




 本文详细介绍了如何在本地环境中安装并配置目标检测模型训练环境,包括材料准备、环境变量设置、模型选择、数据集准备、训练步骤、pb文件转换及预测流程。针对训练中可能出现的GPU使用率问题提供了解决方案。
本文详细介绍了如何在本地环境中安装并配置目标检测模型训练环境,包括材料准备、环境变量设置、模型选择、数据集准备、训练步骤、pb文件转换及预测流程。针对训练中可能出现的GPU使用率问题提供了解决方案。
基本的环境已经准备好了(https://blog.youkuaiyun.com/TYtangyan/article/details/105057503),安装检测训练环境
1.材料准备(这篇文章是以前的tf1.的版本,之后会安装一下tf2.0的,tf2.x的函数改动太大,好多删掉了,安装这个问题太多,网上说1.15就有这样的情况,还是用低一点的吧):
https://github.com/protocolbuffers/protobuf/releases/
https://github.com/tensorflow/models
2.models-master\research文件夹下cmd,复制解压后protoc.exe的完整路径
xxx/xxx/x/protoc.exe object_detection/protos/*.proto --python_out=.正常情况无任何输出

before
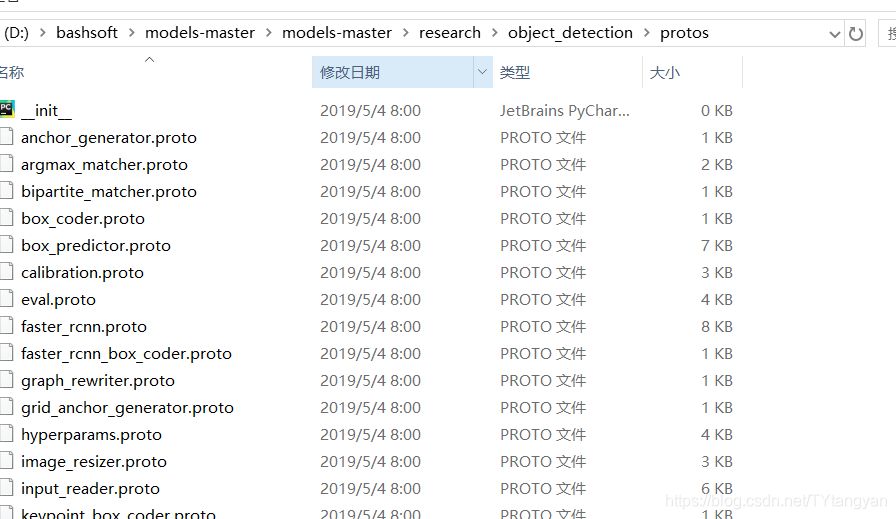
after, 生成py文件成功 !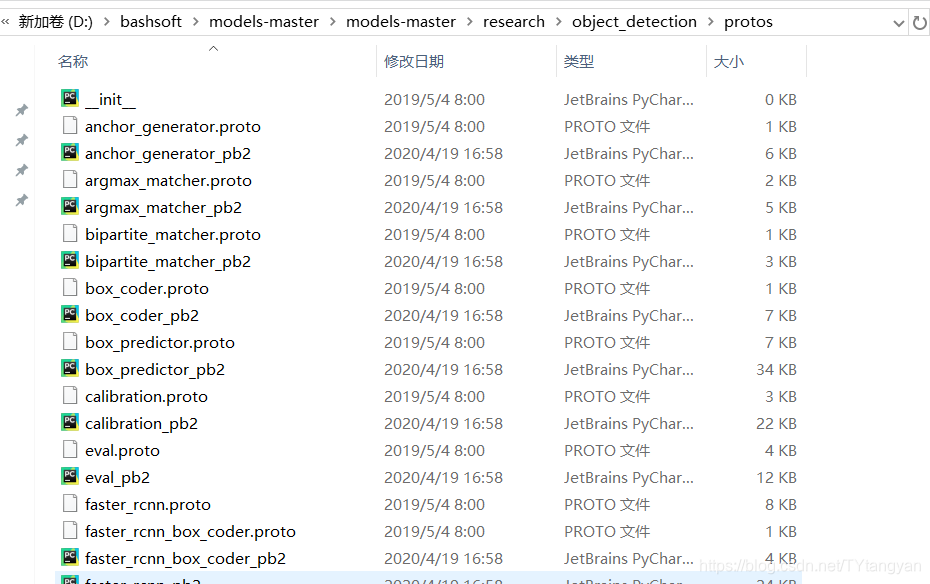
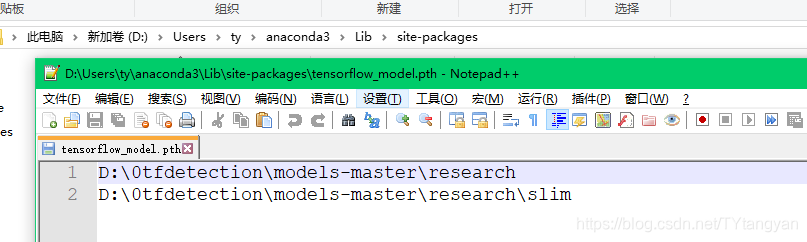
3、添加环境变量(可以跳过)
在Anaconda\Lib\site-packages添加一个路径文件,如tensorflow_model.pth,必须以.pth为后缀,写上你要加入的模块文件所在的目录名称,如下图:
4、运行models/research下的setup.py
python setup.py build
python setup.py install
5、安装完成测试
在models/research下运行如下命令:
python object_detection/builders/model_builder_test.py
输出如下,安装完成

ModuleNotFoundError: No module named 'nets'
1删除*/research/slim下的BUILD文件

2运行命令:
在*/research/slim下运行命令
python setup.py build
python setup.py install
遇到的问题:在训练模型的时候,显示使用GPU而且显存也占用正常,但是gpu的使用率一直为0,训练几步以后卡死不动,测试的时候一切正常。
本人这个问题的解决方式:应该是系统的显卡驱动版本太高,和cuda版本不匹配,把英伟达显卡驱动降低以后一切变正常
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
二、训练:
本人将需要的文件复制到了工程内,以后如果需要训练其他模型,直接更换数据集,无需 修改其他太多的东西
选择自己要使用的模型,是要速度还是精度,下载。。。
2. 数据集准备,准备好自己的数据集,labelimg标记,我使用的voc数据集的格式
下图是训练所需的类别标识,讲这个pascal_label_map文件里面的类别改为自己的,格式不变,复制该文件修改
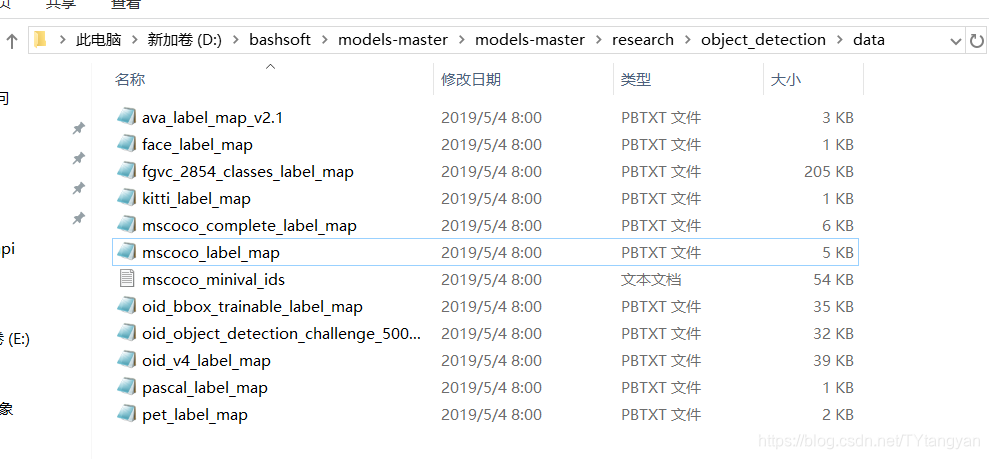 下图为将数据集转化为record格式的文件,路径可能和你自己的数据集不同,稍作更改
下图为将数据集转化为record格式的文件,路径可能和你自己的数据集不同,稍作更改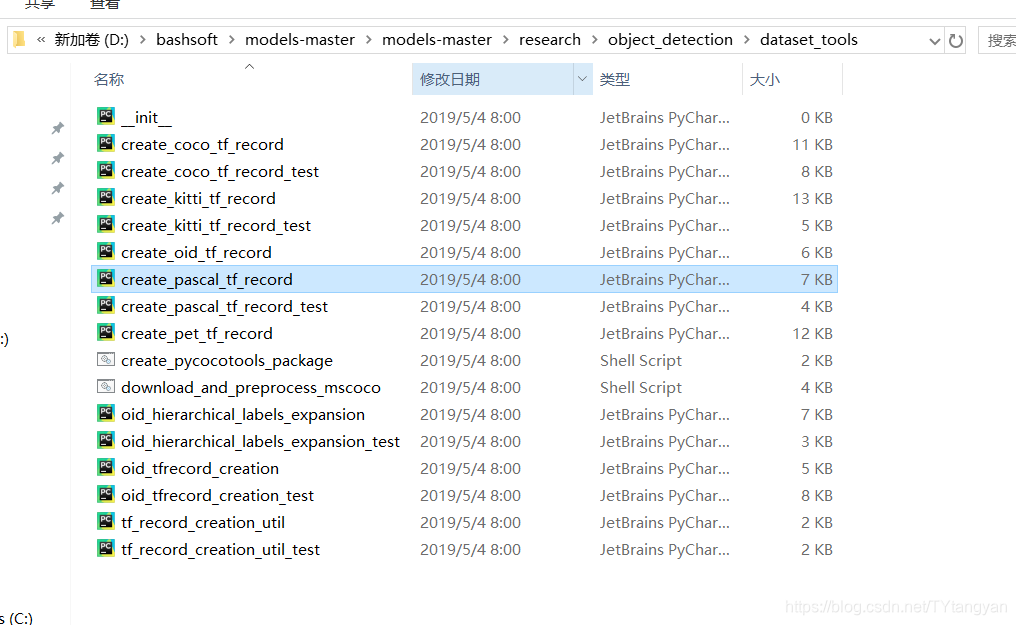
数据准备完成后,训练所需完整的数据
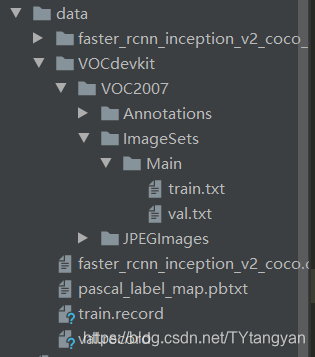
我的数据集格式如上,使用的转化py文件修改后如下,如果你的数据集和我的一样,可以直接使用,修改其中的set,及保存的record名称,分别转化训练集以及验证集
# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
r"""Convert raw PASCAL dataset to TFRecord for object_detection.
Example usage:
python object_detection/dataset_tools/create_pascal_tf_record.py \
--data_dir=/home/user/VOCdevkit \
--year=VOC2012 \
--output_path=/home/user/pascal.record
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import hashlib
import io
import logging
import os
from lxml import etree
import PIL.Image
import tensorflow as tf
from object_detection.utils import dataset_util
from object_detection.utils import label_map_util
from warnings import simplefilter
simplefilter(action='ignore', category=FutureWarning)
# import warnings
# warnings.filterwarnings("ignore")
# os.environ["TF_CPP_MIN_LOG_LEVEL"]='3'
flags = tf.app.flags
flags.DEFINE_string('data_dir', './data/VOCdevkit/', 'Root directory to raw PASCAL VOC dataset.')
flags.DEFINE_string('set', 'train', 'Convert training set, validation set or '
'merged set.')
flags.DEFINE_string('annotations_dir', 'Annotations',
'(Relative) path to annotations directory.')
flags.DEFINE_string('year', 'VOC2007', 'Desired challenge year.')
flags.DEFINE_string('output_path', './data/train.record', 'Path to output TFRecord')
flags.DEFINE_string('label_map_path', './data/pascal_label_map.pbtxt',
'Path to label map proto')
flags.DEFINE_boolean('ignore_difficult_instances', False, 'Whether to ignore '
'difficult instances')
FLAGS = flags.FLAGS
SETS = ['train', 'val', 'trainval', 'test']
YEARS = ['VOC2007', 'VOC2012', 'merged']
def dict_to_tf_example(data,
dataset_directory,
label_map_dict,
ignore_difficult_instances=False,
image_subdirectory='JPEGImages'):
"""Convert XML derived dict to tf.Example proto.
Notice that this function normalizes the bounding box coordinates provided
by the raw data.
Args:
data: dict holding PASCAL XML fields for a single image (obtained by
running dataset_util.recursive_parse_xml_to_dict)
dataset_directory: Path to root directory holding PASCAL dataset
label_map_dict: A map from string label names to integers ids.
ignore_difficult_instances: Whether to skip difficult instances in the
dataset (default: False).
image_subdirectory: String specifying subdirectory within the
PASCAL dataset directory holding the actual image data.
Returns:
example: The converted tf.Example.
Raises:
ValueError: if the image pointed to by data['filename'] is not a valid JPEG
"""
img_path = os.path.join( "VOC2007", image_subdirectory, data['filename'])
full_path = os.path.join(dataset_directory, img_path)
with tf.gfile.GFile(full_path, 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = PIL.Image.open(encoded_jpg_io)
# if image.format != 'JPEG':
# raise ValueError('Image format not JPEG')
key = hashlib.sha256(encoded_jpg).hexdigest()
width = int(data['size']['width'])
height = int(data['size']['height'])
xmin = []
ymin = []
xmax = []
ymax = []
classes = []
classes_text = []
truncated = []
poses = []
difficult_obj = []
if 'object' in data:
for obj in data['object']:
difficult = bool(int(obj['difficult']))
if ignore_difficult_instances and difficult:
continue
difficult_obj.append(int(difficult))
xmin.append(float(obj['bndbox']['xmin']) / width)
ymin.append(float(obj['bndbox']['ymin']) / height)
xmax.append(float(obj['bndbox']['xmax']) / width)
ymax.append(float(obj['bndbox']['ymax']) / height)
classes_text.append(obj['name'].encode('utf8'))
classes.append(label_map_dict[obj['name']])
truncated.append(int(obj['truncated']))
poses.append(obj['pose'].encode('utf8'))
example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/source_id': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/key/sha256': dataset_util.bytes_feature(key.encode('utf8')),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature('jpeg'.encode('utf8')),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmin),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmax),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymin),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymax),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
'image/object/difficult': dataset_util.int64_list_feature(difficult_obj),
'image/object/truncated': dataset_util.int64_list_feature(truncated),
'image/object/view': dataset_util.bytes_list_feature(poses),
}))
return example
def main(_):
if FLAGS.set not in SETS:
raise ValueError('set must be in : {}'.format(SETS))
if FLAGS.year not in YEARS:
raise ValueError('year must be in : {}'.format(YEARS))
data_dir = FLAGS.data_dir
years = ['VOC2007', 'VOC2012']
if FLAGS.year != 'merged':
years = [FLAGS.year]
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
label_map_dict = label_map_util.get_label_map_dict(FLAGS.label_map_path)
for year in years:
logging.info('Reading from PASCAL %s dataset.', year)
examples_path = os.path.join(data_dir, year, 'ImageSets', 'Main',
FLAGS.set + '.txt')
annotations_dir = os.path.join(data_dir, year, FLAGS.annotations_dir)
examples_list = dataset_util.read_examples_list(examples_path)
for idx, example in enumerate(examples_list):
if idx % 100 == 0:
logging.info('On image %d of %d', idx, len(examples_list))
path = os.path.join(annotations_dir, example + '.xml')
with tf.gfile.GFile(path, 'r') as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = dataset_util.recursive_parse_xml_to_dict(xml)['annotation']
tf_example = dict_to_tf_example(data, FLAGS.data_dir, label_map_dict,
FLAGS.ignore_difficult_instances)
writer.write(tf_example.SerializeToString())
writer.close()
if __name__ == '__main__':
tf.app.run()
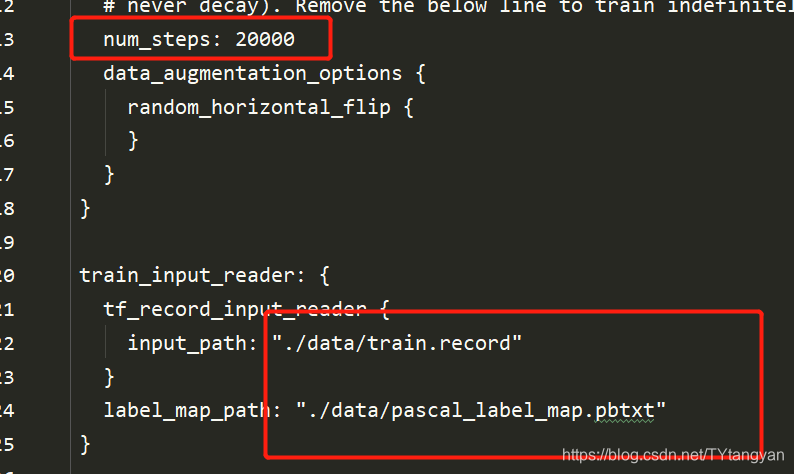
3.训练
数据集准备好,接下来训练,训练的train.py文件路径如下:复制到自己的工程(如果想要带eval的需要使用model_main.py)
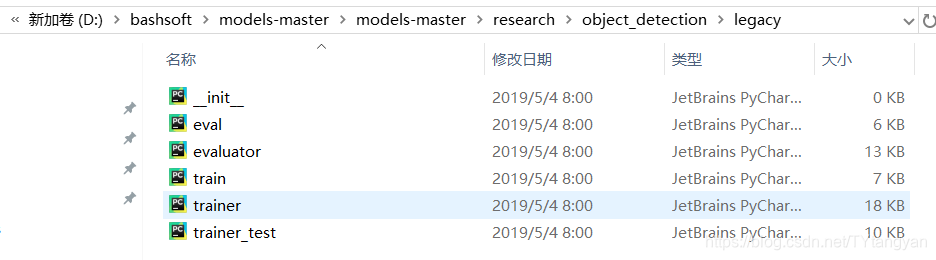
去下面的文件夹找到自己使用模型的config文件
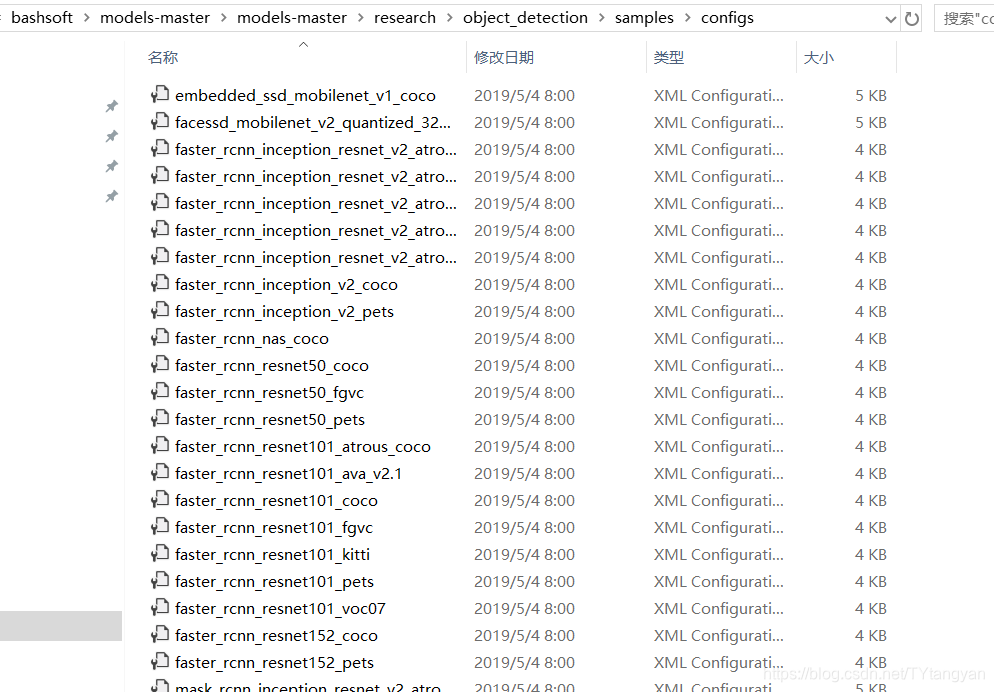
修改config其中类别大小,图像大小也可以固定
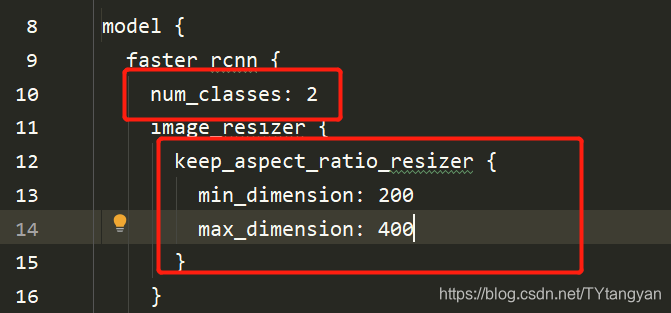
训练步数,数据路径,下面还有两个数据的路径没截取全,但是在使用train.py文件的时候没有使用到val数据集
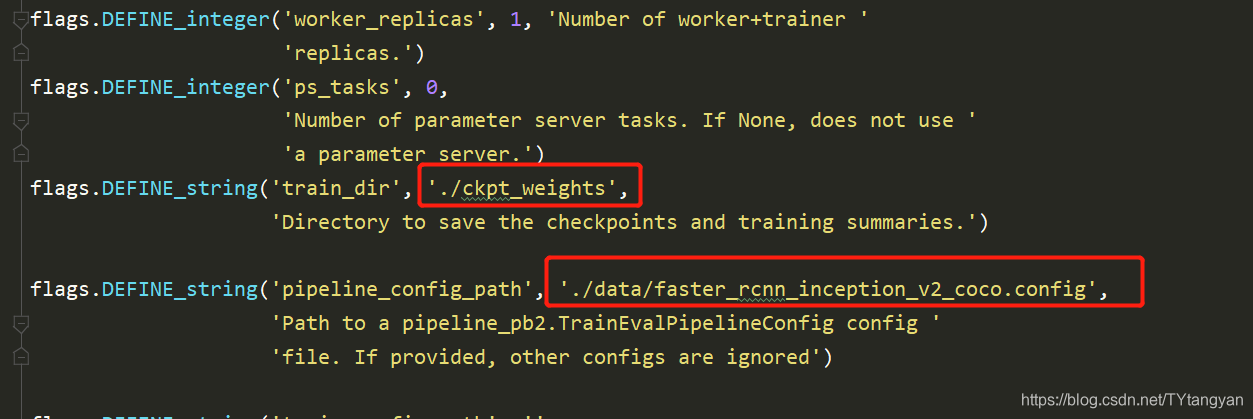
接下来就可以训练了,修改train.py中的两个参数, 输出权重路径 ,这个路径会自动 创建,且需要为空。下面的那个是刚刚设置好的参数路径
 训练。。。。。。。。。。。。。 等待。。。。。。。。。。。。。。
训练。。。。。。。。。。。。。 等待。。。。。。。。。。。。。。
电脑显卡不好的话,这个要等好久了。可以使用tensorboard --logdir=“你的ckptl路径”查看模型训练的loss 等
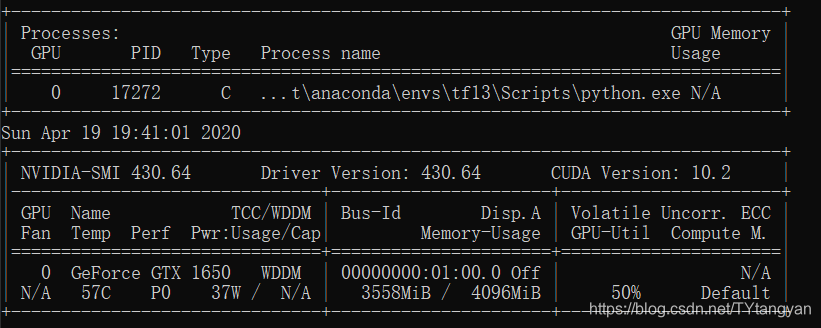
win10 电脑可以直接输入nvidia-smi 查看显卡使用
显卡使用如下,电脑嗡嗡嗡我选择放过我的笔记本。 如果出现gpu使用率为0时候见前面
4.转换pb文件
下图路径的py文件复制,到自己工程
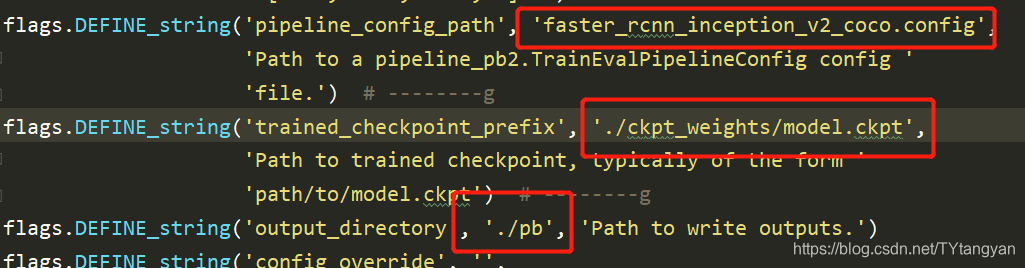
修改其中三处,config路径,刚刚的训练得到的ckpt权重,以及输出pb文件夹的路径,也会自动创建
5.预测
object_detection路径下的object_detection_tutorial.ipynb自己改改
网上好多,待续

















 1382
1382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









