







 本文探讨了基于日志的预测维护技术,旨在通过数据挖掘预测设备故障,减少设备停工期,提高服务质量。介绍了预测维护流程,数据描述,以及解决正负样本不均衡问题的方法,如分层采样和边缘技术。
本文探讨了基于日志的预测维护技术,旨在通过数据挖掘预测设备故障,减少设备停工期,提高服务质量。介绍了预测维护流程,数据描述,以及解决正负样本不均衡问题的方法,如分层采样和边缘技术。
0. 心得
题目翻译过来叫基于日志的预测维护,也就是通过对日志的数据挖掘来预测将来一段时间系统是否发生故障。文章从实际项目出发,提出了整个工作流程(workflows),并简述了工程中常见问题(正负样本数不均衡)以及提供了解决方案,并通过实验证明了该文章的算法的表现,使用的衡量标准是准确率-召回率分数(F1值),文章最后提到了相关的工作,各位学者用不同的方法来进行日志文本挖掘。
这篇文章读下来给我的价值在于以上,比较遗憾的是并没有读懂多示例学习的具体算法,即便是单独的算法1也只是大概的工作流。
好了。接下来,分部分逐步记录阅读论文的笔记,以供后续参考。
论文链接:
[1] https://astro.temple.edu/~tua63862/indg0371-sipos.pdf
[2] http://pdfs.semanticscholar.org/a73c/885a9272acaa2ca43c3ab2637a1477fb165c.pdf
摘要
预测维护是要尽力预判到装备的错误并可以提前给与纠错的时间,因而避免不期望的设备的停工期并且为客户提高服务质量。我们提供了一个基于多示例学习的数据驱动的方式来预测设备失败,通过挖掘设备事件日志。然而,日志通常都不是为了预测错误而设计的,其中包含了大量的操作信息。我们讨论问题领域、规划、评价度量和预测维护的工作流程。我们实验中比较了其他的方法。我们分享了从每个数据挖掘的见解。过去的几个月,我们的预测维护方法一直为主要的医疗设备供应商提供服务,从日志数据中、事实监控大量医疗扫描器中,学习并评估预测模型。
1. 引言
相关工作在后面介绍,这里主要介绍Predictive Maintenance的意义,总而言之就是 预先发现问题,提前解决问题可以保证设备流畅的运行,可谓是意义重大。
2. 问题描述
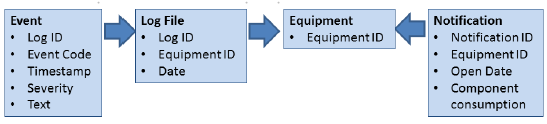
2.1 数据描述
数据分为log数据和服务数据。
- 首先是log数据:

其中,EventCode为相似信息文本组的分类和事件的严重程度。 - 服务数据
2.2 预测维护流程
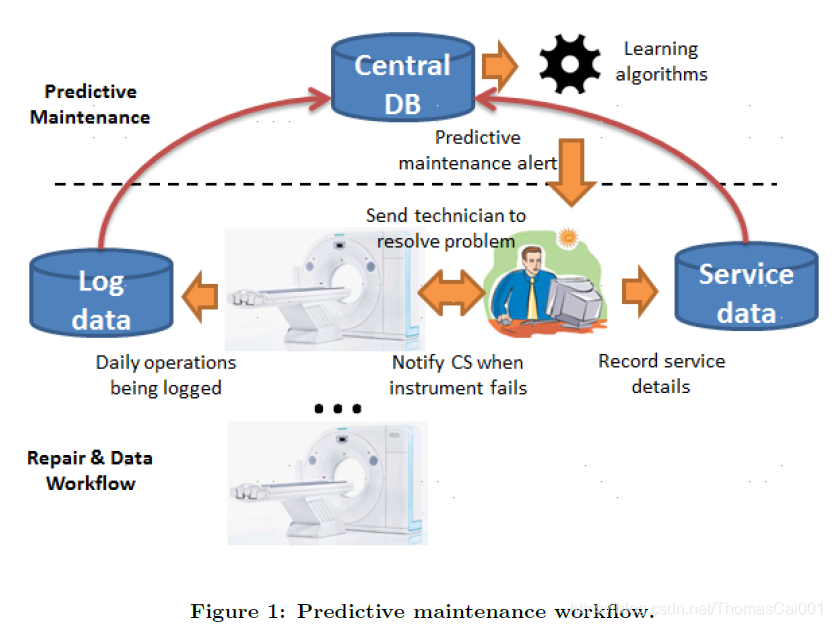
2.3 必要条件
该领域专家提出几个必要条件,是的基于log的预测维护方案是可行的和有用的。
- 时间预警方面:
- 预测空间:在事故发生前一段时间;
- 损伤空间:在事故发生后,设备处于罢工且于维修中;
- 响应时间:发现警告所需时间。
- 正确的和错误的正类:
- 评判标准:
这里很简单直接贴图了。

(说明: True positive指的是预测正确的类,也就是说应该是警告的地方;反之False positive是预测错误的类,就是正常的地方给预测错了)
然后有谈到准确率召回率曲线(PM-AUC)分数来作为平衡准确率和召回率的标准(我认为就是F1值吧?)
- 可解释性:方便专家参与到建模的过程中,有助于模型更加有效,而且参与其中后,使用起来更加有效。
- 高效性
- 处理类的不平衡:这里提供了三种方案(1)分层采样(2)稳定的特征选择(3)大量的边缘技术
6 相关工作
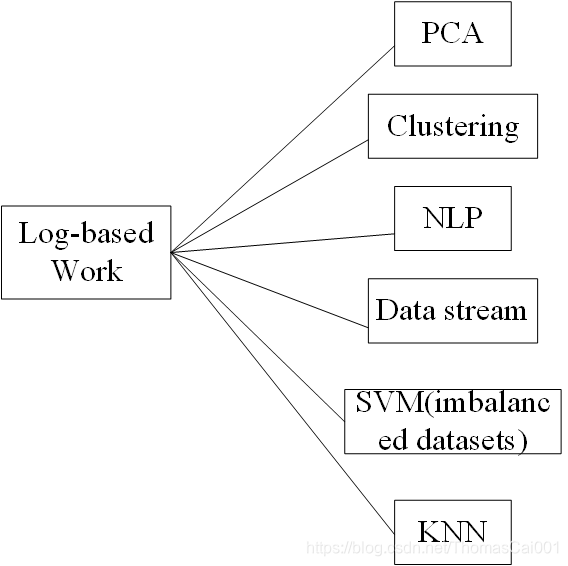
(3方法4实验5影响力就先省略了)
因为这篇文章的具体方法也没怎么讲,因此就先用这篇文章看看日志数据挖掘的流程,算是预言的第一步,接下来我会看一篇SVM的论文,进入到具体的场景,并尝试应用SVM在日志的数据挖掘上。
预告:
SVM文章链接:http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=A46C83887093BD13F2A5886D20F15480?doi=10.1.1.145.5106&rep=rep1&type=pdf


















 359
359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











