




文章目录
1. in和exists的区别
in:确定给定的值是否与子查询或列表中的值相匹配,in在查询的时候,首先查询子查询的表,然后和外表做一个笛卡尔积,再按照条件进行筛选。
exist:指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。匹配上就将结果放入结果集中。
not exist比not in快。
子查询的表很大时,用exist。
表user:
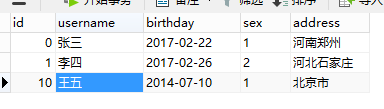
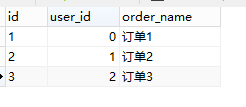
表order:
SELECT
`user`.*
FROM
`user`
WHERE
EXISTS (
SELECT
`order`.user_id
FROM
`order`
WHERE
`user`.id = `order`.user_id
)
2. count()
count(列名),count(*),count(1)
count(*),count(1)统计的是行数。
count()是SQL92定义的标准统计行数的语法,所以用count()。所以会有一些优化,比如在没有where和group by时,MyISAM引擎会直接把表的总行数单独记录下来供count(*)查询,
3. 常用日期函数
datediff(expr1, expr2)返回两个日期相减(expr1 − expr2 )相差的天数:datediff('2019-01-14 14:32:59','2019-01-02')--> 12。time_diff(time1, time2)返回时间差,格式为hh:mm:ss。可利用hour返回时间差的小时值。date_add(date,INTERVAL expr type)date参数是合法的日期表达式。expr参数是您希望添加的时间间隔。type参数是增加的类型,比如day, hour, week:date_add('2008-12-29 16:25:46.635', interval 2 day)--> 2008-12-31 16:25:46.635。date_sub(date,INTERVAL expr type)是相减。date_format(date,format)函数用于以不同的格式显示日期/时间数据:date_format('2021-09-07', '%Y%m%d')--> 20210907
4. 常用字符串函数
-
concat(str1, str2, ……):concat('My', 'S', 'ql')--> MySql -
concat_ws(sep, str1, str2, ……):concat_ws('-', '2019', '09', '07')--> ‘2019-09-07’ -
substr(str, pos, n)从源字符串str中的指定位置pos开始取一个长度为n的字串并返回,如果n省略,则一直到末尾,如果pos为负值表示从源字符串的尾部开始取起:substr('hello world',5)--> ‘o world’;substr('hello world',5,3)--> ‘o w’;substr('a@b.com', -6, 4)--> @b.c -
left(str, len)返回最左边的len长度的子串:left('chinaitsoft',5)--> china。同理,right(str, len)返回最右边的len长度的子串 -
reverse(str)将字符串str反转后返回:reverse('abcdef')--> fedcba -
repeat(str, count)将字符串str重复count次后返回:repeat('MySQL',3)--> MySQLMySQLMySQL -
replace(str, from_str, to_str)在源字符串str中查找所有的子串from_str(大小写敏感),找到后使用替代字符串to_str替换它,返回替换后的字符串:replace('www.mysql.com','w','Ww')--> WwWwWw.mysql.com -
locate(substr, str)函数返回substr在str中出现的位置,如果包含,则返回 >0 的数,否则返回0。可用于hive on的模糊查询,即on locate(a.str, b.str) > 0
5. 常用计算和统计函数
format(x,y)函数,功能是将一个数字x,保留y位小数,并且整数部分用逗号分隔千分位,小数部分进行四舍五入。format(12345678.12345, 4)--> 12, 345, 678.1235。会变成字符串abs(x)求一个数的绝对值:abs(-3)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









