者,甚至错过机会。
使用 LangGraph 和 Elasticsearch,我们可以通过自然语言执行过滤搜索,用户无需手动构建包含几十个过滤条件的复杂请求。为了让工作流更灵活,它会根据用户输入在两种查询类型之间自动决定:
- 投资导向查询:这些查询针对初创公司的财务和融资方面,例如融资轮次、估值或收入。示例:“查找 A 轮或 B 轮融资在 8M—25M 美元之间、月收入超过 500K 美元的初创公司。”
- 市场导向查询:这些查询关注行业领域、地理市场或商业模式,有助于识别特定行业或地区的机会。示例:“查找位于旧金山、纽约或波士顿的金融科技和医疗保健初创公司。”
为了保持查询的稳健性,我们将让 LLM 构建搜索模板,而不是完整的 DSL 查询。这样,你总能得到你想要的查询,LLM 只需填补空白,而不需要每次都承担构建完整查询的责任。
开始所需
- Elasticsearch API Key
- OpenAPI API Key
- Node 18 或更新版本
逐步说明
在本节中,先来看一下应用将如何呈现。为此,我们将使用 TypeScript ,一种 JavaScript 的 超集,通过添加静态类型使代码更可靠、更易维护,并且通过及早捕获错误提高安全性,同时仍与现有 JavaScript 完全兼容。
节点流程如下:
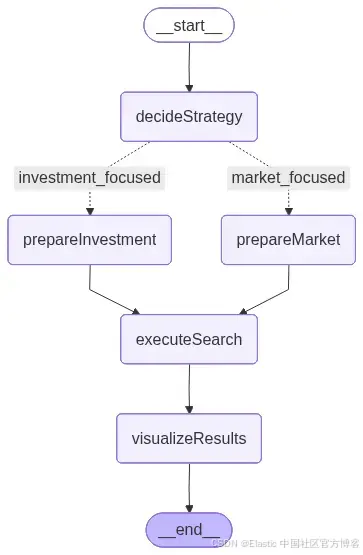
上面的图片由 LangGraph 生成,表示定义节点执行顺序和条件逻辑的工作流:
- decideStrategy:使用 LLM 分析用户查询,并在两种专门的搜索策略(投资导向或市场导向)之间做出决定。
- prepareInvestmentSearch:从查询中提取过滤值,并构建一个预定义模板,重点关注财务和融资相关参数。
- prepareMarketSearch:同样提取过滤值,但会动态构建参数,重点关注市场、行业和地理背景。
- executeSearch:使用搜索模板将构建好的查询发送到 Elasticsearch,并检索匹配的初创公司文档。
- visualizeResults:将最终结果格式化为清晰可读的摘要,显示关键的初创公司属性,例如融资、行业和收入。
这个流程包含条件分支,起到 “if” 语句的作用,根据用户输入决定使用投资搜索路径还是市场搜索路径。这个由 LLM 驱动的决策逻辑使工作流具有自适应性和上下文感知能力,我们将在接下来的部分更详细地探讨这一机制。
LangGraph 状态
在逐个查看节点之前,我们需要了解节点之间如何通信和共享数据。为此,LangGraph 允许我们定义工作流状态。它定义了在节点之间传递的共享状态。
状态充当一个共享容器,在整个工作流中存储中间数据:它从用户的自然语言查询开始,然后保存所选的搜索策略、为 Elasticsearch 准备的参数、检索到的搜索结果,最后是格式化后的输出。
这种结构让每个节点都可以读取和更新状态,确保从用户输入到最终可视化的整个信息流程保持一致。
const VCState = Annotation.Root({
input: Annotation<string>(), // User's natural language query
searchStrategy: Annotation<string>(), // Search strategy chosen by LLM
searchParams: Annotation<any>(), // Prepared search parameters
results: Annotation<any[]>(), // Search results
final: Annotation<string>(), // Final formatted response
});设置应用
本节中的所有代码都可以在 elasticsearch-labs 仓库中找到。
在将要放置应用的文件夹中打开终端,并使用以下命令初始化一个 Node . js 应用:
npm init -y现在我们可以安装这个项目所需的依赖项:
npm install @elastic/elasticsearch @langchain/langgraph @langchain/openai @langchain/core dotenv zod && npm install --save-dev @types/node tsx typescript- @elastic/elasticsearch:帮助我们处理 Elasticsearch 请求,例如数据写入和检索。
- @langchain/langgraph:JS 依赖项,提供所有 LangGraph 工具。
- @langchain/openai:用于 LangChain 的 OpenAI LLM 客户端。
- @langchain/core:提供 LangChain 应用的基础构建模块,包括提示模板。
- dotenv:在 JavaScript 中使用环境变量所需的依赖项。
- zod:用于为数据定义类型的依赖项。
@types / node、tsx、typescript 允许我们编写和运行 TypeScript 代码。
现在创建以下文件:
- elasticsearchSetup.ts:将创建索引映射,从 JSON 文件加载数据集,并将数据写入 Elasticsearch。
- main.ts:将包含 LangGraph 应用。
- .env:用于存储环境变量的文件
在 .env 文件中,添加以下环境变量:
ELASTICSEARCH_ENDPOINT="your-endpoint-here"
ELASTICSEARCH_API_KEY="your-key-here"
OPENAI_API_KEY="your-key-here"OpenAPI APIKey 不会在代码中被直接使用;它会被 @langchain / openai 这个库在内部使用。
所有与映射创建、搜索模板创建和数据集写入相关的逻辑都可以在 elasticsearchSetup.ts 文件中找到。接下来的步骤中,我们将专注于 main.ts 文件。另外,你也可以查看数据集,以更好地了解 dataset.json 中的数据结构。
LangGraph 应用
在 main.ts 文件中,让我们导入一些必要的依赖项来构建 LangGraph 应用。在这个文件中,你还需要包含节点函数和状态声明。图的声明将在接下来的步骤中通过一个 main 方法完成。elasticsearchSetup . ts 文件将包含我们在后续步骤的节点中要使用的 Elasticsearch 辅助函数。
import { writeFileSync } from "node:fs";
import { StateGraph, Annotation, START, END } from "@langchain/langgraph";
import { ChatOpenAI } from "@langchain/openai";
import { z } from "zod";
import {
esClient,
ingestDocuments,
createSearchTemplates,
INDEX_NAME,
INVESTMENT_FOCUSED_TEMPLATE,
MARKET_FOCUSED_TEMPLATE,
createIndex,
} from "./elasticsearchSetup.js";
const llm = new ChatOpenAI({ model: "gpt-4o-mini" });如前所述,LLM 客户端将根据用户的问题生成 Elasticsearch 搜索模板参数。
async function saveGraphImage(app: any): Promise<void> {
try {
const drawableGraph = app.getGraph();
const image = await drawableGraph.drawMermaidPng();
const arrayBuffer = await image.arrayBuffer();
const filePath = "./workflow_graph.png";
writeFileSync(filePath, new Uint8Array(arrayBuffer));
console.log(`📊 Workflow graph saved as: ${filePath}`);
} catch (error: any) {
console.log("⚠️ Could not save graph image:", error.message);
}
}上面的方法会生成 png 格式的图,并在幕后使用 Mermaid . INK API。这个功能很有用,如果你想通过带样式的可视化来查看应用节点是如何相互交互的。
LangGraph 节点
现在来看每个节点的详细内容:
decideSearchStrategy 节点
decideSearchStrategy 节点会分析用户输入,并决定执行投资导向搜索还是市场导向搜索。它使用带有结构化输出模式(由 Zod 定义)的 LLM 来对查询类型进行分类。在做出决策之前,它会通过聚合从索引中获取可用过滤器,确保模型拥有关于行业、地点和融资数据的最新上下文。
为了提取过滤器的可能取值并将它们发送给 LLM,让我们使用一个聚合查询直接从 Elasticsearch 索引中检索它们。这个逻辑被放在一个名为 getAvailableFilters 的方法中:
async function getAvailableFilters() {
try {
const response = await esClient.search({
index: INDEX_NAME,
size: 0,
aggs: {
industries: {
terms: { field: "industry", size: 100 },
},
locations: {
terms: { field: "location", size: 100 },
},
funding_stages: {
terms: { field: "funding_stage", size: 20 },
},
business_models: {
terms: { field: "business_model", size: 10 },
},
lead_investors: {
terms: { field: "lead_investor", size: 100 },
},
funding_amount_stats: {
stats: { field: "funding_amount" },
},
},
});
return response.aggregations;
} catch (error) {
console.error("❌ Error getting available filters:", error);
return {};
}
}通过上面的聚合查询,我们得到了以下结果:
{
"industries": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "logistics",
"doc_count": 5
},
...
]
},
"locations": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "San Francisco, CA",
"doc_count": 4
},
{
"key": "New York, NY",
"doc_count": 3
},
...
]
},
"funding_stages": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "Series A",
"doc_count": 8
},
...
]
},
"business_models": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "B2B",
"doc_count": 13
},
...
]
},
"lead_investors": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "Battery Ventures",
"doc_count": 1
},
{
"key": "Benchmark Capital",
"doc_count": 1
},
...
]
},
"funding_amount_stats": {
"count": 20,
"min": 4500000,
"max": 35000000,
"avg": 14075000,
"sum": 281500000
}
}在这里查看所有结果。
对于这两种策略,我们都会使用混合搜索来同时检测问题中的结构化部分(过滤器)以及更主观的部分(语义)。下面是使用搜索模板的两个查询示例:
await esClient.putScript({
id: INVESTMENT_FOCUSED_TEMPLATE,
script: {
lang: "mustache",
source: `{
"size": 5,
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"semantic": {
"field": "semantic_field",
"query": "{{query_text}}"
}
}
}
},
{
"standard": {
"query": {
"bool": {
"filter": [
{"terms": {"funding_stage": {{#join}}{{#toJson}}funding_stage{{/toJson}}{{/join}}}},
{"range": {"funding_amount": {"gte": {{funding_amount_gte}}{{#funding_amount_lte}},"lte": {{funding_amount_lte}}{{/funding_amount_lte}}}}},
{"terms": {"lead_investor": {{#join}}{{#toJson}}lead_investor{{/toJson}}{{/join}}}},
{"range": {"monthly_revenue": {"gte": {{monthly_revenue_gte}}{{#monthly_revenue_lte}},"lte": {{monthly_revenue_lte}}{{/monthly_revenue_lte}}}}}
]
}
}
}
}
],
"rank_window_size": 100,
"rank_constant": 20
}
}
}`,
},
});在 elasticsearchSetup.ts 文件中查看这些查询的详细内容。在下面的节点中,将决定使用这两个查询中的哪一个:
// Node 1: Decide search strategy using LLM
async function decideSearchStrategy(state: typeof VCState.State) {
// Zod schema for specialized search strategy decision
const SearchDecisionSchema = z.object({
search_type: z
.enum(["investment_focused", "market_focused"])
.describe("Type of specialized search strategy to use"),
reasoning: z
.string()
.describe("Brief explanation of why this search strategy was chosen"),
});
const decisionLLM = llm.withStructuredOutput(SearchDecisionSchema);
// Get dynamic filters from Elasticsearch
const availableFilters = await getAvailableFilters();
const prompt = `Query: "${state.input}"
Available filters: ${JSON.stringify(availableFilters, null, 2)}
Choose between two specialized search strategies:
- investment_focused: For queries about funding stages, funding amounts, monthly revenue, lead investors, financial performance
- market_focused: For queries about industries, locations, business models, market segments, geographic markets
Analyze the query intent and choose the most appropriate strategy.
`;
try {
const result = await decisionLLM.invoke(prompt);
console.log(
`🤔 Search strategy: ${result.search_type} - ${result.reasoning}`
);
return {
searchStrategy: result.search_type,
};
} catch (error: any) {
console.error("❌ Error in decideSearchStrategy:", error.message);
return {
searchStrategy: "investment_focused",
};
}
}prepareInvestmentSearch 和 prepareMarketSearch 节点
这两个节点都使用一个共享的辅助函数 extractFilterValues,该函数利用 LLM 来识别用户输入中提到的相关过滤器,例如行业、地点、融资阶段、商业模式等。我们正在使用这个模式来构建搜索模板。
// Extract all possible filter values from user input
async function extractFilterValues(input: string) {
const FilterValuesSchema = z.object({
// Investment-focused filters
funding_stage: z
.array(z.string())
.default([])
.describe("Funding stage values mentioned in query"),
funding_amount_gte: z
.number()
.default(0)
.describe("Minimum funding amount in USD"),
funding_amount_lte: z
.number()
.default(100000000)
.describe("Maximum funding amount in USD"),
lead_investor: z
.array(z.string())
.default([])
.describe("Lead investor values mentioned in query"),
monthly_revenue_gte: z
.number()
.default(0)
.describe("Minimum monthly revenue in USD"),
monthly_revenue_lte: z
.number()
.default(10000000)
.describe("Maximum monthly revenue in USD"),
industry: z
.array(z.string())
.default([])
.describe("Industry values mentioned in query"),
location: z
.array(z.string())
.default([])
.describe("Location values mentioned in query"),
business_model: z
.array(z.string())
.default([])
.describe("Business model values mentioned in query"),
});
const extractorLLM = llm.withStructuredOutput(FilterValuesSchema);
const availableFilters = await getAvailableFilters();
const extractPrompt = `Extract ALL relevant filter values from: "${input}"
Available options: ${JSON.stringify(availableFilters, null, 2)}
Extract only values explicitly mentioned in the query. Leave fields empty if not mentioned.`;
return await extractorLLM.invoke(extractPrompt);
}根据检测到的意图,工作流会选择两条路径之一:
prepareInvestmentSearch:构建以财务为导向的搜索参数,包括融资阶段、融资金额、投资者和收入信息。完整的查询模板可以在 elasticsearchSetup.ts 文件中找到:
// Node 2A: Prepare Investment-Focused Search Parameters
async function prepareInvestmentSearch(state: typeof VCState.State) {
console.log(
"💰 Preparing INVESTMENT-FOCUSED search parameters with financial emphasis..."
);
try {
// Extract all filter values from input
const values = await extractFilterValues(state.input);
let searchParams: any = {
template_id: INVESTMENT_FOCUSED_TEMPLATE,
query_text: state.input,
...values,
};
return { searchParams };
} catch (error) {
console.error("❌ Error preparing investment-focused params:", error);
return {
searchParams: {},
};
}
}prepareMarketSearch:创建以市场为导向的参数,重点关注行业、地理位置和商业模式。完整查询可在 elasticsearchSetup.ts 文件中查看:
// Node 2B: Prepare Market-Focused Search Parameters
async function prepareMarketSearch(state: typeof VCState.State) {
console.log(
"🔍 Preparing MARKET-FOCUSED search parameters with market emphasis..."
);
try {
// Extract all filter values from input
const values = await extractFilterValues(state.input);
let searchParams: any = {
template_id: MARKET_FOCUSED_TEMPLATE,
query_text: state.input,
...values,
};
return { searchParams };
} catch (error) {
console.error("❌ Error preparing market-focused params:", error);
return {};
}
}executeSearch 节点
这个节点从状态中获取生成的搜索参数,先使用 _render API 将查询可视化以便调试,然后再发送请求从 Elasticsearch 检索结果。
// Node 3: Execute Search
async function executeSearch(state: typeof VCState.State) {
const { searchParams } = state;
try {
// getting formed query from template for debugging
const renderedTemplate = await esClient.renderSearchTemplate({
id: searchParams.template_id,
params: searchParams,
});
console.log(
"📋 Complete query:",
JSON.stringify(renderedTemplate.template_output, null, 2)
);
const results = await esClient.searchTemplate({
index: INDEX_NAME,
id: searchParams.template_id,
params: searchParams,
});
return {
results: results.hits.hits.map((hit: any) => hit._source),
};
} catch (error: any) {
console.error(`❌ ${state.searchParams.search_type} search error:`, error);
return { results: [] };
}
}visualizeResults 节点
最后,这个节点会展示 Elasticsearch 的结果。
// Node 4: Visualize results
async function visualizeResults(state: typeof VCState.State) {
const results = state.results || [];
let formattedResults = `🎯 Found ${results.length} startups matching your criteria:\n\n`;
results.forEach((startup: any, index: number) => {
formattedResults += `${index + 1}. **${startup.company_name}**\n`;
formattedResults += ` 📍 ${startup.location} | 🏢 ${startup.industry} | 💼 ${startup.business_model}\n`;
formattedResults += ` 💰 ${startup.funding_stage} - $${(
startup.funding_amount / 1000000
).toFixed(1)}M\n`;
formattedResults += ` 👥 ${startup.employee_count} employees | 📈 $${(
startup.monthly_revenue / 1000
).toFixed(0)}K MRR\n`;
formattedResults += ` 🏦 Lead: ${startup.lead_investor}\n`;
formattedResults += ` 📝 ${startup.description}\n\n`;
});
return {
final: formattedResults,
};
}从程序上看,整个图如下所示:
const workflow = new StateGraph(VCState)
// Register nodes - these are the processing functions
.addNode("decideStrategy", decideSearchStrategy)
.addNode("prepareInvestment", prepareInvestmentSearch)
.addNode("prepareMarket", prepareMarketSearch)
.addNode("executeSearch", executeSearch)
.addNode("visualizeResults", visualizeResults)
// Define execution flow with conditional branching
.addEdge(START, "decideStrategy") // Start with strategy decision
.addConditionalEdges(
"decideStrategy",
(state: typeof VCState.State) => state.searchStrategy, // Conditional function
{
investment_focused: "prepareInvestment", // If investment focused -> RRF template preparation
market_focused: "prepareMarket", // If market focused -> dynamic query preparation
}
)
.addEdge("prepareInvestment", "executeSearch") // Investment prep -> execute
.addEdge("prepareMarket", "executeSearch") // Market prep -> execute
.addEdge("executeSearch", "visualizeResults") // Execute -> visualize
.addEdge("visualizeResults", END); // End workflow如你所见,我们有一个条件边,应用会决定接下来运行哪一个 “路径” 或节点。这个功能在工作流需要分支逻辑时非常有用,例如在多个工具之间进行选择,或加入一个 human-in-the-loop 步骤。
在理解了 LangGraph 的核心特性之后,我们可以设置运行代码的应用:
把所有内容放在一个 main 方法中,在这里我们用变量 workflow 声明包含所有元素的图:
async function main() {
await createIndex();
await createSearchTemplates();
await ingestDocuments();
// Create the workflow graph with shared state
const workflow = new StateGraph(VCState)
// Register nodes - these are the processing functions
.addNode("decideStrategy", decideSearchStrategy)
.addNode("prepareInvestment", prepareInvestmentSearch)
.addNode("prepareMarket", prepareMarketSearch)
.addNode("executeSearch", executeSearch)
.addNode("visualizeResults", visualizeResults)
// Define execution flow with conditional branching
.addEdge(START, "decideStrategy") // Start with strategy decision
.addConditionalEdges(
"decideStrategy",
(state: typeof VCState.State) => state.searchStrategy, // Conditional function
{
investment_focused: "prepareInvestment", // If investment focused -> RRF template preparation
market_focused: "prepareMarket", // If market focused -> dynamic query preparation
}
)
.addEdge("prepareInvestment", "executeSearch") // Investment prep -> execute
.addEdge("prepareMarket", "executeSearch") // Market prep -> execute
.addEdge("executeSearch", "visualizeResults") // Execute -> visualize
.addEdge("visualizeResults", END); // End workflow
const app = workflow.compile();
await saveGraphImage(app);
const query =
"Find startups with Series A or Series B funding between $8M-$25M and monthly revenue above $500K";
const marketResult = await app.invoke({ input: query });
console.log(marketResult.final);
}query 变量模拟用户在一个假设搜索栏中输入的内容:

从自然语言短语 “Find startups with Series A or Series B funding between $8M-$25M and monthly revenue above $500K” 中,将提取所有过滤器。
最后,调用 main 方法:
main().catch(console.error);结果:
🔍 Checking if index exists...
🏗️ Creating index...
✅ Index created successfully!
Ingesting documents...
✅ Documents ingested successfully!
✅ Investment-focused template created successfully!
✅ Market-focused template created successfully!
📊 Workflow graph saved as: ./workflow_graph.png
🔍 Query: "Find startups with Series A or Series B funding between $8M-$25M and monthly revenue above $500K"
🤔 Search strategy: investment_focused - The query specifically seeks profitable fintech startups with defined funding amounts and high monthly revenue, which aligns closely with financial performance metrics and investment-related criteria.
💰 Preparing INVESTMENT-FOCUSED search parameters with financial emphasis...
📋 Complete query: {
"size": 5,
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"semantic": {
"field": "semantic_field",
"query": "Find startups with Series A or Series B funding between $8M-$25M and monthly revenue above $500K"
}
}
}
},
{
"standard": {
"query": {
"bool": {
"filter": [
{
"terms": {
"funding_stage": [
"Series A",
"Series B"
]
}
},
{
"range": {
"funding_amount": {
"gte": 8000000,
"lte": 25000000
}
}
},
{
"terms": {
"lead_investor": []
}
},
{
"range": {
"monthly_revenue": {
"gte": 500000,
"lte": 0
}
}
}
]
}
}
}
}
],
"rank_window_size": 100,
"rank_constant": 20
}
}
}
🎯 Found 5 startups matching your criteria:
1. **TechFlow**
📍 San Francisco, CA | 🏢 logistics | 💼 B2B
💰 Series A - $8.0M
👥 45 employees | 📈 $500K MRR
🏦 Lead: Sequoia Capital
📝 TechFlow optimizes supply chain operations using AI-powered route optimization and real-time tracking. Founded in 2023, shows remarkable growth with $500K monthly revenue.
2. **DataViz**
📍 New York, NY | 🏢 enterprise software | 💼 B2B
💰 Series A - $10.0M
👥 42 employees | 📈 $450K MRR
🏦 Lead: Battery Ventures
📝 DataViz creates intuitive data visualization tools for enterprise customers. No-code platform allows business users to create dashboards without technical expertise.
3. **FinanceAI**
📍 San Francisco, CA | 🏢 fintech | 💼 B2C
💰 Series C - $25.0M
👥 120 employees | 📈 $1200K MRR
🏦 Lead: Tiger Global Management
📝 FinanceAI provides AI-powered investment advisory services to retail investors. Uses machine learning to analyze market trends with over 100,000 active users.
4. **UrbanMobility**
📍 New York, NY | 🏢 logistics | 💼 B2B2C
💰 Series B - $15.0M
👥 78 employees | 📈 $750K MRR
🏦 Lead: Kleiner Perkins
📝 UrbanMobility revolutionizes urban transportation through autonomous delivery drones and smart logistics hubs. Partners with major retailers for same-day delivery across Manhattan and Brooklyn.
5. **HealthTech Solutions**
📍 Boston, MA | 🏢 healthcare | 💼 B2B
💰 Series B - $18.0M
👥 95 employees | 📈 $900K MRR
🏦 Lead: General Catalyst
📝 HealthTech Solutions develops medical devices and software for remote patient monitoring. Comprehensive telehealth platform reducing hospital readmissions by 30%.
✨ Done in 18.80s.对于发送的输入,应用选择了投资导向路径,因此我们可以看到由 LangGraph 工作流生成的 Elasticsearch 查询,它从用户输入中提取了数值和范围。我们还可以看到发送到 Elasticsearch 的应用了提取值的查询,最后是由 visualizeResults 节点格式化后的结果。
现在让我们使用查询 “Find fintech and healthcare startups in San Francisco, New York, or Boston” 来测试市场导向节点:
...
🔍 Query: Find fintech and healthcare startups in San Francisco, New York, or Boston
🤔 Search strategy: market_focused - The query is focused on finding fintech startups in San Francisco that are disrupting traditional banking and payment systems, which pertains to specific industries (fintech) and locations (San Francisco). Thus, a market-focused strategy is more appropriate.
🔍 Preparing MARKET-FOCUSED search parameters with market emphasis...
📋 Complete query: {
"size": 5,
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"semantic": {
"field": "semantic_field",
"query": "Find fintech and healthcare startups in San Francisco, New York, or Boston"
}
}
}
},
{
"standard": {
"query": {
"bool": {
"filter": [
{
"terms": {
"industry": [
"fintech",
"healthcare"
]
}
},
{
"terms": {
"location": [
"San Francisco, CA",
"New York, NY",
"Boston, MA"
]
}
},
{
"terms": {
"business_model": []
}
}
]
}
}
}
}
],
"rank_window_size": 50,
"rank_constant": 10
}
}
}
🎯 Found 5 startups matching your criteria:
1. **FinanceAI**
📍 San Francisco, CA | 🏢 fintech | 💼 B2C
💰 Series C - $25.0M
👥 120 employees | 📈 $1200K MRR
🏦 Lead: Tiger Global Management
📝 FinanceAI provides AI-powered investment advisory services to retail investors. Uses machine learning to analyze market trends with over 100,000 active users.
2. **CryptoWallet**
📍 Miami, FL | 🏢 fintech | 💼 B2C
💰 Series B - $16.0M
👥 73 employees | 📈 $820K MRR
🏦 Lead: Coinbase Ventures
📝 CryptoWallet provides secure digital wallet solutions for cryptocurrency trading and storage. Multi-chain support with enterprise-grade security features.
...
✨ Done in 7.41s.学习心得
在写作过程中,我学到:
- 我们必须把过滤器的确切取值展示给 LLM,否则我们就只能依赖用户输入完全一致的取值。对于低基数来说这种方式没问题,但在高基数场景下,我们需要某种机制来过滤结果
- 使用搜索模板能让结果比让 LLM 直接写 Elasticsearch 查询稳定得多,而且速度更快
- 条件边是构建具有多种变体和分支路径的应用时非常强大的机制
- 结构化输出在用 LLM 生成信息时非常有用,因为它能强制生成可预测、类型安全的响应。这提高了可靠性,并减少了提示被误解的情况
通过混合检索结合语义和结构化搜索,可以得到更好、更相关的结果,兼顾精确性和上下文理解
结论
在这个示例中,我们将 LangGraph.js 与 Elasticsearch 结合,创建了一个能够解释自然语言查询并在财务导向或市场导向搜索策略之间做出决定的动态工作流。这种方式降低了手动构建复杂查询的难度,同时提高了风险投资分析师的灵活性和准确性。
原文:https://www.elastic.co/search-labs/blog/ai-agent-workflow-finance-langgraph-elasticsearch


















 1917
1917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









