







java
GC
分代假设:大部分新生对象很快无用,存活较长时间的对象,可能存活更长时间。经历了15次GC还存在的就放在老年代.新生代80%,S0,S1各10%新生代到存活区是复制,到老年代是移动。
-XX: +MaxTenuringThreshold=15 表示15次后放到老年代。
可以做为GC ROOT的对象
- 当前正在执行的方法里的局部变量和输入参数
- 活动线程
- 所有类的静态字段
- JNI引用
Serial GC/ParNewGC
-XX: +UseSerialGC开启
对年轻代使用mark-copy算法,对老年代使用mark-sweep-compact算法
串行GC不能并行处理,所以触发全部暂停(STW)
ParNewGC可以配合CMSGC使用
适用场景:
- 单线程应用或资源有限的环境(如嵌入式系统)。
- 小型应用,不需要频繁的垃圾回收。
java版本19,测试GC效率
命令
java -XX:+UseSerialGC -Xms128m -Xmx128m -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
效果。可以看到当分配128m内存的时候,频繁触发GC,最终还是OOM,说明堆大小设置的太小了。
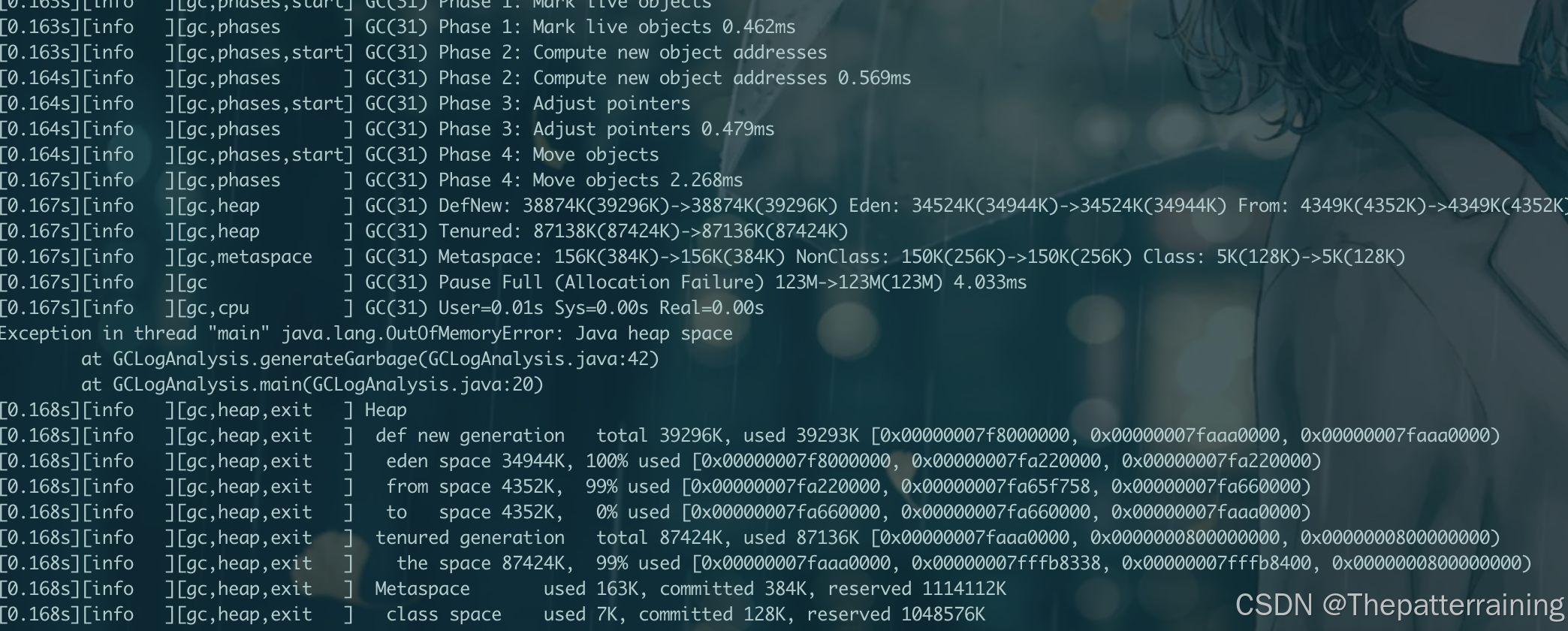
接下来试试512m堆大小
java -XX:+UseSerialGC -Xms512m -Xmx512m -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
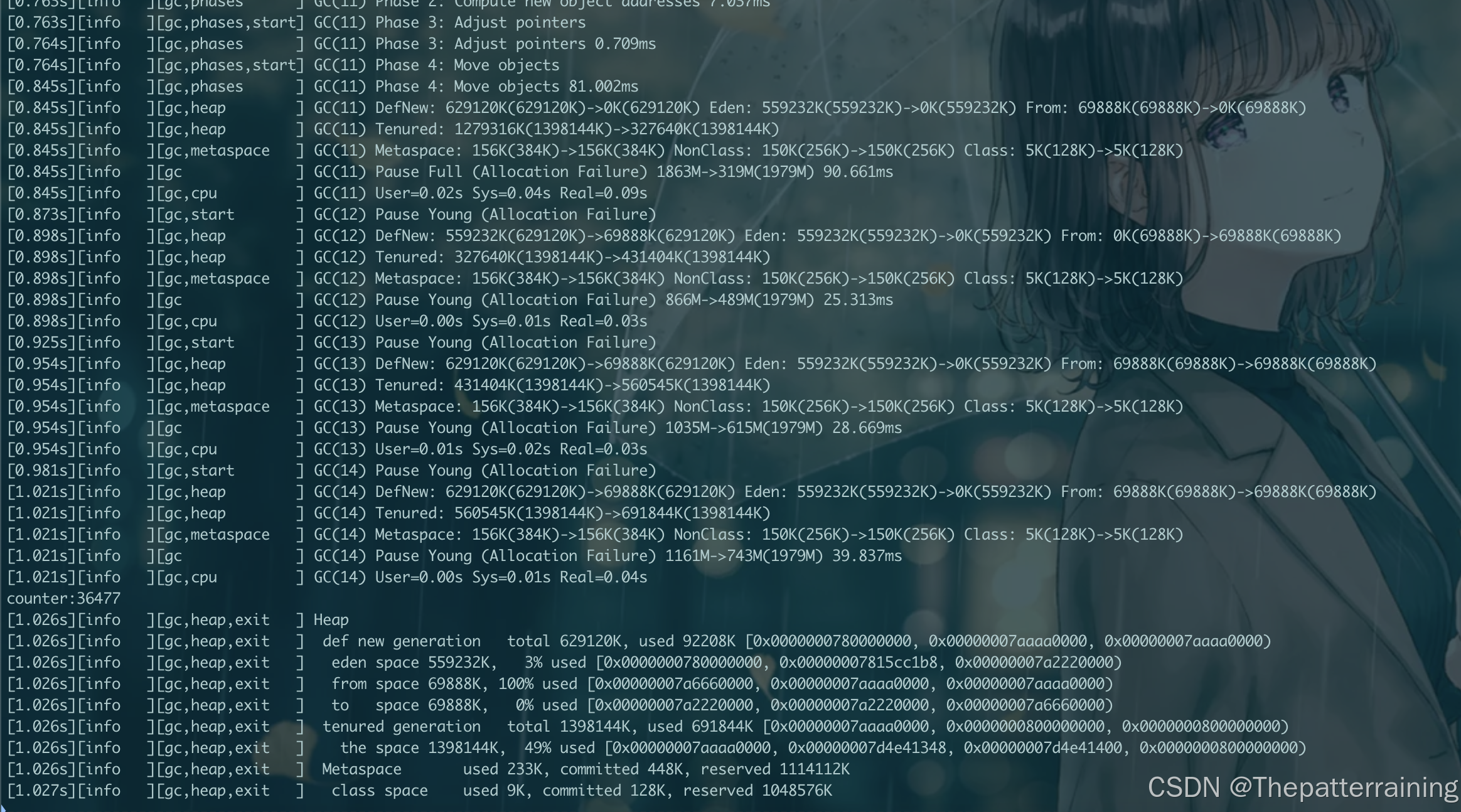
可以看到效果,前面几次yong GC后,触发了很多次full GC,最终成功运行,但是时间很长
再试试1G内存呢
java -XX:+UseSerialGC -Xms1g -Xmx1g -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
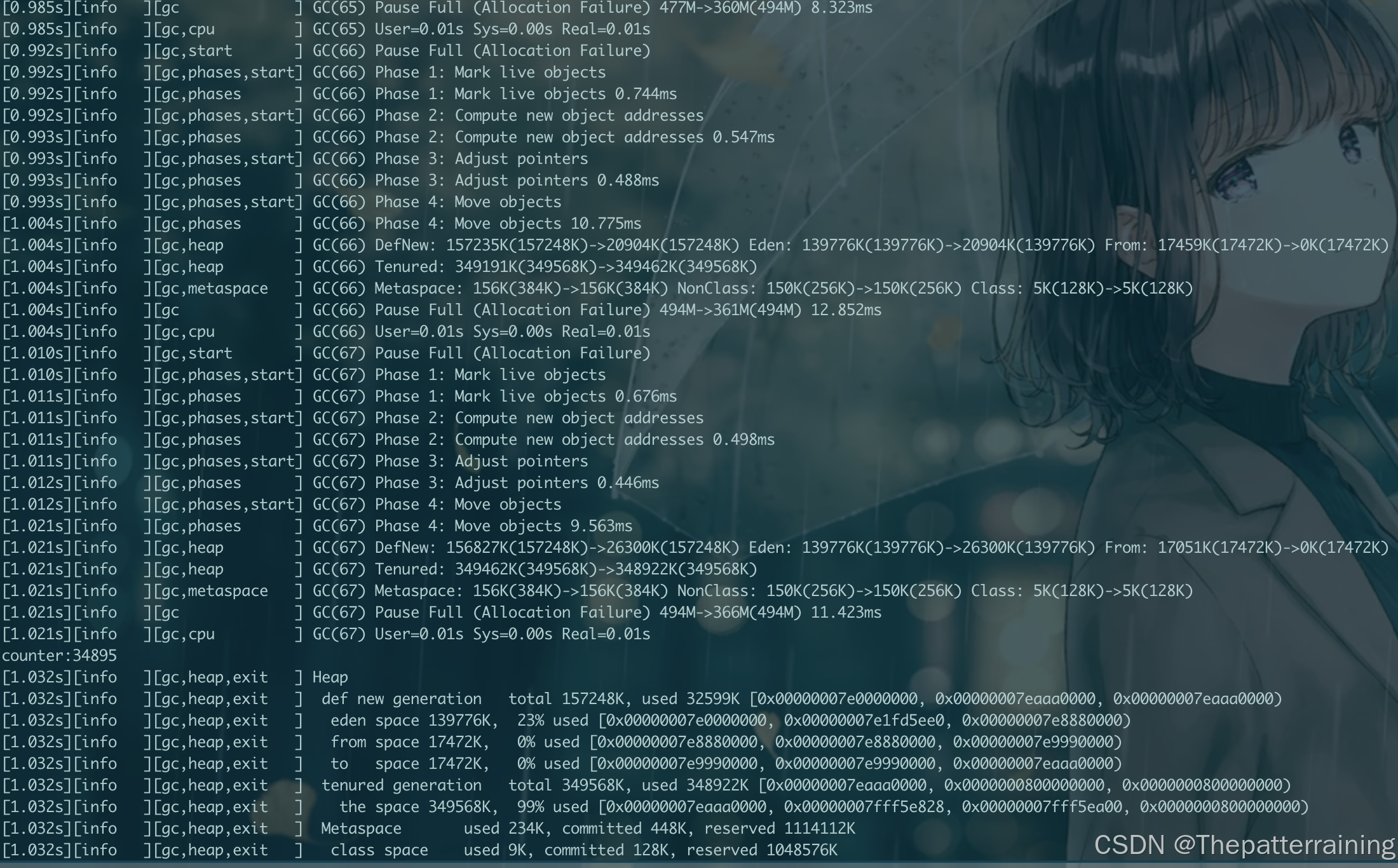
可以看到GC次数大大减少,效率提升,512m的时候生成了30000多个对象,1g的时候生成了33000多个对象
接下来试试2g内存
java -XX:+UseSerialGC -Xms2g -Xmx2g -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
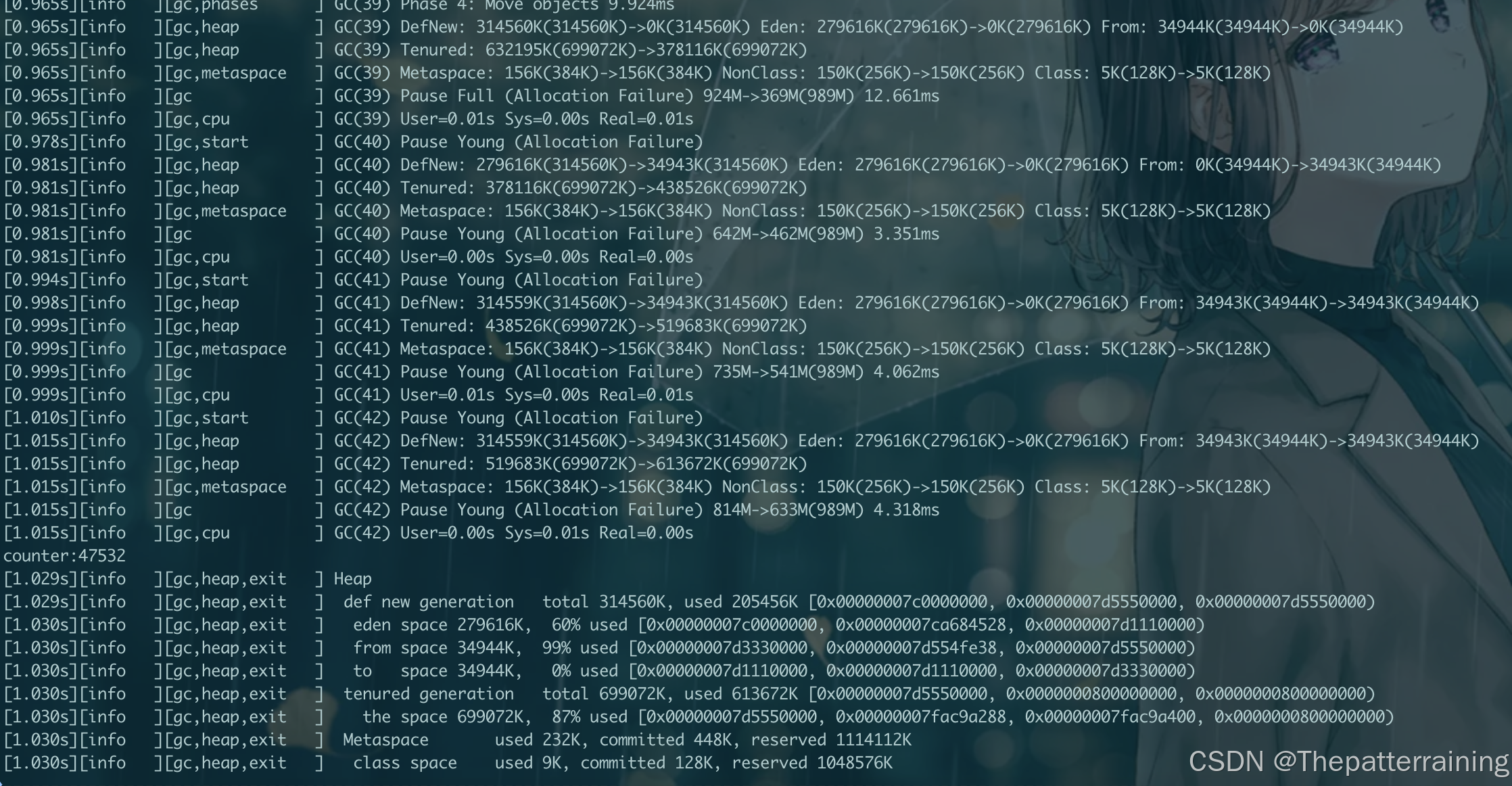
可以看到GC次数减少了一半,生成了36000多个对象。性能再次提升
Parallel GC
目标是最大化应用程序运行时间(吞吐量),最小化 GC 时间。还是会短暂的暂停业务。需要业务能接受短暂的暂停。
-XX: +UseParallelGC
-XX: +UseParallelOldGC 这个在java9以上已经被移除
年轻代和老年代GC都会触发STW事件。
对年轻代使用mark-copy算法,对老年代使用mark-sweep-compact算法
-XX: ParallelGCThreads=N 来指定GC线程数,默认值为CPU核心数。
优点:
- 多线程回收显著提高了回收效率,适合多核环境。
- 停顿时间较 Serial GC 短。
- 两次GC之间不消耗系统资源。
缺点:
- GC 停顿仍然是全暂停(STW)。
- 不适合对延迟要求苛刻的场景。
适用场景:
- 需要高吞吐量的大型后台任务(如批处理、数据分析)。
- 多核 CPU 环境。
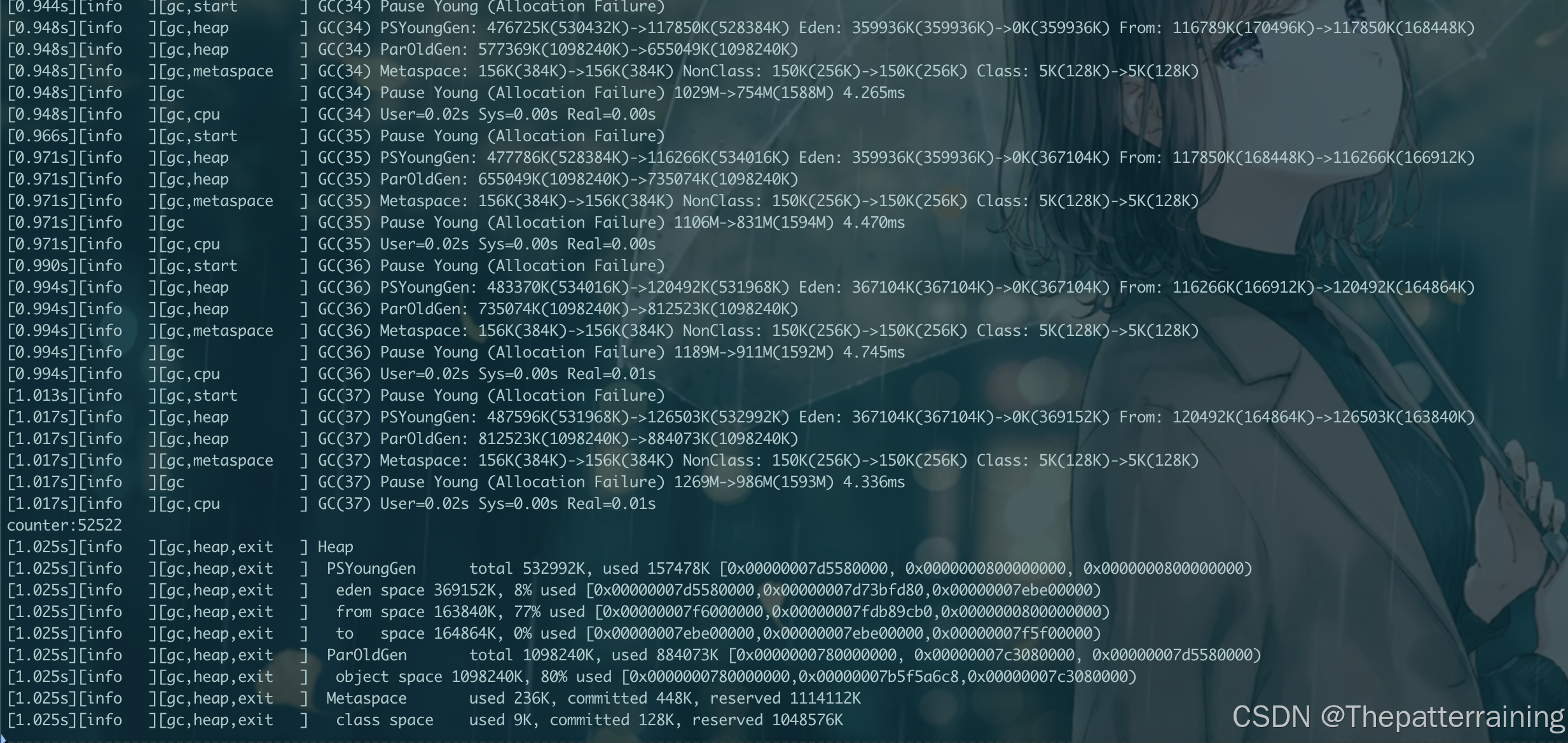
接下来试试并行GC 128m内存
java -XX:+UseParallelGC -Xms128m -Xmx128m -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
结果同样OOM,但是仅仅GC了16次,串行GC了25次,花了0.162s才OOM,而并行GC花了0.108s
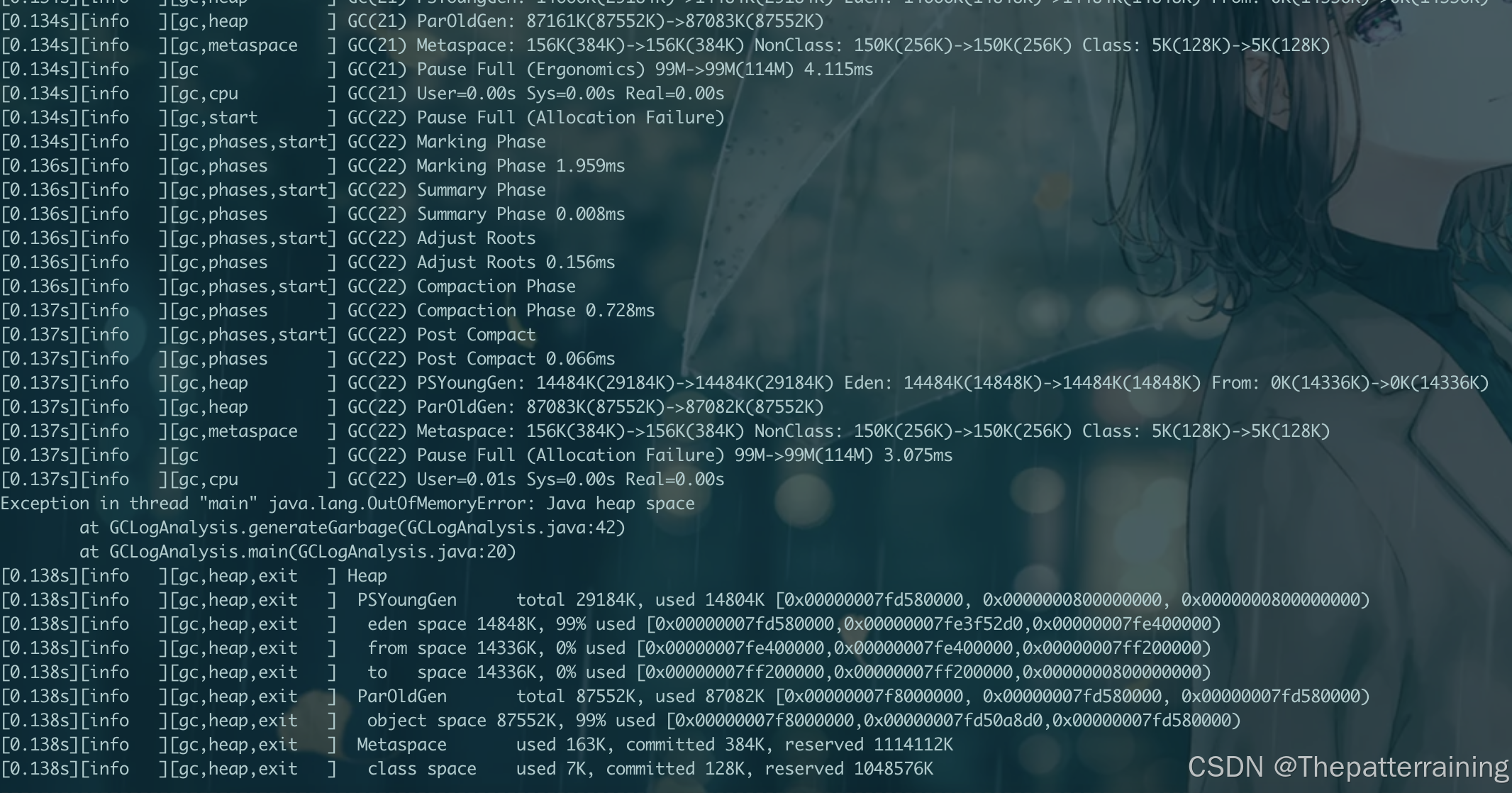
接下来试试512m
java -XX:+UseParallelGC -Xms512m -Xmx512m -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
可以发现GC次数大大增加了,吞吐量也降低了。27000多个对象,99次GC。
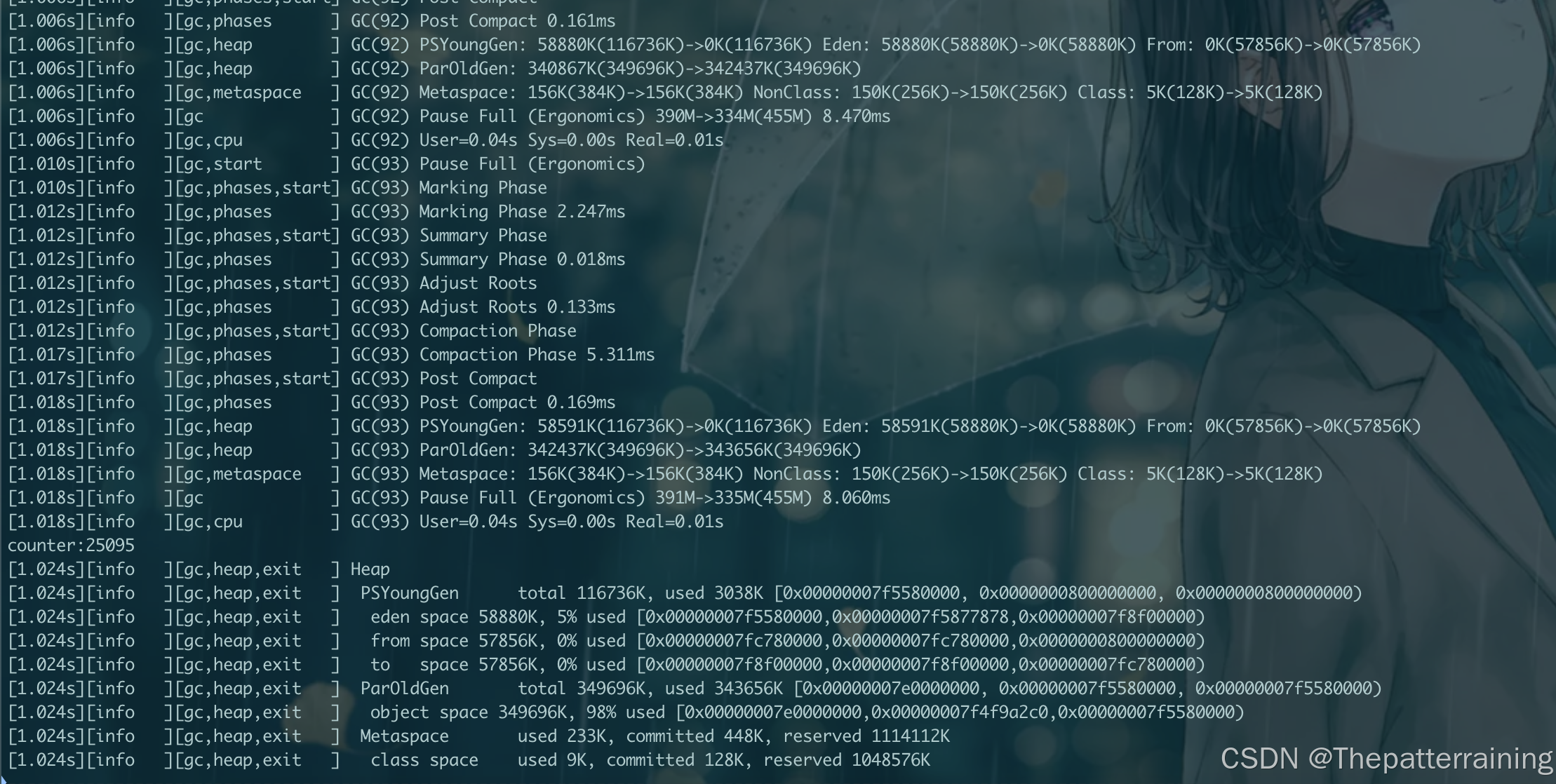
再来试试1g内存
java -XX:+UseParallelGC -Xms1g -Xmx1g -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
跟串行GC相比,GC次数增加,但是吞吐量也增加了很多,串行GC生成了33000多个对象,而并行GC生成了50000多个对象。有明显提升。
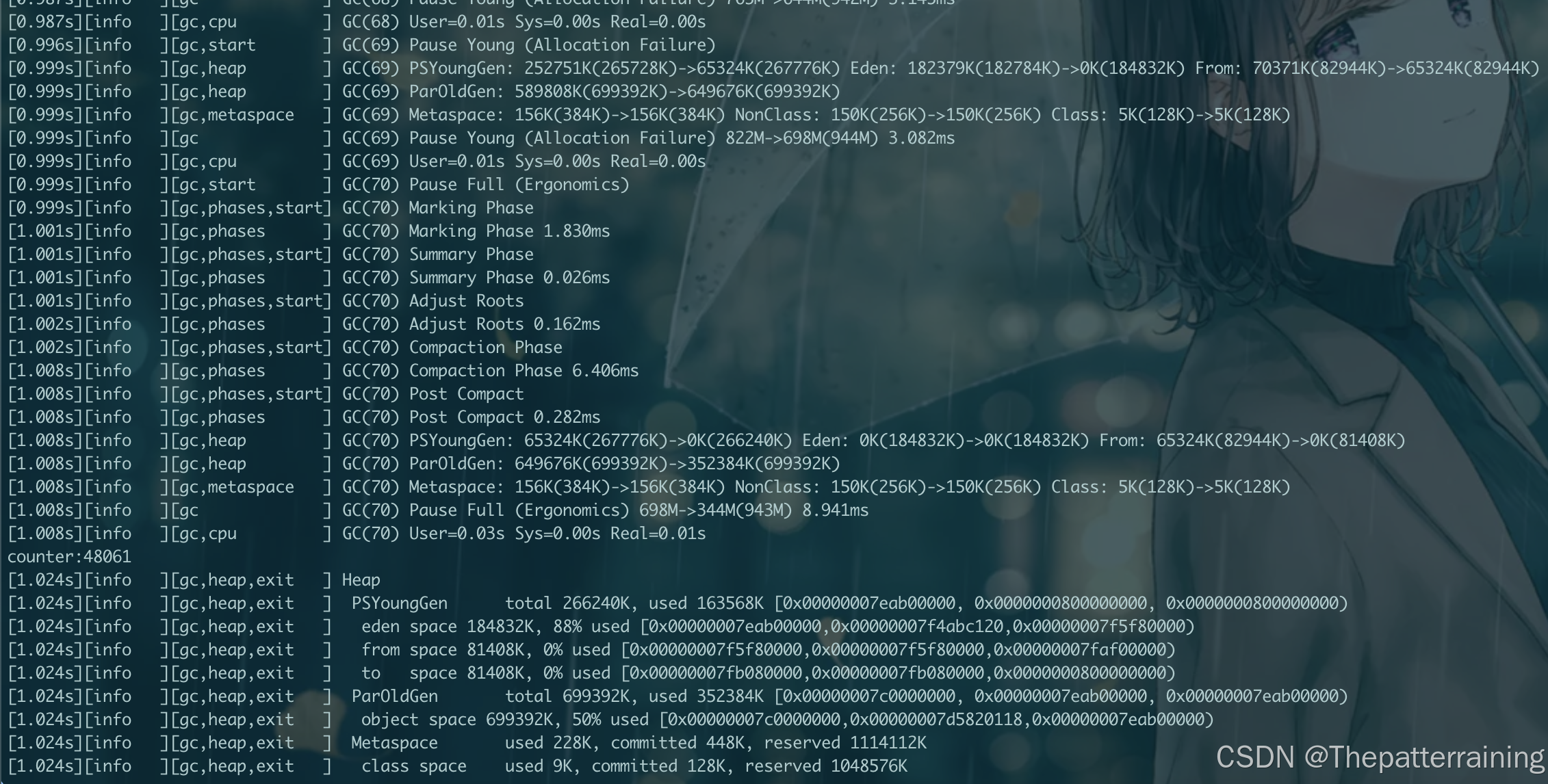
在试试2g内存
java -XX:+UseParallelGC -Xms2g -Xmx2g -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
可以发现跟1g内存相比,GC次数大大减少,但是吞吐量并没有明显增加。仅仅生成了55000多个对象。但是性能依然比串行GC强大
CMS GC
-XX: +UseConcMarkSweepGC
对年轻代使用STW的mark-copy算法,对老年代主要使用并发的mark-sweep算法。这个GC已经在java14版本被移除了。
设计目标:专为老年代设计,目标是最小化 GC 停顿时间。
- 不对老年代进行整理,而是使用空闲列表来管理内存空间的回收
- 在mark-and-sweep的工作和业务线程并发执行。
默认并发线程数等于CPU核心数的1/4
6个阶段
- 初始标记
- 并发标记
- 并发预清理
- 最终标记
- 并发清楚
- 并发重制
MaxHeapSize是系统的1/4内存
MaxNewSize是MaxHeapSize的1/3
NewSize是系统的1/64
优点:
- 只有yongGC暂停业务。GC 停顿时间短,适合延迟敏感的应用。
- 并发回收利用多核资源减少 STW 时间。
缺点:
- 内存碎片化:CMS 不会整理内存,可能导致分配大对象失败(触发 Full GC)。
- CPU 开销较高:并发阶段可能与用户线程争抢资源。
- 容易产生 “Concurrent Mode Failure”:若老年代空间不足,回退到 Serial GC。
适用场景:
- 延迟敏感的应用(如 Web 服务、在线交易系统)。
- 多核环境下的中大型应用。
G1 GC
分区堆内存:将堆划分为若干独立的固定大小的区域(Region),每个 Region 可充当年轻代、老年代或其他用途。混合回收:通过优先回收包含最多垃圾的 Region(Garbage-First)。并行和并发回收:减少 STW 时间。内置碎片整理机制,避免了 CMS 的碎片化问题。一般一个Region是1M。一部分 Region 保留为 Humongous(H) 区,用于存储超过单个 Region 大小一半的巨型对象。
-XX: +UseG1GC -XX: MaxGCPauseMillis=50
将STW的时间和分布变成可预期和可配置的,可设置某项特定的性能指标,为了达成可预期的指标,有独特的实现。增量方式,每次处理一部分,称为回收集合,每次处理所有的年轻代和部分老年代。能看到哪个块的垃圾多,优先回收他们
处理步骤
- 年轻代模式转移暂停
- 并发标记
- 转移暂停:混合模式
G1GC可能退化成串行GC
- 并发模式失败:增加堆大小
- 晋升失败:
- 巨型对象分配失败:增加内存或增大Region大小
优点:
- 减少内存碎片化。
- 更好地控制 GC 停顿时间,可通过 -XX:MaxGCPauseMillis 调整。
- 自动调节年轻代和老年代的大小。
缺点:
- 实现复杂,配置选项多。
- 内存占用较高,CPU 开销大。
适用场景:
- 需要低延迟的中大型应用。
- 堆内存较大的环境(如 >4GB)。
- 替代 CMS 的推荐选择。
Mixed GC
- 老年代内存使用率达到一定阈值(默认 45%,可通过 -XX:InitiatingHeapOccupancyPercent 调整)。
- 同时回收年轻代和部分老年代。
- 执行
- 标记 GC Roots 直接引用的对象。
- 并发扫描老年代,标记存活对象。
- 处理标记期间新产生的引用变化。
- 根据垃圾优先(Garbage-First)的原则,优先选择包含最多垃圾的 Region。
接下来试试G1 GC 128m内存
java -XX:+UseG1GC -Xms128m -Xmx128m -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
同样GC了103次后发生了OOM,可以看到GC次数很多。时间也很长,花了0.136s
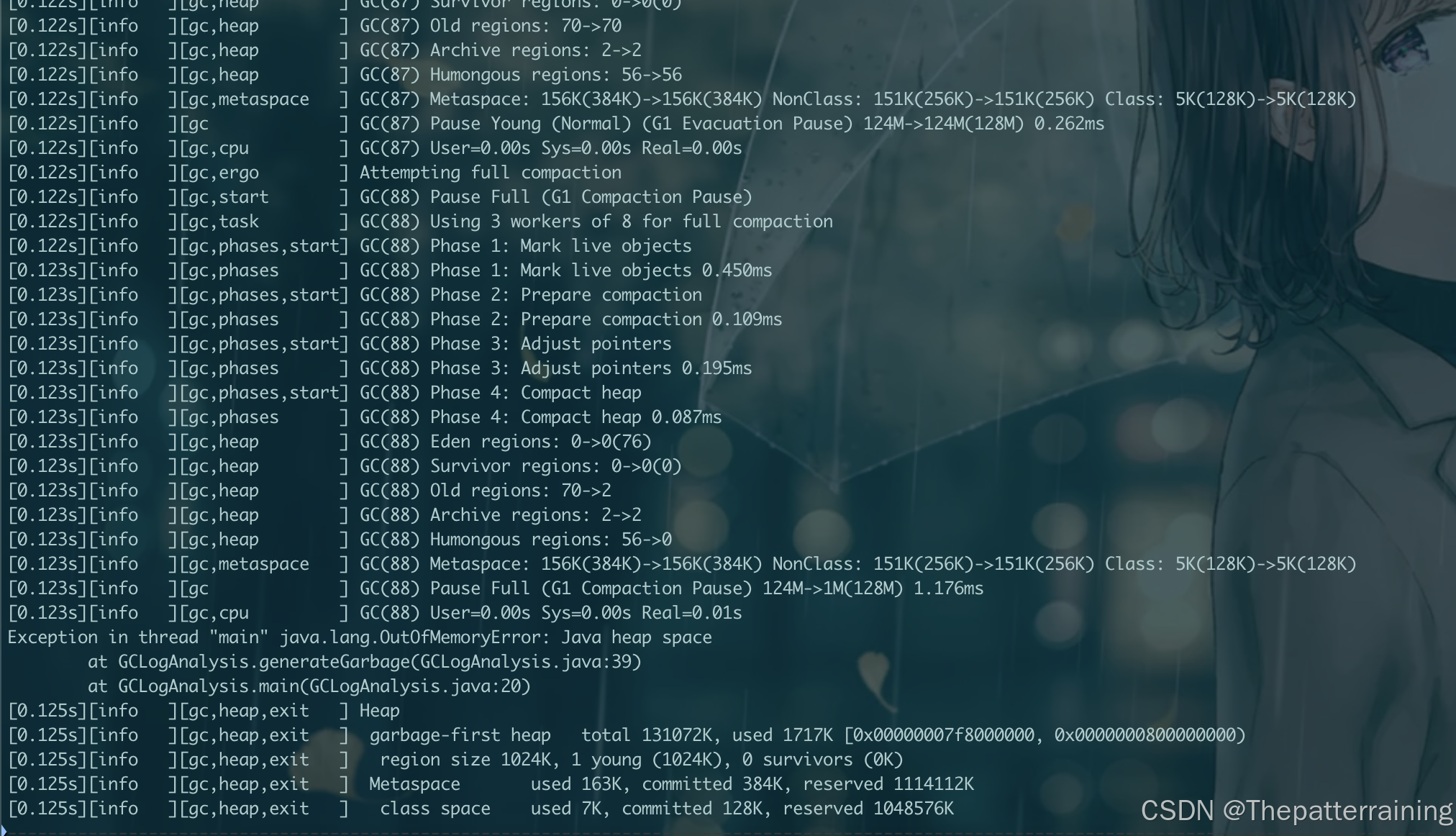
接下来试试512m内存
java -XX:+UseG1GC -Xms512m -Xmx512m -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
可以看到GC了600多次,才生成了29000多个对象。效率很低。但是比并行GC还是要好一些。

接下来试试1g内存
java -XX:+UseG1GC -Xms1g -Xmx1g -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
可以发现效率大大提升,生成了56000多个对象。GC了174次。其吞吐量相比并行GC稍微提升,GC次数却很多,说明GC期间很少影响业务。
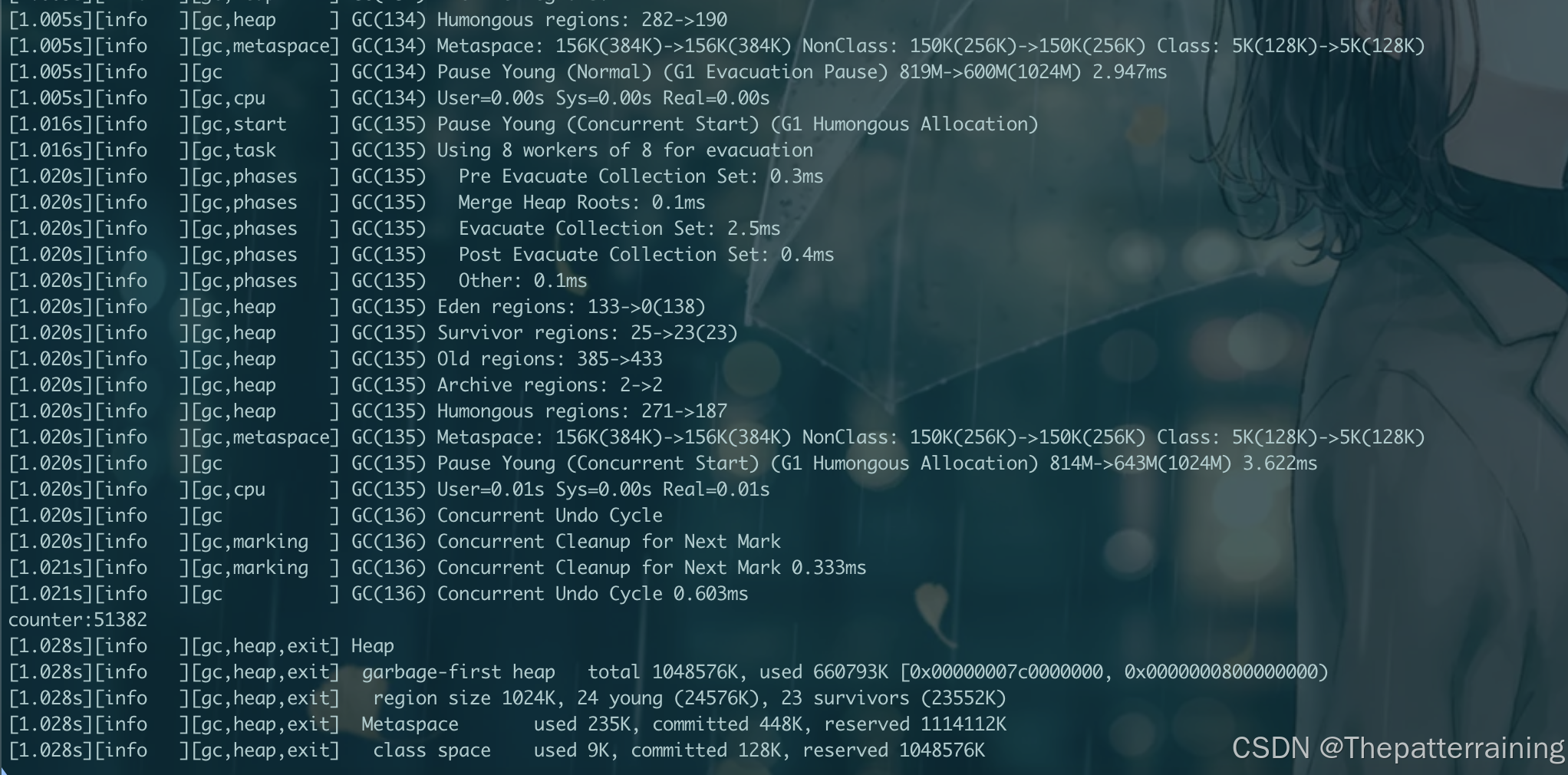
再试试2g内存
java -XX:+UseG1GC -Xms2g -Xmx2g -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
可以看到GC次数减少,但是性能并没有什么提升,这也说明了GC对于性能的影响开始减少
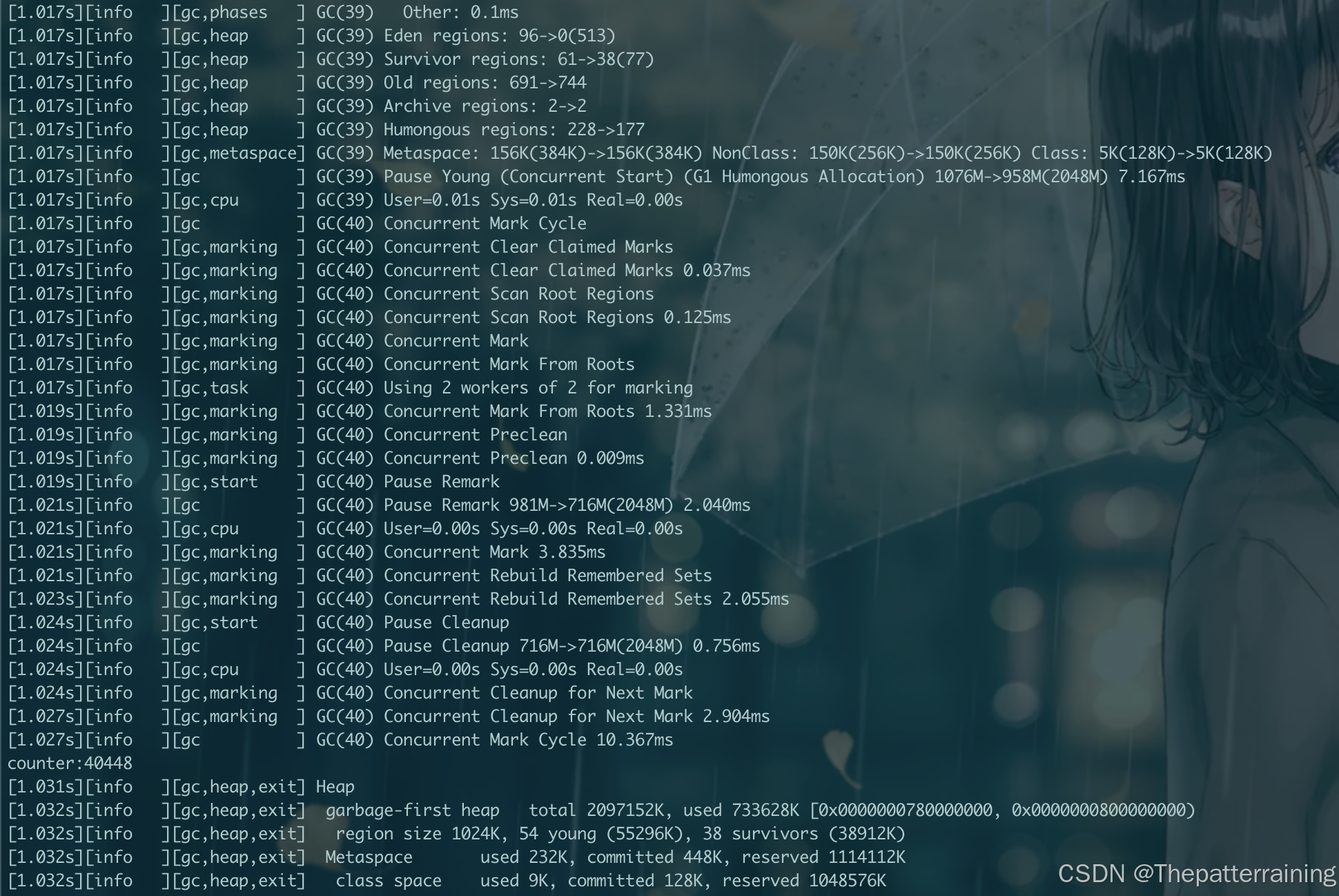
ZGC
专注于低延迟,目标是将 GC 停顿时间控制在 10ms 以下。支持非常大的堆内存(TB 级)。使用多线程并发回收,避免长时间的 STW。基于标记-整理算法,避免内存碎片化。使用指针染色(Pointer Coloring)来实现并发标记和引用更新。
-XX: +UnlockExpermentalVMOptions
-XX: +UseZGC
-XX: -Xmx16g
优点:
- 极低的 GC 停顿时间。
- 支持超大堆,扩展性好。
- 减少内存碎片。
- 与G1相比,应用吞吐量下降不超过15%
缺点:
- 内存占用较高:由于需要染色指针和写屏障。
- 不适合资源紧张的环境。
-XX: +UseShenandoahGC
立项比ZGC早,暂停时间与堆大小无关
适用场景:
- 延迟敏感的大型应用(如金融交易、高并发系统)。
- 超大堆应用(TB 级别内存)。
接下来试试 ZGC 128m内存
java -XX:+UseZGC -Xms128m -Xmx128m -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
可以看到GC12次就出现了OOM,花了0.157s。和并行GC接近,比G1GC的GC次数少
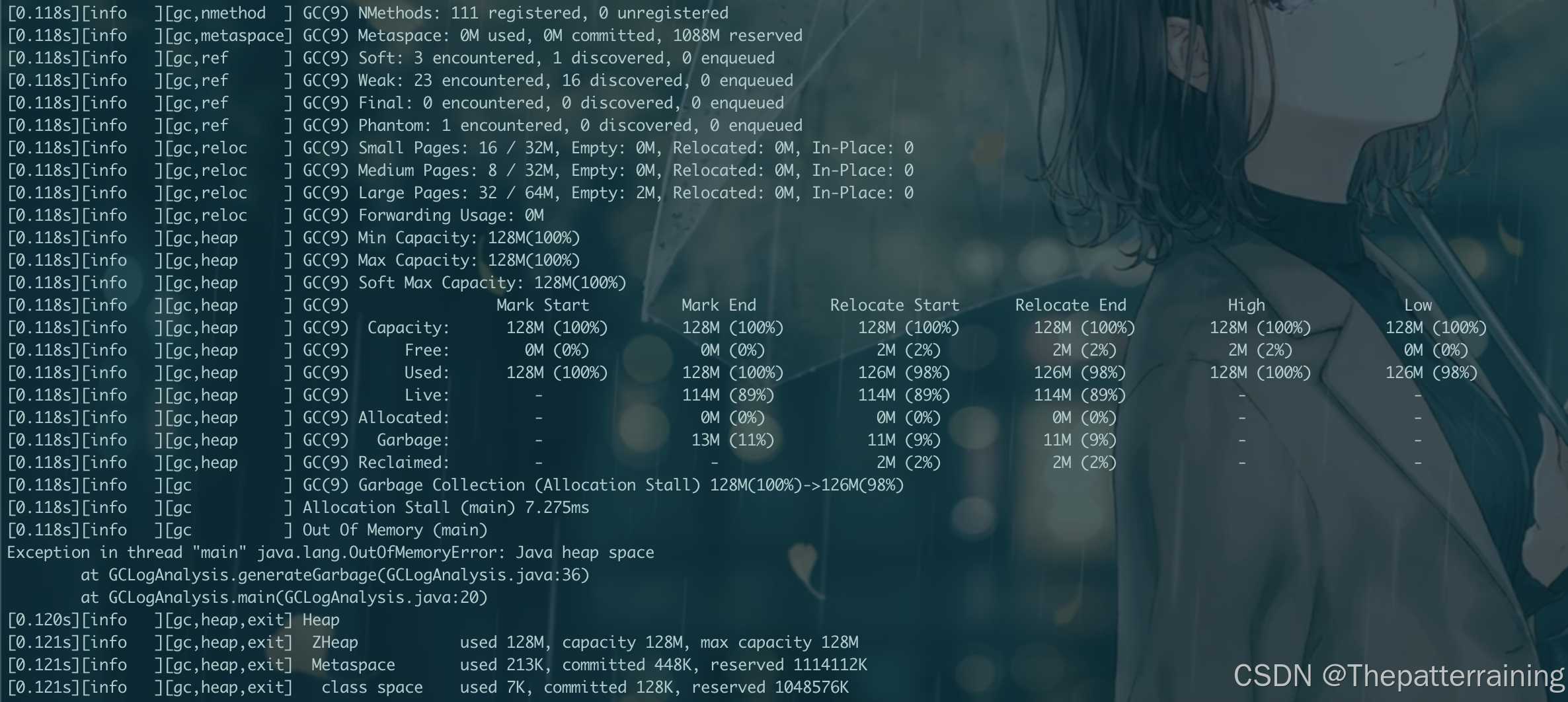
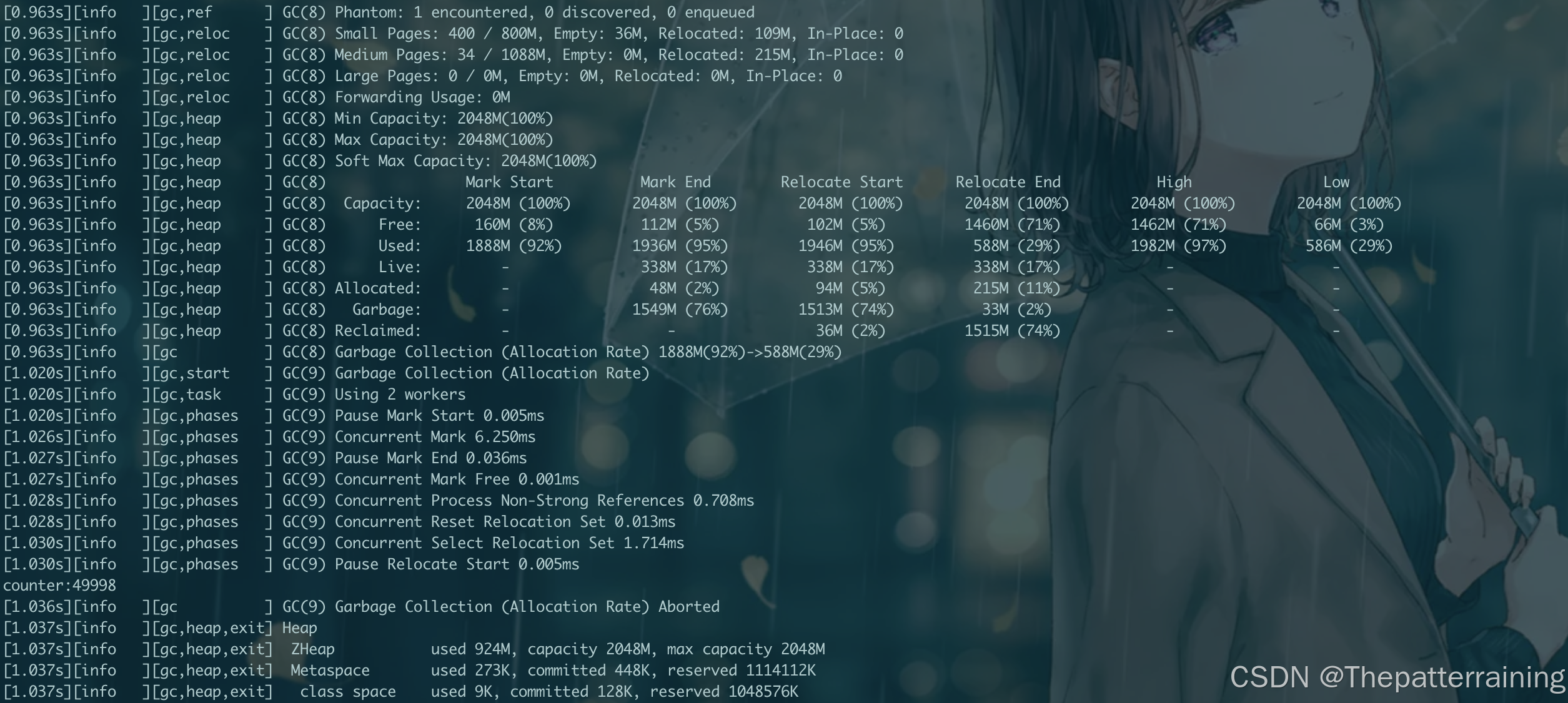
试试512m内存
java -XX:+UseZGC -Xms512m -Xmx512m -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
79次GC,生成了35000多个对象。可以看到效果比G1GC要好一些。
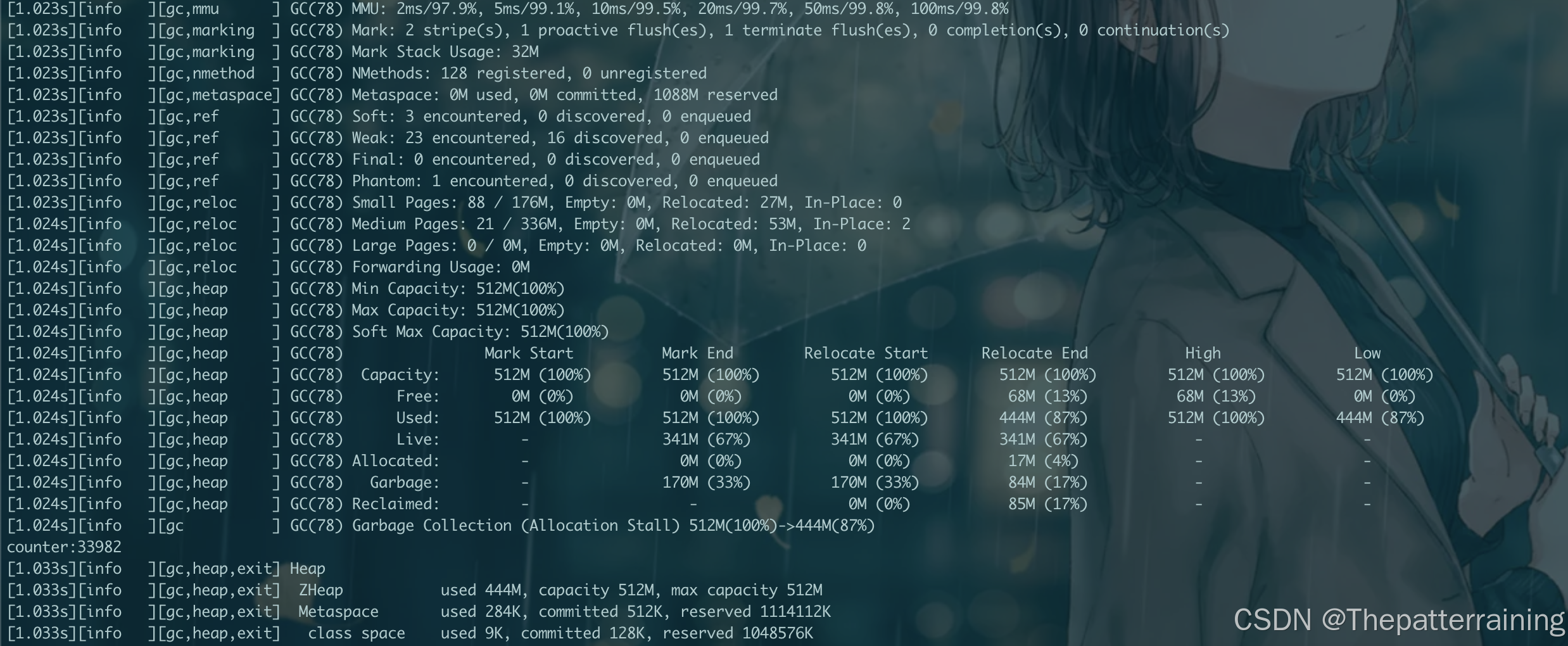
再看看1g内存
java -XX:+UseZGC -Xms1g -Xmx1g -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
结果22次GC,生成了57000多个对象,GC次数相比G1减少了很多,性能也差不多。
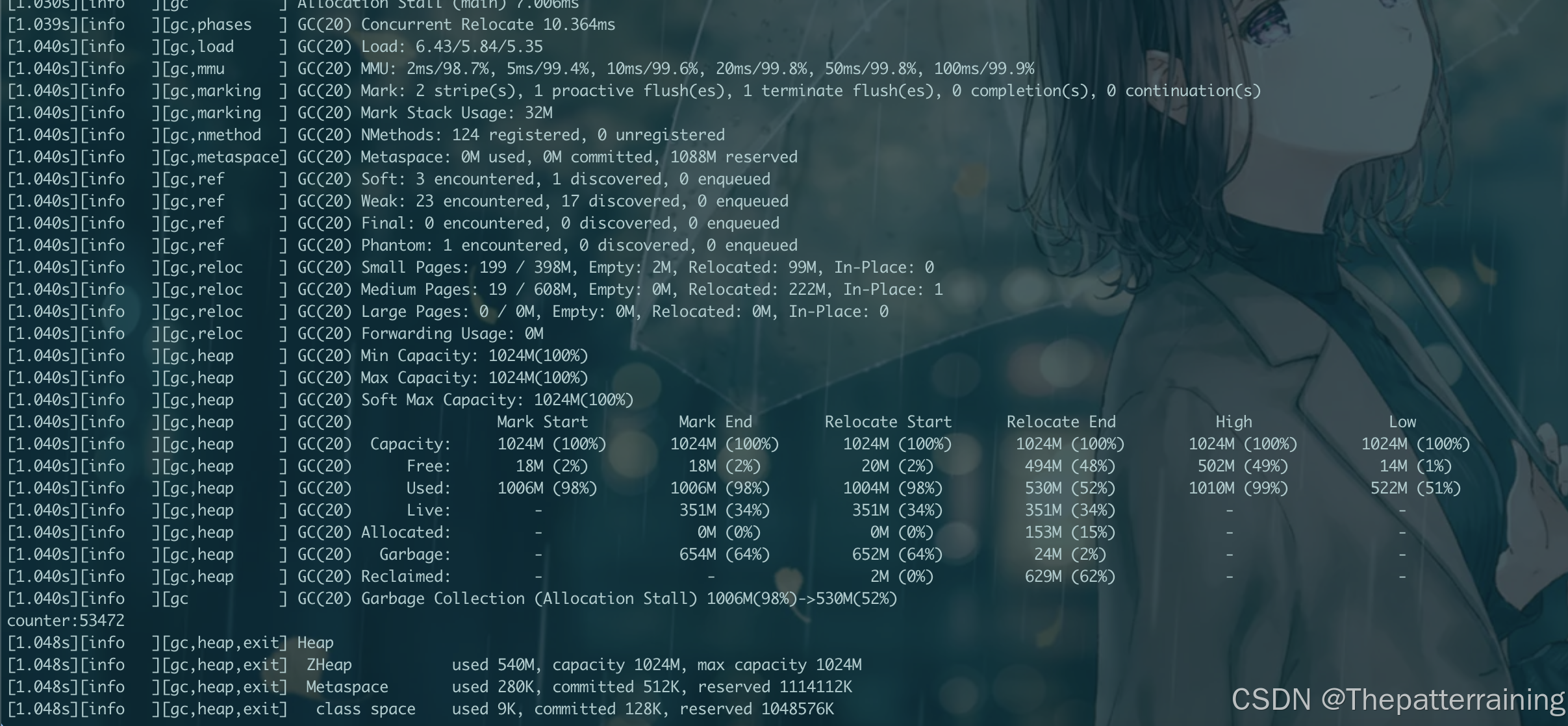
再试试2g内存
java -XX:+UseZGC -Xms2g -Xmx2g -XX:+PrintGCDetails -Xlog:gc\*:file=gc.log:time,uptime,level,tags GCLogAnalysis
结果是9次GC,生成了54000多个对象
Shenandoah GC
目标是极低延迟,尽可能减少 STW 时间。采用并发压缩技术(Concurrent Compaction),避免碎片化问题。大部分回收工作与应用线程并发执行。
优点:
- GC 停顿时间低。
- 内存整理避免碎片化。
- 对堆内存的需求比 ZGC 更低。
缺点:
- 较新的 GC,生态和调优支持可能不如 G1 和 ZGC。
- CPU 开销高。
适用场景:
- 延迟敏感的应用。
- 中大型堆内存的场景。
GC总结
从GC的发展历史来看,目标是两个
- 尽可能减少停顿时间,不影响业务。
- 尽可能减少GC时间,让GC更快。
通过以上的对比可以发现,堆的大小不能设置的太小导致OOM,同样当堆设置的过大对于性能也并没有什么提升,比如2g对比1g内存,就没什么提升。从512m和1g内存对比上来看,ZGC最优,不仅减少了GC次数,性能也很好。而G1GC的优化最好,因为它的GC次数最多,但是性能同样强大。
从结果来看最好的是ZGC,其次可以选择G1GC或者并行GC。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









