




👉️关注公众号Tensor实验室,,第一时间获取大厂算法校招、社招信息、最新论文工作(大模型、具身智能、CV、扩散模型、多模态、自动驾驶、医疗影像、AIGC、遥感等方向的论文解读)、最新AI发展趋势和学习资料等,赶快加入一起学习吧!
CVPR 2025 论文和开源项目合集请戳 CVPR2025-PapersWithCode
AI垂直方向交流群和论文投稿群已成立!
👨🔧👩🔧👨🔬👩🔬👨🚀👨🚒🕵️: 欢迎进群 | Welcome
目前已经开设的AI细分垂直方向交流群包括但不限于: 大模型、多模态、具身智能、CV、扩散模型、目标检测、图像分割、目标跟踪、医学影像、遥感、3DGS、Mamba、NeRF、Transformer、GAN、异常检测/缺陷检测、SLAM、人脸检测&识别、OCR、NAS、Re-ID、超分辨率、强化学习、3D重建、姿态估计、自动驾驶、活体检测、深度估计、去噪、显著性目标检测、车道线检测、模型剪枝&压缩、去雾、去雨、行为识别、视频理解、图像融合、图像检索等。
可以添加微信小助手微信:Tensor333或Tensor555,请备注:研究方向+地区+学校/公司名称+昵称!如:大模型+北京+北航+小北;一定要根据格式申请,可以拉你进对应的交流群。
如果目前方向未定的的同学,可以先加入大群(大群和垂直方向群可以同时加入)。可以添加微信小助手微信:Tensor333或Tensor555,请备注:方向未定+地区+学校/公司名称+昵称!如:方向未定+北京+北航+小北;
如果想进顶刊顶会论文投稿和交流群的同学。可以添加微信小助手微信:Tensor333或Tensor555,请备注:顶刊顶会名称+地区+学校/公司名称+昵称!如:CVPR+北京+北航+小北;
Authors: Aneeshan Sain, Subhajit Maity, Pinaki Nath Chowdhury, Subhadeep Koley, Ayan Kumar Bhunia, Yi-Zhe Song
Paper: https://arxiv.org/abs/2505.23763
Code:
Home:
目录
一、现存问题🌟
二、相关研究和难点📚
三、创新点(解决方法)🔥
四、实验结果分析📈
五、未来工作建议💡
六、总结🌳
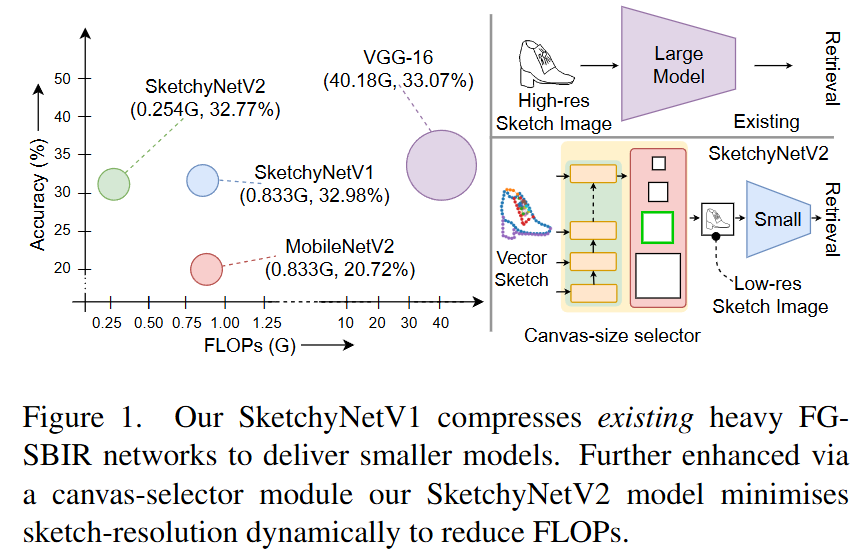
简介:随着素描研究逐渐成熟,其大规模商业化的适应也指日可待。尽管对照片的研究已经很成熟,但还没有针对素描数据专门设计的有效推理的研究。在本文中,我们首先证明现有的为照片设计的最先进的高效轻量级模型不适用于素描。然后,我们提出了两个特定于素描的组件,它们可以在任何照片高效网络上以即插即用的方式工作,以使其能够处理素描数据。我们特意选择了基于细粒度素描的图像检索(FG-SBIR)作为演示者,因为它是最受认可的具有直接商业价值的素描问题。从技术上讲,我们首先提出一个跨模态知识蒸馏网络,将现有的照片高效网络迁移到素描兼容,这将 FLOP 数量和模型参数分别降低了 97.96% 和 84.89%。然后,我们利用草图的抽象特性,引入了一个基于强化学习的画布选择器,该选择器可以根据抽象级别动态调整,从而进一步将 FLOP 数量减少三分之二。最终结果是,与完整网络相比,FLOP 总体减少了 99.37%(从 40.18G 减少到 0.254G),同时保持了准确率(33.03% vs 32.77%)——最终构建了一个高效的稀疏草图数据网络,其 FLOP 数量甚至比最佳照片数据还要少。
一、现存问题🌟
这篇论文试图解决**细粒度基于草图的图像检索(Fine-Grained Sketch-Based Image Retrieval, FG-SBIR)**任务中模型效率低下的问题。具体来说,它关注如何将现有的为照片设计的高效轻量级模型适配到草图数据上,以实现高效的推理,同时保持较高的检索准确率。
背景知识
- 草图研究的成熟与商业化需求:随着草图研究的逐渐成熟,其在大规模商业化应用中的需求日益增加。尽管在照片数据上已经有了许多高效的模型(如MobileNet、EfficientNet等),但在草图数据上,专门针对高效推理的研究还是一片空白。
- 草图的独特特性:草图具有序列性、抽象性、笔画特性、风格多样性和数据稀缺性等独特性质,这些特性使得不能直接将照片上的高效模型应用于草图数据。
- FG-SBIR的重要性:FG-SBIR是草图领域中研究最多的问题之一,具有直接的商业价值,例如在时尚设计、产品检索等场景中,用户可以通过草图快速检索到相关的图片。
研究动机
- 现有轻量级模型在草图上的失效:论文首先通过实验表明,现有的高效轻量级模型(如MobileNetV2)在草图数据上表现不佳,与使用VGG-16等大型模型相比,检索准确率下降了约37%。
- 草图数据的特殊性:草图数据是稀疏的,主要由黑白线条组成,与照片的像素密集信息不同。因此,草图在较低分辨率下可能仍然能够保留足够的语义信息,这为降低计算量提供了可能。
解决方案
论文提出了两个主要的解决方案,以将现有的照片高效网络适配到草图数据上:
- 跨模态知识蒸馏网络(Cross-modal Knowledge Distillation Network):
- 目标:将大型模型(教师网络)的知识转移到小型模型(学生网络)中,以减少FLOPs和模型参数,同时保持检索性能。
- 方法:通过蒸馏教师网络中的语义知识,使得学生网络能够在嵌入空间中保持与教师网络相似的结构一致性。具体来说,论文提出了一个关系蒸馏损失函数(Relational Distillation Loss),用于蒸馏教师网络中草图和照片特征之间的距离关系。
- 结果:通过这种方法,论文中的SketchyNetV1模型将FLOPs从40.18G降低到0.833G,模型参数减少了84.89%,同时保持了与大型模型相当的检索准确率(32.98% vs 33.03%)。
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









