




前言
-
coze知识文档搭建的初衷:本人作为小白,实践学习AI和coze等工作流已有大半年的时间,深知作为一个小白从零开始学习的难度不小,并且本人搜索了全网各平台,对coze平台底层原理性介绍、具体详细操作介绍的视频和文档少之又少,但是coze中很多插件又缺乏详细具体使用的介绍,所以结合本地近半年大量的实践经验,希望能够整理一份系统性的coze工作流的知识库文档,并且免费开源供大家使用。
-
coze知识文档搭建的期望:本人期望利用业余时间搭建一个入门小白视角可以使用的、系统性的coze知识文档,已经在持续更新中,具体规模大小还不确认,也许1万字?也许5万字?(先给自己定一个小目标哈哈哈🤣)总而言之,就是希望将自己实践的经验,可以开源分享给大家使用,大家也可以评论或添加我的微信,一起讨论更好的coze使用的方案
本文档仅为其中一小部分的介绍,为了方便大家咨询问题、讨论或者获取更多coze教程,也可以添加我的微信,希望可以和大家一起共建一个coze讨论社区!!
微信:xiaoxiongAI25

文章飞书云文档源链接:【小白使用视角】coze多维表格插件数据格式转换方法系统性介绍
文档正式内容:
一、coze多维表格插件数据格式的背景
1. 前述讲到从多维表格搜索记录插件获取的数据,其对应的数据格式是字符串,字符串里面包了json对象的数据,我们实际上是要拿到json对象的数据,才能方便后续其他插件的使用。本质上就是要把数据从字符串格式转换成object对象格式。

二、方法一:使用【代码节点】转换多维表格数据格式
1. 工作流全流程
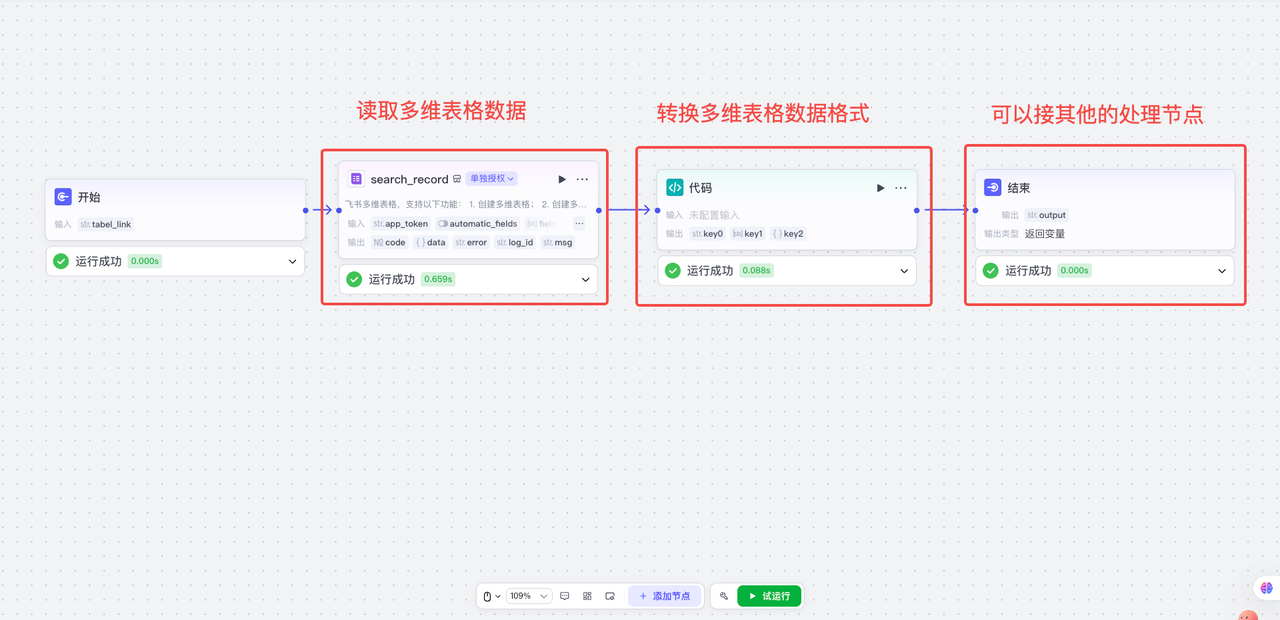
2. 代码节点转化格式的操作方法
1. 直接编写python代码,把字符串格式转换为object对象格式,或数组(object对象格式)
2. 【重点推荐,对新手友好】——AI写代码,亲测按照以下顺序操作,代码一次运行成率高达95%以上
3. AI写代码操作步骤
| 步骤 | 说明 | 示例 |
| 在代码节点的输入中,关联上一个多维表格节点输出的变量,选择data数据节点或items数据节点都可以,只不过data数据节点包含的数据会更多,包含了hash_more、page_token数据;如果不需要的话,直接关联上items数据节点也可以 | 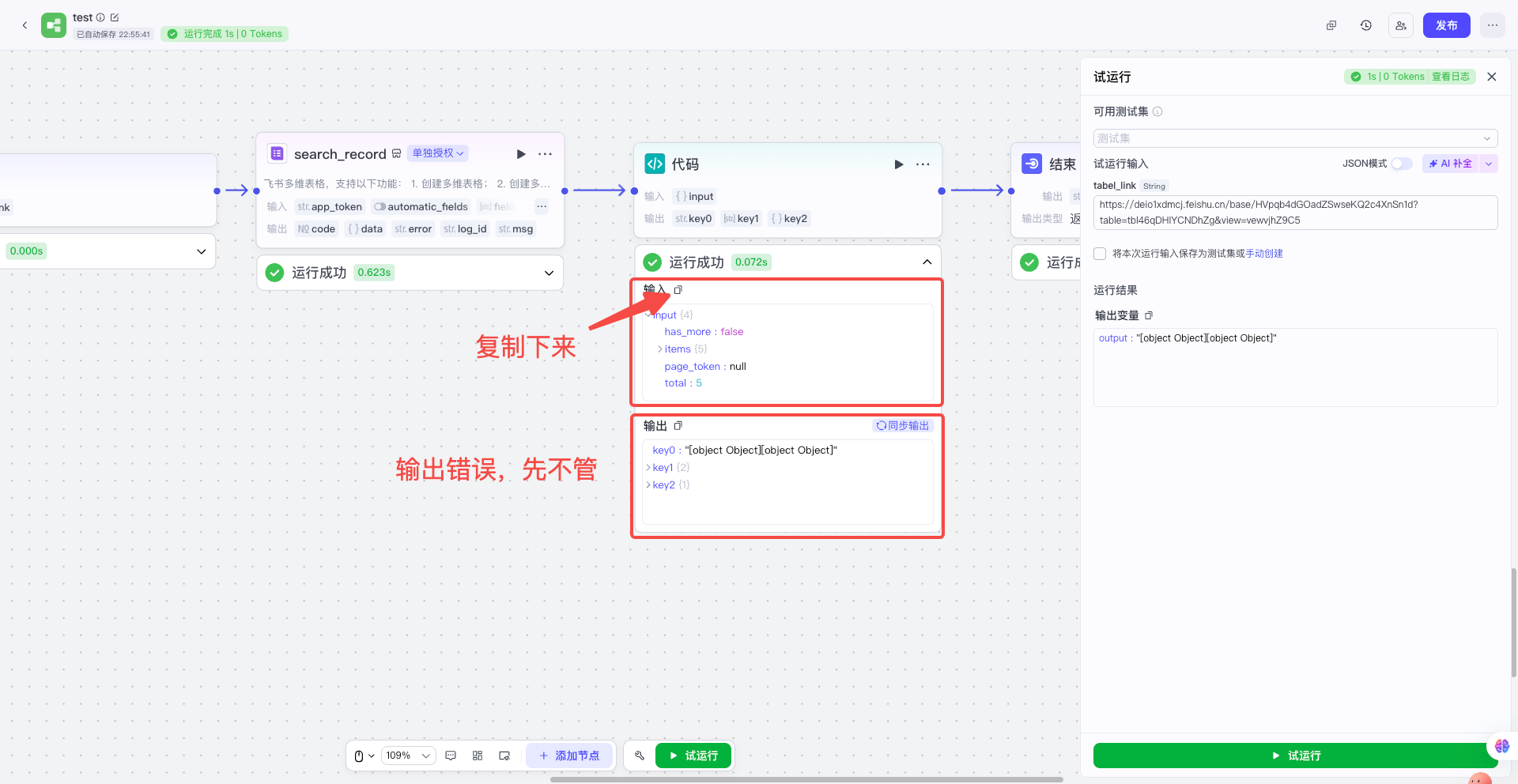 |
| 把其他节点先随便连接上,让整个工作流可以运行起来;然后获取多维表格传给代码节点的真实数据,并且复制下来备用 | 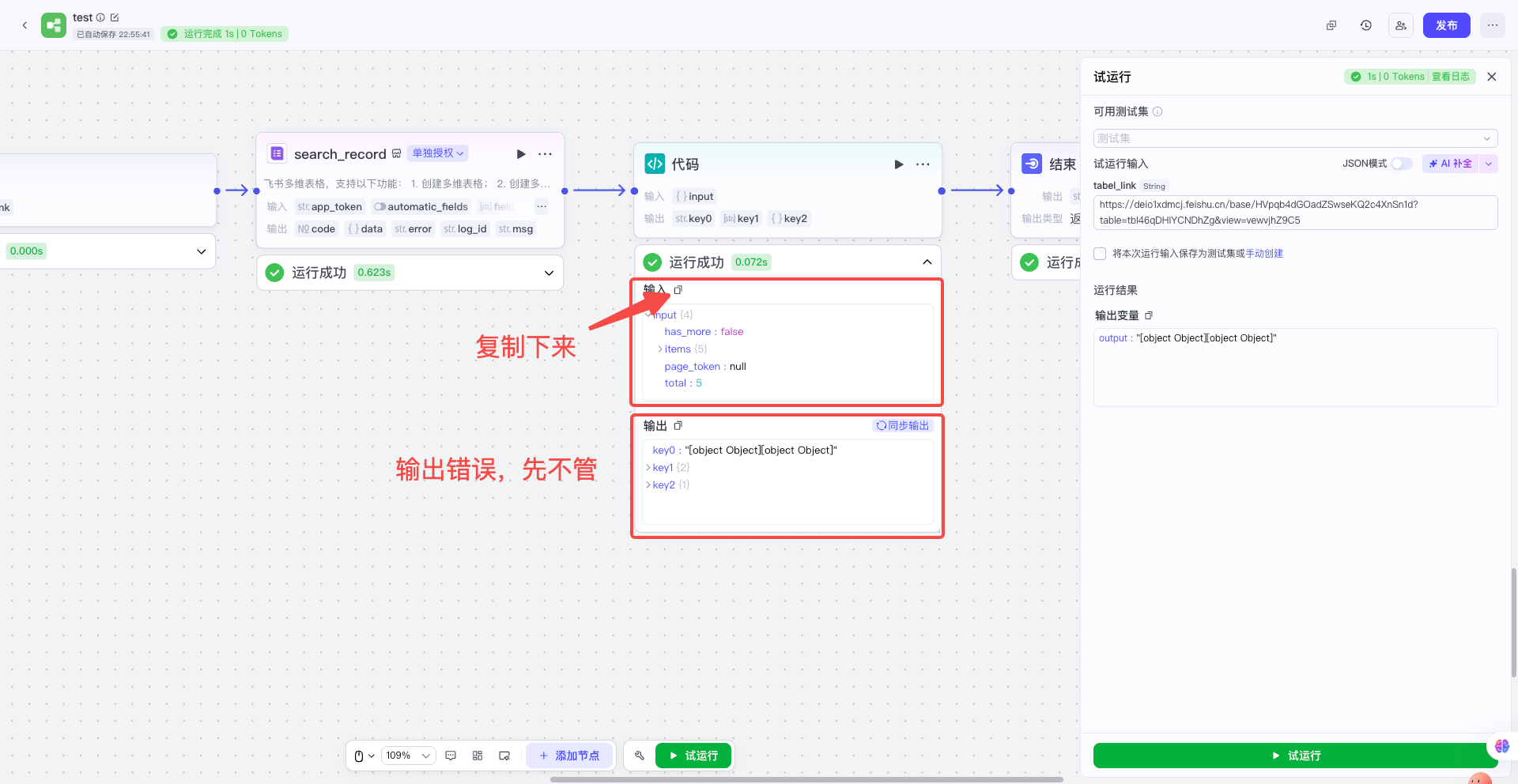 |
| 点开代码节点,点击【在IDE中编辑】,再选择【python】语言,然后把代码框中的所有内容,原封不动的复制下来备用 | 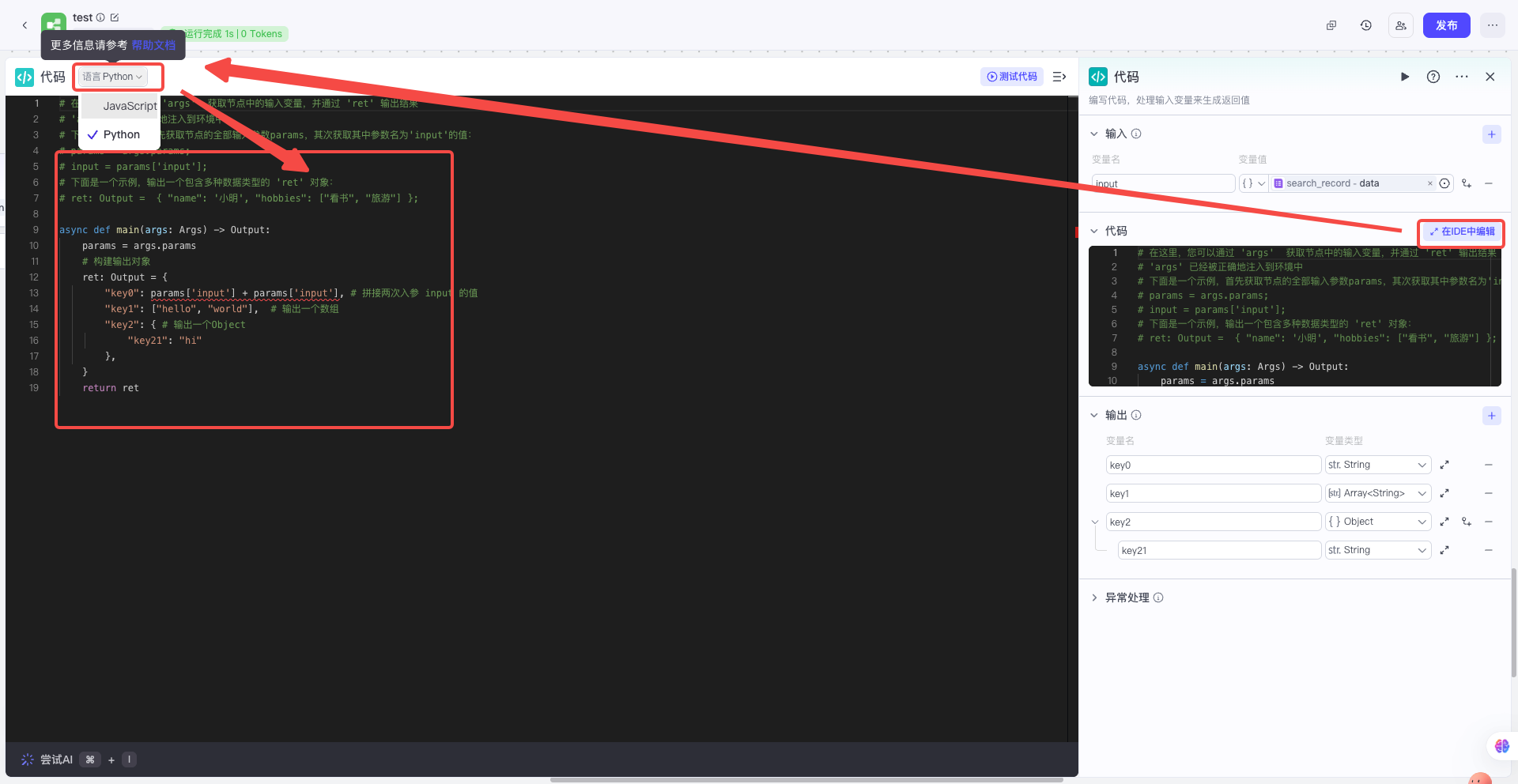 |
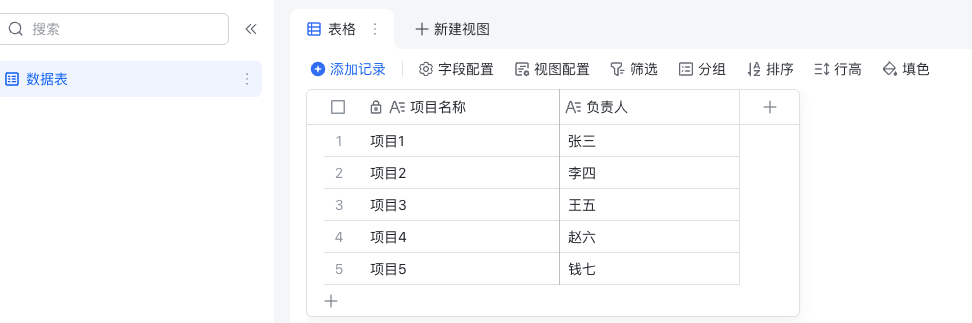
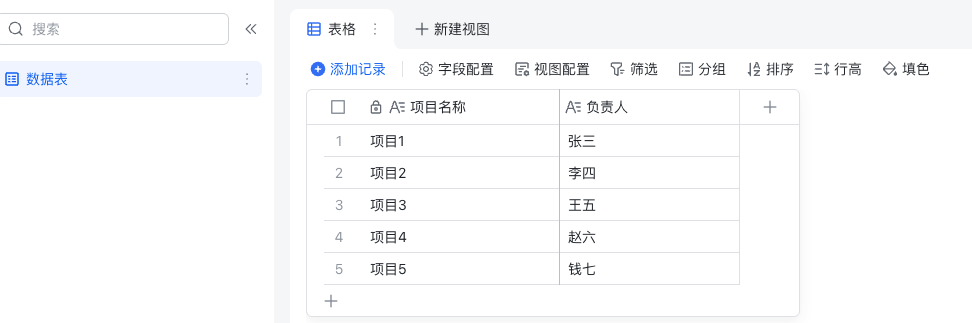
(需要熟悉数据结构类型) | 我们要分析预期要得到的数据格式,然后撰写一个案例出来。比如示例中,多维表格里面是项目名称和负责人两个字段,然后一共5条记录,我们想要把5条记录都输出出来,那么转换成object对象存储的数据格式,并且总共有5条记录,那么一共会有5个object对象,这时候最好又用数组包起来,所以最后要输出的是数组(object对象)格式。如下: {"data": [ "fields" :{"负责人" : "张三", "项目名称" : "项目1" }, "fields" :{"负责人" : "李四", "项目名称" : "项目2" }, ... ] } | 示例多维表格记录
预期输出的结构
|
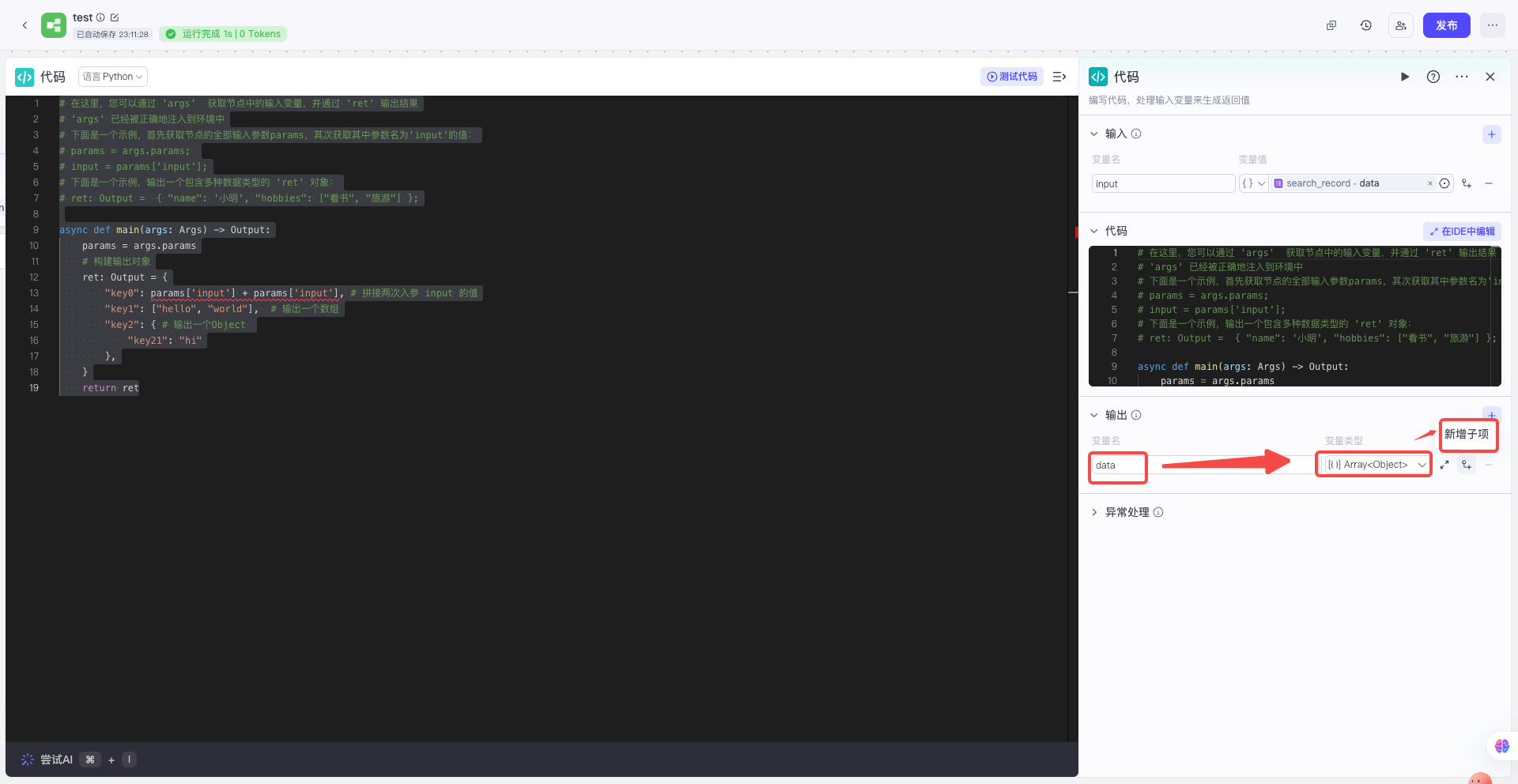
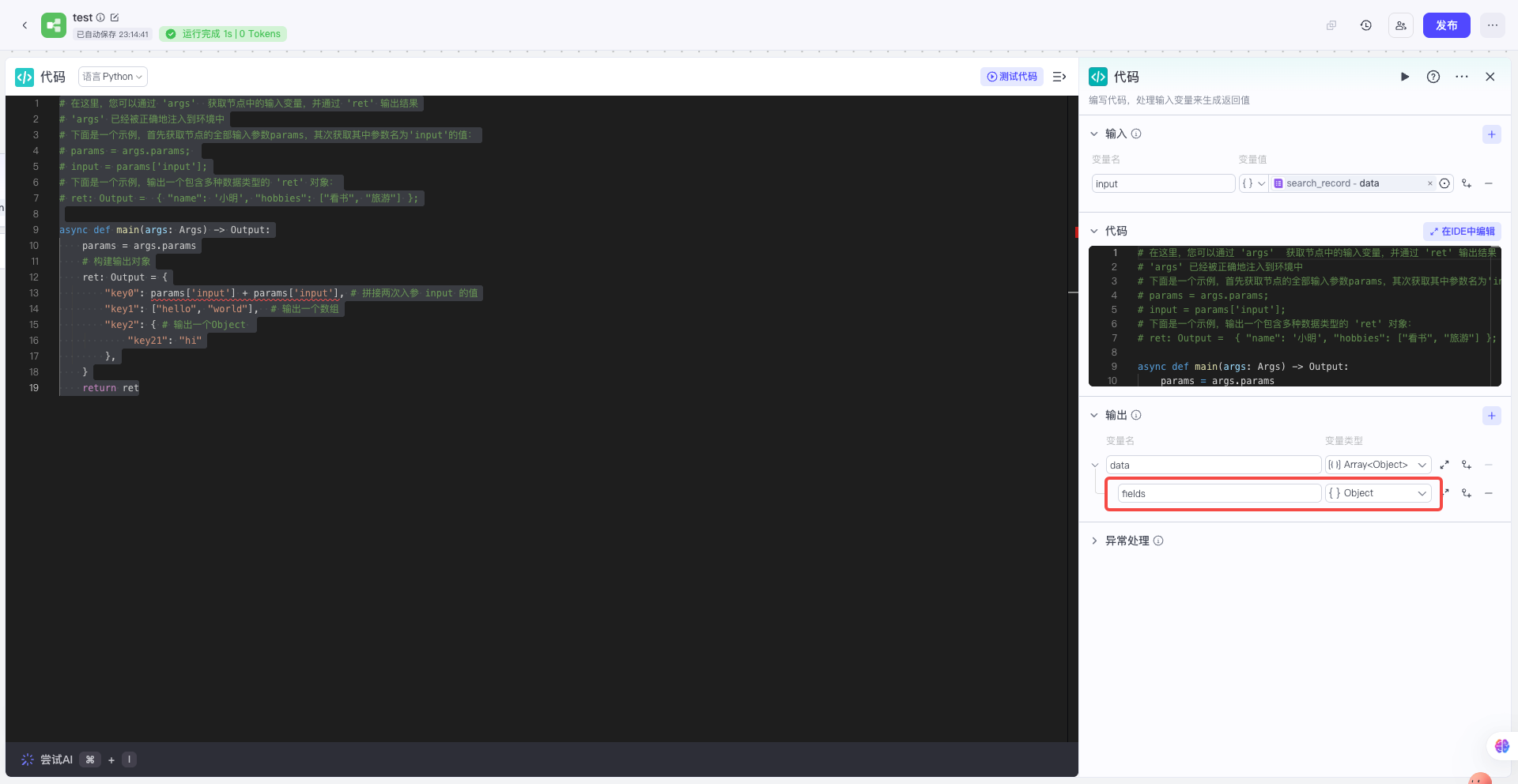
| 对照上面预期的输出结构,在代码节点配置变量名称和变量类型
|
|
| 提示词包含4个部分:
(详细提示词见附录) 然后把代码给Deepseek运行。 代码一次运行成功!!! | 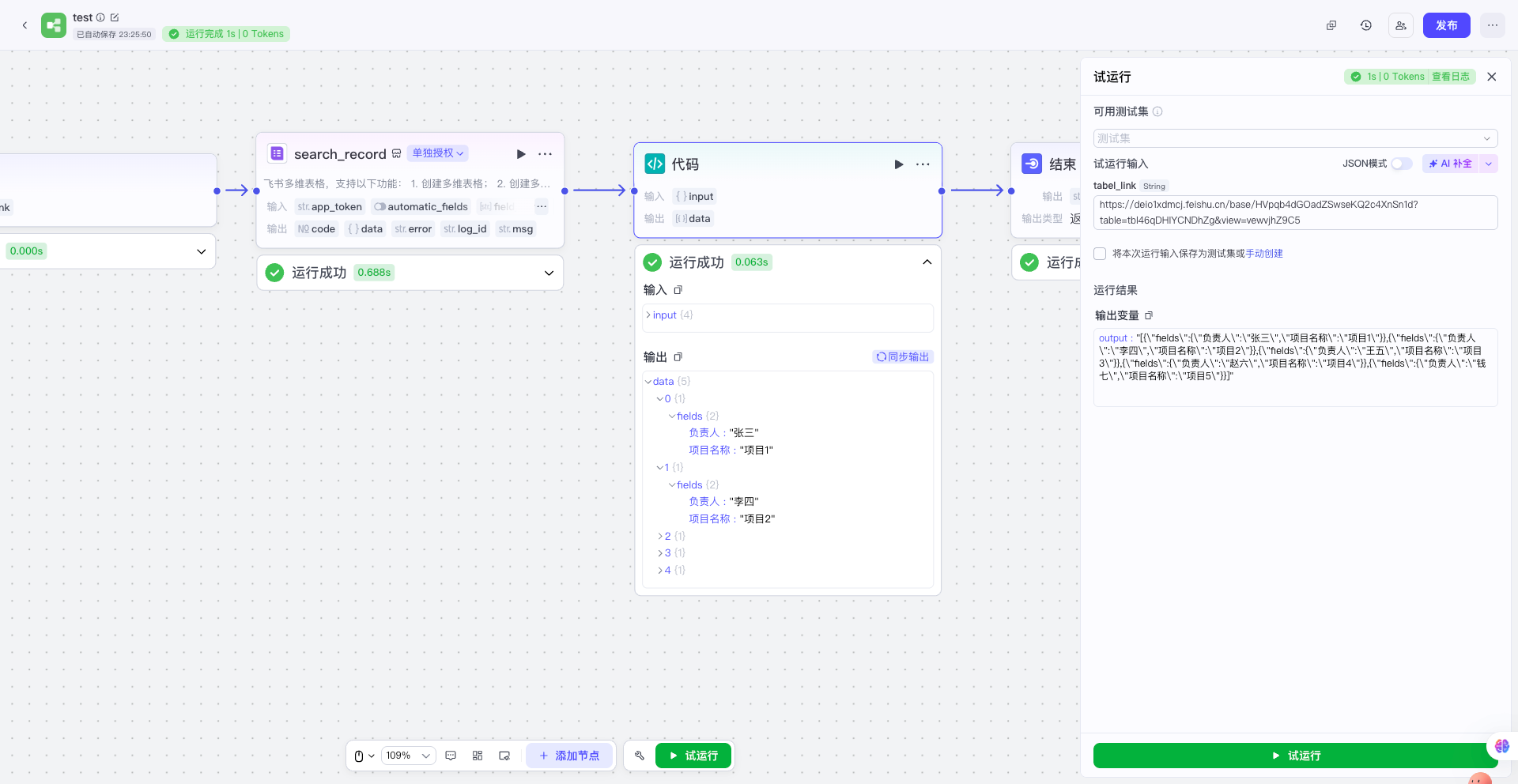 |

三、方法二:使用【大模型节点】转换多维表格数据格式
1. 工作流全流程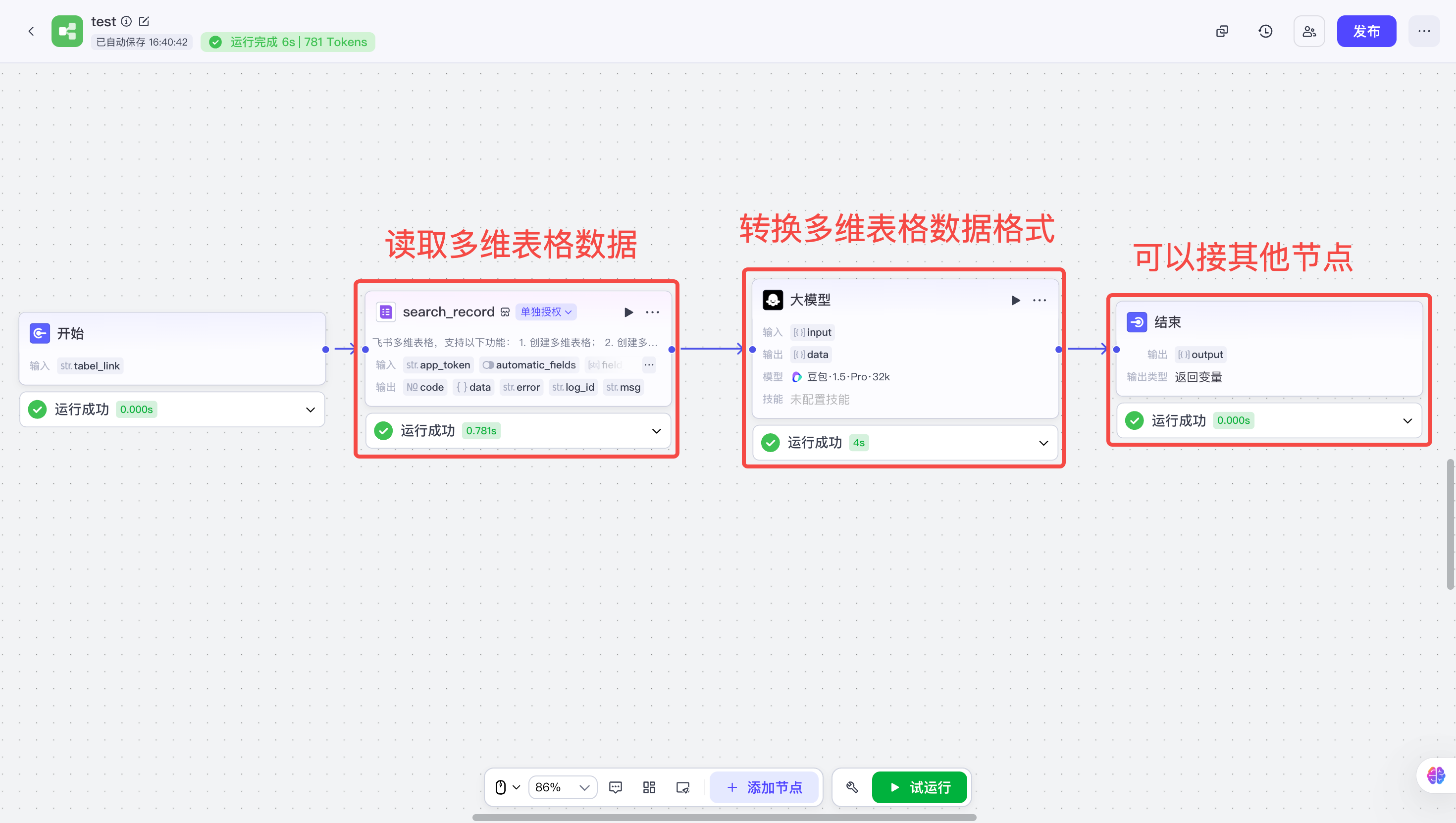
2. 大模型转换代码格式的操作步骤
| 步骤 | 说明 | 示例 |
| 在大模型节点的输入中,关联上一个多维表格节点输出的变量,选择data数据节点或items数据节点都可以,只不过data数据节点包含的数据会更多,包含了hash_more、page_token数据;如果不需要的话,直接关联上items数据节点也可以 | 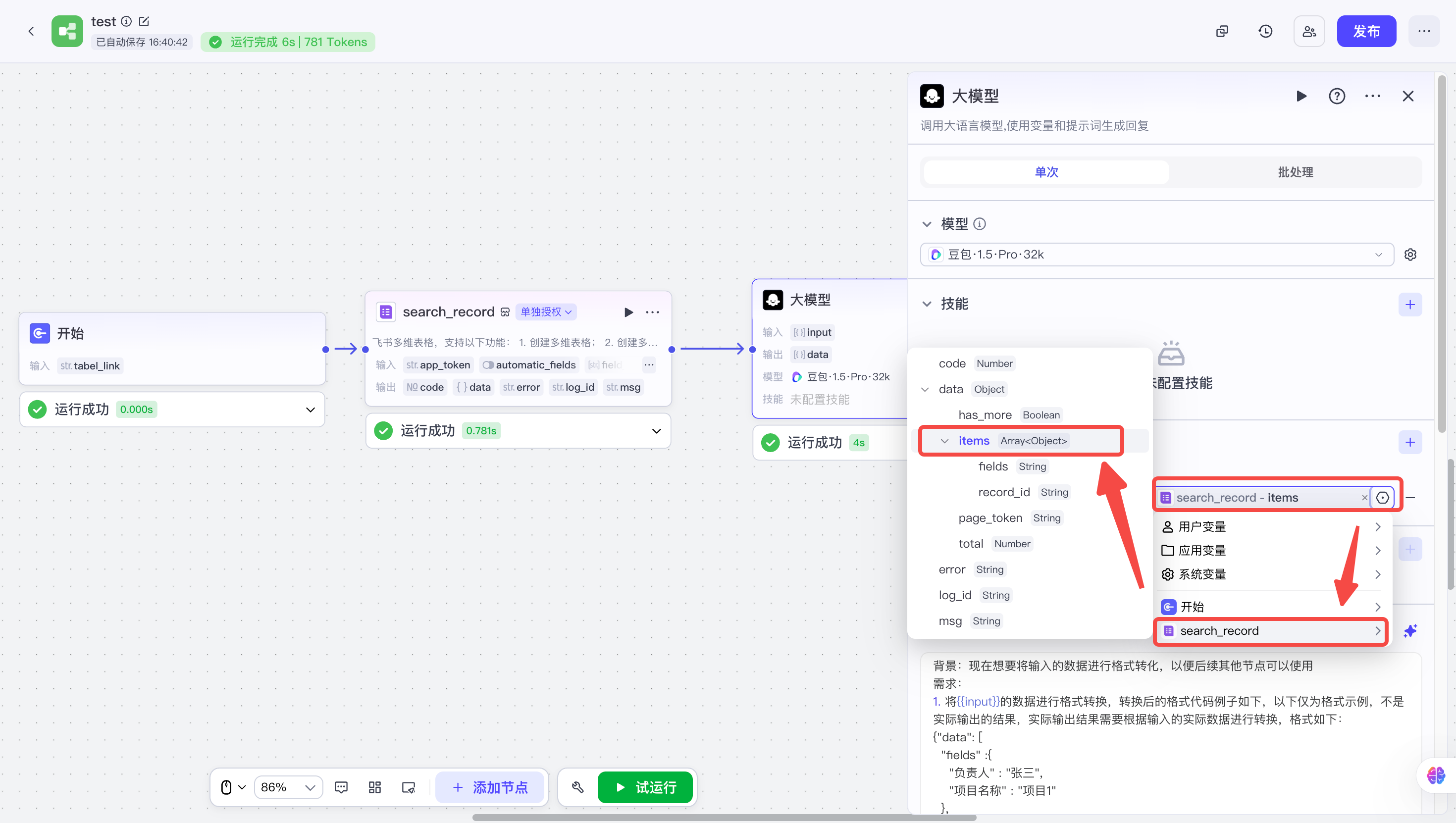 |
| 把其他节点先随便连接上,先使用少量数据,让整个工作流可以运行起来;然后获取多维表格传给代码节点的真实数据,并且复制下来备用 | 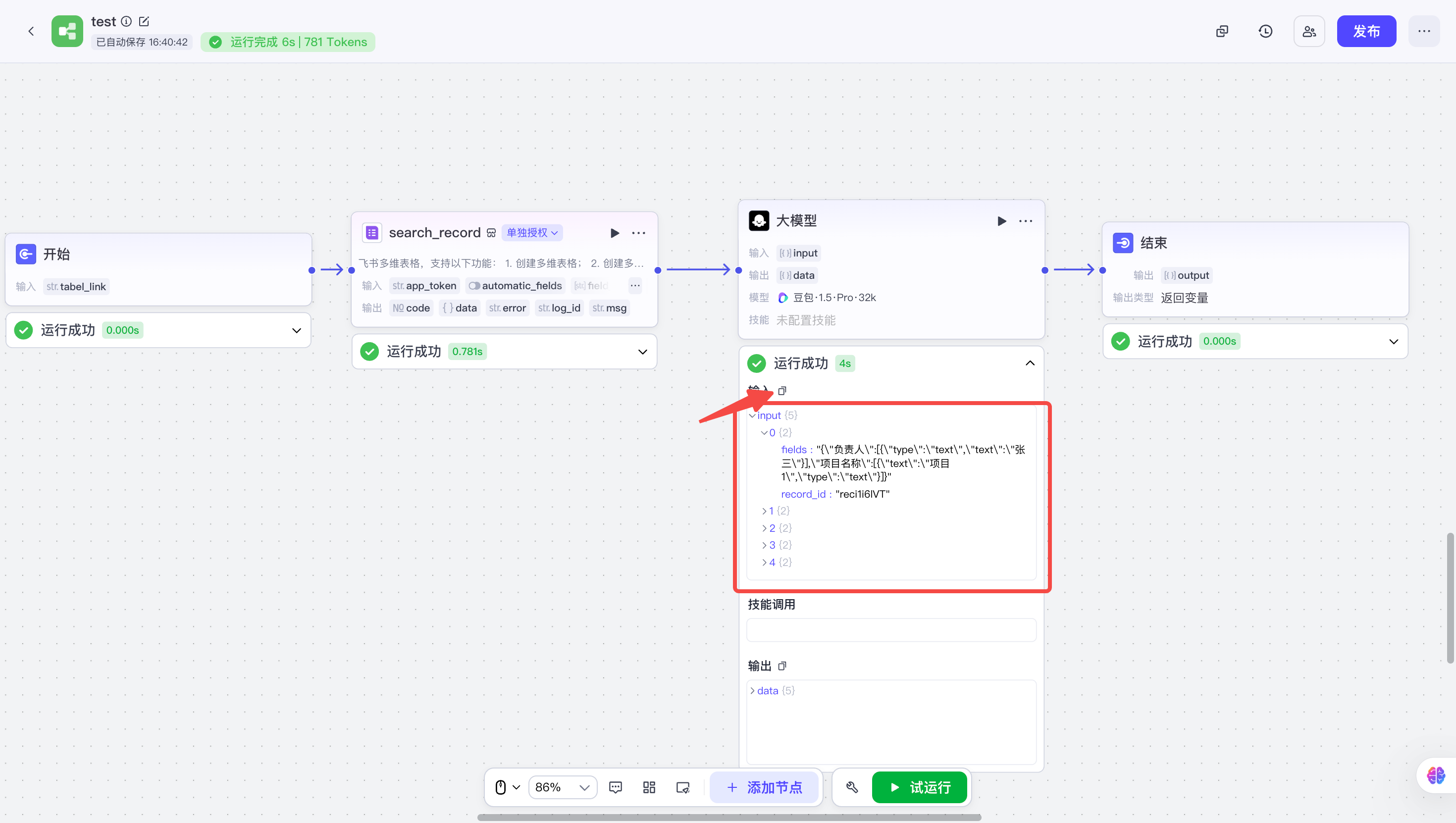 |
(需要熟悉数据结构类型) | 我们要分析预期要得到的数据格式,然后撰写一个案例出来。比如示例中,多维表格里面是项目名称和负责人两个字段,然后一共5条记录,我们想要把5条记录都输出出来,那么转换成object对象存储的数据格式,并且总共有5条记录,那么一共会有5个object对象,这时候最好又用数组包起来,所以最后要输出的是数组(object对象)格式。如下: {"data": [ "fields" :{"负责人" : "张三", "项目名称" : "项目1" }, "fields" :{"负责人" : "李四", "项目名称" : "项目2" }, ... ] } | 示例多维表格记录
预期输出的结构 |
| 提示词包含4个部分:
(详细提示词见附录) |  |

四、使用建议
优先建议使用【代码节点】,稳定性较高;如果实在不会代码使用和调试,再使用大模型节点。
| 优点 | 缺点 | |
| 代码节点 |
|
|
| 大模型节点 |
|
|
五、附录
1. 多维表格数据格式转换代码Prompt
一、提示词Prompt
需求:我现在正在使用coze的代码节点进行数据格式转换,输入的数据见下述第一点,输出的格式见下述第二点。你需要严格遵循下述第3点代码节点示例代码的逻辑和格式要求,给出完整的python代码,不要有任何的遗漏!!
1. 输入的数据
{
"input": {
"has_more": false,
"items": [
{
"fields": "{\"负责人\":[{\"type\":\"text\",\"text\":\"张三\"}],\"项目名称\":[{\"text\":\"项目1\",\"type\":\"text\"}]}",
"record_id": "reci1i6lVT"
},
{
"fields": "{\"负责人\":[{\"text\":\"李四\",\"type\":\"text\"}],\"项目名称\":[{\"text\":\"项目2\",\"type\":\"text\"}]}",
"record_id": "recgmbJpp6"
},
{
"fields": "{\"项目名称\":[{\"text\":\"项目3\",\"type\":\"text\"}],\"负责人\":[{\"text\":\"王五\",\"type\":\"text\"}]}",
"record_id": "reczTt3gr4"
},
{
"fields": "{\"负责人\":[{\"text\":\"赵六\",\"type\":\"text\"}],\"项目名称\":[{\"text\":\"项目4\",\"type\":\"text\"}]}",
"record_id": "rec95bxK8Y"
},
{
"fields": "{\"负责人\":[{\"text\":\"钱七\",\"type\":\"text\"}],\"项目名称\":[{\"text\":\"项目5\",\"type\":\"text\"}]}",
"record_id": "recU8qlUbN"
}
],
"page_token": null,
"total": 5
}
}
2. 预期输出的数据格式(仅为格式示意,具体输出内容以输入的数据为准)
{"data": [
"fields" :{
"负责人" : "张三",
"项目名称" : "项目1"
},
"fields" :{
"负责人" : "李四",
"项目名称" : "项目2"
}
]
}
3. 代码节点的示例代码
'''python
# 在这里,您可以通过 'args' 获取节点中的输入变量,并通过 'ret' 输出结果
# 'args' 已经被正确地注入到环境中
# 下面是一个示例,首先获取节点的全部输入参数params,其次获取其中参数名为'input'的值:
# params = args.params;
# input = params['input'];
# 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
# ret: Output = { "name": '小明', "hobbies": ["看书", "旅游"] };
async def main(args: Args) -> Output:
params = args.params
# 构建输出对象
ret: Output = {
"key0": params['input'] + params['input'], # 拼接两次入参 input 的值
"key1": ["hello", "world"], # 输出一个数组
"key2": { # 输出一个Object
"key21": "hi"
},
}
return ret
'''
二、Deepseek输出的代码
根据需求,我将严格按照代码节点示例的逻辑和格式编写转换代码。以下是完整的解决方案:
async def main(args: Args) -> Output:
params = args.params
input_data = params['input']
# 构建输出数据结构
data_list = []
# 处理每个item
for item in input_data['items']:
# 解析fields字符串为字典
fields_dict = eval(item['fields'])
# 提取字段值
processed_fields = {}
for field_name, field_list in fields_dict.items():
# 取列表中第一个元素的text值
if field_list and isinstance(field_list, list) and field_list[0].get('text'):
processed_fields[field_name] = field_list[0]['text']
# 构建fields对象
data_list.append({"fields": processed_fields})
# 构建最终输出
ret: Output = {"data": data_list}
return ret
**代码说明:**
1. **输入获取**:
- 通过 `params = args.params` 获取所有输入参数
- 使用 `input_data = params['input']` 获取输入数据
2. **数据处理**:
- 初始化 `data_list` 作为输出列表
- 遍历输入中的每个 `item`
- 使用 `eval()` 将 `fields` 字符串解析为字典
- 提取每个字段的第一个元素的 `text` 值
- 构建符合要求的 `fields` 对象
3. **输出构建**:
- 将每个处理后的 `fields` 对象添加到 `data_list`
- 最终返回 `{"data": data_list}` 格式
**注意事项:**
- 严格遵循了示例代码的异步函数格式和类型注解
- 使用 `eval()` 处理 JSON 字符串(实际使用中建议替换为 `json.loads()`)
- 处理了字段顺序不一致的情况(如第三个项目)
- 包含空值检查和类型验证
- 输出格式完全符合需求示例
此代码将输入数据转换为指定的输出格式,保留了所有原始数据项,并正确处理了字段值提取。2. 多维表格数据格式大模型节点提示词
背景:现在想要将输入的数据进行格式转化,以便后续其他节点可以使用
需求:
1. 将{{input}}的数据进行格式转换,转换后的格式代码例子如下,以下仅为格式示例,不是实际输出的结果,实际输出结果需要根据输入的实际数据进行转换,格式如下:
{"data": [
"fields" :{
"负责人" : "张三",
"项目名称" : "项目1"
},
"fields" :{
"负责人" : "李四",
"项目名称" : "项目2"
},
...
]
}
2. 需要做异常情况的兼容,如果输入的数据为空或其他分析异常,请不要中止执行,而是要按照上述第一点的数据结构输出,只是具体的值为空,例子如下:
{"data": [
"fields" :{
"负责人" : " ",
"项目名称" : " "
},
"fields" :{
"负责人" : " ",
"项目名称" : " "
},
...
]
}
















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









