






 本文深入分析了Java中的Map接口实现,包括HashMap的散列表和红黑树结构,LinkedHashMap的有序性实现,TreeMap的红黑树排序,以及Hashtable的线程安全性。详细探讨了各个类的put, get, remove等关键操作的源码,揭示了它们的内部工作机制。"
103209597,9120155,C/C++实现简单计算器,"['C++编程', '算法实现', '基础编程', '算术运算']
本文深入分析了Java中的Map接口实现,包括HashMap的散列表和红黑树结构,LinkedHashMap的有序性实现,TreeMap的红黑树排序,以及Hashtable的线程安全性。详细探讨了各个类的put, get, remove等关键操作的源码,揭示了它们的内部工作机制。"
103209597,9120155,C/C++实现简单计算器,"['C++编程', '算法实现', '基础编程', '算术运算']
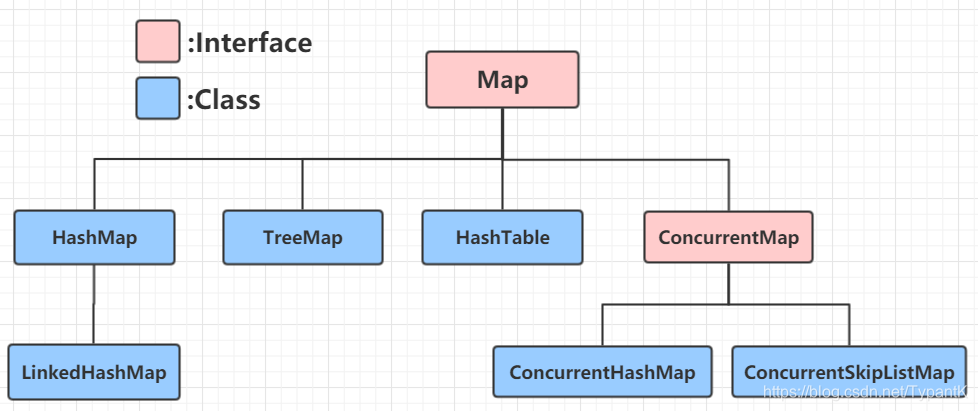
Map接口下的结构
目录
④public boolean containsKey(Object Key)
public boolean remove(Object key, Object value)
LinkedHashMap(散列表+非循环双向链表)[1.8不是循环]
① public V put(K key, V value)
② final int compare(Object k1, Object k2)
③private void fixAfterInsertion(Entry x),v>
HashTable(数组+链表)[Synchronized实现线程安全-锁住整个table]
①public synchronized V put(K key, V value)
HashMap(散列表+链表or红黑树)
通过Node数组进行存储,哈希冲突就通过链表或者红黑树进行存储
Node<K,V>实现了父类接口Map.Entry<K,V>

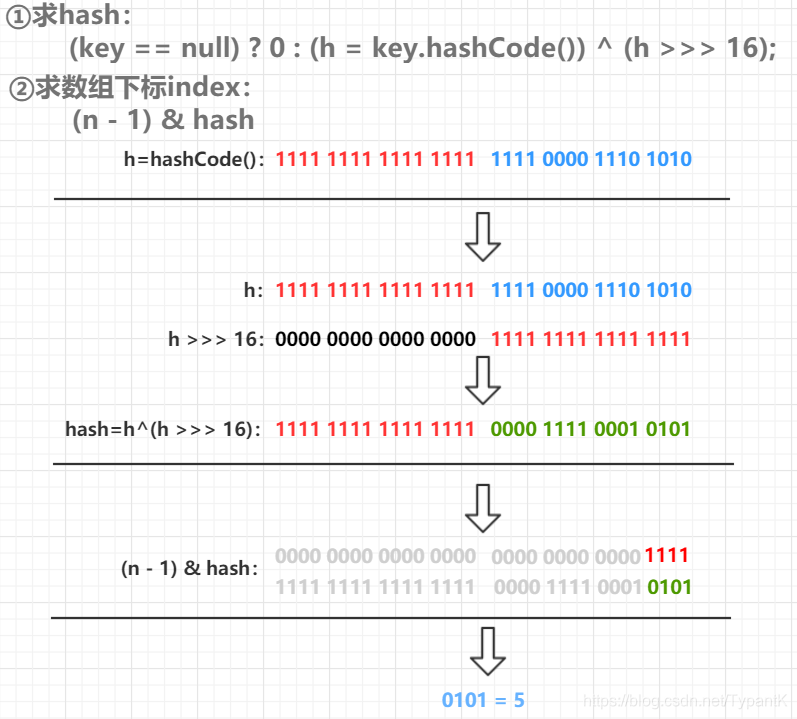
**数组下标index的求值:
①public V Put(K key, V value)
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
//hashCode()是本地方法
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果存储元素的table为空,进行必要字段的初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果根据hash值取得的结点为null,就新建一个结点p,否则返回结点p(注意p在tab的位置)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//如果插入的结点hash和key都相同
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//哈希冲突:如果是红黑树结点,就进行红黑树插入
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//哈希冲突:链表形式
else {
for (int binCount = 0; ; ++binCount) {
//已经遍历到最后一个结点p了,e为p.next,也就是链尾插入e
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//链表长度大于8,将链表转换成红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//这时e已经等于p.next了,如果链表中有相同的key,就退出
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//继续遍历下一个链表结点
p = e;
}
}
//如果不为null,此时e指向key相同hash相同的结点
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
//覆盖旧值
e.value = value;
//子类LinkedHashMap中重写,HashMap中是空函数
afterNodeAccess(e);
//返回旧值
return oldValue;
}
}
//更改操作次数
++modCount;
//大于存储空间临界值,就扩容,并将原先数组元素放到新数组中
//因为有链表、红黑树之类,所以还要调整他们
if (++size > threshold)
resize();
//子类LinkedHashMap中重写,HashMap中是空函数
afterNodeInsertion(evict);
return null;
}借鉴一张图,侵权即删

②final void treeifyBin(Node<K,V>[] tab, int hash)
//树化前预备操作
//插入一个元素之后,判断hash对应桶结点数>=8就执行此函数进行链表树化
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
//此方法返回一个有e数据(hash/key/value)的树节点p,null传入的是e.next
TreeNode<K,V> p = replacementTreeNode(e, null);
//遍历的第一层:相当于设置根结点hd
if (tl == null)
hd = p;
else {
//和原链表顺序一致:双向链表
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
//进行树化
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
// For treeifyBin
TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
return new TreeNode<>(p.hash, p.key, p.value, next);
}
③final void treeify(Node<K,V>[] tab)
/**
* Forms tree of the nodes linked from this node.
* @return root of tree
*/
//此时链表已经是双向链表了
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
//调用此方法时用的是头结点Node.treeify(),所以this代表需要树化双向链表头结点
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
//循环第一层:设置头结点
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
//p是从根结点用来搜索x应该插入到哪的指针
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
//*注意:hash不等同于数组下标,所以hash是可以不同的,数组下标是一定相同的
//dir == -1 代表往p的右走
if ((ph = p.hash) > h)
dir = -1;
//dir == 1 代表往p的左走
else if (ph < h)
dir = 1;
//走到这里代表x的hash和p的hash相同,就比较key
else if ((kc == null &&
//如果key没有实现comparable接口或者 x和p的key也是相同的
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
//定义的规则(比较判空+类名+hashCode())进行判断走左还是走右
dir = tieBreakOrder(k, pk);
//记录父节点xp
TreeNode<K,V> xp = p;
//代表x就插入在xp的下层
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
//红黑树插入平衡(通过左右旋和改变结点颜色保证符合红黑树要求)
root = balanceInsertion(root, x);
break;
}
}
}
}
moveRootToFront(tab, root);
}
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
//字典序法比较两个类名是否一致,如果返回0代表类相同
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
//通过hashcode()大小来比较
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
④static <K,V> TreeNode<K,V> balanceInsertion
(TreeNode<K,V> root, TreeNode<K,V> x)
//每次插入一个红黑树结点就调用此方法进行一次调整,使其满足红黑树要求
//root是红黑树根结点,x是新插入的结点。最后返回调整后红黑树根结点
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
//新节点设置成红色
x.red = true;
//xp是x的父节点/xpp是xp的父节点/xppl是xpp左结点/xppr是xpp右结点
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
//红黑树只有一个结点x,颜色设置成黑色(红黑树根节点是黑色)
if ((xp = x.parent) == null) {
x.red = false;
return x;
}
//只有两层(xp->x)
else if (!xp.red || (xpp = xp.parent) == null)
return root;
//如果x父节点是x爷结点的左节点
if (xp == (xppl = xpp.left)) {
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
else {
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
⑤static <K,V> void moveRootToFront
(Node<K,V>[] tab, TreeNode<K,V> root)
/**
* Ensures that the given root is the first node of its bin.
*/
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root != null && tab != null && (n = tab.length) > 0) {
int index = (n - 1) & root.hash;
TreeNode<K,V> first = (TreeNode<K,V>)tab[index];
if (root != first) {
Node<K,V> rn;
tab[index] = root;
TreeNode<K,V> rp = root.prev;
if ((rn = root.next) != null)
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
if (first != null)
first.prev = root;
root.next = first;
root.prev = null;
}
assert checkInvariants(root);
}
}③final TreeNode<K,V> putTreeVal
(HashMap<K,V> map, Node<K,V>[] tab, int h, K k, V v)
/**
* Tree version of putVal.
*/
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
TreeNode<K,V> root = (parent != null) ? root() : this;
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
②resize()
//初始化(当前table==null)或者扩容之后元素调整(++size > threshold --> resize())
final Node<K,V>[] resize() {
//oldTab是旧元素数组
Node<K,V>[] oldTab = table;
//旧数组长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//旧数组扩容临界值
int oldThr = threshold;
//新数组长度以及扩容值
int newCap, newThr = 0;
//如果旧数组不为空
if (oldCap > 0) {
//数组的长度已经达到最大值,就改变临界值为Integer.MAX_VALUE,返回旧数组
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//1.新数组扩容1倍后小于数组最大值 2.旧数组长度大于默认初始值
//就把新数组的临界值也扩大一倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//如果旧数组为空,且临界值大于0,新数组长度就等于旧数组的扩容临界值
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
//旧数组为空,临界值≤0,新数组长度和临界值都使用默认值
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//如果新数组临界值还为0,就设置根据loadFactor(负载因子)临界值(其实好像不可能发生?上面的情况要不就return,要不都有赋值)
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//更新装填因子
threshold = newThr;
//建表
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//对新表的初始化
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//如果当前节点没有哈希冲突直接插入就行
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//哈希冲突:红黑树调整
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//哈希冲突:链表调整
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
//遍历当前哈希冲突链表
do {
next = e.next;
//用于计算扩容新增后计算位置bit如果为0,就保持原位置(数组标识)
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
//如果新增bit后计算位置bit为1,就是原位置+旧数组长度(数组标识)
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}**扩容后新结点的位置判断:if(e.hash & oldCap == 0){}
- n-1:n是当前tab的长度
- hash(key1):key1的hash值
- hash(key2):key2的hash值

可以看出扩容之后(b)只有部分数据(key2)的数组index会发生改变,key1保持不变
而发生变化的就是hash(key)&oldCap这一位bit,所以只需要判断这一位就知道位置是否变化
而位置变化的大小就是原位置+oldCap
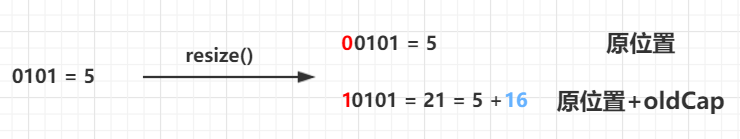
③public V get(Object key)
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//判断必要字段是否已经初始化,如果没有直接返回null
if ((tab = table) != null && (n = tab.length) > 0 &&
//注意这里对first的赋值,插入时也是用长度和hash进行与运算来得出tab位置
(first = tab[(n - 1) & hash]) != null) {
//首先都是检查首结点
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//存在哈希冲突状况
if ((e = first.next) != null) {
//判断是不是红黑树
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//不是红黑树就当做链表来处理(key和hash相同就返回)
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}④public boolean containsKey(Object Key)
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//先判断是否为空,然后拿到hash相同的头结点
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//先检查头结点是否key也和传进来的key相同
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//如果和头结点不相同,继续往深查找
if ((e = first.next) != null) {
//红黑树查找
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//链表查找
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
⑤public V remove(Object key)
public boolean remove(Object key, Object value)
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
public boolean remove(Object key, Object value) {
return removeNode(hash(key), key, value, true, true) != null;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//还是先检查必要的参数table和table.length,index是所要删除元素的数组下标
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
//还是先检查头结点的key和hash是否和要求一致,如果一致就赋值node指向要删除的结点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
//如果不一致,可能在头结点的后面,往深找
else if ((e = p.next) != null) {
//如果是红黑树结构,就调用getTreeNode()来找结点返回给node
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
//如果是链表结构的处理,找到结点就赋值给node。循环中以及循环外p.next=e
//如果第一次执行就break了,代表只有一个节点?
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//如果node不为空,说明找到了要删除的结点
//matchValue为是否需要对比value值(remove两个方法不同值)
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
//红黑树结构删除
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
//如果头结点就是所要删除结点
else if (node == p)
tab[index] = node.next;
//node不是首节点:p是node的父节点,直接改变一下指针即可
else
p.next = node.next;
//HashMap的操作次数+1
++modCount;
--size;
//让子类LinkedHashMap重写,HashMap中没有实现
afterNodeRemoval(node);
return node;
}
}
return null;
}
LinkedHashMap(散列表+非循环双向链表)[1.8不是循环]{有序}
Node(Entry):

这里的prev就是before,next就是after,hnext就是next(原HashMap中解决哈希冲突的指针)
*图中省略了Key/Value
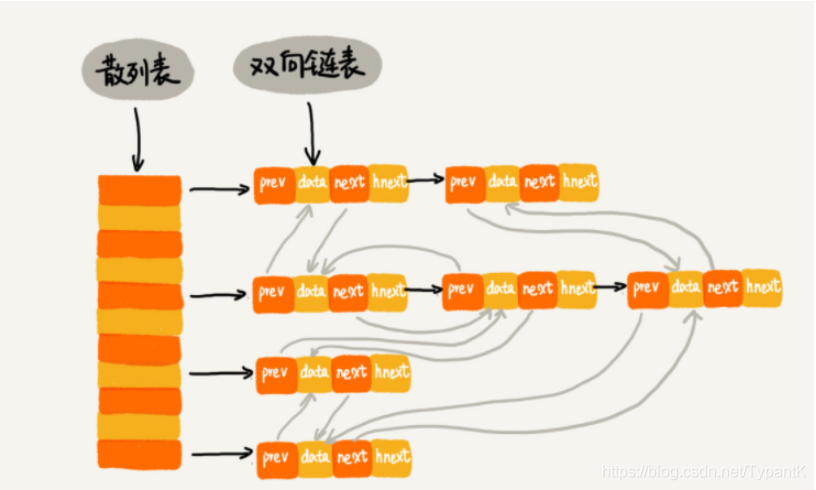

*head和tail只有一个结点时指向同一个结点
*accessOrder为true:链表根据访问顺序排序(LRU,最新访问放后面);为false:链表根据插入顺序排序
① public V put(K key, V value)
LinkedHashMap并没有重写put方法,但是重写了构造结点的几个方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
tab[i] = newNode(hash, key, value, null);
...
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
...
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
...
afterNodeAccess(e);
...
afterNodeInsertion(evict);
return null;
}Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
//集合之前是空的
if (last == null)
head = p;
else {
//将新节点链接到尾部
p.before = last;
last.after = p;
}
}void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}②public V get(Object key)
void afterNodeAccess(Node<K,V> e)
*getNode(int hash,Object key)和HashMap的实现一样,就不重复了
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
//如果是访问顺序排序,才进行排序;如果最后一个结点已经是e就不用排序了
if (accessOrder && (last = tail) != e) {
//用p指向e
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
//情况1:p前一个结点b不存在
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
//情况2:p后一个结点a不存在
else
last = b;
//last==null代表只有一个结点p
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
//新的尾结点变成p
tail = p;
++modCount;
}
}③public V remove(Object key)
void afterNodeRemoval(Node<K,V> e)
*getNode(int hash,Object key)和HashMap的实现一样,就不重复了
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
//删除节点后日常两种情况:前面结点是否空,后面结点是否空
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
TreeMap(红黑树){有序}
可以对添加进来的元素进行排序[二叉搜索树]
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{
//比较器
private final Comparator<? super K> comparator;
//根结点
private transient Entry<K,V> root;
/**
* 结点个数
*/
private transient int size = 0;
/**
* 树结构被修改次数
*/
private transient int modCount = 0;
//红黑树节点颜色
private static final boolean RED = false;
private static final boolean BLACK = true;
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
}
}①public V put(K key, V value)
public V put(K key, V value) {
Entry<K,V> t = root;
//如果根结点为空,就设置插入的元素为根结点root,设置必要参数size/modCount后返回
if (t == null) {
//....
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
//提取出比较器
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
//如果比较器不为空,就采用比较器里面的排序算法进行排序
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
//排序结果小于0:新增节点的key小于当前根结点,往左子树找插入位置
if (cmp < 0)
t = t.left;
//排序结果大于0:新增节点的key大于当前根结点,往右子树找插入位置
else if (cmp > 0)
t = t.right;
//两个key相同,新值覆盖旧值,返回旧值
else
return t.setValue(value);
} while (t != null);
}
//如果比较器为空,就采用默认的排序算法
else {
if (key == null)
throw new NullPointerException();
//获得比较器
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
//和上面处理步骤一样
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
//执行到这里,代表key没有重复,需要新插入结点,所以指定parent为其父节点
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
//插入完参数设置
size++;
modCount++;
return null;
}
② final int compare(Object k1, Object k2)
/**
* Compares two keys using the correct comparison method for this TreeMap.
* 通过正确的比较器来比较两个key:如果TreeMap比较器为空,就用key类实现的比较器;如果不为空,就直接用来比较
*/
@SuppressWarnings("unchecked")
final int compare(Object k1, Object k2) {
//如果
return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2)
: comparator.compare((K)k1, (K)k2);
}
③private void fixAfterInsertion(Entry<K,V> x)
/** From CLR */
//CLR:公共语言运行库和Java虚拟机一样也是一个运行时环境,它负责资源管理(内存分配和垃圾收集等),并保证应用和底层操作系统之间必要的分离
private void fixAfterInsertion(Entry<K,V> x) {
//新增的结点设置成红色
x.color = RED;
while (x != null && x != root && x.parent.color == RED) {
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == rightOf(parentOf(x))) {
x = parentOf(x);
rotateLeft(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}
} else {
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == leftOf(parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
root.color = BLACK;
}
④public V get(Object key)
public V get(Object key) {
Entry<K,V> p = getEntry(key);
return (p==null ? null : p.value);
}
final Entry<K,V> getEntry(Object key) {
//如果有自定义比较器对象,分离出来执行另一段逻辑相同代码(为了性能)
// Offload comparator-based version for sake of performance
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
//提出当前key的类型实现的比较器k
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
//深度遍历
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}
/**
* Version of getEntry using comparator. Split off from getEntry
* for performance. (This is not worth doing for most methods,
* that are less dependent on comparator performance, but is
* worthwhile here.)
* 为了性能将此方法从getEntry()分离出来,大部分方法不依赖于性能的话就没什么意义,反之则有意义
*/
final Entry<K,V> getEntryUsingComparator(Object key) {
//逻辑也是差不多的,执行此方法代表有自定义的比较器
@SuppressWarnings("unchecked")
K k = (K) key;
Comparator<? super K> cpr = comparator;
if (cpr != null) {
Entry<K,V> p = root;
while (p != null) {
int cmp = cpr.compare(k, p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
}
return null;
}⑤public V remove(Object key)
public V remove(Object key) {
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
deleteEntry(p);
return oldValue;
}
/**
* Delete node p, and then rebalance the tree.
*/
private void deleteEntry(Entry<K,V> p) {
modCount++;
size--;
// If strictly internal, copy successor's element to p and then make p
// point to successor.
if (p.left != null && p.right != null) {
Entry<K,V> s = successor(p);
p.key = s.key;
p.value = s.value;
p = s;
} // p has 2 children
// Start fixup at replacement node, if it exists.
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {
// Link replacement to parent
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// Null out links so they are OK to use by fixAfterDeletion.
p.left = p.right = p.parent = null;
// Fix replacement
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { // return if we are the only node.
root = null;
} else { // No children. Use self as phantom replacement and unlink.
if (p.color == BLACK)
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
HashTable(数组+链表)[Synchronized实现线程安全-锁住整个table]
key-value都不能为null
Hashtable 中的方法是Synchronize的,而HashMap中的方法在缺省情况下是非Synchronize的。在多线程并发的环境下,可以直接使用Hashtable
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。但二者都实现了Map接口
基本的参数都是一样的,参数名从Node改成了Entry
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
/**
* The hash table data.
* 哈希表数据用一个数组存起来
*/
private transient Entry<?,?>[] table;
/**
* The total number of entries in the hash table.
* 数据总数
*/
private transient int count;
/**
* The table is rehashed when its size exceeds this threshold. (The
* value of this field is (int)(capacity * loadFactor).)
* 扩容临界值
* @serial
*/
private int threshold;
/**
* The load factor for the hashtable.
* 扩容因子
* @serial
*/
private float loadFactor;
/**
* The number of times this Hashtable has been structurally modified
* Structural modifications are those that change the number of entries in
* the Hashtable or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the Hashtable fail-fast. (See ConcurrentModificationException).
* 操作次数
*/
private transient int modCount = 0;
private static class Entry<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Entry<K,V> next;
}
}
①public synchronized V put(K key, V value)
//HashTable不同于HashMap:使用synchronized关键字保证线程同步
public synchronized V put(K key, V value) {
// Make sure the value is not null
//HashTable不同于HashMap:不接受value为null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
//返回对象的32位jvm内存地址
//HashTable不同于HashMap:不接受key为null,隐式抛出空指针异常
int hash = key.hashCode();
//HashTable不同于HashMap:HashMap数组下标计算i = (n - 1) & hash]
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
//遍历链表。新值覆盖旧值,返回旧值
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
//没有相同index又相同key,调用方法addEntry()进行判断是否扩容然后插入
addEntry(hash, key, value, index);
return null;
}
//执行此函数代表要多一个结点了
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
//判断是否需要扩容(是否≥临界值)
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
/**
* Increases the capacity of and internally reorganizes this
* hashtable, in order to accommodate and access its entries more
* efficiently. This method is called automatically when the
* number of keys in the hashtable exceeds this hashtable's capacity
* and load factor.
* 用于重新hash
*/
@SuppressWarnings("unchecked")
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
//和HashMap不一样的地方:设置的新容量是*2+1
int newCapacity = (oldCapacity << 1) + 1;
//如果扩容之后,已经大于数组的最大值了(Integer.MAX_VALUE - 8)
if (newCapacity - MAX_ARRAY_SIZE > 0) {
//如果旧数组已经扩容到最大就继续用
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
//还没到最大新数组容量就扩容成最大
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
//遍历旧数组的每个Entry
for (int i = oldCapacity ; i-- > 0 ;) {
//遍历哈希冲突中链表的每个数
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
//重新计算数组下标后插入,如果又是同一条链表,插入的顺序和之前的相反
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
②public synchronized V get(Object key)
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key.equals(k))},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @param key the key whose associated value is to be returned
* @return the value to which the specified key is mapped, or
* {@code null} if this map contains no mapping for the key
* @throws NullPointerException if the specified key is null
* @see #put(Object, Object)
*/
@SuppressWarnings("unchecked")
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
//很普通地求出数组下标
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
//很普通地遍历然后找key和hash都相同的value
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
//很普通地找不到返回null
return null;
}
ConcurrentMap
ConcurrentHashMap
*JDK1.7(获取的是Segment锁)
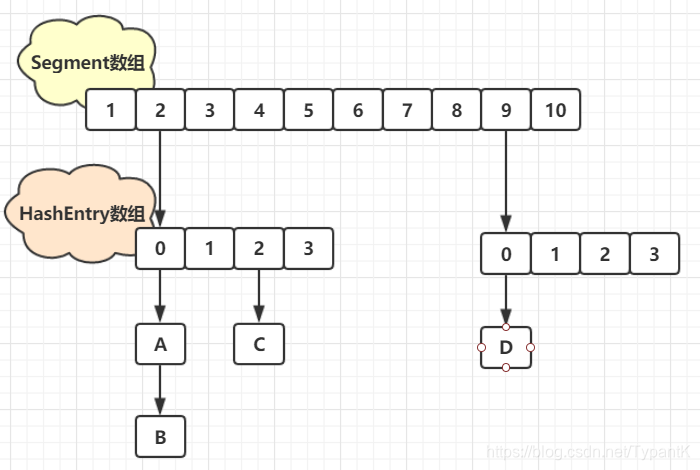
多线程环境下:并不需要争夺同一个锁,HashTable的话效率太低(锁住整个table)
整个 Hash 表被分成多个段,每个段中会对应一个 Segment 段锁,段与段之间可以并发访问,但是多线程想要操作同一个段是需要获取锁的。所有的 put,get,remove 等方法都是根据键的 hash 值对应到相应的段中,然后尝试获取锁进行访问。
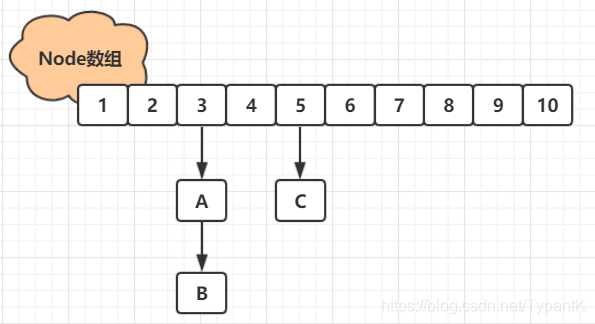
*JDK1.8
取消了基于 Segment 的分段锁思想,改用 CAS + synchronized 控制并发操作,在某些方面提升了性能。并且追随 1.8 版本的 HashMap 底层实现,使用数组+链表或红黑树进行数据存储。
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
/**
* The largest possible table capacity. This value must be
* exactly 1<<30 to stay within Java array allocation and indexing
* bounds for power of two table sizes, and is further required
* because the top two bits of 32bit hash fields are used for
* control purposes.
*/
//整个Node数组的最大范围,最高的两位bits要用于控制
private static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The default initial table capacity. Must be a power of 2
* (i.e., at least 1) and at most MAXIMUM_CAPACITY.
*/
//默认的Node数组容量,必须是2次幂
private static final int DEFAULT_CAPACITY = 16;
/**
* The largest possible (non-power of two) array size.
* Needed by toArray and related methods.
*/
//数组的最大容量(不是Node数组),要留8个字节控制数组对象
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* The default concurrency level for this table. Unused but
* defined for compatibility with previous versions of this class.
*/
//默认并发级别:此版本已经不用,是为了兼容以前版本
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
/**
* The load factor for this table. Overrides of this value in
* constructors affect only the initial table capacity. The
* actual floating point value isn't normally used -- it is
* simpler to use expressions such as {@code n - (n >>> 2)} for
* the associated resizing threshold.
*/
//加载因子,实际上不用浮点数,而是用n - (n >>> 2)来调整阈值
private static final float LOAD_FACTOR = 0.75f;
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2, and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
//桶里已有8个数据,再加的时候就要转换成红黑树
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
//小于6时,将红黑树转回链表
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* The value should be at least 4 * TREEIFY_THRESHOLD to avoid
* conflicts between resizing and treeification thresholds.
*/
//树化所要求的数组最小长度,要树化数组长度要大于此值,不满足则调用tryPresize(int size)扩容
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* Minimum number of rebinnings per transfer step. Ranges are
* subdivided to allow multiple resizer threads. This value
* serves as a lower bound to avoid resizers encountering
* excessive memory contention. The value should be at least
* DEFAULT_CAPACITY.
*/
private static final int MIN_TRANSFER_STRIDE = 16;
/**
* The number of bits used for generation stamp in sizeCtl.
* Must be at least 6 for 32bit arrays.
*/
//生成sizeCtl需要的位数
private static int RESIZE_STAMP_BITS = 16;
/**
* The maximum number of threads that can help resize.
* Must fit in 32 - RESIZE_STAMP_BITS bits.
*/
//允许的进行扩容的最大进程数
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
/**
* The bit shift for recording size stamp in sizeCtl.
*/
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*/
//整个哈希表(数组形式存储),Node数组
transient volatile Node<K,V>[] table;
/**
* The next table to use; non-null only while resizing.
*/
//连接表,用于哈希表扩容,扩容完成之后重置回null
private transient volatile Node<K,V>[] nextTable;
/**
* Base counter value, used mainly when there is no contention,
* but also as a fallback during table initialization
* races. Updated via CAS.
*/
//保存哈希表中存储所有节点个数,类似于HashMap的size
private transient volatile long baseCount;
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* creation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
*/
//-1 :代表table正在初始化,其他线程应该交出CPU时间片
//-N: 表示正有N-1个线程执行扩容操作(高 16 位是 length 生成的标识符,低 16 位是扩容的线程数)
//大于 0: 如果table已经初始化,代表table容量,默认为table大小的0.75,如果还未初始化,代表需要初始化的大小
private transient volatile int sizeCtl;
}
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}构造函数
/**
* Creates a new, empty map with the default initial table size (16).
*/
//创建默认初始容量16,加载因子0.75,并发等级16的空映射
public ConcurrentHashMap() {
}
/**
* Creates a new, empty map with an initial table size
* accommodating the specified number of elements without the need
* to dynamically resize.
*
* @param initialCapacity The implementation performs internal
* sizing to accommodate this many elements.
* @throws IllegalArgumentException if the initial capacity of
* elements is negative
*/
//创建指定初始容量,加载因子0.75,并发等级16的空映射
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0) //合法性检查
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
//找到最接近initialCapacity的2次幂
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap; //sizeCtl > 0时相当于扩容阈值
}
/**
* Creates a new map with the same mappings as the given map.
*
* @param m the map
*/
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
/**
* Creates a new, empty map with an initial table size based on
* the given number of elements ({@code initialCapacity}) and
* initial table density ({@code loadFactor}).
*
* @param initialCapacity the initial capacity. The implementation
* performs internal sizing to accommodate this many elements,
* given the specified load factor.
* @param loadFactor the load factor (table density) for
* establishing the initial table size
* @throws IllegalArgumentException if the initial capacity of
* elements is negative or the load factor is nonpositive
*
* @since 1.6
*/
//创造指定初始容量和加载因子,以及并发等级为1的映射
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
/**
* Creates a new, empty map with an initial table size based on
* the given number of elements ({@code initialCapacity}), table
* density ({@code loadFactor}), and number of concurrently
* updating threads ({@code concurrencyLevel}).
*
* @param initialCapacity the initial capacity. The implementation
* performs internal sizing to accommodate this many elements,
* given the specified load factor.
* @param loadFactor the load factor (table density) for
* establishing the initial table size
* @param concurrencyLevel the estimated number of concurrently
* updating threads. The implementation may use this value as
* a sizing hint.
* @throws IllegalArgumentException if the initial capacity is
* negative or the load factor or concurrencyLevel are
* nonpositive
*/
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0) //参数合法性检查
throw new IllegalArgumentException();
//有多少个桶就允许多少个并发进程
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
//size是容量,不是阈值
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
//构造时sizeCtl为2次幂(此时sizeCtl是容量,不是阈值?)
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
①public V put(K key, V value)
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
//ConcurrentHashMap不允许key或者value为空
if (key == null || value == null) throw new NullPointerException();
//hash的计算:return (h ^ (h >>> 16)) & HASH_BITS;
//(h是key.hashCode()、HASH_BITS默认是0x7fffffff)
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//检查是否需要初始化(tab为空)
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//根据键的hash值找到数组相应的index
//如果表不为空、hash值对应的桶为空就用CAS无锁式向该位置添加一个结点
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//检测到结点的hash值为MOVED,表示正在进行数组扩张的数据复制阶段
//允许多线程复制,所以当前线程去帮忙复制(转移)
else if ((fh = f.hash) == MOVED)
//结点转移
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//锁住桶
synchronized (f) {
//i为该桶在Node数组的下标值,f为对应的桶
if (tabAt(tab, i) == f) {
//fh为f桶的hash值
if (fh >= 0) {
binCount = 1;
//遍历f桶内所有元素
for (Node<K,V> e = f;; ++binCount) {
K ek;
//f桶内有key相同的键值对,返回一个oldVal旧值
//onlyIfAbsent = false(put操作),才将旧值改成新值
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
//f桶内没有key相同键值对,插入一个新节点
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//如果该结点是红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
//返回旧值oldVal、onlyIfAbsent==false时:替换旧值
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//链表深度超过8就转换成红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
/**
* Initializes table, using the size recorded in sizeCtl.
*/
//table为空时初始化table
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
//sizeCtl < 0 代表有进程正在初始化table,让权等待
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
//比较sizeCtl是否和sc相同,如果是就用-1赋值sizeCtl
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
//初始化时,sc=sizeCtl是数组的容量而不是阈值
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
//新生节点数组,大小为n
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
//扩容阈值设置为3n/4(也就相当于0.75 x Capacity = threshold)
sc = n - (n >>> 2);
}
} finally {
//此时sizeCtl才从容量变为阈值(初始化之后)
sizeCtl = sc;
}
break;
}
}
return tab;
}
//通过unsafe对象反射获取桶?i为Node数组中桶对应的下标
@SuppressWarnings("unchecked")
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
//CAS操作:判断i下标的桶是不是c,如果是就用v换c,否则不换
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
协助扩容:
/**
* Helps transfer if a resize is in progress.
*/
//协助扩容
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
//由于是协助扩容,所以当前nextTable应该不为空的
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
//根据table长度获得一个标识符
int rs = resizeStamp(tab.length);
//如果nextTable和Table没有被并发修改,而且处于扩容状态
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
// 如果 sizeCtl 无符号右移 16 不等于 rs ( sc前 16 位如果不等于标识符,则标识符变化了)
// 或者 sizeCtl == rs + 1 (扩容结束了,没有线程在进行扩容)
//(默认第一个线程设置 sc ==rs 左移 16 位 + 2,当第一个线程结束扩容了,就会将 sc 减一。这个时候,sc 就等于 rs + 1)
// 或者 sizeCtl == rs + 65535 (如果达到最大帮助线程的数量,即 65535)
// 或者转移下标正在调整 (扩容结束)
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
//以上情况都不是,CAS操作将sizeCtl+1,代表多了当前线程来帮助扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
//进行转移
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
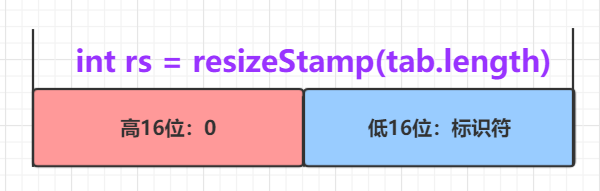
//根据table长度获得一个标识符
int rs = resizeStamp(tab.length);
第一个进程在扩容时

SC的值被设置成:标识符(高16位)+2(低16位)。也就是rs左移16位+2
当所有进程完成扩容时
SC的值应该是:标识符(高16位)+1(低16位)
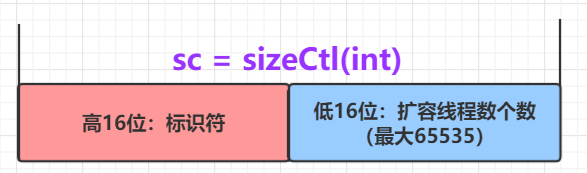
满足四条中 任 一 一 条 当前线程就不帮忙转换结点到nextTable
- 如果 sizeCtl 无符号右移 16 不等于 rs ( sc前 16 位如果不等于标识符,则标识符变化了,就代表还未扩容)
sizeCtl == rs + 1 (扩容结束了,没有线程在进行扩容)(默认第一个线程设置 sc ==rs 左移 16 位 + 2,当第一个线程结束扩容了,就会将 sc 减一。这个时候,sc 就等于 rs + 1)或者 sizeCtl == rs + 65535 (如果达到最大帮助线程的数量,即 65535)- 或者转移下标正在调整 (扩容结束)
if ((sc >>> RESIZE_STAMP_SHIFT) != rs ||
sc == rs + 1 ||
sc == rs + MAX_RESIZERS ||
transferIndex <= 0)
break;
https://bugs.java.com/bugdatabase/view_bug.do?bug_id=JDK-8214427
但是根据这里提交的bug,![]()
所以第二、三个判断是没有用的。
/**
* Moves and/or copies the nodes in each bin to new table. See
* above for explanation.
*/
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
//限制每个CPU处理数组长度最少为16
//即如果有一个数组长度只有16,则处理此数组的线程只能有一个
//stride为每个线程处理的数组长度
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // initiating
try {
//初始化nextTable:新建一个大小为原Table两倍的新Table
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
//nextTable是否完成扫描的标识(false未完成、true已完成)
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
//如果已经完成扫描,就不用这一步了
if (--i >= bound || finishing)
advance = false;
//需要转换的数组下标不合法
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
//CAS操作告诉线程要处理到哪个数组,下标为i
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
//完成扫描了,将旧数组指向新数组,清空临时对象nextTable
if (finishing) {
nextTable = null;
table = nextTab;
//扩容阈值设置成原来的1.5倍
sizeCtl = (n << 1) - (n >>> 1);
return;
}
//详见上面关于rs和sc的分析
//如果sc = sc - 1:代表当前线程执行完成,退出
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
//还有第一个线程在扩容,就直接表示任务完成??
finishing = advance = true;
i = n; // recheck before commit
}
}
//如果遍历到的桶为空,就放入一个fwd(ForwardingNode)结点,表示这个桶已经被处理过了
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
//并发控制核心:如果遍历到fwd指针,就代表这个桶已经被处理过了,跳过。
else if ((fh = f.hash) == MOVED)
advance = true; // already processed 已经 处理
//处理桶
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
//如果获得的桶是链表结构
if (fh >= 0) {
//处理同HashMap,resize后的结点要不留在原地,要不就移动n个桶
//(n是原来的capacity),详情可以往上拉看HashMap中分析
int runBit = fh & n;
Node<K,V> lastRun = f;
//遍历链表结点,拿到链表尾的结点lastRun
//或者结点链[上面所有结点都保持原地址或者移动capacity个单位]
//runBit是lastRun是否移动的判断
//如果要保持原序插入的话,倒过来是最好的,可以省掉一个记录头结点的空间
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
//遍历链表的每个结点根据新地址值来插入不同的链表
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
//ln = ln(new).next / hn = hn(new).next
//ln是resize后原地不动的链表
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
//hn是resize后移动capacity单位的链表
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
/**
* Finds or adds a node.
* @return null if added
*/
final TreeNode<K,V> putTreeVal(int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if (p == null) {
first = root = new TreeNode<K,V>(h, k, v, null, null);
break;
}
else if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.findTreeNode(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.findTreeNode(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
TreeNode<K,V> x, f = first;
first = x = new TreeNode<K,V>(h, k, v, f, xp);
if (f != null)
f.prev = x;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
if (!xp.red)
x.red = true;
else {
lockRoot();
try {
root = balanceInsertion(root, x);
} finally {
unlockRoot();
}
}
break;
}
}
assert checkInvariants(root);
return null;
}
/**
* Replaces all linked nodes in bin at given index unless table is
* too small, in which case resizes instead.
*/
//将链表中的Node变为TreeNode
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
//判断数组长度是否小于最小树化的数组数量要求(table太小不能树化,要先扩容)
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
//扩容以避免一个桶中结点过多
tryPresize(n << 1);
//开始树化
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
//操作之前锁住当前桶
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
//遍历所有结点,将所有Node变为TreeNode
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
//只是用TreeNode封装,没有用到left/right/parent等属性
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}putVal()---addCount(1L, binCount);
/**
* Adds to count, and if table is too small and not already
* resizing, initiates transfer. If already resizing, helps
* perform transfer if work is available. Rechecks occupancy
* after a transfer to see if another resize is already needed
* because resizings are lagging additions.
*
* @param x the count to add
* @param check if <0, don't check resize, if <= 1 only check if uncontended
*/
//x是要加的个数
//check当前桶已有结点个数,check<0就不用检查是否需要扩容;check<=1就只检查是否没有并发
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
//counterCells用于并发添加数量(有这个对象就代表并发了;没有不代表没有并发,还未处理)
//baseCount用于无竞争添加数量(CAS成功代表没有并发)
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
//as == null :并发已发生,尚未处理并发
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
//在此方法中继续死循环操作,直到成功
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
②
ConcurrentSkipListMap

















 574
574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









