



LSTM:
首先我们知道了RNN呢对于序列是不是不能解决长依赖问题啊,因此啊在LSTM我们做了改进,如下图:
我们引入了门和细胞状态C,门是做什么的呢,控制那些信息我要向下传递,哪些信息我要把它忘掉,然后这些有用的信息储存到了哪里呢就是细胞状态C中。
我们可以看到原来的RNN神经单元是不是只有一个h或者s啊,现在在LSTM中呢,又增加了一个C,这个C有什么作用呢,让它来保存长期记忆的状态,成为单元状态。
那么我们这个C既然只是储存记忆的对不对,那么我们怎么去控制这个C中的记忆呀,我不可能全部都记住吧,我要忘了那些,记住那些呢?怎么控制啊,通过门去控制,门说白了是什么啊,是不是就是一个sigmooid激活函数啊,为什么是sigmoid激活函数啊,大家想一想,sigmoid的输出是多少[0,1],0我是不是就可以代表过去的信息不接着向下传递了呀,1是不是就代表接着往下传递啊。
那么LSTM总共有几个门呢,分别是什么呢?
总共有三个门来控制,遗忘门,输入门,输出门。
我们通过例子来理解这三个门:
首先遗忘门:
作用对象是谁啊,就是C,细胞状态
作用呢就是将C中的信息进行选择性的遗忘
举例:‘他今天有点事,所以我.........’当我们看到了这个新的主语‘我’了对不对,那么我们是不是就要把,之前的主语‘他’给忘记,或者减小这个词对后边的影响啊。
因此呢这个时候我们输出的sigmoid的结果有可能就是[0,1,1,1,1,1,1,1,1],和C中的向量进行想乘,C中的向量了就是[他,今,天,有,点,事,所,以,我],那么这时候一线程是不是就把‘他’这个主语给忘掉了呀,或者说我们想减少‘他’对后边句子的影响,我们sigmoid输出的向量有可能就是[0.2,1,1,1,1,1,1,1,1]。
输入门:
作用对象同样也是细胞状态C
作用呢就是想新的信息更新到细胞状态C当中
举例:‘他今天有点事,所以我.........’同样这句话,当我们处理到‘我’这个主语的时候,是不是刚刚已经把‘他’这个主语给忘记了呀,那么我们是不是要把‘我’这个主语给更新到细胞状态C当中啊。
输出门:
他的作用对象是谁啊:隐藏状态ht
举例:还是刚才那句话‘他今天有点事,所以我.........’,处理到‘我’的时候,我们知道,下一个词是不是动词的可能性比较大,而且还是第一人称,英文中比较好理解:我们刚刚是不是把he给忘啦,然后把I添加到记忆中去啦,那么我下一个词很可能是am而不太可能是are或者is对不对,所以呢这个输出门啊,就是把我之前的并且对下一个时刻可能有用的信息保存到隐层ht当中。
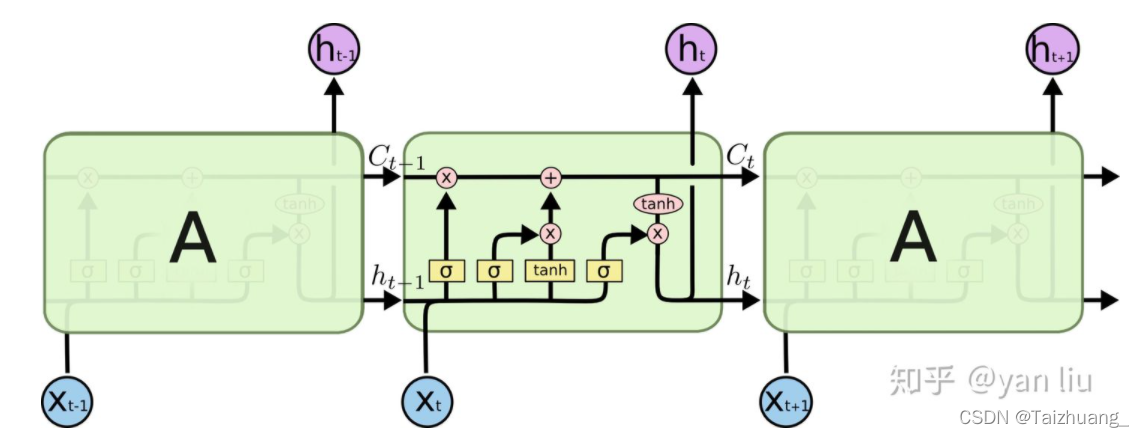
前向传播:
Ft = sigmoid(wf*[ht-1,xt] + bf)
It = sigmoid(wi*[ht-1,xt] + bi)
C:t = tanh(wc *[ht-1,xt] + bc)
Ct = Ft * Ct-1 + it * C:t
Ot = sigmoid(wo * [ht-1,xt] + bo)
Ht = ot * tanh(Ct)
为什么LSTM可以避免长期记忆问题?
因为LSTM中有两个通道,短期记忆通道h(保持非线性操作)和长期记忆通道c(保持线性操作),线性比较稳定,所以C变化比较稳定。
tf.contrib.rnn.static_rnn和tf.nn.dynamic_rnn的区别?
1.首先输入不同,前者输入的x需要是一个列表,后者直接输入tf就行
2.输出不同,前者的输出维度是【步长,批量,input_dim】,后者的输出维度【批量,步长,inout_dim】,因此如果使用后者,在进行后续处理的时候,需要进行一个维度的转换。
3.前者的输入的维度是固定的,而后者的输入批量与批量之间的句子长度是可以不同的,但是每个批量之间必须相同。
图片来源于知乎

















 4330
4330




 到【灌水乐园】发言
到【灌水乐园】发言







