




 本文详细介绍了使用Pandas库在Python中操作DataFrame的方法,包括设置和修改索引、时间序列索引构造、按内容和索引排序等核心操作,适合初学者和进阶者参考。
本文详细介绍了使用Pandas库在Python中操作DataFrame的方法,包括设置和修改索引、时间序列索引构造、按内容和索引排序等核心操作,适合初学者和进阶者参考。
一,设置DataFrame索引值 以及 时间索引如何构造
1,设置DataFrame索引值
import numpy as np
import pandas as pd
day_data = np.random.normal(0,1,(500,507))
# 将数据变成dataframe格式
day_data1 = pd.DataFrame(day_data)
# 构造行索引列表
stock_list = ["股票"+ str(i) for i in range(day_data.shape[0])]
# 构造列索引列表
date = pd.date_range("2018-01-01",periods=day_data.shape[1],freq='B')
# 设置行、列索引
day_data2 = pd.DataFrame(day_data,index=stock_list,columns=date)
print(day_data2)
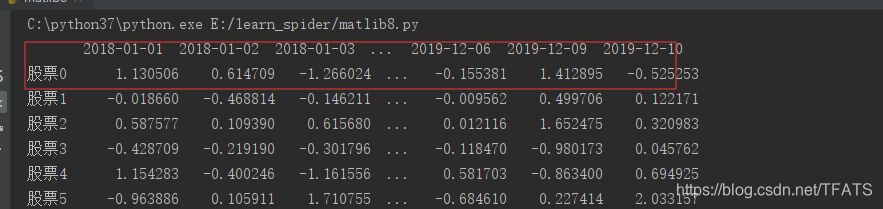
2,时间索引如何构造
pd.date_range():用于生成一组连续的时间序列
date_range(start=None, end=None, periods=None, freq=‘D’)
- start:开始时间
- end:结束时间
- periods:时间天数
- freq:递进单位,默认1天,频率
二,dataframe修改索引
1,直接修改
import numpy as np
import pandas as pd
day_data = np.random.normal(0,1,(500,507 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1405
1405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









