







 本文详细介绍了队列这一数据结构的基础概念与实现方式,包括顺序队列、链式队列及循环队列,并探讨了阻塞队列和并发队列在实际应用中的重要性和优势。
本文详细介绍了队列这一数据结构的基础概念与实现方式,包括顺序队列、链式队列及循环队列,并探讨了阻塞队列和并发队列在实际应用中的重要性和优势。
概念
定义
一种只允许从一端插入数据,另一端删除数据的线性表结构。它具有先进先出、后进后出的特点,允许插入数据的一端称为队尾,允许删除数据的一端称为队头,插入数据称为入队,删除数据称为出队。其结构如下图:
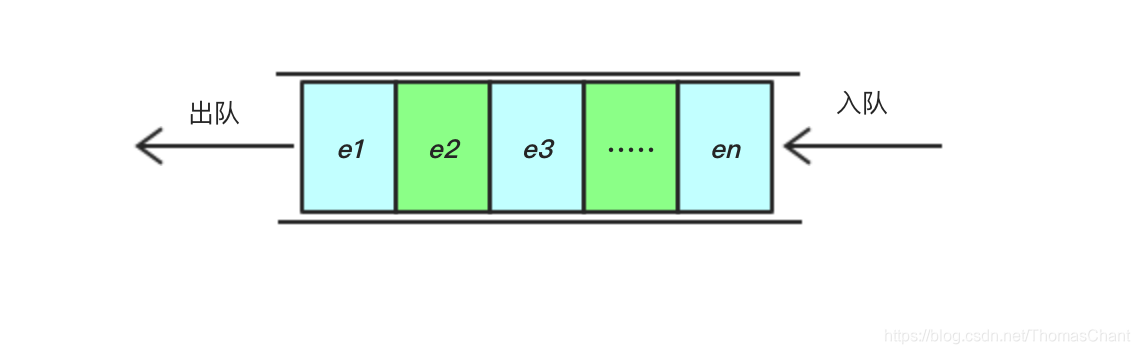
基础队列类型
队列的从底层实现来看有两大类:顺序队列和链式队列。顺序队列是基于数组来实现,而链式队列是基于链表来实现。
顺序队列
基于数组来实现的队列,以下java语言版本的简单实现,其核心思路是通过维持队首和队尾指针,来进行入队和出队操作。
public class ArrayQueue {
private Object[] data;
//队首指针
private int head = 0;
//队尾指针
private int tail = 0;
//队列长度
private int count = 0;
public ArrayQueue(int capacity){
this.data = new Object[capacity];
}
/**
* 入队操作
* @param e
*/
public boolean enqueue(Object e){
//1、队列已满,返回false
if(count == data.length){
return false;
}
//2、已经tail到达队尾
if(tail == data.length){
//2.1、队头已经没有空间,返回
if(head == 0){
return false;
}
//2.2、对头还有空间
//2.2.1、搬移数据
System.arraycopy(data,head ,data ,0,count);
//2.2.2、更新指针
head = 0;
tail = tail - head;
}
//3、插入数据
data[tail++] = e;
count++;
return true;
}
/**
* 出队操作
* @return
*/
public Object dequeue(){
//1、队列为空,返回null
if(count == 0){
return null;
}else {
//2
//2.1、获取队首数据
Object o = data[head];
//2.2、将队首数据清空,并将队首指针后推
data[head++] = null;
//2.3、将计数器减1
count--;
return o;
}
}
@Override
public String toString() {
final StringBuilder sb = new StringBuilder("");
sb.append("data=").append(Arrays.toString(data));
return sb.toString();
}
}
由于队列在不停的出队和入队操作中,其指针必然会渐渐后移,所以当队尾指针到达队尾后,再进行数据插入,需要将数据搬移到队首,其过程大致如下图所示:
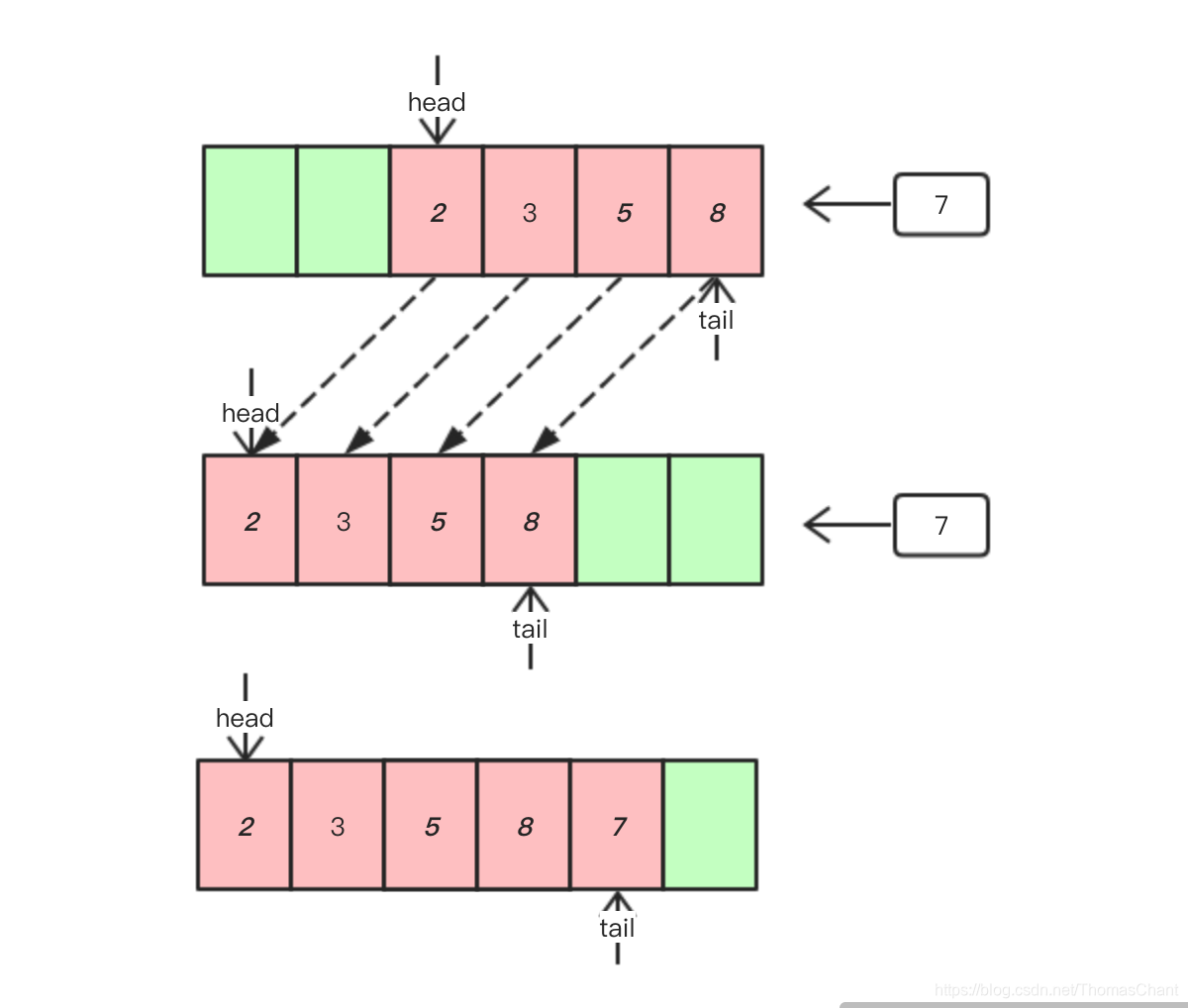
链式队列
链式队列是基于链表来实现的队列,其实现思路和数组实现方式类似,也是维护两个指针来进行出队和入队操作,只不过指针指向的是链表节点。
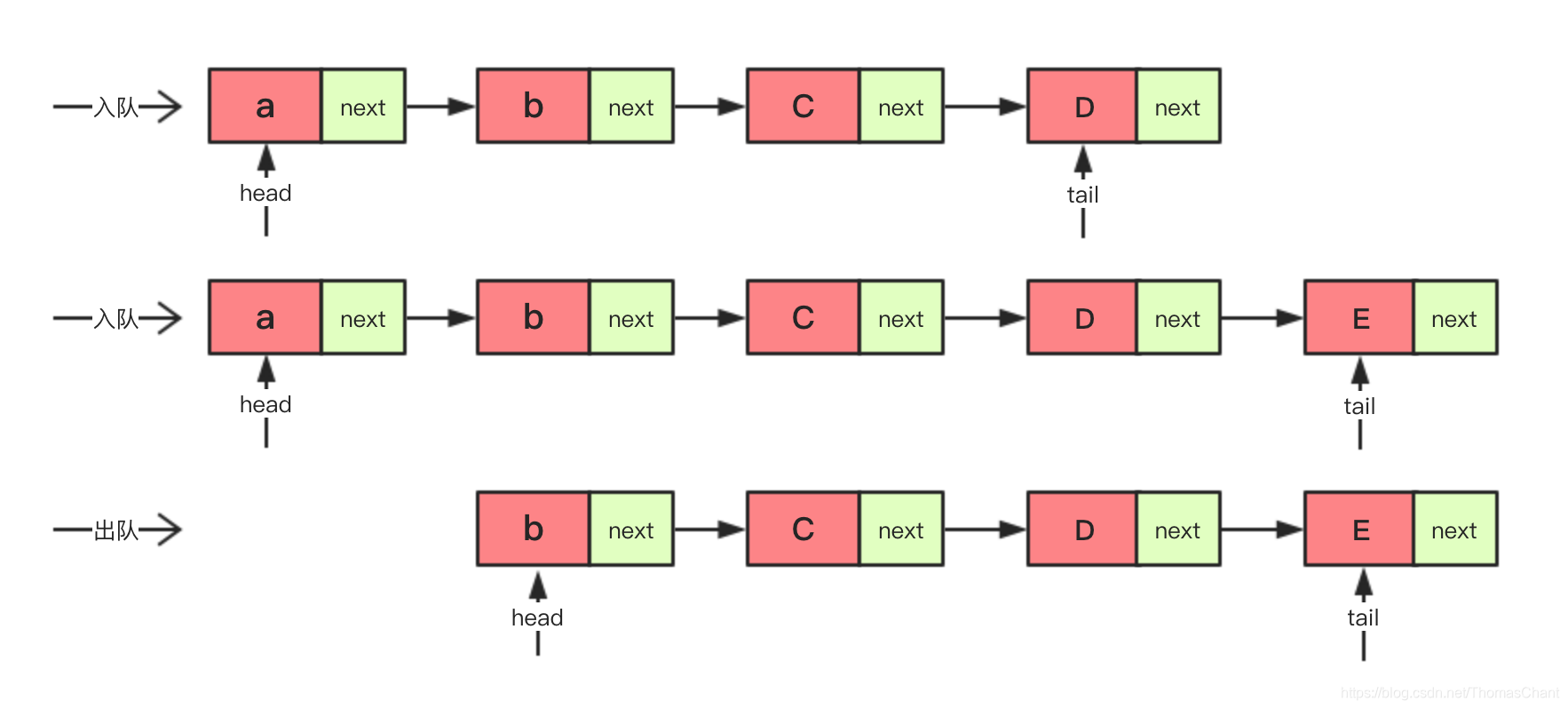
循环队列
循环队列是对顺序队列的一个改进,其通过将数组首尾相连来有效避免数据搬移的问题,其具体操作过程如下,以下每个步骤对应着下方一个图:
- 初始化一个长度为8的数组组成的队列,此时队列为空的时候,tail和head指针重叠,都指向0
- 往队列添加一个字符g,此时tail指针向前进一步,指向1,head指针不动
- 依次往队尾添加t、v、y、r、f、a字符,可以看到添加完后tail指针指向了最后一个空位7
- 接着我们从队头取出两个字符g、t,队列多出两个空位了
- 然后我们插入1个字符z,注意观察,会发现插入数据后tail由位置7移到了位置0,这一步是避免数据搬移的关键。因为上面讲过,在顺序队列里面,当tail指针到达终点后,就要通过搬移数据来留出位置,其时间复杂度为O(n),而循环队列的tail指针到位置7后,再添加数据,只需要把tail指针继续往前移一步到0就可以了,时间复杂度为O(1)。通过观察,我们可以发现一个规律,当tail<7的时候,添加数据后tail=tail+1=(tail+1)%8,而当tail=7时,添加数据后tail=0=(tail+1)%8,用一个统一的公式表达为:tail=(tail+1)%n。
- 接着再添加2个数据h、b,可以看到,tail再次和head指针重合,但是这次和第一幅图中重合的情况不一样,第一幅图中重合的位置是没有数据的,而这次是有数据的,我们可以根据这一点,来判断当head=tail时,队列到底是满的还是空的。
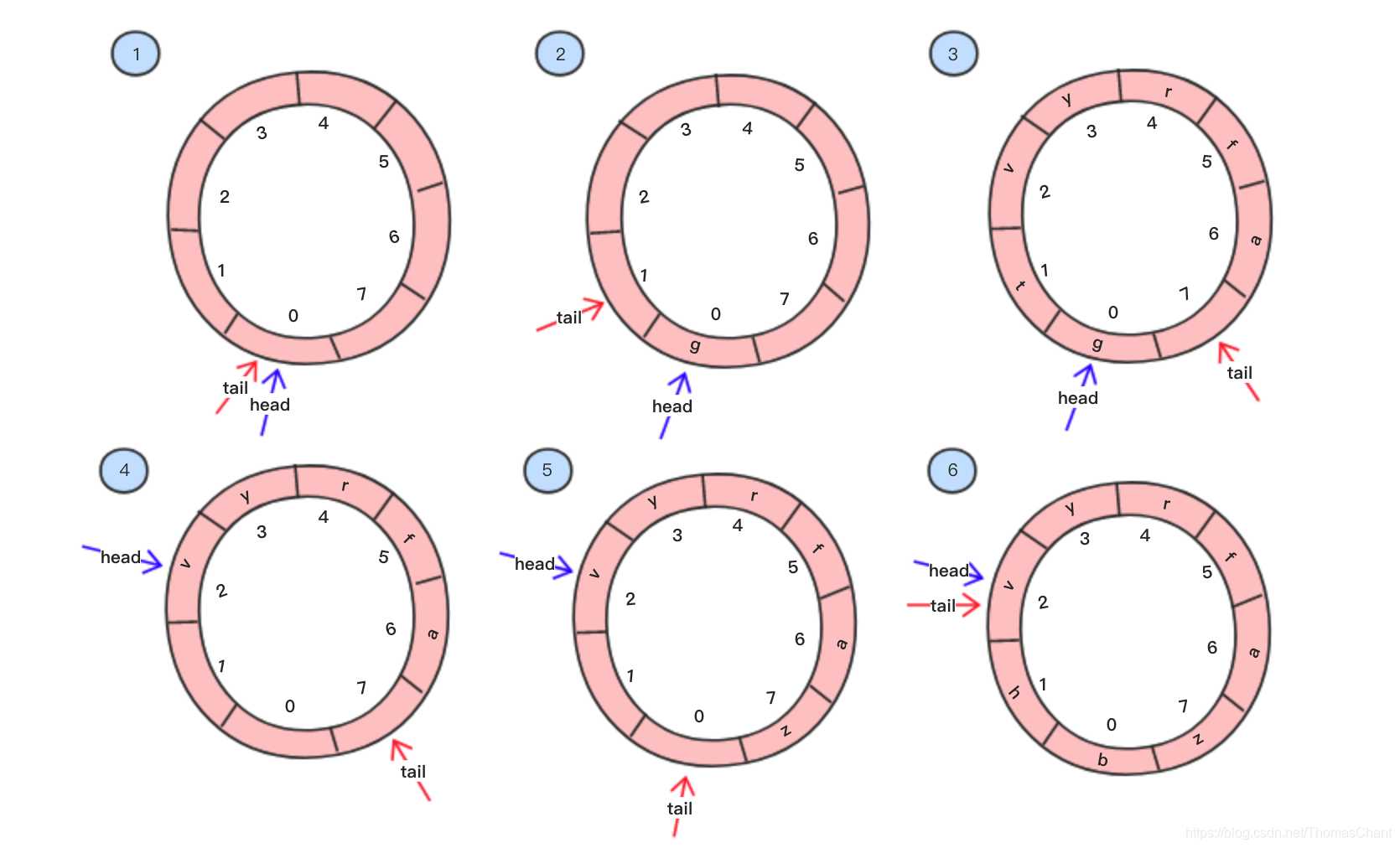
总结一下,主要有三点特别要注意:
- head=tail且指向的位置无数据表明队列为空;
- head=tail且指向的位置有数据表明队列已满
- 添加元素后tail=(tail+1)%n,删除元素后head=(head+1)%n
talk is cheap ,如果还没有理解,show you code 吧
public class CircularQueue {
private Object[] data;
private int head = 0;
private int tail = 0;
public CircularQueue(int capacity) {
if(capacity <= 0){
throw new IllegalArgumentException("Invalid capacity: "+capacity);
}
this.data = new Object[capacity];
}
public boolean enQueue(Object o){
if(isFull()){
return false;
}
data[tail] = o;
tail = (tail + 1) % data.length;
return true;
}
public Object deQueue(){
//tail和head相等,表明队列为空
if(isEmpty()){
return null;
}
Object o = data[head];
head = (head + 1) % data.length;
return o;
}
public boolean isEmpty(){
return head == tail && data[head] == null;
}
public boolean isFull(){
return head == tail && data[head] != null;
}
}
其他常用队列
阻塞队列
阻塞队列是在普通队列基础上,加上阻塞操作。具体来讲,就是当队列为空的时候,阻塞出队操作,直到队列中有数据,才返回结果,当队列满了的时候,阻塞入队操作,直到队列中有空位在插入。阻塞队列的目的是为了保证操作得到期望的正常的结果。就像排队买票时,排了很长的队,终于轮到你了,这时售票点出票机突然坏掉了,需要等一会,此时我们肯定不愿意出队,又到队尾去重新排一遍,而是等(阻塞)在那里,直到出票机重新出票。
阻塞队列的特性,可以帮助我们很好的实现一个生产者-消费者模式,生产者将数据放到队列,消费者从队列取出数据。
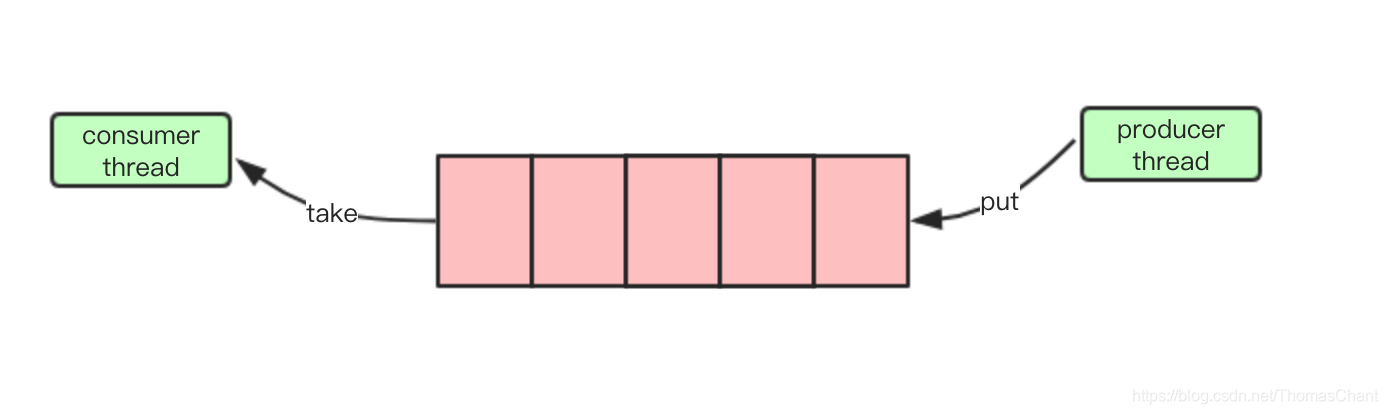
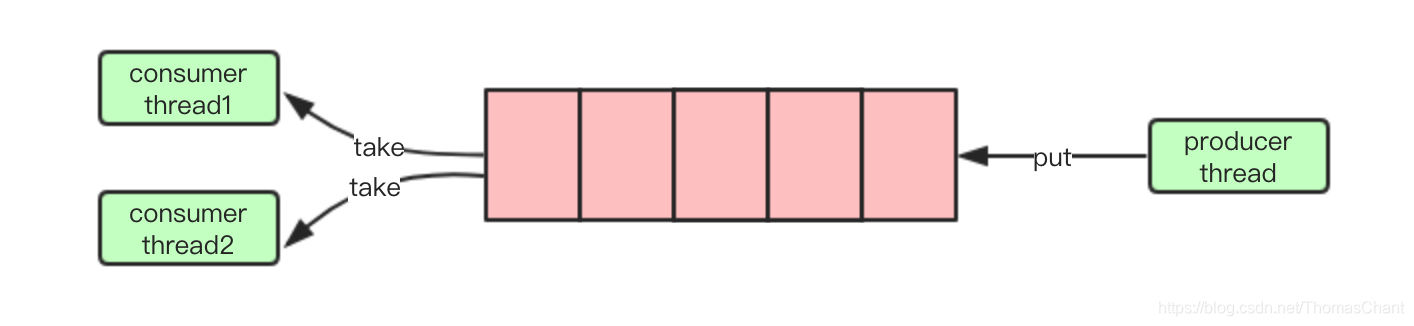
如果生产和消费速度不一致时,我们还可以通过调整线程数量,来使生产和消费速度达到一致。比如生产速度快于消费速度,我们可以增加消费线程来使数据更快的消耗掉。
并发队列
上面讲过,为了使阻塞队列的出队和入队速度达到平衡,可能会采用多线程,这时就要考虑到并发安全的问题。并发队列就是实现了并发安全的队列。最简单的做法是直接在方法上加锁,但是锁粒度大并发度低,可以基于cas或可重入锁等并发工具来实现高并发度的并发队列。
总结
这篇文章主要讲述了队列这种数据结构,它的基础实现有数组和链表两种,基于数组的称为顺序队列,基于链表的称为链式队列。循环队列的出现是为了避免顺序队列数据搬移的问题。而为了提高可用性于是有了阻塞队列,同时为了提高阻塞队列的性能,有了并发队列。

















 696
696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









