




 本文围绕强化学习展开,介绍其用马尔可夫决策过程描述及相关四元组。以西瓜浇水为例说明,机器要学得使长期积累奖赏最大化的策略。还阐述了K - 摇臂赌博机的探索与利用窘境,以及ϵ - 贪心、Softmax算法,最后提及有模型学习下的策略评估。
本文围绕强化学习展开,介绍其用马尔可夫决策过程描述及相关四元组。以西瓜浇水为例说明,机器要学得使长期积累奖赏最大化的策略。还阐述了K - 摇臂赌博机的探索与利用窘境,以及ϵ - 贪心、Softmax算法,最后提及有模型学习下的策略评估。
#### 任务与奖赏 ####
“强化学习”(reinforcement learning)可以讲述为在任务过程中不断摸索,然后总结出较好的完成任务策略。
强化学习任务通常用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述:机器处于环境EE中,状态空间为,其中每个状态x∈Xx∈X是机器感知到的环境的描述;机器能采取的动作构成了动作空间AA;若某个动作作用在当前状态xx上,则潜在的转移函数将使得环境从当前状态按某种概率转移到另一个状态;在转移到另一个状态的同时,环境会根据潜在的“奖赏”(reward)函数RR反馈给机器一个奖赏;综合起来,强化学习任务对应了四元组,其中P:X×A×X→RP:X×A×X→R指定了状态转移概率,R:X×A×X→RR:X×A×X→R指定了奖赏;在有的应用中,奖赏函数可能仅与状态转移有关,即R:X×X→RR:X×X→R。
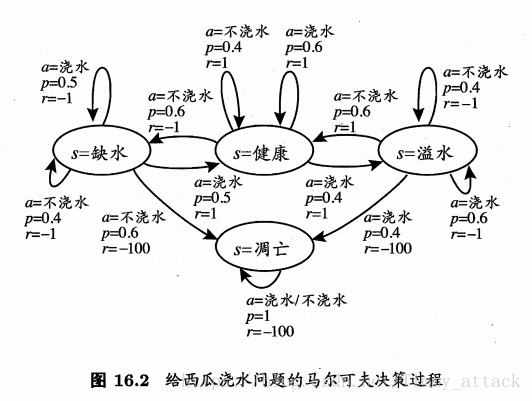
图16.2给出了西瓜浇水的马尔可夫决策过程。该任务中只有四个状态(健康、缺水、溢水、凋亡)和两个动作(浇水、不浇水),在每一步转移后,若状态是保持瓜苗健康则获得奖赏11,瓜苗缺水或溢水奖赏为,当瓜苗凋亡时奖赏是最小值−100−100。箭头代表状态转移,箭头旁的a,p,ra,p,r分别代表导致状态转移的动作、转移概率以及返回的奖赏。
机器要做的是通过在环境中不断地尝试而学得一个“策略”(policy)ππ,根据这个策略,在状态xx下就能得知要执行的动作。策略有两种表示方法:一种是将策略表示为函数π:X→Aπ:X→A,确定性策略常用这种表示;另一种是概率表示π:X×A→Rπ:X×A→R,随机性策略常用这种表示,π(x,a)π(x,a)为状态xx下选择动作的概率,这里必须有∑aπ(x,a)=1∑aπ(x,a)=1。
策略的优劣取决于长期执行这一策略后得到的累积奖赏。在强化学习任务中,学习的目的就是要找到能使长期积累奖赏最大化的策略。长期积累奖赏有多种计算方式,常用的有“T步积累奖赏”E[1T∑Tt=1rt]E[1T∑t=1Trt]和“r折扣累积奖赏”E[∑+∞t=0γtrt+1]E[∑t=0+∞γtrt+1],其中rtrt表示第tt不获得的奖赏值,表示对所有随机变量求期望。
K-摇臂赌博机
探索与利用
我们考虑比较简单的情形:最大化单步奖赏,即仅考虑一步操作。这时需要考虑两个方面:一是需知道每个动作带来的奖赏,二是要执行奖赏最大的动作。
单步强化学习任务对应了一个理论模型,即“K-摇臂赌博机”(K-armed bandit)。
K-摇臂赌博机和我们常见的老虎机差不多,投入硬币后可选择按下其中一个摇臂,每个摇臂以一定的概率吐出硬币。
若仅为获知每个摇臂的期望奖赏,则可采用“仅探索”(exploration-only)法:将所有的尝试机会平均分配给每个摇臂(即轮流按下每个摇臂),最后以每个摇臂各自的平均吐币概率作为其奖赏期望的近似估计。
若仅为执行奖赏最大的动作,则可采用“仅利用”(exploitation-only)法:按下目前最优的(即到目前为止平均奖赏最大)的摇臂,若有多个摇臂同为最优,则随机选择其中一个。
显然,“仅探索”法能很好地估计每个摇臂的奖赏,却会市区很多选择最优摇臂的机会;“仅利用”法则相反,它没有很好地估计摇臂期望奖赏,很有可能经常选不到最优摇臂。因此,这两种方法都难以使得最终的积累奖赏最大化。
由于尝试次数是有限的,“探索”和“利用”这两者相互矛盾,加强了一方则会自然消弱另一方,这就是强化学习所面临的“探索-利用窘境”(Exploration-Exploitation dilemma)。欲使积累奖赏最大,则必须在探索与利用之间达成较好的折中。
ϵϵ-贪心
ϵϵ-贪心法基于一个概率来对探索和利用进行折中:每次尝试时,以ϵϵ的概率进行探索,即以均匀概率随机选取一个摇臂;以1−ϵ1−ϵ的概率进行利用,即选择当前平均奖赏最高的摇臂(若有多个,则随机选取一个)。
令Q(k)Q(k)记录摇臂kk的平均奖赏,若摇臂被尝试了nn次,得到的奖赏为。一般,我们对均值进行增量式计算,即每尝试一次就立即更新Q(k)。这样每次尝试仅需记录两个值:已尝试次数n−1n−1和最近平均奖赏Qn−1(k)Qn−1(k)
ϵϵ-贪心算法描述如图16.4所示

Q(i)Q(i)和count(i)count(i)分别记录摇臂ii的平均奖赏和选中次数。
若摇臂奖赏的不确定性较大,例如概率分布较宽时,则需更多的探索,此时需要较大的值;若摇臂的不确定性较小,例如概率分布较集中时,则小量的尝试就能很好地近似真实奖赏,此时需要的ϵϵ较小。
Softmax
Softmax算法基于当前已知的摇臂平均奖赏来对探索和利用进行折中。若各个摇臂的平均奖赏相当,则选取各摇臂的概率也相当;若某些摇臂的平均奖赏明显高于其他摇臂,则被选取的概率也明显更高。
Softmax算法中摇臂概率的分配是基于Boltzmann分布:

有模型学习
假定任务对应的马尔可夫决策过程四元组E=<X,A,P,R>E=<X,A,P,R>均为已知,这样的情形称为“模型已知”,即机器对环境进行了建模。
策略评估
在模型已知时,对任意策略ππ能估计出该策略带来的期望积累奖赏。令函数Vπ(x)Vπ(x)表示从状态xx出发,使用策略所带来的积累奖赏;函数Qπ(x,a)Qπ(x,a)表示从状态xx出发,执行动作后再使用策略ππ带来的积累奖赏。这里V(⋅)V(⋅)称为“状态值函数”(state value function),Q(⋅)Q(⋅)称为“状态-动作值函数”(state-action value function),分别代表指定“状态”上以及指定“状态-动作”上的积累奖赏。可以定义状态值函数
令x0x0表示起始状态,a0a0表示起始状态上采取的第一个动作;对于TT不积累奖赏,用下标表示后续执行的步数。有状态-动作值函数

















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









