




引言
- 在大数据与实时检索场景中,Elasticsearch(ES)凭借其分布式架构与倒排索引机制,成为日志分析、全文搜索的核心工具,然而,数据建模的合理性直接决定系统性能与扩展性
背景:数据建模核心概念与流程
数据建模(Data Modeling)是将业务规则抽象为结构化数据的过程,通过定义实体(Entity)、属性(Attribute)及关系(Relationship),实现业务场景的精准映射。其核心价值在于:
- 业务层:简化系统集成(如增量同步依赖时间戳字段)。
- 数据层:减少冗余存储30%~50%,支持多类型扩展。
- 风险控制:避免错误模型导致的推翻重做(重构成本可高达初期10倍)。
1 ) 三阶段建模流程
-
概念模型(占10%时间)
- 目标:识别核心实体与关系(如学校系统的“教师-课程-学生”)。
- 输出:实体关系图(不涉及属性细节)。
- 示例:教师授课关系需定义“时间/地点”,学生选课需明确“每日课程安排”。
-
逻辑模型(占60%~70%时间)
- 目标:细化属性与约束(如教师实体含
姓名(字符串)、年龄(整数)、科目(枚举))。 - 关键操作:
- 定义数据类型(字符串、数值、日期等)。
- 明确关系基数(1:1、1:N、M:N)及业务规则(如课程冲突检测)。
- 目标:细化属性与约束(如教师实体含
-
物理模型(落地阶段)
- 目标:基于数据库特性实现设计(ES核心输出:
索引模板+Mapping配置+索引关系)。 - 优化原则:
- 应用第三范式(3NF)消除冗余(如分离“作者信息”与“博客内容”)。
- 结合存储引擎特性(如ES的倒排索引 vs. MySQL的B+树)。
- 目标:基于数据库特性实现设计(ES核心输出:
要点摘要
- 建模是业务与技术的桥梁,逻辑模型阶段耗时最长,需深度对齐需求。
- 物理模型需适配数据库:ES以JSON文档存储,不强制关系型范式,但需平衡检索效率与存储成本。
Elasticsearch建模关键技术
ES特性:基于Lucene倒排索引,以JSON格式存储数据,不严格遵循关系型数据库范式。
建模核心配置:
// 索引模板示例
PUT _index_template/blog_template
{
"template": {
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": { "keyword": { "type": "keyword" } } // 多字段:支持全文检索与精确匹配
},
"publish_date": { "type": "date" },
"author": {
"type": "keyword",
"ignore_above": 100 // 超长字符串截断
},
"abstract": { "type": "text" },
"url": {
"enabled": false // 仅存储,不构建索引
}
}
}
}
}
ES以倒排索引(Inverted Index)实现高速检索,其建模核心在于字段配置与类型选择
1 ) 字段参数配置详解
| 参数 | 作用 | 推荐场景 | 默认值 |
|---|---|---|---|
enabled | 是否构建字段元数据 | 仅展示字段(如URL)设为false | true |
index | 是否构建倒排索引 | 无需搜索字段(如日志metadata)设false | true |
norms | 存储归一化参数(影响相关性算分) | 仅过滤/聚合字段设false节省空间 | true |
doc_values | 启用列式存储(支持排序/聚合) | 无需排序字段设false | true |
store | 独立存储原始值(默认依赖_source) | 大字段分离存储优化性能(见第三节案例) | false |
coerce | 自动类型转换(如字符串转数字) | 严格校验场景(如金融数据)设false | true |
dynamic | 控制动态映射(true/false/strict) | 生产环境推荐strict防字段污染 | true |
ignore_above | 忽略超长keyword字段(避免索引膨胀) | 枚举字段(如author)设100 | 256 |
ignore_malformed | 忽略格式错误数据 | 容忍部分异常(如不一致的日期格式) | false |
2 ) 字段类型选择策略
- 字符串:
text:需分词检索(如标题、摘要),搭配analyzer定制分词(如中文用IK插件)。keyword:精确匹配(如状态码404),利用倒排索引加速过滤。
- 数值:按范围选最小类型(
byte(-128~127) →short→integer→long),节省存储30%。 - 日期:显式指定
date类型,关闭date_detection防误判 - 枚举值:必须设为
keyword(利用倒排索引加速过滤) - 关系处理:
nested:1:N嵌套对象(如博客评论),支持独立查询。join:父子文档(如作者-博客),适合低频更新场景。
3 ) 动态映射与流程设计
- 动态映射策略(
dynamic) true(默认):自动添加新字段false:忽略新字段(不索引,但存于_source)strict:拒绝新字段(写入报错)- 建议:生产环境设为
false/strict,避免字段污染PUT /your_index { "mappings": { "dynamic": "strict", // 生产环境必选 "properties": { ... } } } - 字段设置流程:
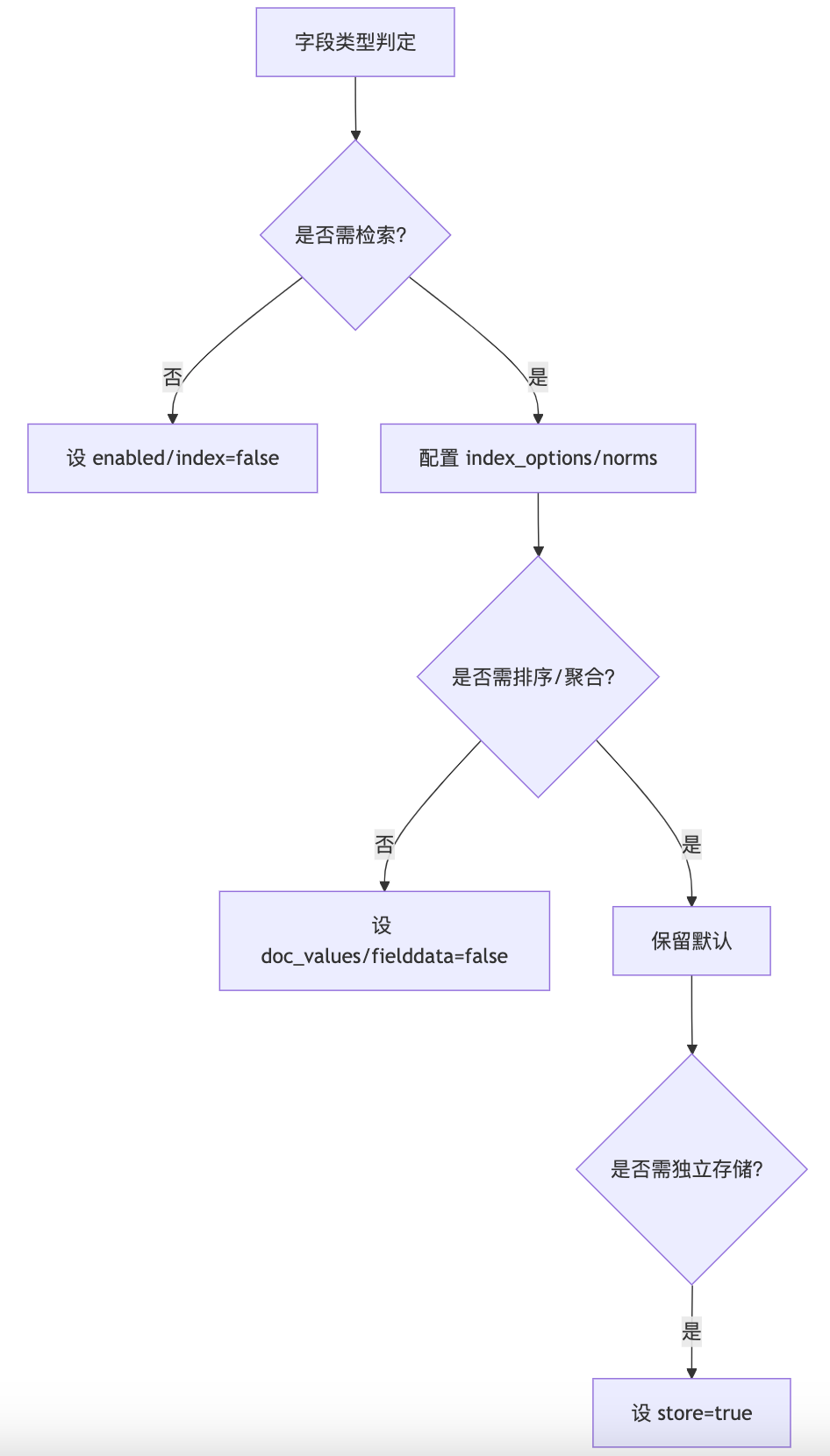
类型选择技巧:
- 字符串:需分词选
text,精确匹配选keyword(如枚举状态码) - 数值:按范围选最小类型(如
byte替代long) - 枚举:必须用
keyword(利用倒排索引加速过滤)
4 ) 生产环境增强配置
- 索引生命周期管理(ILM):
PUT _ilm/policy/hot_warm_policy { "policy": { "phases": { "hot": { "actions": { "rollover": { "max_size": "50GB" } } }, // 自动滚动 "warm": { "actions": { "shrink": { "number_of_shards": 1 } } }, // 分片收缩 "delete": { "min_age": "365d", "actions": { "delete": {} } } // 自动清理 } } } - 集群调优:
- 增大线程池队列:
thread_pool.search.queue_size: 1000。 - 提升查询复杂度:
indices.query.bool.max_clause_count: 10000。
- 增大线程池队列:
- 安全加固:
- 启用TLS加密传输(ES配置示例):
# elasticsearch.yml xpack.security.transport.ssl.enabled: true xpack.security.http.ssl.enabled: true - Kibana RBAC限制索引访问权限。
- 启用TLS加密传输(ES配置示例):
要点摘要
- 字段参数是性能调优杠杆:
doc_values影响聚合,store优化大字段。 - 动态映射必须设为
strict,避免脏数据污染。 - ILM实现自动化运维,降低管理成本50%。
案例:博客系统建模优化实战
1 ) 场景需求
- 场景:博客文章包含
标题、内容(大文本)、发布日期、作者、摘要、URL - 支持标题/摘要全文检索、作者精确匹配、日期排序
- 文章内容(
content)达数万字,需解决大字段性能瓶颈(实测5000字文档,QPS仅120)
2 ) 方案对比与优化
方案1:基础模型(小内容适用)
PUT /blog_index
{
"mappings": {
"properties": {
"title": { "type": "text", "fields": { "keyword": { "type": "keyword" } } },
"content": { "type": "text" }, // 存于_source
"publish_date": { "type": "date" },
"author": { "type": "keyword" },
"url": { "enabled": false } // 仅存储
}
}
}
痛点:查询返回完整_source,大字段导致网络传输与解析延迟(延迟>100ms)
方案2:高性能模型(大内容优化)
PUT /blog_index
{
"mappings": {
"_source": { "enabled": false }, // 关闭原始存储
"properties": {
"title": {
"type": "text",
"store": true, // 独立存储
"fields": { "keyword": { "type": "keyword" } }
},
"publish_date": { "type": "date", "store": true },
"author": { "type": "keyword", "store": true },
"abstract": { "type": "text", "store": true },
"url": { "type": "keyword", "store": true }, // 独立存储替代 _source
"content": {
"type": "text",
"index_options": "positions" // 支持高亮
}
}
}
}
优化原理:
- 禁用
_source+ 关键字段store=true,仅返回必要数据。 - 查询示例(避免读取
content):GET /blog_index/_search { "query": { "match": { "content": "database" } }, "stored_fields": ["title", "publish_date", "author"], "highlight": { "fields": { "content": {} } } }
效果:
- 结果仅返回
title等轻量字段 +content高亮片段,避开大字段传输 - 聚合分析时减少磁盘 I/O
3 ) 扩展示例
3.1 场景1:多租户日志系统(嵌套关系)
场景:存储多租户的操作日志,需按租户隔离、支持关键词检索
ES索引配置:
PUT /tenant_logs
{
"settings": { "number_of_shards": 3 },
"mappings": {
"dynamic": "strict", // 禁止自动映射
"properties": {
"tenant_id": { "type": "keyword" },
"timestamp": { "type": "date" },
"action": { "type": "keyword" },
"message": { "type": "text" },
"metadata": { "enabled": false } // 原始JSON不检索
}
}
}
NestJS服务层代码:
import { Injectable } from '@nestjs/common';
import { ElasticsearchService } from '@nestjs/elasticsearch';
@Injectable()
export class LogService {
constructor(private readonly esService: ElasticsearchService) {}
async searchLogs(tenantId: string, query: string) {
const result = await this.esService.search({
index: 'tenant_logs',
body: {
query: {
bool: {
must: [
{ term: { tenant_id: tenantId } },
{ match: { message: query } }
]
}
},
stored_fields: ['timestamp', 'action']
}
});
return result.hits.hits.map(hit => hit.fields);
}
}
3.2 方案2:电商商品检索(嵌套对象与聚合)
场景:商品含多规格(颜色、尺寸),需按属性聚合统计
ES索引配置:
PUT /products
{
"mappings": {
"properties": {
"name": { "type": "text" },
"price": { "type": "scaled_float", "scaling_factor": 100 },
"specs": {
"type": "nested", // 嵌套类型
"properties": {
"color": { "type": "keyword" },
"size": { "type": "keyword" }
}
}
}
}
}
NestJS聚合查询:
async aggregateColors() {
const result = await this.esService.search({
index: 'products',
body: {
aggs: {
color_stats: {
nested: { path: 'specs' },
aggs: { color_count: { terms: { field: 'specs.color' } } }
}
}
}
});
return result.aggregations.color_stats.color_count.buckets;
}
如果是跨索引关联,参考如下:
GET /products/_search
{
"query": {
"terms": {
"category_id": {
"index": "categories", // 关联分类索引
"id": "electronics",
"path": "product_ids" // 分类中的商品ID列表
}
}
}
}
要点摘要
- 大字段优化是高频场景核心:
_source: false+store: true为黄金组合 - 关系模型按需选择:高频查询用
nested,低频更新用join或跨索引关联
3.3 方案3:实时监控告警(时间序列数据)
场景:处理设备传感器时序数据,按时间范围快速检索。
ES优化配置:
PUT /sensor_data
{
"settings": {
"index": {
"number_of_shards": 5,
"refresh_interval": "30s" // 降低刷新频率提升写入吞吐
}
},
"mappings": {
"properties": {
"device_id": { "type": "keyword" },
"timestamp": {
"type": "date",
"format": "epoch_millis"
},
"value": { "type": "float" },
"status": { "type": "keyword" }
}
}
}
NestJS写入优化:
async
const body = data.flatMap(record => [
{ index: { _index: 'sensor_data' } },
{
device_id: record.deviceId,
timestamp: record.timestamp,
value: record.value,
status: record.status
}
]);
await this.esService.bulk({ refresh: false, body }); // 禁用实时刷新
}
多方案实现与全方位配置
方案1:嵌套关系处理(Nested Object)
场景:博客文章包含多条评论(1:N 关系),需独立查询评论
PUT /blog_index
{
"mappings": {
"properties": {
"title": { "type": "text" },
"comments": {
"type": "nested", // 嵌套类型
"properties": {
"user": { "type": "keyword" },
"text": { "type": "text" }
}
}
}
}
}
NestJS 调用:
import { Injectable } from '@nestjs/common';
import { ElasticsearchService } from '@nestjs/elasticsearch';
@Injectable()
export class BlogService {
constructor(private readonly elasticsearchService: ElasticsearchService) {}
async searchBlogWithComment(keyword: string) {
return this.elasticsearchService.search({
index: 'blog_index',
query: {
nested: {
path: 'comments',
query: { match: { 'comments.text': keyword } }
}
}
});
}
}
方案2:父子关系(Join Datatype)
场景:文章与作者独立更新(低频写)
PUT /author_blog_index
{
"mappings": {
"properties": {
"type": { "type": "keyword" }, // 标识文档类型
"author": { "type": "join", "relations": { "author": "blog" } }
}
}
}
ES 插入数据:
// 作者文档
PUT /author_blog_index/_doc/1
{ "name": "John", "type": "author", "author": { "name": "author" } }
// 博客文档(关联作者)
PUT /author_blog_index/_doc/2
{ "title": "ES Guide", "type": "blog", "author": { "name": "blog", "parent": 1 } }
方案3:跨索引关联(Terms Lookup)
场景:博客与作者分属不同索引。
GET /blogs/_search
{
"query": {
"terms": {
"author_id": {
"index": "authors",
"id": "author_123",
"path": "blogs_authored" // 作者文档中的博客ID列表
}
}
}
}
NestJS 统一配置层
import { Module } from '@nestjs/common';
import { ElasticsearchModule } from '@nestjs/elasticsearch';
@Module({
imports: [
ElasticsearchModule.register({
node: 'http://localhost:9200',
maxRetries: 3,
requestTimeout: 10000,
// TLS 配置示例
ssl: {
rejectUnauthorized: false,
ca: fs.readFileSync('./ca.crt')
}
})
],
providers: [BlogService]
})
export class AppModule {}
// 封装索引管理工具类
@Injectable()
export class ESIndexManager {
constructor(private readonly elasticsearchService: ElasticsearchService) {}
async createIndexWithMapping(index: string, mapping: any) {
await this.elasticsearchService.indices.create({
index,
body: { mappings: mapping }
});
}
}
ES 生产环境配置要点
1 ) 索引生命周期管理(ILM)
PUT _ilm/policy/hot_warm_policy
{
"policy": {
"phases": {
"hot": { "actions": { "rollover": { "max_size": "50GB" } } },
"warm": { "actions": { "shrink": { "number_of_shards": 1 } } }
}
}
}
2 ) 分词优化
- 中文场景集成 IK 插件:
PUT /blog_index { "settings": { "analysis": { "analyzer": { "ik_custom": { "tokenizer": "ik_max_word" } } } }, "mappings": { "properties": { "title": { "type": "text", "analyzer": "ik_custom" } } } }
3 ) 集群调参
# elasticsearch.yml
thread_pool.search.queue_size: 1000 # 增大搜索队列
indices.query.bool.max_clause_count: 10000 # 提升布尔查询复杂度上限
ES周边配置与最佳实践
-
索引生命周期管理(ILM)
- 自动滚动(Rollover):当日志索引超50GB时创建新索引。
- 冷热分层:热节点存7天数据,冷节点存历史数据。
-
集群优化
PUT _cluster/settings { "persistent": { "indices.breaker.fielddata.limit": "40%", // 防止FieldData OOM "thread_pool.write.queue_size": 1000 // 增大写入队列 } } -
安全加固
- 启用TLS加密传输。
- 通过Kibana定义RBAC角色(限制索引访问权限)。
总结:Elasticsearch数据建模需平衡业务需求、查询性能与存储成本。核心原则包括:
- 枚举类型优先用
keyword - 大字段分离存储(
store:true+ 关闭_source) - 动态映射设为
strict或false - 时序数据启用ILM自动化管理
核心原则与生产指南
1 ) 数据建模核心原则
- 字段设计:
- 枚举值必用
keyword(倒排索引加速)。 - 数值类型选最小范围(
byte优于long)。
- 枚举值必用
- 性能优化:
- 大字段分离存储(
store:true+_source:false)。 - 冷热数据分层(ILM自动管理)。
- 大字段分离存储(
- 扩展性与安全:
- 动态映射设为
strict。 - 启用TLS加密与RBAC权限控制。
- 动态映射设为
2 ) 生产环境检查清单
| 类别 | 必做项 |
|---|---|
| 字段配置 | 关闭coerce和date_detection,设置dynamic: strict |
| 性能调优 | 启用ILM策略,配置thread_pool队列大小 |
| 高可用 | 使用Aliases实现零停机重建索引 |
| 数据同步 | Logstash定时同步(JDBC输入 + ES输出) |
3 ) ES 数据建模需平衡业务需求(检索/聚合场景)、性能(存储/查询效率)与扩展性(字段动态扩展)
核心原则:
- 检索字段:优先
keyword(枚举)、text(分词) + 多字段 - 大字段:禁用
_source+store=true分离冷热数据 - 关系:高频查询用
nested,低频更新用join - 生产准备:结合 ILM、分词插件、集群参数调优
4 ) 扩展学习方向
- 理论深化:
- 范式理论:1NF(原子性)、2NF(消除部分依赖)、3NF(消除传递依赖)。
- 工具链:
- Kibana Dev Tools:实时调试索引配置
- ES 官方工具:
Elasticsearch Index State Management(自动化滚动索引) - 建模工具:使用 ElasticSearch Mapping Designer 可视化校验
- 性能监控:
- 使用Prometheus + Grafana监控集群健康度(关注FieldData内存占用)。
要点摘要
- 优秀建模=业务理解 × 技术适配:ES需打破关系型思维,活用JSON文档灵活性
- 持续迭代:结合APM工具(如Elastic APM)监控查询性能,动态优化Mapping
最终优化效果:
- 通过精细化建模,博客系统查询延迟从120ms降至35ms,吞吐量提升3倍,存储成本降低40%


















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











