







 本教程介绍如何使用Python的Scrapy框架创建爬虫,包括新建工程、编写爬虫代码、运行爬虫,以及如何提取和存储数据。通过实例讲解start_requests、parse方法、XPath选择器等关键步骤。
本教程介绍如何使用Python的Scrapy框架创建爬虫,包括新建工程、编写爬虫代码、运行爬虫,以及如何提取和存储数据。通过实例讲解start_requests、parse方法、XPath选择器等关键步骤。
基于Python的Scrapy静态网页爬取
- 1.创建工程
- 2.我们的第一个爬虫
- 3.如何运行我们的爬虫
- 4.幕后发生了什么
- 5.start_requests方法的捷径
- 6.提取数据
- 7.XPath简介
- 8.提取引用和作者
- 9.从我们的爬虫中提取数据
- 10.存储爬取的数据
假设你的电脑上已经安装了Scrapy。
这篇教程将会带你学习以下任务:
- 新建一个Scrapy工程
- 编写一个爬虫爬取一个网站并提取数据
- 使用命令行输出爬取的数据
- 将爬虫改成递归跟踪链接(recursively follow links)
- 使用爬虫参数
我们进入正题吧 ~
1.创建工程
在你开始爬取网页数据之前,你需要新建一个Scrapy工程。输入一个你希望存储你的代码的目录并运行。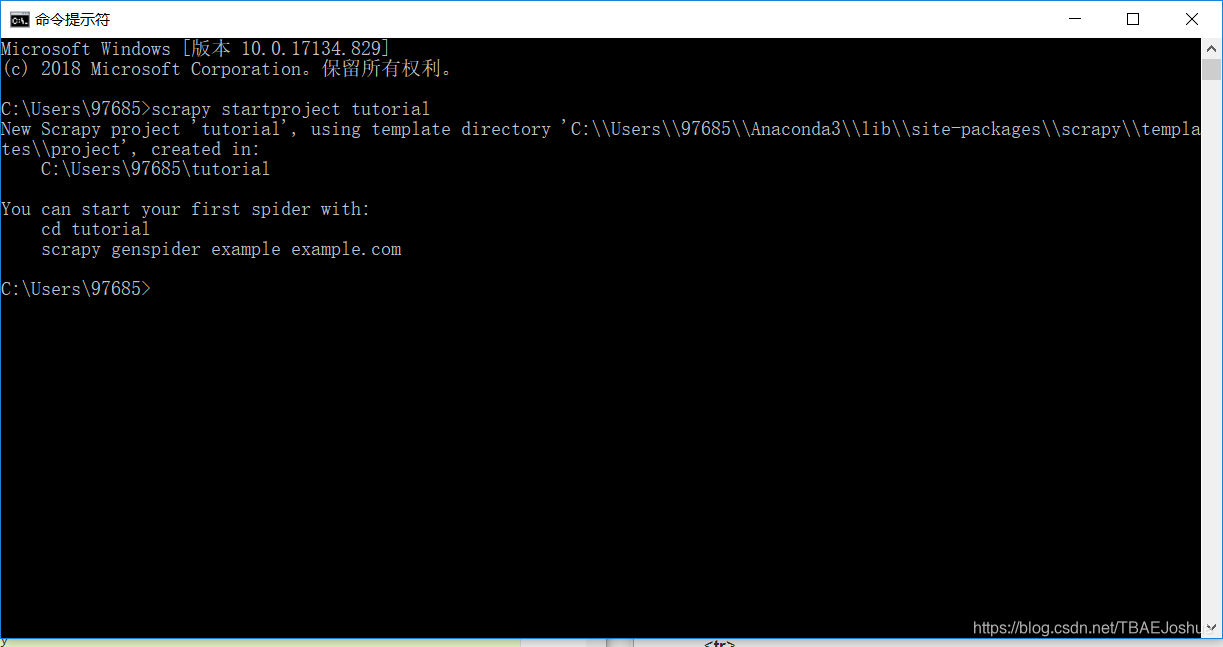
这样会建立一个tutorial目录,包含以下内容:
tutorial/
scrapy.cfg #部署配置文件
tutorial/ #工程的Python模块,你将从这里导入你的代码
__ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1629
1629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









