







一 索引(行索引)(index)竖着的
1.索引是什么
1.如果找不到一个有意义的索引,那么在构造 DataFrame 时可以直接省略,pandas 会自动创建一个从 0 开始的整数索引。
2.DataFrame 的行索引或列索引的标签允许存在多个相同的值。
一个 DataFrame 的行索引可以是 ['a', 'b', 'a', 'b'],其中 'a' 和 'b' 各自重复出现两次。
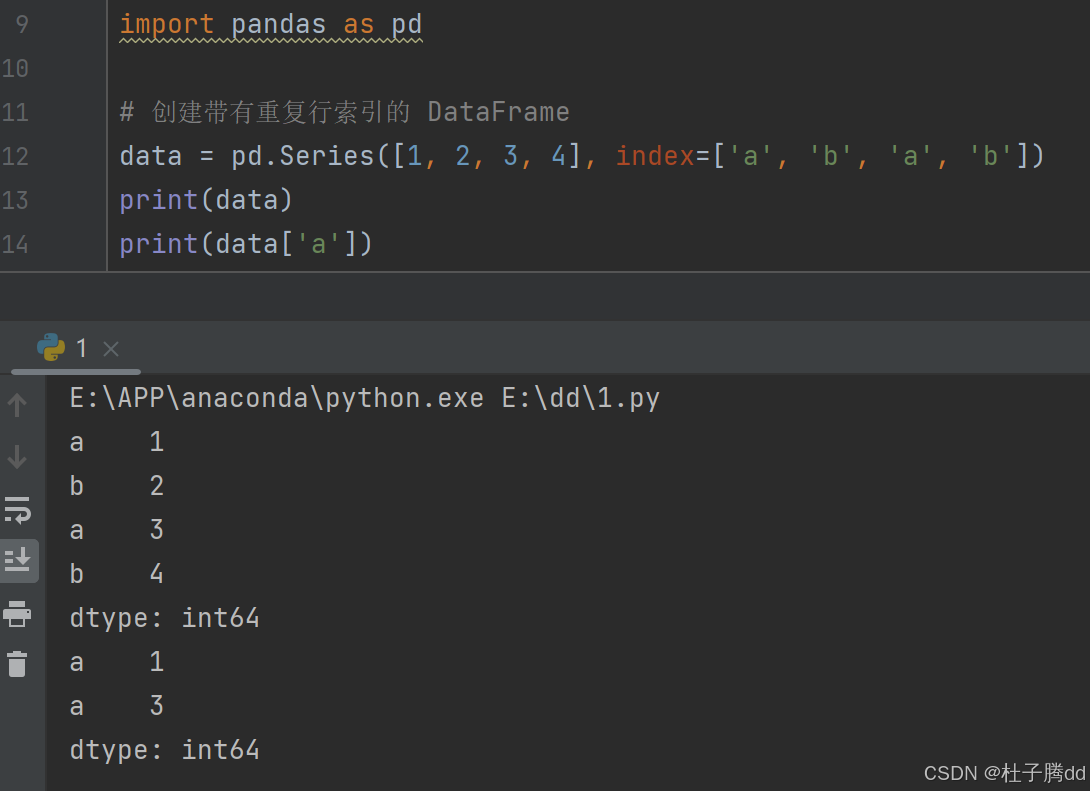
1.允许索引重复的原因
同一时间点可能因多源数据采集而出现重复(如多个传感器的数据合并)。
在分组统计时,多个行可能属于同一分组类别,需要共享同一索引标签。
在数据合并、连接或追加过程中,可能暂时生成重复索引,后续再统一处理。
多级索引中,不同层级可能允许重复,例如国家-城市关系中,不同国家可能有同名城市。
2.如何处理重复索引
在下面 1.3.5 介绍。
2.为什么有索引
索引可以让 pandas 更快地查询数据。
3.如何使用索引
1.获取索引对象
df.index
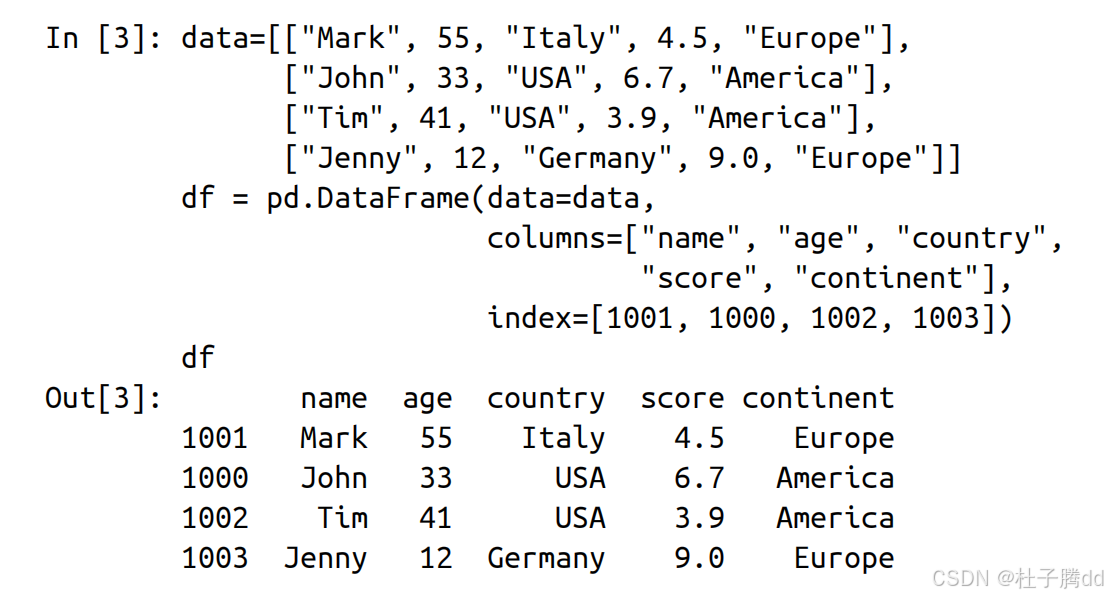

2.给索引取名

3.将索引还原成普通的列
使用 reset_index
4.设置一个新的索引
使用 set_index
当你想将某列设置为新的索引,但同时希望保留原索引(即原索引不丢失,而是作为普通列存在于 DataFrame 中)时,需要先通过 reset_index() 将原索引转换为普通列,再使用 set_index() 设置新索引。否则,原索引会被直接替换或丢弃,无法保留。
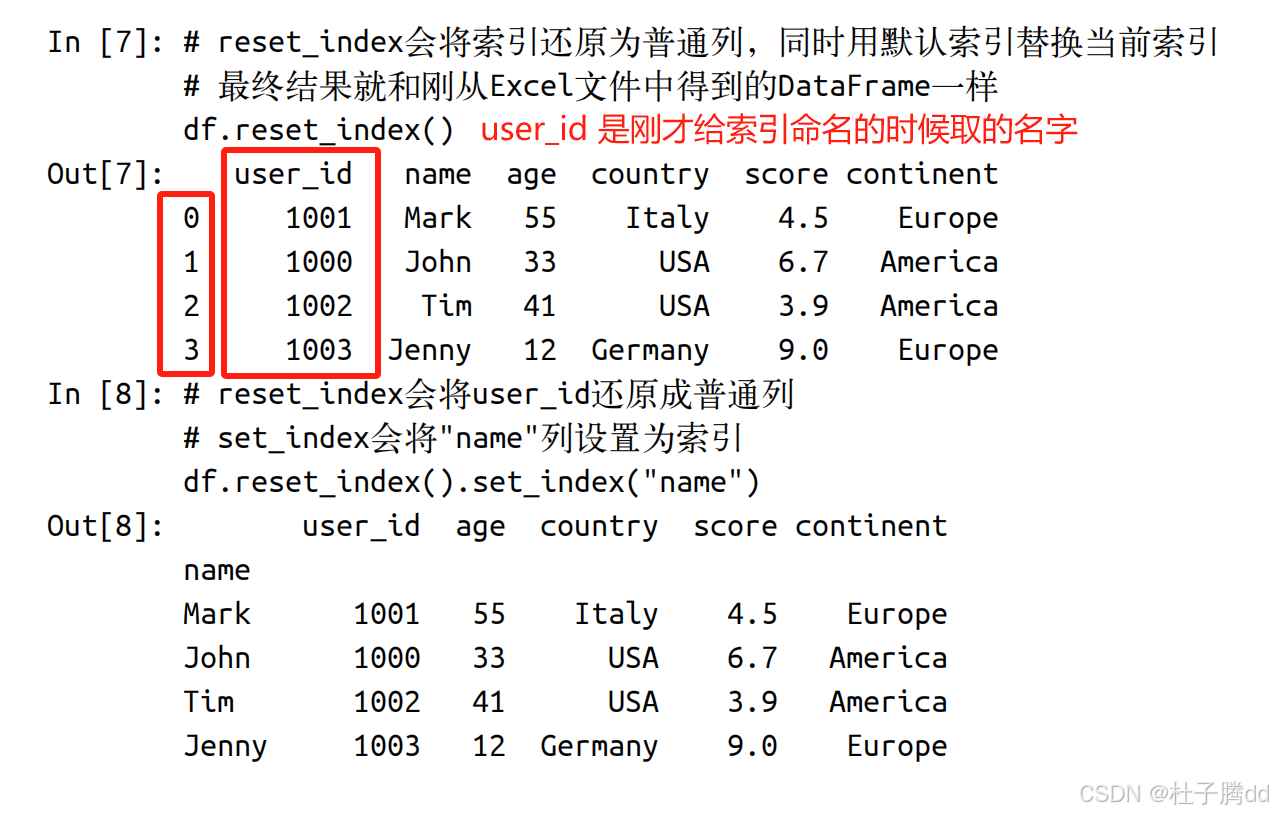
df.reset_index().set_index("name") 这种形式的代码被称为链式方法调用。reset_index() 会返回一个 DataFrame,你可以直接在这个 DataFrame 上调用另一个方法而无须写出中间值。
5.关于重复索引的操作
1.检测重复索引
df.index.duplicated() # 返回布尔数组标记重复索引。
2.删除重复索引
df = df[~df.index.duplicated(keep='first')] # 保留第一个出现的索引。
3.重置索引
df = df.reset_index(drop=True) # 生成新的唯一整数索引。
6.更换索引内容
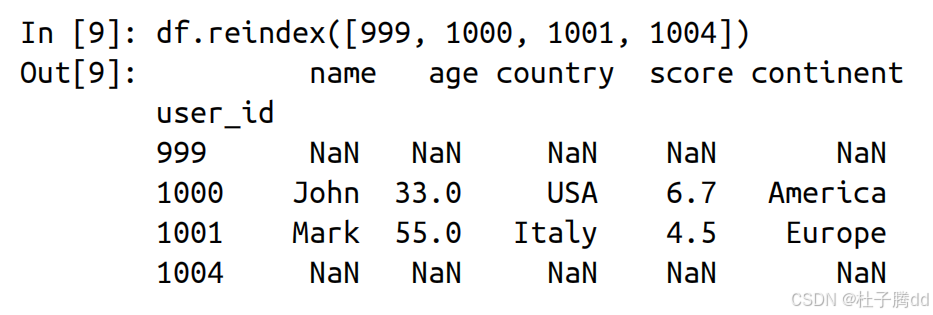
reindex 方法。
reindex 会接管所有能够匹配新索引的行,而无法匹配的索引会引入含有空值(NaN)的行。

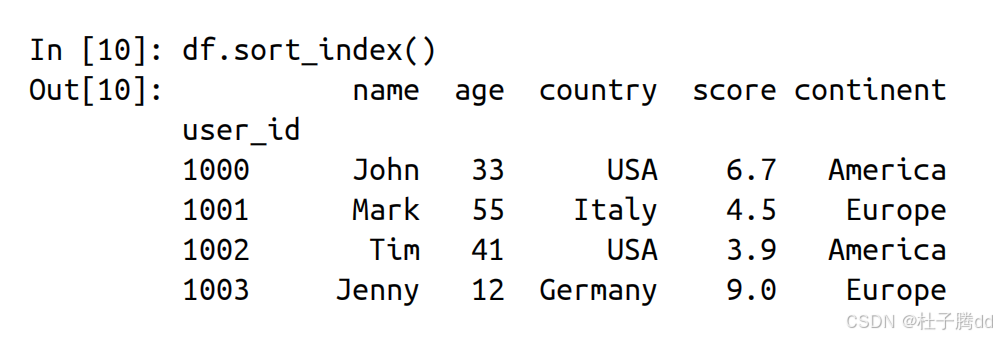
7.按照索引进行排序
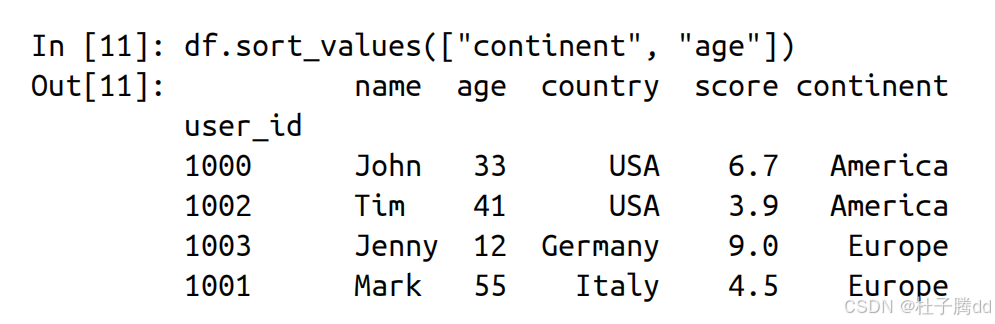
8.按一列或多列进行排序
使用 sort_values
continent 排序,再按 age 排序。
只想按某一列进行排序, 用列名字符串作为参数:
df.sort_values("continent")
二 DataFrame 的列
(columns)横着的
1.查询列的数据类型
使用 df.dtypes
2.获得列的信息

3.给列命名
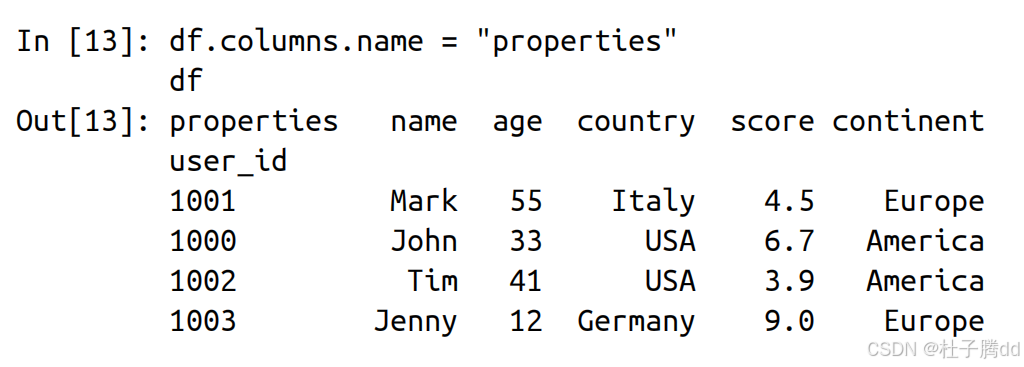
行索引(index)和列索引(columns)可以分别拥有自己的名称(name)。
df.columns.name = "properties"是给列索引(columns)本身设置了一个名称。

3.列名的重命名

4.删除列
删除列的同时删除索引。

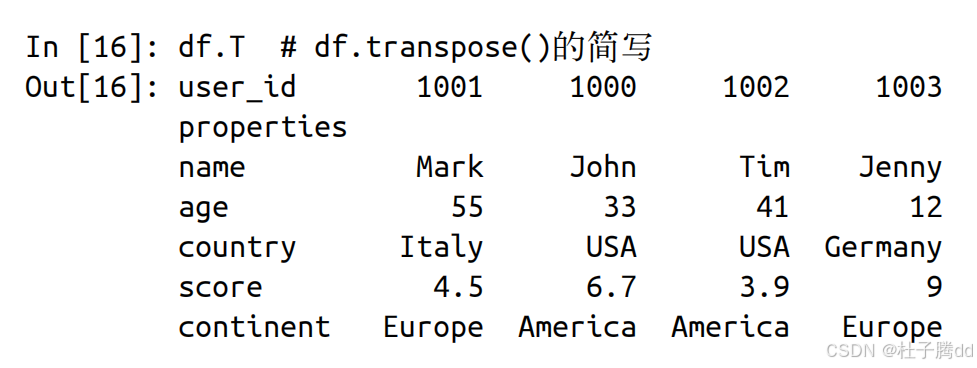
5.通过转置(transpose)可以将行和列对调
6.更改列的顺序
直接给出所需要的列顺序。

三 时序(类似索引,DatetimeIndex)
1.什么是时序
时间序列是按固定时间间隔采集的观测值序列,例如每日气温、每分钟股票价格、每月销售额等。其核心特点是数据点与时间点严格对应,且时间间隔一致(如秒、天、年)。
股票价格分时数据(每分钟记录一次价格)。
家庭每月电费账单(按月统计用电量)。
2.如何使用时序
1.创建时间索引 DatetimeIndex
实际中总是需要将时间戳转换为 DataFrame 的索引,因为以时间戳为索引可以让筛选数据更加简单,所以要创建DatetimeIndex。
1.从字符串列转换成时间索引
当数据源中的时间字段以字符串形式存储时,Pandas 默认会将其读取为字符串类型(object 或 str),而非时间戳类型。此时,所有时间相关的操作(如日期计算、重采样等)将无法直接进行,因为字符串不具备时间序列的属性。
1.用 to_datetime 函数将 DataFrame 中的日期字符串列转换为时间格式,并设为索引。

inplace=True:表示直接在原 DataFrame 上修改,而不返回新的对象。若未设置此参数或设为 False,则需通过赋值接收修改后的新 DataFrame(如 data = data.set_index('Date'))。
下面两行代码可以写成一行:
data.loc[ : , " Data " ] = pd.to_datetime( data [ " Data " ] )
2.用 read_csv 函数读取文件的时候用 parse_dates 参数
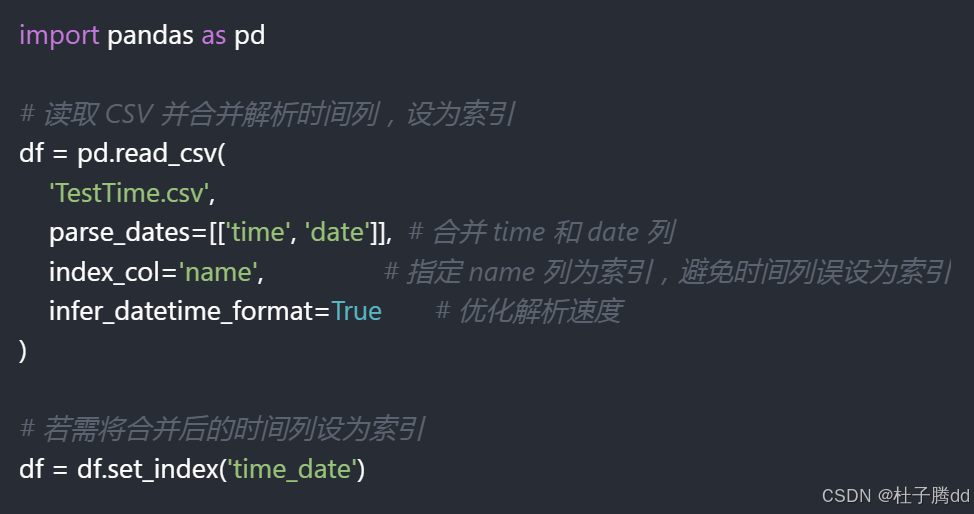
1.parse_dates 参数的作用:解析,把字符串类型变成时间戳类型
接受一个列名列表或者索引作为参数。
parse_dates=['date'] 或 parse_dates=[0](0 表示第一列)
parse_dates=[['time', 'date']],将 time 和 date 两列合并解析为一个完整时间戳(如 2019-10-10 21:33:30),新列名以 time_date 格式命名。
parse_dates={'new_col': ['col1', 'col2']},将指定列合并并重命名。
2.设为索引:把 parse_dates 参数解析后的时间戳类型设置成索引
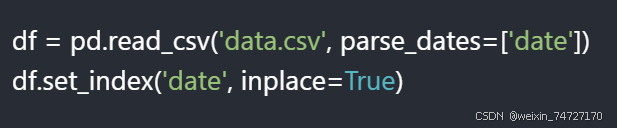
1.index_col 参数:在 read_csv() 中直接指定解析后的时间列为索引。

此时,date 列被转换为时间格式并成为 DataFrame 的行索引。
在 index_col 参数中提供想要用作索引的列名或索引可以省去一次 set_index 调用。
2.set_index() 方法:若读取时未指定索引,后续可通过 set_index() 设置。
注意:
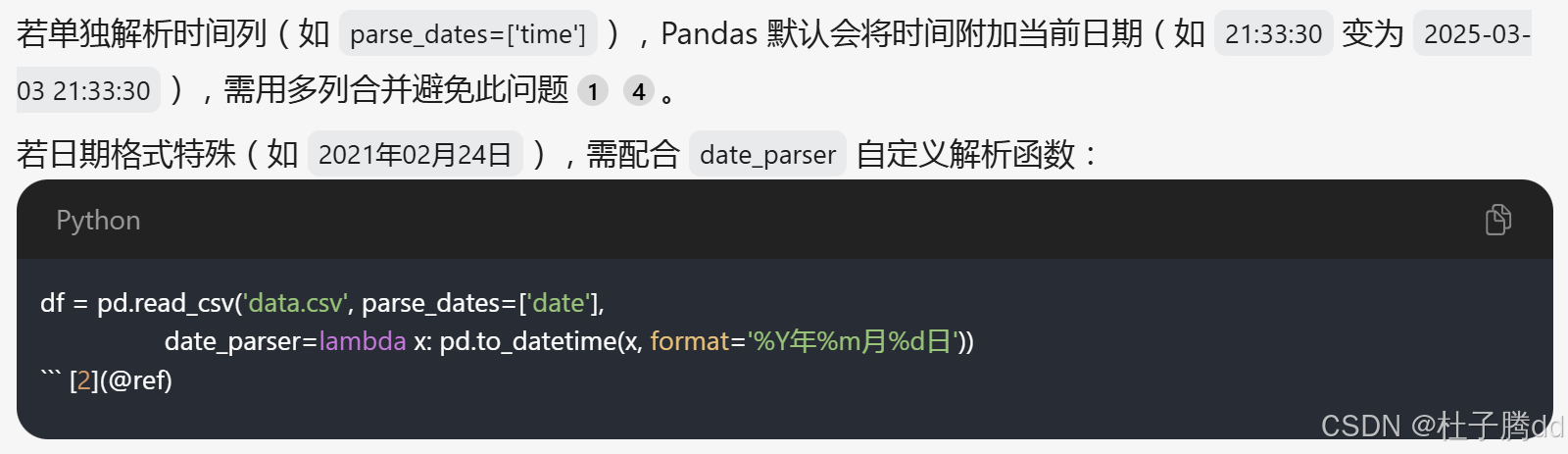
3.拓展:前面是把列转成时间戳数据类型,把其他列转成别的数据类型的方法
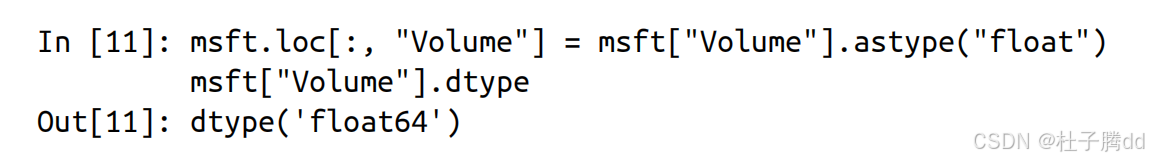
2.另外生成时间索引
使用 pd.date_range() 生成连续时间索引。
接受一个开始日期、一个频率参数,以及周期数或者结束日期。
如果 DataFrame 的索引是日期时间类型(如 pd.date_range('2020-01-01', periods=5)),则可以通过自然的时间字符串(如 '2019-01-01')直接筛选数据。
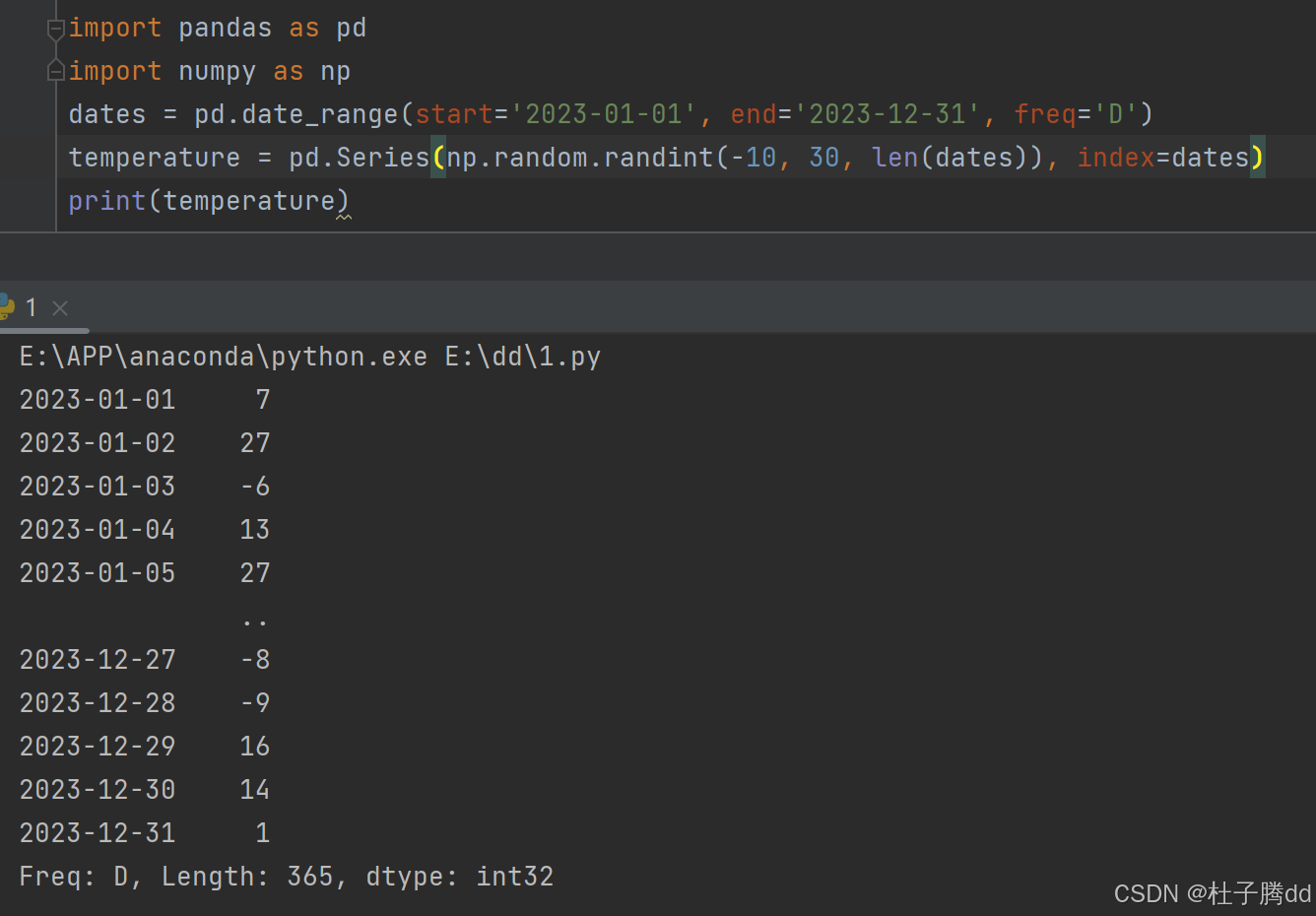
例子1:生成 2023 年每日气温记录的索引。

freq='D':生成频率为“天”(Day),即按天递增。
第2行代码:生成一个带有时间索引的 Pandas Series 对象,模拟某地全年的每日温度数据(随机生成)。
size=len(dates):生成随机数的数量等于日期序列 dates 的长度(全年 365 天)。
pd.Series:Pandas 中表示一维带标签数组的对象。
index=dates:将之前生成的日期序列 dates 设置为索引,实现日期与温度的一一对应。
例子2:
2.处理时序时,在开始分析之前最好确保索引井然有序
3.如果只需要访问 DatetimeIndex 的一部分
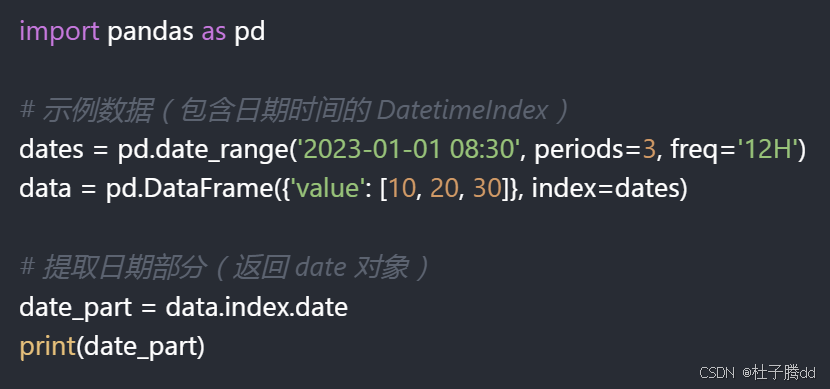
如果 DatetimeIndex 包含日期和时间(例如 2023-01-01 08:30:00),但只需要访问日期部分(如 2023-01-01),可以用 .date 属性提取日期。

4.时间索引的查询与切片
Series 的例子:
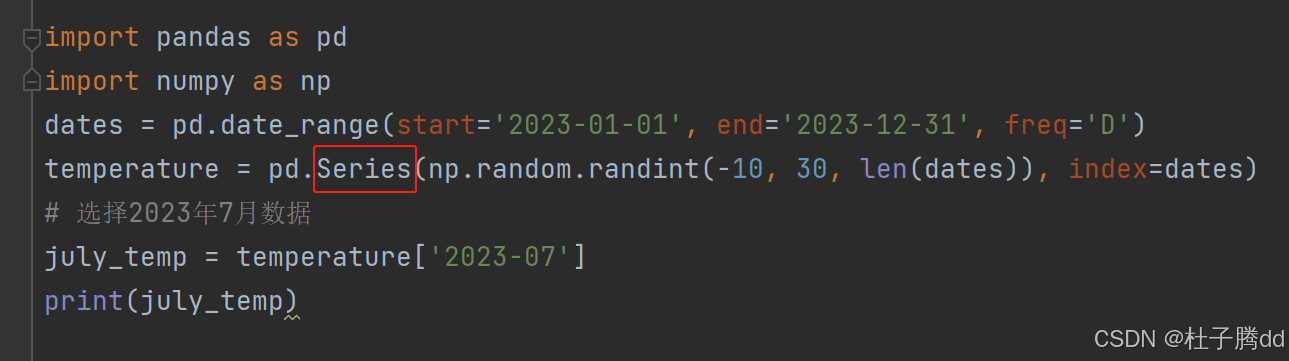

DataFrame 的例子:
在 Pandas 中,当 DataFrame 的索引是 DatetimeIndex(时间日期索引)时,可以通过 loc 方法直接传递时间格式的字符串来快速切片数据。
直接传递 'YYYY-MM-DD' 格式的字符串(如 '2019', '2019-05', '2019-05-01 10:00:00')作为 loc 的参数。Pandas 会自动将字符串解析为时间范围,并返回匹配的行。
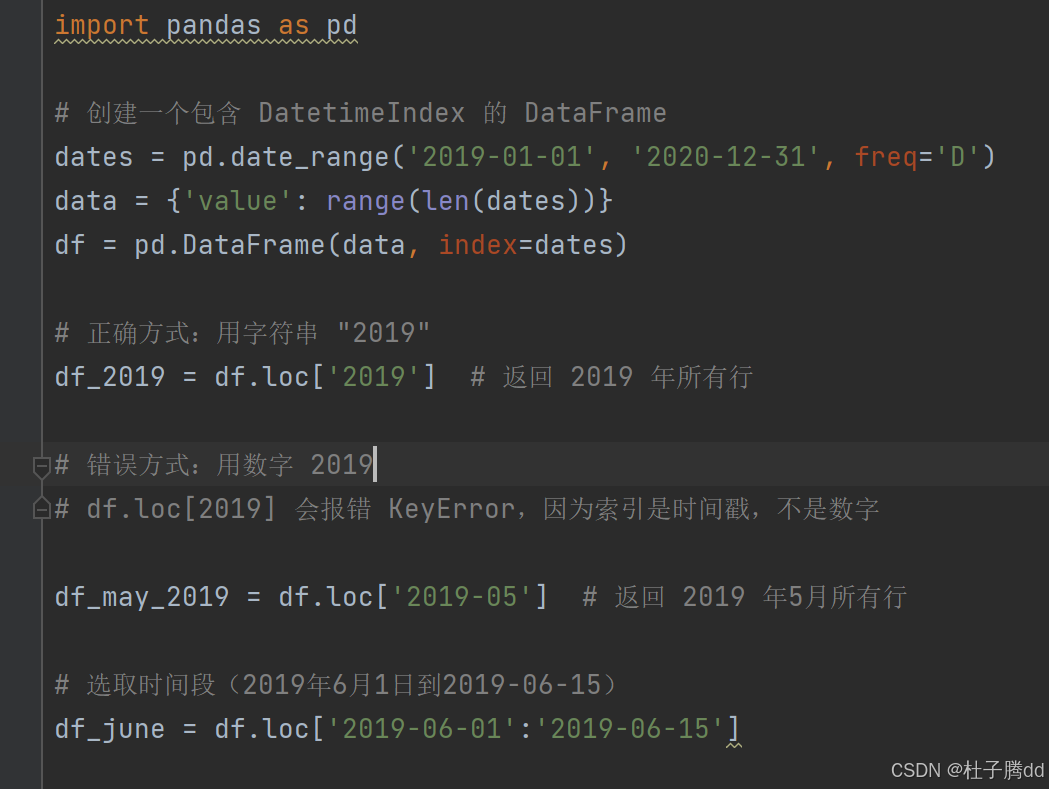
注意:
1.字符串格式必须合法
字符串需要符合 YYYY-MM-DD HH:MM:SS 格式(精度可以灵活调整)。
'2019', '2019-05', '2019-05-01 10:00'。
2.避免用数字代替年份
不能传递数字(如 2019)。
3.时间范围自动闭合
df.loc['2019'] 实际等价于 df.loc['2019-01-01':'2019-12-31']。
Pandas 会自动推断时间范围的起始和结束。
5.更改时序的基数
时序的基数是时间序列数据中的一个参考起点值,用于衡量后续数据相对于这一起点的变化程度。
基数的本质:一个标准化的参考点,用于消除绝对值的干扰。
假设小明记录自己每天的体重,第一天的体重(比如 50kg)就是基数,后续每天的体重会以这一天的值为基准进行比较。
更改基数的核心目的是标准化数据,使得不同时间序列之间更容易比较。
如果两个股票价格分别为 100 元和 1000 元,直接比较绝对值没有意义,但将它们统一转换为“相对于某一天的变化百分比”,就能直观看出涨幅/跌幅趋势。
将数据转换为百分比形式。

例子:减肥进度跟踪
原始数据:小明每天体重(单位:kg)[70, 69, 68, 67, 66](第1天到第5天)
更改基数:以第1天(70kg)为基数,转换为百分比:
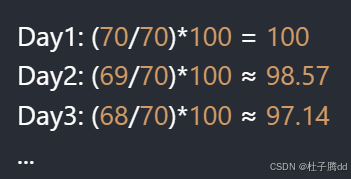
直观看出每天体重相对于初始值的百分比变化(如第5天为 94.29,表示比起点轻了约5.71%)。
在 Excel 中实现:写一个结合了绝对值和相对单元格引用的公式,然后把这个公式复制并粘贴到每一行和每一个时序。
在 pandas 中实现:只需写一个公式即可。

通过广播技术,自动将整个列的值相对于第一个值(df["value"].iloc[0])进行计算。
6.向上 / 向下采样
1.什么是向上 / 向下采样
向上采样指的是将时序的频率提高,而向下采样指的是将时序的频率降低。
在时间序列分析中,上采样是指将低频数据转换为高频数据的过程(例如从月度数据生成周度数据)。然而,这种转换会导致大量时间段缺乏原始数据,从而产生缺失值(NaN)。通过结合 asfreq() 和 ffill() 方法,可以解决这一问题。(在如何向上/向下采样第二点描述)
2.为什么要向上 / 向下采样
发现每日收益率对于你的分析任务来说并不是一个好的选择,你想要改成每月收益率。
超市每日销售额波动大,但月度统计能反映整体业绩是否达标。
不同频率的数据需统一时间粒度才能对比。
将每日气温数据与月度用电量数据结合,分析季节性影响。
3.如何向上 / 向下采样
1.要将每日时序转换为每月时序,可以使用 resample 方法
该方法接受字符串形式的频率参数,比如 M 代表日历月底,可以紧接着调用一个方法指定如何重采样。


聚合函数:sum(), mean(), max(), min() 等。
举例:

通过 resample('M') 将每日数据按月分组,sum() 计算月度总支出,便于制定预算。
2.asfreq() 与 ffill()
上采样是指将低频数据转换为高频数据的过程(例如从月度数据生成周度数据)。然而,这种转换会导致大量时间段缺乏原始数据,从而产生缺失值(NaN)。通过结合 asfreq() 和 ffill() 方法,可以解决这一问题。
通过 asfreq() 和 ffill(),低频数据可快速转换为高频数据,填补分析空白。其核心逻辑是基于历史数据的延续性假设,适用于需要连续时间序列但缺乏高频采集的场景。
asfreq():仅调整时间序列的频率,不填充缺失值。例如将月度数据转为周度数据时,只有月末对应周的数据保留原值,其他周的数据为 NaN 。
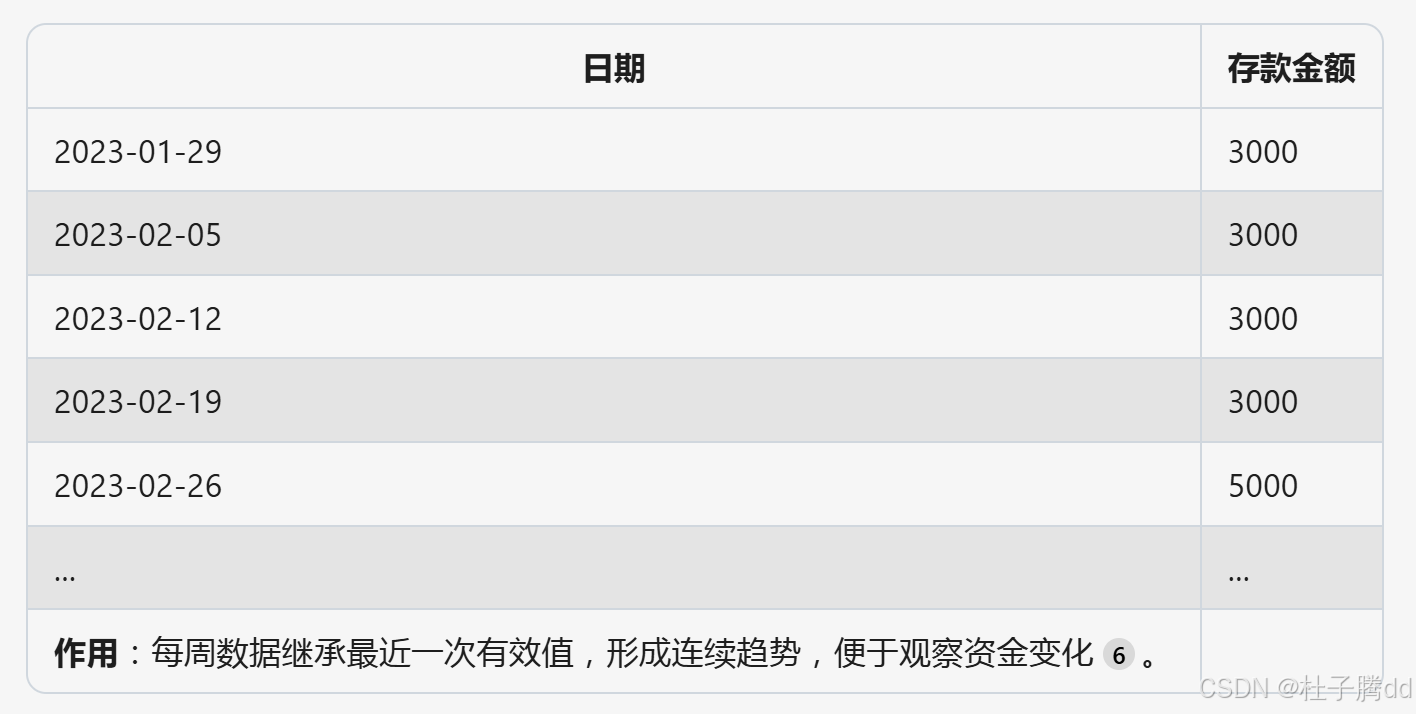
ffill():向前填充,用最近的有效观测值填充后续缺失值。例如,若某月最后一周的销售额为 5000 元,后续缺失的周数据会自动填充为 5000 元,直到下一个月末数据更新。
举例:
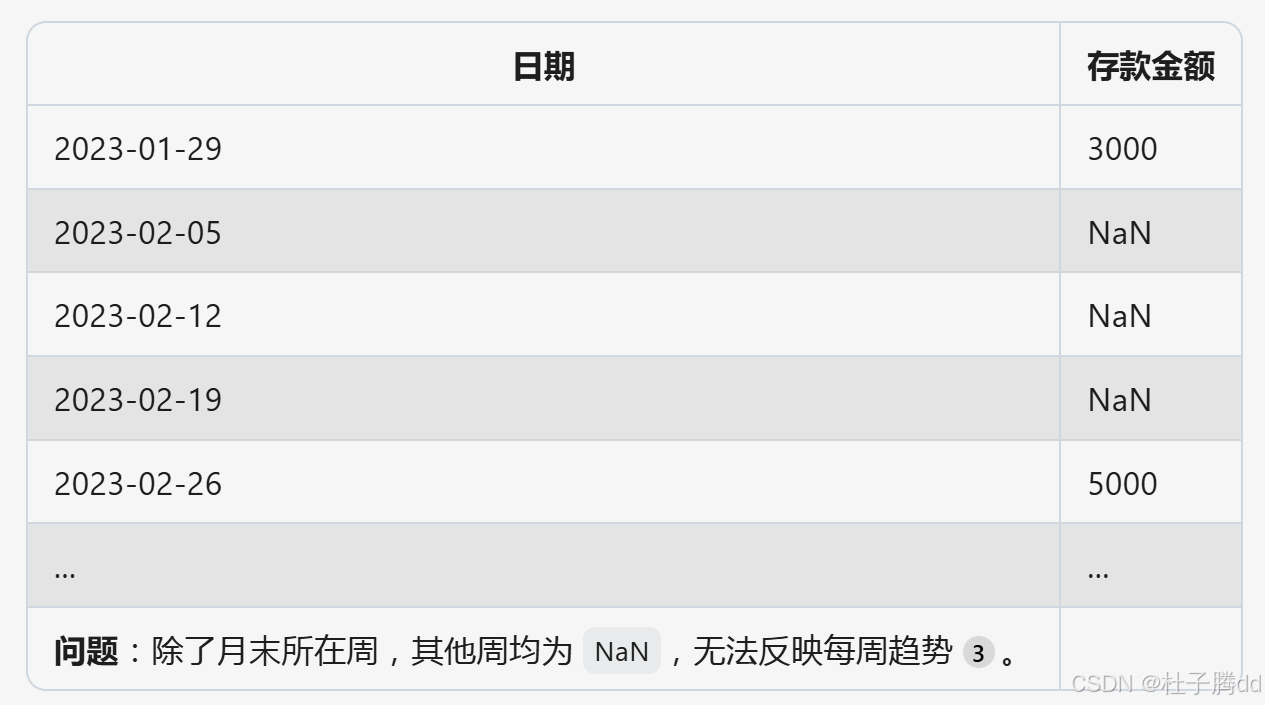
小明每月末记录一次存款金额,但想分析每周的财务状况。原始数据如下:
1月31日:存款 3000 元
2月28日:存款 5000 元
3月31日:存款 7000 元
用 asfreq('W') 上采样为周数据:

用 ffill() 向前填充:

7.移动平均值
1.什么是移动平均值
是一种通过滚动窗口计算局部均值来平滑时间序列数据的方法。
移动平均值 = 滑动窗口内的平均分,它能将「忽高忽低的波动」变成「平缓的趋势线」,就像给数据戴了一副降噪耳机,过滤掉刺耳的杂音,留下清晰的旋律。
2.为什么使用移动平均值
消除短期干扰:
单日数据容易受偶然因素影响(如考试题目太难、天气突变),移动平均能淡化这些干扰。
暴露长期趋势:
通过连续滑动窗口,把碎片化的波动连成一条线,一眼看出数据在上升、下降还是稳定。
公平比较:
不同时间段的数据因外部因素不可比,移动平均能标准化数据,让比较更合理。
3.如何使用移动平均值

定义窗口大小(例如25天),选取连续的子集数据;
计算该窗口内数据的均值;
滑动窗口(例如每天向前移动一次),重复计算均值,形成新的平滑序列。
例子1:体重管理中的趋势分析
小明每天记录体重,但数据波动较大(周末聚餐后体重上升)。直接观察日体重难以判断减肥效果。解决方法:计算7天移动平均体重。

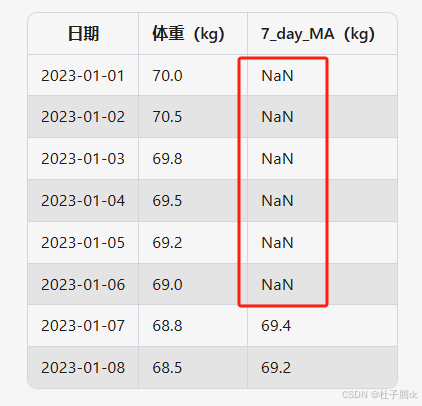
假设df为包含每日体重的DataFrame,在包含每日体重的 DataFrame 中,新增一列 7_day_MA,用于存储过去7天体重的移动平均值。通过滚动窗口(rolling window)计算均值,平滑每日波动,反映体重变化的长期趋势。
df['体重']:从 DataFrame df 中提取名为 “体重” 的列(假设该列存储每日体重数据)。
.rolling(window=7):创建一个滚动窗口计算器,窗口大小为7天。从第1天到第7天为一个窗口,第2天到第8天为下一个窗口,依次滑动。前6天(窗口未填满时)无法计算7日均值,结果为 NaN(缺失值)。rolling接受观测数量作为参数,可以在 rolling 后面链式调用所需的统计量方法,如求和(.sum())、最大值(.max())、标准差(.std())等。对于移动平均值来说就是在 rolling 后面调用 mean。
补充:通过
min_periods参数允许窗口未满时计算部分均值。
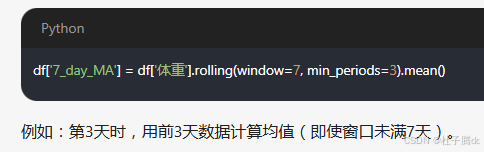
.mean():对每个滚动窗口内的数据计算 算术平均值。第7天的值为第1-7天体重的平均值;第8天的值为第2-8天的平均值,依此类推。
df['7_day_MA'] = ...:将计算结果赋值给 DataFrame 的新列 7_day_MA,存储7日移动平均值。
例子2:学生成绩波动分析
老师统计学生每日测验分数,因题目难度不同,单日分数波动较大。解决方法:计算5次测验的移动平均分,评估真实学习水平。老师可忽略单次低分(如75),关注长期均值是否稳定。
import pandas as pd
import matplotlib.pyplot as plt
# 示例数据:学生每日测验分数(假设日期已排序)
data = {
'日期': ['2023-09-01', '2023-09-02', '2023-09-03', '2023-09-04', '2023-09-05',
'2023-09-06', '2023-09-07', '2023-09-08', '2023-09-09', '2023-09-10'],
'分数': [85, 78, 92, 80, 88, 75, 90, 85, 89, 93]
}
df = pd.DataFrame(data)
df['日期'] = pd.to_datetime(df['日期']) # 转换为日期格式
df.set_index('日期', inplace=True) # 设置日期为索引
# 计算移动平均(窗口大小=5,自动忽略前4天的NaN)
df['5次移动平均'] = df['分数'].rolling(window=5).mean()
# 输出结果
print(df)
'''
分数 5次移动平均
日期
2023-09-01 85 NaN
2023-09-02 78 NaN
2023-09-03 92 NaN
2023-09-04 80 NaN
2023-09-05 88 84.6 # (85+78+92+80+88)/5
2023-09-06 75 82.6 # (78+92+80+88+75)/5
2023-09-07 90 85.0 # (92+80+88+75+90)/5 → 忽略单次75分的影响
2023-09-08 85 83.6
2023-09-09 89 85.4
2023-09-10 93 88.2
'''补充:若数据包含多个学生,使用
groupby分组计算。


















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









