



优先队列
之前的容器传的都是迭代器,优先队列为什么传的是索引?
可以使用索引的前提就是容器支持随机访问(如vector),而优先队列有这个性质
如果使用迭代器,代码肯定会复杂很多,毕竟每次都要调用
void heapAdjustByIter(vector<int>& heap, vector<int>::iterator current, int heapSize)
迭代器本身是一个对象,构造、复制、解引用都有微小时间和空间的开销
为什么优先队列模板会有三个参数
template<class T,class Container=vector<T>, class Compare=less<T>>
第二个是选择优先队列存储的容器类型,这里只能使用支持随机访问的容器,第三个是选择比较用的容器,用于控制构建大堆/小堆
我本来想着传过去的容器(Container)里面本来就有存储类型了,干嘛还要传第一个T?其实容器的存储类型对于优先队列来说 本来就是个盲盒,既然选择要接收这个容器,就必须明确容器的存储类型,所以才用第一个参数(类型)来写第二个参数
可以确保模板参数发挥设想的作用吗?
实际上不能,模板参数就是用于接收不确定的类型,所以不用想可能会接收到什么,支不支持完成什么功能,必要的检查加上即可,剩下的就看调用者传什么过来了
priority_queue(const Inputiterator p1,const Inputiterator p2) {//不知道要干啥了
assert(p1 < p2);//是谁都有这种比大小的运算符重载吗?//不是,这里不检查
for (auto i = p1; i != p2;i++) {
_arr.push_back(input[i]);
}
for (int i = (input.size() - 1 - 1) / 2; i >= 0; i--) {//for循环不能用size_t会爆
Down_Adjust(i);//用索引而不是迭代器
}
}
建堆的过程中为什么要保证左右子树都是堆?
首先这是最高效的方式,只需要n/2次向下调整
其次如果换成其它办法(比方对堆顶重复往下调整)是完全没办法保证堆本身的性质的
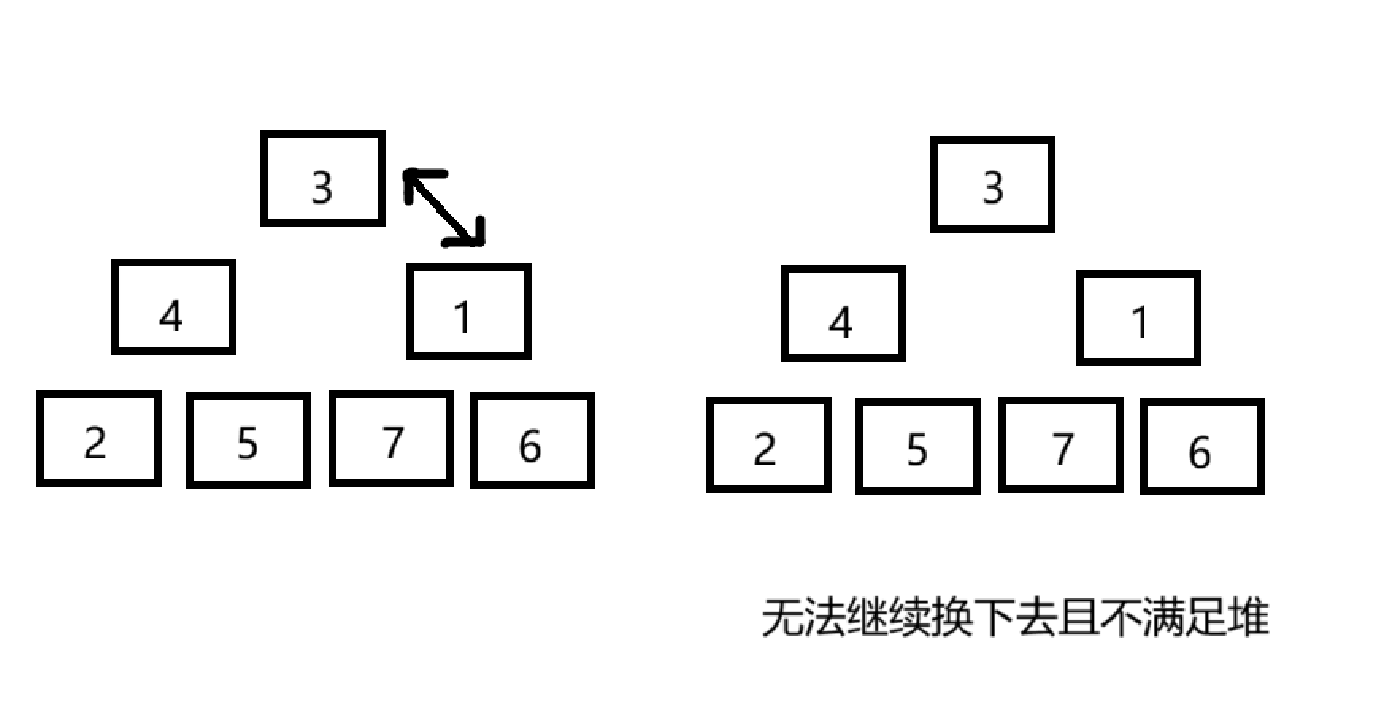
为什么Pop后选择向下调整而不是左右子树补位?
虽然这样可以让画出来的“树状图”确实还像个堆,但是数组早就被破坏了。如图如果选择7补位,需要进行判断。而且假如空缺的是3,5这些位置,补位会导致2,6,7构成的子树完全混乱
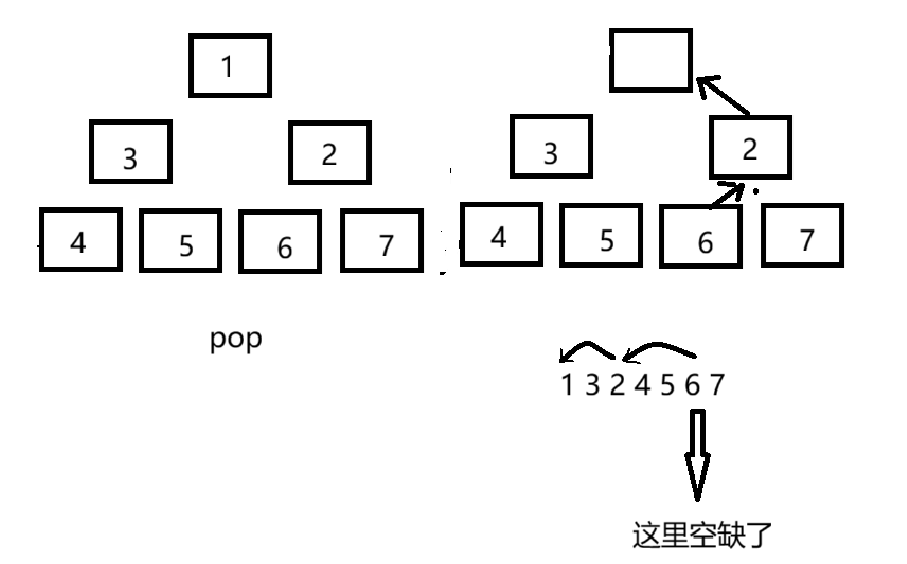
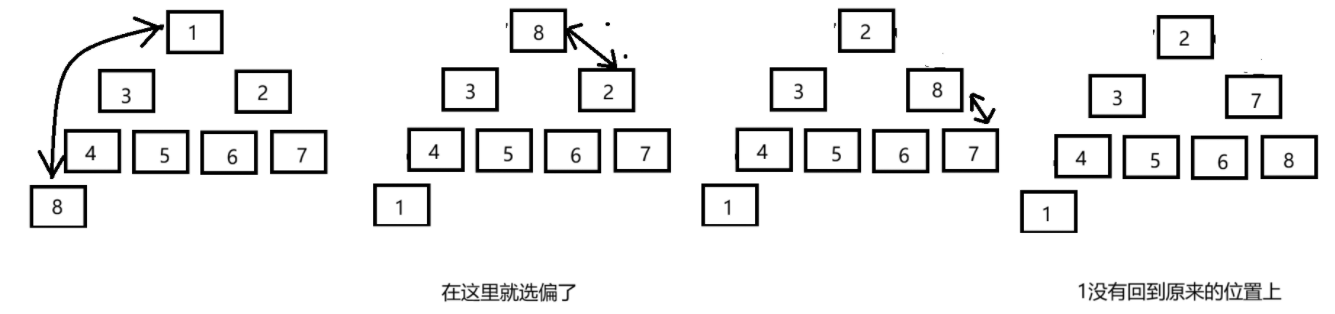
为什么push选择向上调整而不是像pop一样先交换然后向下调整?
向上必然是正确的(因为只有一条路可走),而向下每次有两条路径,有可能走错路
仿函数
一般形式
先定义一个类类型,然后写一个它的括号重载函数,用起来的时候就跟函数一样,所以叫仿函数
template<class T>
class less {
public:
bool operator()(const T& p1,const T& p2){
return p1 < p2;
}
};
为什么调用仿函数的时候不会调用它的构造函数?两个不是长得一样吗?
首先,语法上就不同:
// 语法1:类型名 对象名(参数); → 构造函数
MyFunctor obj(5); // 调用构造函数 MyFunctor(int)
// 语法2:对象名(参数); → operator()
obj(10); // 调用 operator()(int)
其次,构造函数只能使用一次(对象被定义的时候)后续不能再显式调用构造函数
特殊情况:临时仿函数对象如果要调用仿函数就要写成下面的的形式:
MyFunctor(5)(10);
为什么不直接用仿函数的构造函数来触发而选择用重载运算符?比如下面这样
template<class T>
class less {
public:
less(T p1){
p1++;}
};
有三个原因:
-
构造函数不能有返回值,而仿函数通常需要返回值。如果上面代码真要比大小的话,肯定要返回一个Bool的
-
构造函数只能通过创建新对象来调用,会导致每次“调用”都会创建一个新对象,开销大
-
如前文所述,构造函数不能被显式调用,而仿函数可以。
能否用除了仿函数以外的方式,实现优先队列指定建大堆/小堆呢?
既然是“指定”,构建优先队列的时侯必然传递了一些参数,这样就会有多种替代方式,这里只列
传函数指针这一种方式
bool minHeapCompare(int a, int b) {
return a > b; // 小顶堆
bool maxHeapCompare(int a, int b) {
return a < b; // 大顶堆
}
int main() {
// 将函数指针类型作为模板参数
bool (*minHeapFuncPtr)(int, int) = minHeapCompare;
priority_queue<int, vector<int>, bool(*)(int, int)>
minHeap(minHeapFuncPtr);
bool (*maxHeapFuncPtr)(int, int) = maxHeapCompare;
priority_queue<int, vector<int>, bool(*)(int, int)>
maxHeap(maxHeapFuncPtr);}
然而,仿函数仍然是最佳选择,原因如下
1. 性能最优:内联优化好
2. 可携带状态:可以存储比较所需的额外信息
3. 类型安全:编译时类型检查
4. 可复用:容易在不同地方复用
什么时候需要自己写仿函数?
比如比较List指针的时候,由于指针没有前后之分,所以必须自己控制实现
反向迭代器
template<class Iterator,class Ref,class Ptr>
class Reiterator {
public:
typedef Reiterator<Iterator, Ref, Ptr>self;
Iterator _it;
};
template<class T,class Ref,class Ptr>
struct List_Iterator {
node* _it;
};
//看看在容器中是怎么调用的?以List为例
template<class T>
class List {
public:
typedef List_Iterator<T,T&,T*> iterator;
typedef List_Iterator<const T,const T&,const T*> const_iterator;
typedef Reiterator<iterator, T&, T*> reiterator;
typedef Reiterator<const_iterator, const T&, const T*> const_reiterator;//为啥要我自己传给他?不然它不知道啊,又回到了那个问题//一定不要重名
typedef List_node<T> node;
iterator begin() {
return iterator(_start->_next);
}
iterator end() {
return iterator(_start);//左闭右开
}
reiterator rebegin() {
return reiterator(end());
}
reiterator rend() {
return reiterator(begin());
}
};
跟容器适配器有点像,reiterator直接把Iterator拿去复用了。“reiterator”这个名字本身只是为了给iterator做配套的服务而已.
值得注意的是,设计上rebegin()是iterator的end(),rend是原函数的begin();那我总不能真去访问end吧?所以解引用重载就往前挪了一位
Ref operator*() {
Iterator temp = _it;
return *(--temp);//这里也可以显式调用operator()
}
Ptr operator->() {
return &(operator*());
}
为啥要在容器中将正向迭代器传给反向迭代器?在反向迭代器里面定义iterator不就好了?
这其实就和之前设计const和非const迭代器一样的意思,假如我在迭代器内部这样写:
template<class T,class Ref,class Ptr>
class Reiterator {
public:
typefdef List_Iterator<T,T&, T*> iterator;
typefdef List_Iterator<T,const T&,const T*> const_iterator;
typedef Reiterator<Iterator, Ref, Ptr>self;
const_iterator _const_it;
iterator _it;
//那我后面每个iterator有关的函数都得注明用const还是非const的
//要么就写两个Reiterator,那我还是在list里面直接定义吧
};
为什么前置++可以返回引用而后置++就不行?
self& operator++() {
_it++;
return *this;
}
self operator++(int) {
self temp=*this;
//这里使用默认的拷贝构造函数,不需要另外写一个
//因为会自动调用iterator的拷贝构造函数
_it--;
return temp;
//此时temp已经被销毁,不能拿去引用,必须构造
}
其它各种小错误
非const引用不能绑定到字面值、临时对象或需要类型转换的对象,而const引用可以
范围for是不能使用反向迭代器的
一旦声明了任何构造函数,编译器就不再自动生成默认构造函数,如果没写后面会报错的
swap是浅拷贝吗?不是的:
namespace std {
template<typename T>
void swap(T& a, T& b) {
T temp = a; // 调用拷贝构造函数
a = b; // 调用拷贝赋值运算符
b = temp; // 调用拷贝赋值运算符
}
}//这样的实现方式决定了swap既可以浅拷贝又可以深拷贝
for循环不能用size_t,会爆,如果是i++还好,要是i--的话,i如果小于0就会变成随机值
for (size_t i = n-1; i >= 0; --i) {
// 当i为0时,执行循环体后,--i导致i变为size_t的最大值,循环条件i>=0始终成立,导致无限循环。
}
尽量不要和库里面的函数同名,虽然有命名空间,但要是用了using namespace就可能冲突了
调用模板类的时候千万记得加参数,嫌麻烦就typedef一下,把自己坑了好多次了
如果是编译错误就用注释代码的方式,能快速定位到错误区域,在较大片的区域里面还可以用二分法的原则去找,挺推荐的

















 558
558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









