



关注gongzhonghao【图灵学术SCI科研圈】,解锁更多SCI相关资讯!
在当今数字化时代,多模态数据的融合正逐渐成为智能系统的核心需求。无论是视觉与音频的协同处理,还是多输出回归任务中复杂数据的整合,如何高效地利用和处理这些跨模态信息,已成为人工智能领域的重要课题。
从视频场景中精准地分离声音,到利用视觉线索优化音频源分离,再到大规模多输出回归任务中的高效模型构建,这些看似分散的任务背后,其实都隐藏着一个共同的挑战:如何通过数据驱动的方法,有效地挖掘并利用多模态数据之间的内在关联,从而实现更精准、更高效的信息处理。近期的研究工作正逐步打破模态间的壁垒,探索出一系列创新的解决方案,为我们理解多模态数据的交互与整合提供了新的视角和方法。
下面。小图给大家精选3篇Mixture-of-Recursions方向的论文,请注意查收!
Learning Audio-Visual Dynamics Using Scene Graphs for Audio Source Separation
方法:
文章首先通过2.5D场景图的构建,将视频中的物体及其伪三维空间关系转换为图结构数据,然后利用循环图神经网络对场景图进行分割,生成与各个音频源对应的子图嵌入向量。这些子图嵌入向量被用于条件化音频分离网络,该网络基于U-Net架构实现音频源的分离。同时,通过方向预测网络,从分离后的音频信号中预测发声源的三维运动方向,从而实现音频源分离与运动预测的联合优化。
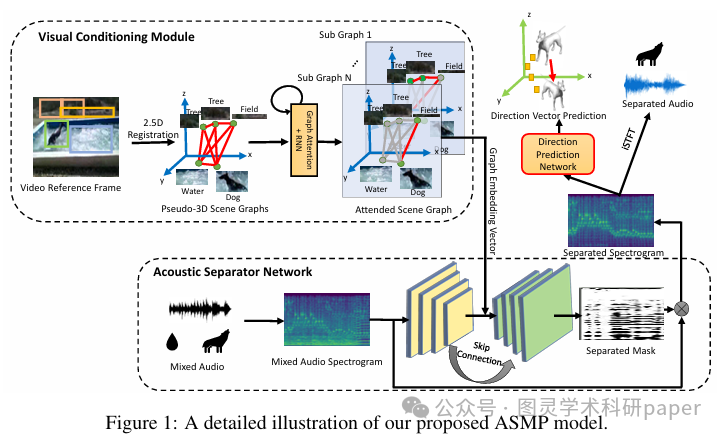
创新点:
-
首次提出了一种结合音频和视觉动态信息的深度学习框架,能够同时实现音频源分离和发声源的三维运动预测,为多模态学习开辟了新的应用场景。
-
引入了一种新颖的2.5D场景图表示方法,通过将视频帧的伪深度信息与物体检测结果相结合,有效地捕捉了场景中各个物体的伪三维空间关系,为音频源分离提供了更丰富的上下文信息。
-
利用发声源的运动方向作为辅助监督信号,通过端到端的训练方式,使得音频分离模块能够学习到与物体运动相关的声音特征,从而进一步提高了音频源分离的准确性和鲁棒性。
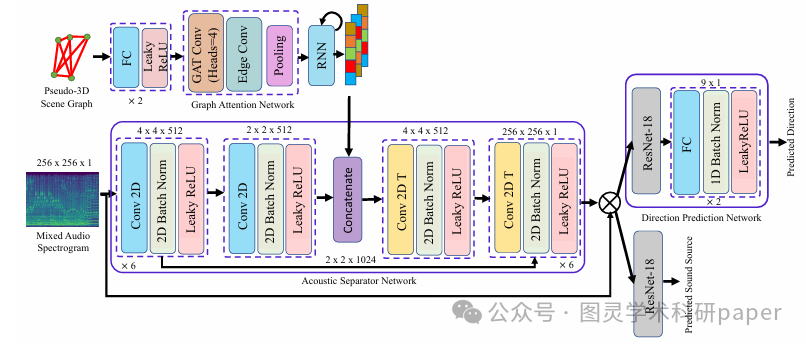
论文链接:
https://arxiv.org/pdf/2210.16472
关注gongzhonghao【图灵学术SCI科研圈】,获取MoR最新选题和idea
Leveraging Probabilistic Circuits for Nonparametric Multi-Output Regression
方法:
文章首先通过递归划分协变量空间和输出空间构建一个深层结构的概率电路,将复杂的多输出回归问题分解为多个相对简单的单输出子问题。接着,利用单输出高斯过程专家对每个子问题进行建模,并通过概率电路的求和和乘积节点整合各个专家的预测结果,从而实现对多输出变量的联合建模。最后,通过优化模型的超参数和利用变分推断等技术,提高了模型的计算效率和预测性能,使其能够有效地处理大规模数据集并准确地估计目标分布。
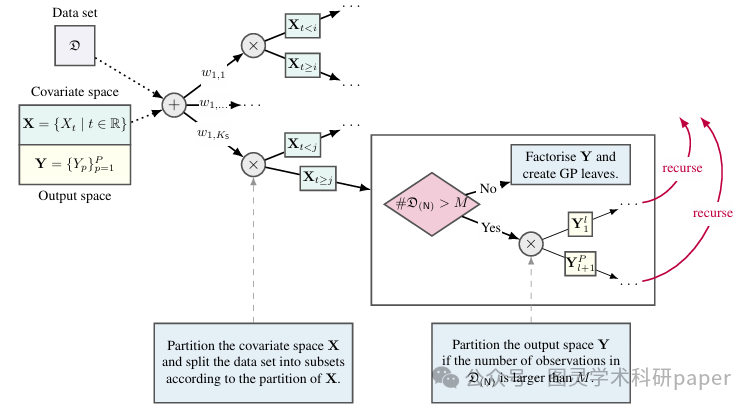
创新点:
-
提出了一种多输出混合高斯过程(MOMoGP),通过递归分解协变量空间和输出空间,将多输出回归问题转化为多个单输出高斯过程专家的组合,从而有效降低计算复杂度。
-
利用概率电路的结构特性,实现了精确且高效的后验推断,避免了传统方法在处理多输出任务时的近似计算,提高了模型的准确性和可靠性。
-
引入了一种基于树结构的混合模型构建方法,能够自适应地学习数据分布,从而更好地捕捉输出变量间的依赖关系,提升了模型的预测能力和泛化性能。

论文链接:
https://arxiv.org/pdf/2106.08687
关注gongzhonghao【图灵学术SCI科研圈】,获取MoR最新选题和idea
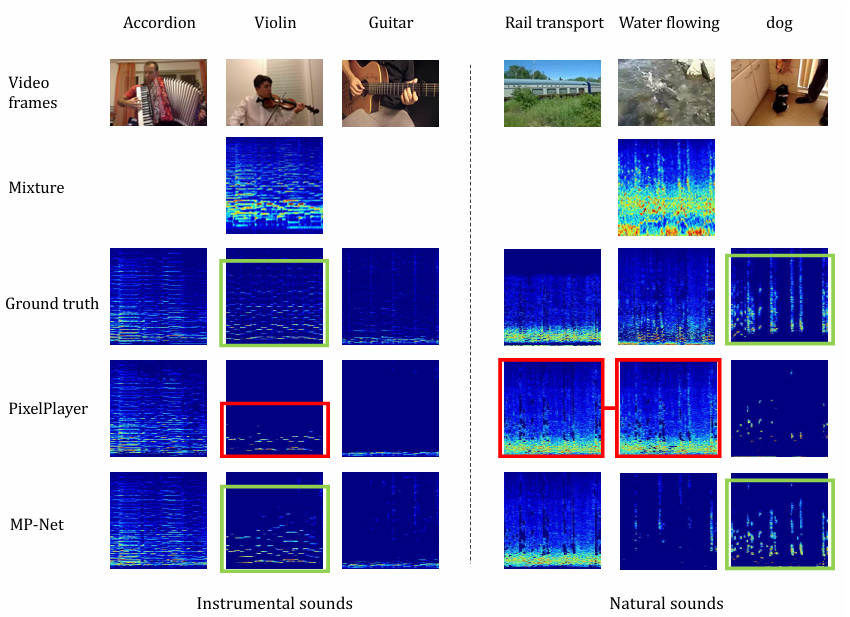
Recursive Visual Sound Separation Using Minus-Plus Net
方法:
文章提出的MP-Net框架包含两个关键阶段:Minus阶段和Plus阶段。在Minus阶段,模型通过递归方式逐步分离出混合声音中能量最大的独立声音,并将其从混合声音中移除,直到混合声音仅剩噪声或为空,此过程利用U-Net预测子频谱图并结合视觉特征图确定声音源位置,生成预测声音。Plus阶段则通过U-Net基于先前分离声音的混合和当前分离声音计算残差,对Minus阶段的分离结果进行优化,弥补可能遗漏的共享信息,最终输出精细化的声音分离结果。此外,文章还引入了基于结构相似性的新评估指标AMID,用于更稳定地衡量视觉声音分离模型的性能。
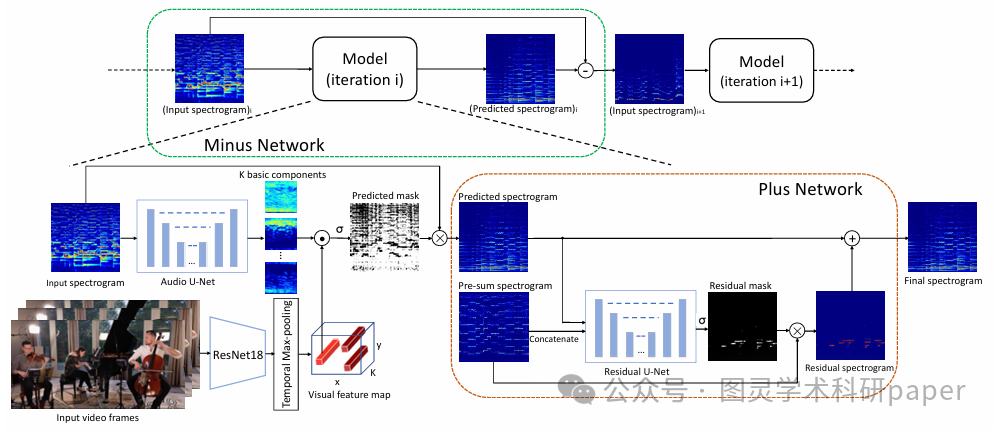
创新点:
-
提出MinusPlus网络(MP-Net)框架,通过递归分离能量最大的声音并从混合声音中移除,使能量较小的声音逐渐清晰,从而更精确地分离不同声音。
-
引入Plus阶段对已分离声音进行细化处理,补偿因移除先前分离声音而导致的共享信息丢失,提升分离声音的完整性和准确性。
-
提出平均互信息失真(AMID)指标,基于结构相似性(SSIM)评估分离声音的质量,有效避免传统指标因频率敏感性导致的评分波动。
论文链接:
https://arxiv.org/pdf/1908.11602
► 论文发表难题,一站式解决!
TURING
选题是论文的第一步,非常重要!
但很多学生找到了热门的选题,却卡在代码和写作上!可见论文要录用,选题-idea-代码-写作都缺一不可!
图灵学术论文辅导,汇聚经验丰富的实战派导师团队,针对计算机各类领域提供1v1专业指导,直至论文录用!
关注gongzhonghao【图灵学术SCI科研圈】,解锁更多SCI相关资讯!

















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









