 深入理解pandas.concat:行与列的高效合并
深入理解pandas.concat:行与列的高效合并








 本文详细介绍了pandas的concat函数,包括参数objs、axis、join、ignore_index、keys等的使用,通过实例展示了如何进行行连接、列连接,以及自定义索引和忽略原索引的功能。同时提到了join_axes参数的替代方案——使用pandas.merge。
本文详细介绍了pandas的concat函数,包括参数objs、axis、join、ignore_index、keys等的使用,通过实例展示了如何进行行连接、列连接,以及自定义索引和忽略原索引的功能。同时提到了join_axes参数的替代方案——使用pandas.merge。
更多文章可关注微信公众号:Excelwork
“ 作为pandas库常用的函数,应该做到熟悉才行,最近发现自己也并没真正理解这个函数,本文目的也是加深下对concat函数的理解。”
语法:pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True)
01 参数认知
-
objs:要合并的对象,可以是Series、Dataframe、Panel objects;
-
axis:连接的轴,默认axis=0,axis=0行连接,axis=1按列;
-
join:连接方式,默认outer,有inner和outer两种;
-
keys:可手动传递键作为外层索引;
-
ignore_index:默认False,若为True,则不使用原来合并文件的索引。
02 参数应用
之前的文章介绍过,同一文件夹内,同一格式文件合并到同一个工作表上,使用了os.listdir获取到文件夹下所有文件,使用append函数添加:
result=[]for i in os.listdir(path):result.append(pd.read_excel(path+i))pd.concat(result)
可以看到,文件都传入到列表中,从type(result)结果看,传入的是<class 'list'>类型,如果类型不正确,也会提示我们“first argument must be an iterable of pandas objects”。
所以,如果我们已经读取了文件,直接pd.concat([data1,data2,data3])即可。
2.1 axis使用:
将三个文件数据,传入到列表new中,axis=0,行连接,axis=1,列连接:
new=[data1,data2,data3]pd.concat(new,axis=0)
结果如下:
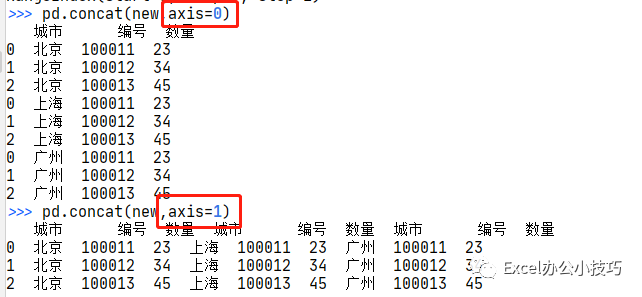
2.2 ingore_index使用:
上面的结果可以看到,索引仍为源文件索引,所以我们需要重新排列,只需要ignore_True就好了:
pd.concat(new,ignore_index=True)
结果如下:

2.3 join使用:
使用inner可以得到交集,outer得到并集:
pd.concat([data1,data14],join='inner',axis=1)pd.concat([data1,data14],join='outer',axis=1)

2.4 keys使用:
自定义索引 ,若ignore_index=True,则keys无效。:
pd.concat(new,keys=['a','b','c'])

2.5 join_axes变化:
如2.3,单纯使用集合的交集和并集,是满足不了我们的需求的,新版本join_axes没了,可以使用pandas.merge更好用哦。

















 2585
2585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









