




👉️关注公众号Tensor实验室,,第一时间获取大厂算法校招、社招信息、最新论文工作(大模型、具身智能、CV、扩散模型、多模态、自动驾驶、医疗影像、AIGC、遥感等方向的论文解读)、最新AI发展趋势和学习资料等,赶快加入一起学习吧!
CVPR 2025 论文和开源项目合集请戳 CVPR2025-PapersWithCode
AI垂直方向交流群和论文投稿群已成立!
👨🔧👩🔧👨🔬👩🔬👨🚀👨🚒🕵️: 欢迎进群 | Welcome
目前已经开设的AI细分垂直方向交流群包括但不限于: 大模型、多模态、具身智能、CV、扩散模型、目标检测、图像分割、目标跟踪、医学影像、遥感、3DGS、Mamba、NeRF、Transformer、GAN、异常检测/缺陷检测、SLAM、人脸检测&识别、OCR、NAS、Re-ID、超分辨率、强化学习、3D重建、姿态估计、自动驾驶、活体检测、深度估计、去噪、显著性目标检测、车道线检测、模型剪枝&压缩、去雾、去雨、行为识别、视频理解、图像融合、图像检索等。
可以添加微信小助手微信:Tensor333或Tensor555,请备注:研究方向+地区+学校/公司名称+昵称!如:大模型+北京+北航+小北;一定要根据格式申请,可以拉你进对应的交流群。
如果目前方向未定的的同学,可以先加入大群(大群和垂直方向群可以同时加入)。可以添加微信小助手微信:Tensor333或Tensor555,请备注:方向未定+地区+学校/公司名称+昵称!如:方向未定+北京+北航+小北;
如果想进顶刊顶会论文投稿和交流群的同学。可以添加微信小助手微信:Tensor333或Tensor555,请备注:顶刊顶会名称+地区+学校/公司名称+昵称!如:CVPR+北京+北航+小北;
Authors: Aneeshan Sain, Subhajit Maity, Pinaki Nath Chowdhury, Subhadeep Koley, Ayan Kumar Bhunia, Yi-Zhe Song
Paper: https://arxiv.org/abs/2505.23763
Code:
Home:
目录
一、现存问题🌟
二、相关研究和难点📚
三、创新点(解决方法)🔥
四、实验结果分析📈
五、未来工作建议💡
六、总结🌳
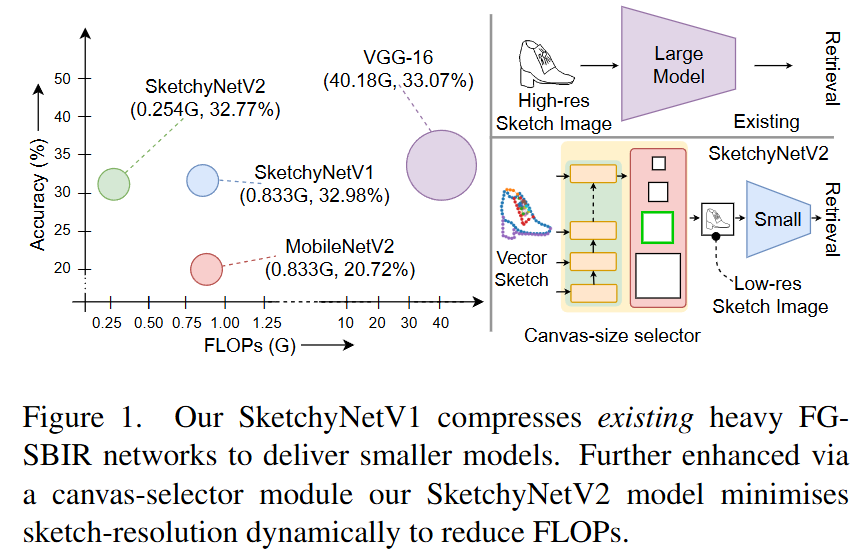
简介:随着素描研究逐渐成熟,其大规模商业化的适应也指日可待。尽管对照片的研究已经很成熟,但还没有针对素描数据专门设计的有效推理的研究。在本文中,我们首先证明现有的为照片设计的最先进的高效轻量级模型不适用于素描。然后,我们提出了两个特定于素描的组件,它们可以在任何照片高效网络上以即插即用的方式工作,以使其能够处理素描数据。我们特意选择了基于细粒度素描的图像检索(FG-SBIR)作为演示者,因为它是最受认可的具有直接商业价值的素描问题。从技术上讲,我们首先提出一个跨模态知识蒸馏网络,将现有的照片高效网络迁移到素描兼容,这将 FLOP 数量和模型参数分别降低了 97.96% 和 84.89%。然后,我们利用草图的抽象特性,引入了一个基于强化学习的画布选择器,该选择器可以根据抽象级别动态调整,从而进一步将 FLOP 数量减少三分之二。最终结果是,与完整网络相比,FLOP 总体减少了 99.37%(从 40.18G 减少到 0.254G),同时保持了准确率(33.03% vs 32.77%)——最终构建了一个高效的稀疏草图数据网络,其 FLOP 数量甚至比最佳照片数据还要少。
一、现存问题🌟
这篇论文试图解决**细粒度基于草图的图像检索(Fine-Grained Sketch-Based Image Retrieval, FG-SBIR)**任务中模型效率低下的问题。具体来说,它关注如何将现有的为照片设计的高效轻量级模型适配到草图数据上,以实现高效的推理,同时保持较高的检索准确率。
背景知识
- 草图研究的成熟与商业化需求:随着草图研究的逐渐成熟,其在大规模商业化应用中的需求日益增加。尽管在照片数据上已经有了许多高效的模型(如MobileNet、EfficientNet等),但在草图数据上,专门针对高效推理的研究还是一片空白。
- 草图的独特特性:草图具有序列性、抽象性、笔画特性、风格多样性和数据稀缺性等独特性质,这些特性使得不能直接将照片上的高效模型应用于草图数据。
- FG-SBIR的重要性:FG-SBIR是草图领域中研究最多的问题之一,具有直接的商业价值,例如在时尚设计、产品检索等场景中,用户可以通过草图快速检索到相关的图片。
研究动机
- 现有轻量级模型在草图上的失效:论文首先通过实验表明,现有的高效轻量级模型(如MobileNetV2)在草图数据上表现不佳,与使用VGG-16等大型模型相比,检索准确率下降了约37%。
- 草图数据的特殊性:草图数据是稀疏的,主要由黑白线条组成,与照片的像素密集信息不同。因此,草图在较低分辨率下可能仍然能够保留足够的语义信息,这为降低计算量提供了可能。
解决方案
论文提出了两个主要的解决方案,以将现有的照片高效网络适配到草图数据上:
- 跨模态知识蒸馏网络(Cross-modal Knowledge Distillation Network):
- 目标:将大型模型(教师网络)的知识转移到小型模型(学生网络)中,以减少FLOPs和模型参数,同时保持检索性能。
- 方法:通过蒸馏教师网络中的语义知识,使得学生网络能够在嵌入空间中保持与教师网络相似的结构一致性。具体来说,论文提出了一个关系蒸馏损失函数(Relational Distillation Loss),用于蒸馏教师网络中草图和照片特征之间的距离关系。
- 结果:通过这种方法,论文中的SketchyNetV1模型将FLOPs从40.18G降低到0.833G,模型参数减少了84.89%,同时保持了与大型模型相当的检索准确率(32.98% vs 33.03%)。
- 基于强化学习的画布选择器(Canvas-size Selector):
- 目标:进一步利用草图的抽象特性,动态调整草图的渲染分辨率,以进一步减少FLOPs。
- 方法:由于草图是以矢量格式存储的,可以自由地渲染到任何分辨率,论文设计了一个基于强化学习的画布选择器,它可以根据输入草图的抽象程度动态选择最优的渲染分辨率。
- 结果:最终的SketchyNetV2模型进一步将FLOPs降低了3.28倍,从0.833G降低到0.254G,同时保持了与完整模型相似的检索准确率(32.77% vs 33.03%)。
实验结果
- 数据集:论文在多个公开的FG-SBIR数据集上进行了评估,包括QMUL-ShoeV2、QMUL-ChairV2、Sketchy和FS-COCO。
- 性能对比:与现有的最先进方法相比,SketchyNetV2在保持较高检索准确率的同时,显著降低了计算量。例如,在QMUL-ShoeV2数据集上,SketchyNetV2的Top-1准确率为32.77%,而FLOPs仅为0.254G,相比之下,使用VGG-16的基线模型准确率为33.03%,但FLOPs高达40.18G。
- 消融研究:论文还进行了消融实验,验证了画布选择器的设计选择和学生网络架构的有效性。例如,通过改变画布选择器的奖励函数中的不同组成部分,可以平衡准确率和计算量之间的权衡。
结论
论文首次针对FG-SBIR任务提出了高效的推理方法,通过跨模态知识蒸馏和动态画布选择器,显著降低了模型的计算量,同时保持了与大型模型相当的检索性能。这些方法不仅适用于FG-SBIR任务,还可以推广到其他基于草图的任务,如草图识别等。
二、相关研究和难点📚
论文中提到了多个与细粒度草图检索(FG-SBIR)和模型效率提升相关的研究工作。以下是这些相关研究的分类和简要介绍:
细粒度草图检索(FG-SBIR)
- Triplet-SN [75]:使用三元组损失函数的Siamese网络,是FG-SBIR任务的早期工作之一。
- HOLEF-SN [59]:在Triplet-SN的基础上引入了注意力机制,提升了检索性能。
- Triplet-RL [6]:利用强化学习优化检索过程,提高了检索效率。
- StyleVAE [51]:通过风格无关的草图检索,解决了草图风格多样性的问题。
- Partial-OT [14]:针对场景级别的FG-SBIR,利用部分输入进行检索。
- B-SBIR-SN [36]:基于草图的图像检索的基线模型,使用VGG-16作为骨干网络。
- DSH [36]:深度草图哈希方法,用于快速检索。
- B-D2S [19]:一种零样本草图检索方法,通过草图到图像的映射实现检索。
- T-SBIR-SN [75]:使用MobileNetV2作为骨干网络的轻量级FG-SBIR模型。
- T-DSH [36]:轻量级的深度草图哈希方法。
- T-D2S [19]:轻量级的零样本草图检索方法。
- T-StyleVAE [51]:轻量级的风格无关草图检索方法。
模型效率提升
- Network pruning [37, 68]:通过发现并丢弃预训练大型网络中影响较小的权重或通道来压缩模型。
- Quantisation [21]:通过减少参数值和梯度的位宽来降低计算量,使用低精度定点数替代浮点运算。
- Binarisation [18]:将权重和激活函数二值化,进一步降低计算复杂度。
- Knowledge Distillation [25]:将大型预训练教师网络的知识转移到小型学生网络中,以实现成本效益更高的部署。
- Input-size optimisation [62]:通过替换高分辨率输入图像为其下采样的低分辨率版本来减少计算量,同时保持准确率。
- B-BFR [62]:在CNN网络的中间层设计双线性特征调整器,输出下采样的图像。
- B-DRS [12]:训练一个卷积模块,计算输入图像在不同分辨率下的概率向量,并将其转换为二进制决策,指示选择的缩放因子。
- B-Crop [32]:通过元学习图像裁剪模块,将输入图像裁剪到目标分辨率,以降低计算量。
- B-Regress [48]:通过回归方法将教师网络的特征直接传递给学生网络。
- B-AKD [76]:使用空间注意力图进行知识传递。
- B-PKT [45]:通过建模教师网络嵌入空间中样本对之间的概率分布来进行知识传递。
这些相关研究为本文提出的高效FG-SBIR模型提供了理论基础和技术支持,本文通过跨模态知识蒸馏和动态画布选择器进一步提升了模型的效率和性能。
三、创新点(解决方法)🔥
论文通过两个主要阶段来解决细粒度草图检索(FG-SBIR)任务中的模型效率问题:
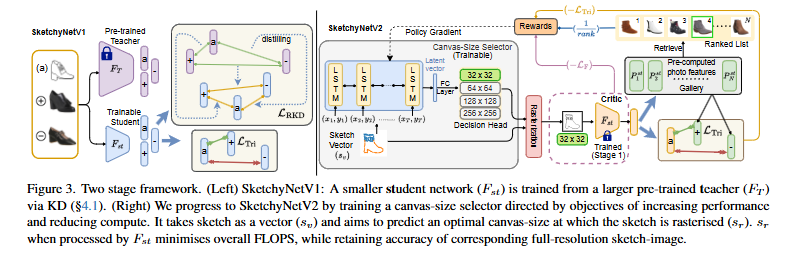
第一阶段:跨模态知识蒸馏(Cross-modal Knowledge Distillation)
- 问题:现有的轻量级模型(如MobileNetV2)在草图数据上表现不佳,与大型模型(如VGG-16)相比,检索准确率下降了约37%。
- 方法:论文提出了一个跨模态知识蒸馏框架,将大型模型(教师网络)的知识转移到小型模型(学生网络)中,以减少FLOPs和模型参数,同时保持检索性能。
- 教师网络:使用VGG-16作为教师网络,因为它在FG-SBIR任务中表现良好。
- 学生网络:选择MobileNetV2作为学生网络,因为它在边缘设备上表现高效。
- 蒸馏方法:通过蒸馏教师网络中的语义知识,使得学生网络能够在嵌入空间中保持与教师网络相似的结构一致性。具体来说,论文提出了一个关系蒸馏损失函数(Relational Distillation Loss),用于蒸馏教师网络中草图和照片特征之间的距离关系。
- 关系蒸馏损失:计算教师网络和学生网络中草图和照片特征之间的欧几里得距离,并通过Huber损失函数进行蒸馏。
- 总损失函数:结合三元组损失和关系蒸馏损失,训练学生网络。
- 结果:通过这种方法,论文中的SketchyNetV1模型将FLOPs从40.18G降低到0.833G,模型参数减少了84.89%,同时保持了与大型模型相当的检索准确率(32.98% vs 33.03%)。
第二阶段:基于强化学习的画布选择器(Canvas-size Selector)
- 问题:草图是抽象的,可以在较低分辨率下仍然保留足够的语义信息。因此,可以进一步降低计算量。
- 方法:论文设计了一个基于强化学习的画布选择器,动态选择草图的渲染分辨率,以进一步减少FLOPs。
- 画布选择器:输入草图的矢量表示,预测最优的渲染分辨率。
- 强化学习:使用强化学习训练画布选择器,以平衡准确率和计算量。
- 奖励函数:结合准确率和计算量两个目标设计奖励函数。准确率奖励(Racc)基于检索排名和三元组损失,计算奖励(Rcomp)基于选择的分辨率的FLOPs。
- 总奖励:通过超参数λF平衡两个目标。
- 训练方法:使用策略梯度方法训练画布选择器。
- 结果:最终的SketchyNetV2模型进一步将FLOPs降低了3.28倍,从0.833G降低到0.254G,同时保持了与完整模型相似的检索准确率(32.77% vs 33.03%)。
总结
通过这两个阶段,论文成功地将一个大型的FG-SBIR模型转换为一个高效的小型模型,同时保持了较高的检索性能。具体步骤如下:
- 跨模态知识蒸馏:将大型模型的知识转移到小型模型中,显著减少了FLOPs和模型参数。
- 动态画布选择器:利用草图的抽象特性,动态选择最优的渲染分辨率,进一步减少了计算量。
这两个阶段的结合,使得最终的SketchyNetV2模型在保持高检索准确率的同时,显著降低了计算量,适合在资源受限的设备上部署。
四、实验结果分析📈
论文中进行了多种实验来验证所提出方法的有效性和效率。以下是详细的实验设置和结果:
数据集
论文在以下四个公开的FG-SBIR数据集上进行了评估:
- QMUL-ShoeV2:包含6730个草图和2000张照片。
- QMUL-ChairV2:包含1800个草图和400张照片。
- Sketchy:包含125个类别,每个类别有100张照片,每张照片大约有5个草图。
- FS-COCO:包含10,000个独特的草图-照片对。
实验设置
- 教师网络:使用VGG-16作为教师网络,因为它在FG-SBIR任务中表现良好。
- 学生网络:选择MobileNetV2作为学生网络,因为它在边缘设备上表现高效。
- 训练细节:
- 使用Adam优化器,学习率为0.0001,批量大小为16,训练200个epoch。
- 画布选择器使用GRU网络,嵌入大小为128,训练500个epoch,批量大小为32。
- 使用不同的超参数设置,如λ、λr、λTri和λF,以平衡准确率和计算量。
实验结果
1. 与现有方法的对比
论文将提出的SketchyNetV1和SketchyNetV2模型与现有的最先进方法进行了对比,结果如下表所示:
| 方法 | 数据集 | Top-1 (%) | Top-10 (%) | FLOPs (G) | 参数量 (M) |
|---|---|---|---|---|---|
| Triplet-SN [75] | QMUL-ShoeV2 | 28.71 | 71.56 | 5.280 | 8.75 |
| HOLEF-SN [59] | QMUL-ShoeV2 | 31.74 | 75.78 | 5.758 | 9.31 |
| Triplet-RL [6] | QMUL-ShoeV2 | 34.10 | 78.82 | 6.041 | 22.1 |
| StyleVAE [51] | QMUL-ShoeV2 | 36.47 | 81.83 | 5.642 | 25.37 |
| SketchyNetV1 | QMUL-ShoeV2 | 33.88 | 77.15 | 0.833 | 2.22 |
| SketchyNetV2 | QMUL-ShoeV2 | 33.26 | 76.84 | 0.255 | 2.27 |
方法
数据集
Top-1 (%)
Top-10 (%)
FLOPs (G)
参数量 (M)
Triplet-SN [75]
QMUL-ShoeV2
28.71
71.56
5.280
8.75
HOLEF-SN [59]
QMUL-ShoeV2
31.74
75.78
5.758
9.31
Triplet-RL [6]
QMUL-ShoeV2
34.10
78.82
6.041
22.1
StyleVAE [51]
QMUL-ShoeV2
36.47
81.83
5.642
25.37
SketchyNetV1
QMUL-ShoeV2
33.88
77.15
0.833
2.22
SketchyNetV2
QMUL-ShoeV2
33.26
76.84
0.255
2.27
- 准确率:SketchyNetV1和SketchyNetV2在保持较高检索准确率的同时,显著降低了计算量。
- 计算量:SketchyNetV2的FLOPs仅为0.255G,相比Triplet-SN的5.280G,计算量减少了约95%。
2. 消融研究
论文还进行了消融实验,验证了画布选择器的设计选择和学生网络架构的有效性。
- 画布选择器的奖励函数:
- 完整奖励函数:结合准确率和计算量两个目标。
- 去除准确率奖励:仅考虑计算量,导致准确率下降。
- 去除计算量奖励:仅考虑准确率,导致计算量增加。
- 结果:完整奖励函数在准确率和计算量之间取得了最佳平衡。
- 学生网络的架构:
- 不同骨干网络:尝试了ResNet18和EfficientNet作为学生网络,发现MobileNetV2在准确率和计算量之间取得了最佳平衡。
- 输入方式:比较了使用矢量输入和图像输入的画布选择器,发现矢量输入更有效。
- 编码器类型:比较了LSTM、GRU和Transformer作为编码器,发现GRU在准确率和计算量之间取得了最佳平衡。
3. 画布选择器的泛化能力
- 跨模型泛化:训练了四个不同的画布选择器,分别用于不同的FG-SBIR模型。在QMUL-ShoeV2数据集上,89.21%的测试集草图在不同模型之间选择了相同的最优画布大小。
- 跨数据集泛化:将画布选择器在QMUL-ShoeV2上训练,然后应用于在QMUL-ChairV2上训练的检索模型。结果表明,画布选择器能够保持较高的准确率,同时显著降低计算量。
4. 推理时间
- GPU推理时间:在12GB的Nvidia RTX 2080 Ti GPU上,Triplet-SN的推理时间为37ms,而SketchyNetV2的推理时间为10ms。
- 移动设备推理时间:在iPhone13上,Triplet-SN的推理时间为51ms,而SketchyNetV2的推理时间为18ms。
结论
通过这些实验,论文验证了所提出方法的有效性和效率。SketchyNetV1和SketchyNetV2在保持较高检索准确率的同时,显著降低了计算量,适合在资源受限的设备上部署。
五、未来工作建议💡
论文在细粒度草图检索(FG-SBIR)任务中提出了高效的推理方法,但仍有一些可以进一步探索的方向。以下是一些潜在的研究点:
1. 跨模态知识蒸馏的进一步优化
- 更高效的教师-学生对:虽然论文中使用了VGG-16作为教师网络和MobileNetV2作为学生网络,但可以探索其他更高效的教师-学生对,例如使用EfficientNet作为教师网络,或者探索更轻量级的学生网络(如MobileNetV3或ShuffleNet)。
- 多阶段知识蒸馏:可以考虑多阶段知识蒸馏,即先将知识从一个大型网络蒸馏到一个中等大小的网络,然后再从这个中等大小的网络蒸馏到一个更小的网络,逐步减少模型大小和计算量。
- 自蒸馏:探索自蒸馏方法,即使用同一个网络作为教师和学生网络,进一步减少计算量。
2. 动态画布选择器的改进
- 连续动作空间:当前的画布选择器使用离散的动作空间(固定的分辨率集合),可以探索连续动作空间,使画布选择器能够选择更精细的分辨率。
- 多模态输入:除了矢量输入,可以探索使用多模态输入(如矢量和图像的组合)来进一步提高画布选择器的性能。
- 自适应训练策略:探索自适应训练策略,例如根据草图的复杂度动态调整训练过程中的奖励函数权重。
3. 结合其他模型压缩技术
- 量化和二值化:结合量化和二值化技术,进一步减少模型的计算量和存储需求。例如,可以将知识蒸馏后的模型进行量化训练。
- 网络剪枝:结合网络剪枝技术,进一步减少模型的参数量。可以探索结构化剪枝方法,以更好地适应移动设备的硬件特性。
- 混合精度训练:使用混合精度训练方法,结合FP16和FP32精度,进一步提高模型的推理速度。
4. 跨数据集和跨任务的泛化能力
- 跨数据集泛化:进一步验证画布选择器在更多数据集上的泛化能力,例如在更复杂的场景级别草图数据集上进行实验。
- 跨任务泛化:探索画布选择器在其他基于草图的任务中的应用,如草图识别、草图生成等。例如,将画布选择器应用于草图识别任务,验证其在减少计算量的同时是否能保持较高的识别准确率。
5. 实时性和硬件适配
- 实时性优化:进一步优化模型的实时性,使其能够在移动设备上实时运行。可以探索模型的轻量化设计,如减少卷积层的通道数或使用更高效的卷积操作。
- 硬件适配:针对特定的硬件平台(如ARM架构的移动设备或FPGA)进行优化,探索硬件友好的模型设计和推理方法。
6. 多模态融合
- 多模态输入融合:探索将草图和其他模态(如文本描述、语音指令)结合,进一步提高检索性能。例如,结合草图和文本描述进行多模态检索。
- 跨模态迁移学习:探索从其他模态(如图像或文本)到草图的迁移学习方法,利用其他模态的丰富数据来提升草图检索的性能。
7. 用户交互和反馈
- 用户交互:探索用户交互式检索,允许用户在检索过程中提供反馈,以进一步优化检索结果。
- 主动学习:结合主动学习方法,让模型主动选择需要用户标注的数据,以提高模型的泛化能力和检索性能。
8. 理论分析和解释性研究
- 理论分析:进行更深入的理论分析,解释为什么某些模型压缩方法在草图数据上特别有效,以及如何进一步优化这些方法。
- 解释性研究:探索模型的解释性,例如通过可视化方法解释画布选择器是如何选择最优分辨率的,以及这些选择对检索结果的影响。
这些方向不仅可以进一步提升FG-SBIR任务的效率和性能,还可以为其他相关领域的研究提供新的思路和方法。
六、总结🌳
本文的核心内容是针对细粒度草图检索(FG-SBIR)任务,提出了一个高效的推理框架,旨在解决现有轻量级模型在草图数据上表现不佳的问题。文章通过两个主要阶段来实现这一目标:跨模态知识蒸馏(Cross-modal Knowledge Distillation)和基于强化学习的动态画布选择器(Canvas-size Selector)。以下是文章的详细内容:
背景知识
- 草图数据的独特性:草图具有序列性、抽象性、笔画特性、风格多样性和数据稀缺性等特点,这使得不能直接将照片上的高效模型应用于草图数据。
- FG-SBIR的重要性:FG-SBIR是草图领域中研究最多的问题之一,具有直接的商业价值,例如在时尚设计、产品检索等场景中,用户可以通过草图快速检索到相关的图片。
研究方法
第一阶段:跨模态知识蒸馏
- 问题:现有的轻量级模型(如MobileNetV2)在草图数据上表现不佳,与大型模型(如VGG-16)相比,检索准确率下降了约37%。
- 方法:提出一个跨模态知识蒸馏框架,将大型模型(教师网络)的知识转移到小型模型(学生网络)中,以减少FLOPs和模型参数,同时保持检索性能。
- 教师网络:使用VGG-16作为教师网络。
- 学生网络:选择MobileNetV2作为学生网络。
- 蒸馏方法:通过蒸馏教师网络中的语义知识,使得学生网络能够在嵌入空间中保持与教师网络相似的结构一致性。具体来说,提出了一个关系蒸馏损失函数(Relational Distillation Loss),用于蒸馏教师网络中草图和照片特征之间的距离关系。
- 总损失函数:结合三元组损失和关系蒸馏损失,训练学生网络。
- 结果:通过这种方法,SketchyNetV1模型将FLOPs从40.18G降低到0.833G,模型参数减少了84.89%,同时保持了与大型模型相当的检索准确率(32.98% vs 33.03%)。
第二阶段:基于强化学习的画布选择器
- 问题:草图是抽象的,可以在较低分辨率下仍然保留足够的语义信息。因此,可以进一步降低计算量。
- 方法:设计了一个基于强化学习的画布选择器,动态选择草图的渲染分辨率,以进一步减少FLOPs。
- 画布选择器:输入草图的矢量表示,预测最优的渲染分辨率。
- 强化学习:使用强化学习训练画布选择器,以平衡准确率和计算量。
- 奖励函数:结合准确率和计算量两个目标设计奖励函数。准确率奖励(Racc)基于检索排名和三元组损失,计算奖励(Rcomp)基于选择的分辨率的FLOPs。
- 总奖励:通过超参数λF平衡两个目标。
- 训练方法:使用策略梯度方法训练画布选择器。
- 结果:最终的SketchyNetV2模型进一步将FLOPs降低了3.28倍,从0.833G降低到0.254G,同时保持了与完整模型相似的检索准确率(32.77% vs 33.03%)。
实验结果
- 数据集:在QMUL-ShoeV2、QMUL-ChairV2、Sketchy和FS-COCO四个公开的FG-SBIR数据集上进行了评估。
- 性能对比:与现有的最先进方法相比,SketchyNetV2在保持较高检索准确率的同时,显著降低了计算量。例如,在QMUL-ShoeV2数据集上,SketchyNetV2的Top-1准确率为33.26%,而FLOPs仅为0.255G,相比之下,使用VGG-16的基线模型准确率为33.03%,但FLOPs高达40.18G。
- 消融研究:验证了画布选择器的设计选择和学生网络架构的有效性。例如,通过改变画布选择器的奖励函数中的不同组成部分,可以平衡准确率和计算量之间的权衡。
- 泛化能力:画布选择器在不同模型和数据集上表现出良好的泛化能力。
- 推理时间:在12GB的Nvidia RTX 2080 Ti GPU上,SketchyNetV2的推理时间为10ms,相比Triplet-SN的37ms显著降低。在iPhone13上,SketchyNetV2的推理时间为18ms,相比Triplet-SN的51ms显著降低。
结论
本文首次针对FG-SBIR任务提出了高效的推理方法,通过跨模态知识蒸馏和动态画布选择器,显著降低了模型的计算量,同时保持了与大型模型相当的检索性能。这些方法不仅适用于FG-SBIR任务,还可以推广到其他基于草图的任务,如草图识别等。
A: 这篇论文试图解决**细粒度基于草图的图像检索(Fine-Grained Sketch-Based Image Retrieval, FG-SBIR)**任务中模型效率低下的问题。具体来说,它关注如何将现有的为照片设计的高效轻量级模型适配到草图数据上,以实现高效的推理,同时保持较高的检索准确率。
背景知识
- 草图研究的成熟与商业化需求:随着草图研究的逐渐成熟,其在大规模商业化应用中的需求日益增加。尽管在照片数据上已经有了许多高效的模型(如MobileNet、EfficientNet等),但在草图数据上,专门针对高效推理的研究还是一片空白。
- 草图的独特特性:草图具有序列性、抽象性、笔画特性、风格多样性和数据稀缺性等独特性质,这些特性使得不能直接将照片上的高效模型应用于草图数据。
- FG-SBIR的重要性:FG-SBIR是草图领域中研究最多的问题之一,具有直接的商业价值,例如在时尚设计、产品检索等场景中,用户可以通过草图快速检索到相关的图片。
研究动机
- 现有轻量级模型在草图上的失效:论文首先通过实验表明,现有的高效轻量级模型(如MobileNetV2)在草图数据上表现不佳,与使用VGG-16等大型模型相比,检索准确率下降了约37%。
- 草图数据的特殊性:草图数据是稀疏的,主要由黑白线条组成,与照片的像素密集信息不同。因此,草图在较低分辨率下可能仍然能够保留足够的语义信息,这为降低计算量提供了可能。
解决方案
论文提出了两个主要的解决方案,以将现有的照片高效网络适配到草图数据上:
- 跨模态知识蒸馏网络(Cross-modal Knowledge Distillation Network):
- 目标:将大型模型(教师网络)的知识转移到小型模型(学生网络)中,以减少FLOPs和模型参数,同时保持检索性能。
- 方法:通过蒸馏教师网络中的语义知识,使得学生网络能够在嵌入空间中保持与教师网络相似的结构一致性。具体来说,论文提出了一个关系蒸馏损失函数(Relational Distillation Loss),用于蒸馏教师网络中草图和照片特征之间的距离关系。
- 结果:通过这种方法,论文中的SketchyNetV1模型将FLOPs从40.18G降低到0.833G,模型参数减少了84.89%,同时保持了与大型模型相当的检索准确率(32.98% vs 33.03%)。
- 基于强化学习的画布选择器(Canvas-size Selector):
- 目标:进一步利用草图的抽象特性,动态调整草图的渲染分辨率,以进一步减少FLOPs。
- 方法:由于草图是以矢量格式存储的,可以自由地渲染到任何分辨率,论文设计了一个基于强化学习的画布选择器,它可以根据输入草图的抽象程度动态选择最优的渲染分辨率。
- 结果:最终的SketchyNetV2模型进一步将FLOPs降低了3.28倍,从0.833G降低到0.254G,同时保持了与完整模型相似的检索准确率(32.77% vs 33.03%)。
实验结果
- 数据集:论文在多个公开的FG-SBIR数据集上进行了评估,包括QMUL-ShoeV2、QMUL-ChairV2、Sketchy和FS-COCO。
- 性能对比:与现有的最先进方法相比,SketchyNetV2在保持较高检索准确率的同时,显著降低了计算量。例如,在QMUL-ShoeV2数据集上,SketchyNetV2的Top-1准确率为32.77%,而FLOPs仅为0.254G,相比之下,使用VGG-16的基线模型准确率为33.03%,但FLOPs高达40.18G。
- 消融研究:论文还进行了消融实验,验证了画布选择器的设计选择和学生网络架构的有效性。例如,通过改变画布选择器的奖励函数中的不同组成部分,可以平衡准确率和计算量之间的权衡。
结论
论文首次针对FG-SBIR任务提出了高效的推理方法,通过跨模态知识蒸馏和动态画布选择器,显著降低了模型的计算量,同时保持了与大型模型相当的检索性能。这些方法不仅适用于FG-SBIR任务,还可以推广到其他基于草图的任务,如草图识别等。
👉️关注公众号Tensor实验室,,第一时间获取大厂算法校招、社招信息、最新论文工作(大模型、具身智能、CV、扩散模型、多模态、自动驾驶、医疗影像、AIGC、遥感等方向的论文解读)、最新AI发展趋势和学习资料等,赶快加入一起学习吧!

















 5623
5623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









