







RAG项目——物流信息咨询问答系统
0 前言
上篇文章,我们使用的是百度智能云平台(也叫千帆平台)上已经部署好的模型,对一个企业来说,你把模型放到别人的服务器上,会有一定的信息安全隐患,使得自己“受制于人”;另一方面,很多业务场景的生产环境都是隔离,也就是没有联网,这种情况下你很难用类似的公共云服务来进行推理。
因此,在本地或者私有云上进行开发也是大模型开发的一项重要能力。本文以“物流行业信息咨询问答系统”这个项目为载体,介绍一下RAG和私有云开发。
1 RAG及项目介绍
1.1 什么是RAG
2023年以来,随着ChatGPT的火爆,使得LLM成为研究和应用的热点,但是市面上大部分LLM都存在一个共同的问题:模型都是基于过去的经验数据进行训练完成,无法获取最新的知识,以及各企业私有的知识。因此很多企业为了处理私有的知识,主要借助一下两种手段来实现:(1)利用企业私有知识,对开源大模型进行微调;(2)搭建本地知识库,作为大模型的参考知识,即RAG技术。
RAG(Retrieval-Augmented Generation)是一种结合了信息检索技术与语言生成模型的人工智能技术。具体来说,RAG技术通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大型语言模型(LLMs),以增强模型处理知识密集型任务的能力,如问答、文本摘要、内容生成等。这种结合使得生成模型在生成文本时能够参考更多的外部知识,从而提高生成内容的准确性和丰富性。
RAG模型的工作流程大致可以分为以下几个步骤:
检索:使用检索模型从大规模文档库中找到与问题最相关的若干文档。这些文档为生成模型提供了额外的上下文信息。
增强:将检索到的信息用作生成模型(即大语言模型)的上下文输入,以增强模型对特定问题的理解和回答能力。这一步的目的是将外部知识融入生成过程中,使生成的文本内容更加丰富、准确和符合用户需求。
生成:结合大语言模型,利用检索到的信息作为上下文输入,生成符合用户需求的文本内容。
RAG技术的应用场景广泛,主要用于知识密集型的自然语言处理任务,尤其是在需要结合外部知识库的信息生成高质量文本的场景中,如智能客服、知识问答、内容创作等。通过引入RAG技术,这些应用能够提供更准确、更相关、更丰富的回答和文本内容。
1.2 项目原理与功能
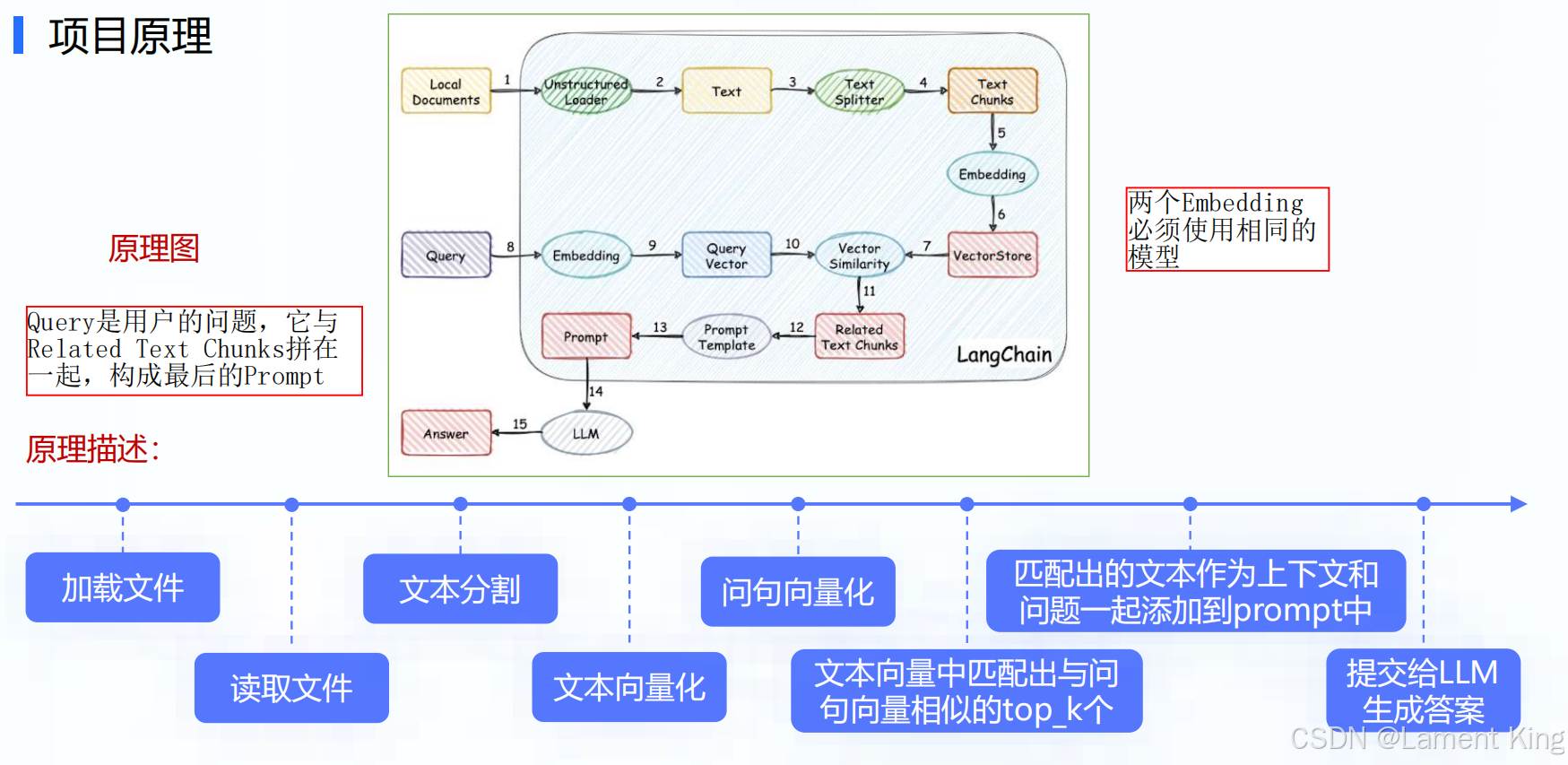

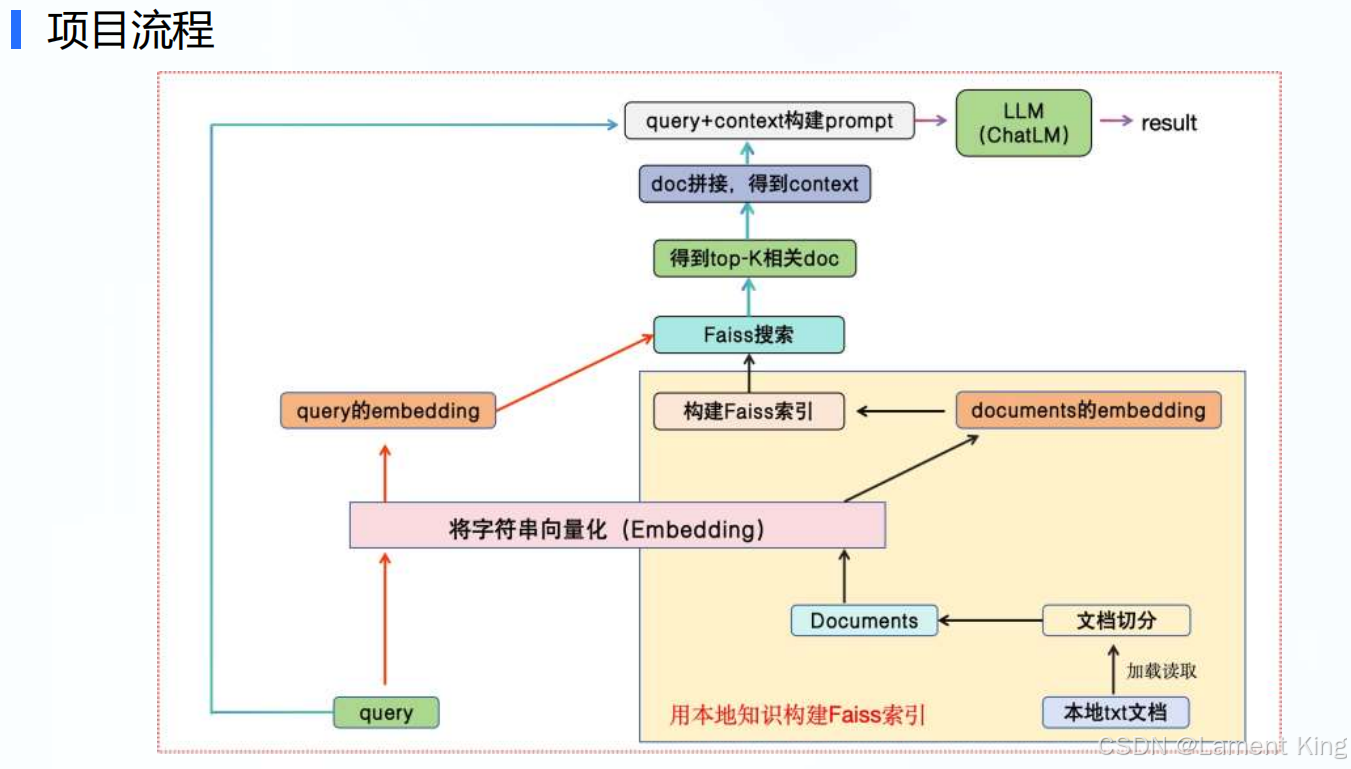
1.3 硬件设备
我们在AutoDL上租算力,显存必须大于8G,使用AutoDL的好处有两个:一是可以通过阿里云胖传输数据,速度可以很快;二是不用显卡的时候,软件环境还得以保留,避免二次开机后重新安装软件依赖(某些云算力平台,每次租用GPU都得重新安装一遍环境,特别费精力)。
2 模型的下载
首先要声明的是,因为模型一般都比较大,为了避免重复的上传于下载,最好是直接下载到部署设备上,本文使用chatglm2-6b-int4模型来演示,实际中可以使用其他模型。
2.1 Hugging Face下载
一般最新的开源大模型,都会发布到Hugging Face,但这个网站并非每次都能进去,因此这里暂不演示。
2.2 魔搭下载
相比于Hugging Face,魔搭平台存在比较大的滞后性,很多新模型在hugging face上线几个月之后,才能在魔搭上看到。
魔搭平台进入后,在模型库中搜索chatglm2-6b-int4
然后点击模型文件
接下来是下载,如果你准备在当前浏览器所在的设备部署,那么可以逐个点击下面的下载按钮,但是不建议这么干,更推荐的是使用modelscope下载(稍后说)。

使用modelscope下载,可以一次性把所有文件下载到指定设备,只需要在指定设备上安装modelscope(pip install modelscope):


模型介绍最好认真看一下,特别是关于软件依赖和代码调用部分,这就相当于是Readme

当然,本项目我们不用大模型的原生接口,而是使用LangChain封装的接口,我们使用的langchain版本为0.1.20,langchain-community版本为0.0.38,安装FAISS时,要指定CPU版本,即pip install faiss-cpu,否则自动安装GPU版。
下载完,用同样的方式下载文本嵌入模型m3e-base
3 项目代码
3.1 项目结构
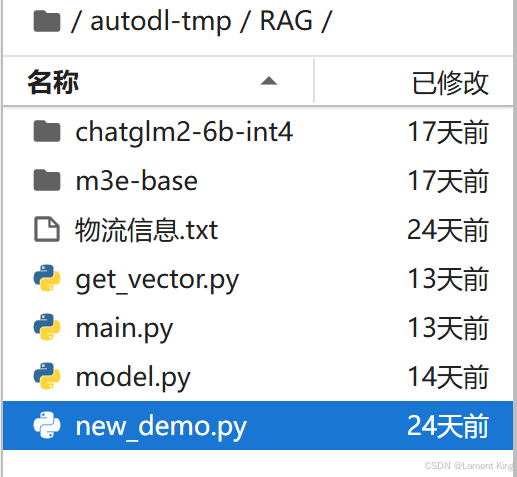
chatglm2-6b-int4是大模型文件的目录,m3e-base是文本嵌入模型的目录,物流信息.txt是我们的知识库,内容如下:
物流公司:速达物流
公司总部:北京市
业务范围:国际快递、仓储管理
货物追踪:
- 货物编号:ABC123456
- 发货日期:2024-06-15
- 当前位置:上海分拨中心
- 预计到达日期:2024-06
-20
运输方式:
- 运输公司:快运通
- 运输方式:陆运
- 出发地:广州
- 目的地:重庆
- 预计运输时间:3天
仓储信息:
- 仓库名称:东方仓储中心
- 仓库位置:深圳市
- 存储货物类型:电子产品
- 存储条件:常温仓储
- 当前库存量:1000件
剩下几个python脚本我们稍后介绍
3.2 文本向量化
这里get_vector.py是将知识库向量化,并把向量数据库保存到本地,内容如下:
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS # 向量数据库
# from langchain.document_loaders import UnstructuredFileLoader
# from langchain.text_splitter import RecursiveCharacterTextSplitter
# from langchain.embeddings import HuggingFaceEmbeddings
# from langchain.vectorstores import FAISS # 向量数据库
def main():
# 定义向量模型路径
EMBEDDING_MODEL = './m3e-base'
# 第一步:加载文档:
loader = UnstructuredFileLoader('物流信息.txt')
data = loader.load()
# print(f'data-->{data}')
# 第二步:切分文档:
text_split = RecursiveCharacterTextSplitter(chunk_size=128, chunk_overlap=4)
split_data = text_split.split_documents(data)
# print(f'split_data-->{split_data}')
# 第三步:初始化huggingface模型embedding
embeddings = HuggingFaceEmbeddings(model_name=EMBEDDING_MODEL)
# 第四步:将切分后的文档进行向量化,并且存储下来
db = FAISS.from_documents(split_data, embeddings)
db.save_local('./faiss/camp') # 保存目录
return split_data
if __name__ == '__main__':
split_data = main()
print(f'split_data')
for content in split_data:
print(content.page_content)
break
输出
split_data
物流公司:速达物流
公司总部:北京市
业务范围:国际快递、仓储管理
货物追踪:
货物编号:ABC123456
发货日期:2024
06
15
当前位置:上海分拨中心
预计到达日期:2024
06
20
运输方式:
运输公司:快运通
运输方式:陆运
出发地:广州
目的地:重庆
预计运输时间:3天
仓储信息:
仓库名称:东方仓储中心
仓库位置:深圳市
存储货物类型:电子产品
存储条件:常温仓储
当前库存量:1000件
程序运行结束之后,当前目录会多出一个名为faiss的文件夹,里面是向量数据库。
3.2 模型类
接下来我们看看model.py,代码如下:
from langchain.llms.base import LLM
from langchain.llms.utils import enforce_stop_tokens
from transformers import AutoTokenizer, AutoModel
from typing import List, Optional, Any
# 自定义GLM类
class ChatGLM2(LLM):
max_token: int = 4096
temperature: float = 0.8
# temperature 是用于控制模型输出概率分布的参数,具体来说:
# 温度值越高(例如:1.0 或更高),模型生成的文本将更加多样化和随机,但可能会降低生成文本的质量和连贯性。
# 温度值越低(例如:0.1 或更低),模型生成的文本将更加确定和集中,通常会生成更保守、更可预测的结果。
# temperature一般取0.7或者0.8
top_p = 0.9 # 这里不用top-k,而是概率,即知识库中,待选的chunks,必须与query的相似度之和必须小于等于0.9
tokenizer: object = None
model: object = None
history = []
def __init__(self):
super().__init__()
@property
def _llm_type(self) -> str:
return "custom_chatglm2"
# 定义load_model的方法
def load_model(self, model_path=None):
# 加载分词器
self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 加载模型
self.model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
# 定义_call方法:进行模型的推理
def _call(self,prompt: str, stop: Optional[List[str]] = None) -> str:
# 使用模型进行对话
response, _ = self.model.chat(self.tokenizer,
prompt,
history=self.history,
temperature=self.temperature,
top_p=self.top_p)
# 如果有停止词,则应用停止词,但一般不去设置
if stop is not None:
response = enforce_stop_tokens(response, stop)
# 更新对话历史
self.history = self.history + [[None, response]]
return response
if __name__ == '__main__':
llm = ChatGLM2()
llm.load_model(model_path=r'chatglm2-6b-int4')
print(f'llm--->{llm}')
print(llm("1+1等于几?"))
输出:
llm--->ChatGLM2
Params: {}
--------------------------------------------------
1+1等于2。
了解transformers框架的,基本能看懂上述代码,这里自定义的模型类继承了langchain.llms.base.LLM,这里最重要的是要实现_call方法。
假如这里把_call方法改成__call__,是不是可以不继承langchain.llms.base.LLM呢?这样改了之后,这个脚本运行起来是没有问题的,但实例化后的模型对象就无法使用invoke方法了。
这里有个要说的top_p,如果大模型用的多了,细心的朋友会发现,即便是相同的输入,每次获得的结果也未必一致,关键原因是temperature和top-p两个参数:
temperature:控制生成结果的随机性。较高的温度值(如0.8或1.0)会让模型生成更多样化、更随机的结果;较低的温度值(如0.1或0.2)会让模型生成更确定、更保守的结果。
top-p (Nucleus Sampling):限制生成时只从累积概率达到某个阈值的词汇中采样。
在top-p之前,用的比较多的是top-k,两种取词策略不一样。
模型获得输入之后,生成的第一个词究竟该是什么?此时模型会得到一堆候选词及其概率,top-k则是从这里选取概率最大的k个词,然后对这k个候选词进行概率归一化,最后对这些词,按照归一化的概率随机取一个,作为第一个词,接下来按照相同的方式取第二个、第三个,直到取到停止符或者达到长度上限。对于top-p,则对所有 token 按照概率降序排序,然后依次累加 token 的概率,直到累积概率达到或超过设定的阈值 P,最终保留这些累积概率达到 P 的 token作为候选词,随后进行概率归一化并随机取词。
3.3 模型推理
模型推理时,就是根据问题,从知识库中找到与问题最接近的文档块,然后与问题拼接成提示词,并送入到大模型中。代码如下:
# coding:utf-8
from langchain.prompts import PromptTemplate
from get_vector import *
from model import ChatGLM2
# 加载FAISS向量库
EMBEDDING_MODEL = './m3e-base'
embeddings = HuggingFaceEmbeddings(model_name=EMBEDDING_MODEL)
db = FAISS.load_local(r'faiss/camp',embeddings,allow_dangerous_deserialization=True)
def get_related_content(related_docs):
related_content = []
for doc in related_docs:
related_content.append(doc.page_content.replace('\n\n', '\n'))
return '\n'.join(related_content)
def define_prompt():
question = '我买的商品ABC123456来自于哪个仓库,从哪出发的,预计什么到达'
docs = db.similarity_search(question, k=3) # 这里把k设置成1,则很容易导致有效信息不足
# 这里把k设置成3,大模型的回答为:根据提供的信息,您买的商品ABC123456来自于东方仓储中心,存储于深圳市,预计从广州出发,预计运输时间为3天。
# 也不是说k越大就越好,太大的情况下,会导致prompt截断,并且还会导致处理时间变长,一般k设置为3或4
# print(f'docs-->{docs}')
related_docs = get_related_content(docs)
# 构建模板
PROMPT_TEMPLATE = """
基于以下已知信息,简洁和专业的来回答用户的问题。不允许在答案中添加编造成分。
已知内容:
{context}
问题:
{question}"""
prompt = PromptTemplate(input_variables=["context", "question"],
template=PROMPT_TEMPLATE)
my_prompt = prompt.format(context=related_docs,
question=question)
return my_prompt
def qa():
# 创建模型对象并导入相关文件
llm = ChatGLM2()
llm.load_model('chatglm2-6b-int4')
# 构建提示词
my_prompt = define_prompt()
print(my_prompt)
print('-'*50)
# 推理
result = llm(my_prompt)
return result
if __name__ == '__main__':
result = qa()
print(f'result-->{result}')
输出
基于以下已知信息,简洁和专业的来回答用户的问题。不允许在答案中添加编造成分。
已知内容:
物流公司:速达物流
公司总部:北京市
业务范围:国际快递、仓储管理
货物追踪:
货物编号:ABC123456
发货日期:2024
06
15
当前位置:上海分拨中心
预计到达日期:2024
06
20
运输方式:
运输公司:快运通
运输方式:陆运
出发地:广州
目的地:重庆
预计运输时间:3天
仓储信息:
仓库名称:东方仓储中心
仓库位置:深圳市
存储货物类型:电子产品
存储条件:常温仓储
当前库存量:1000件
问题:
我买的商品ABC123456来自于哪个仓库,从哪出发的,预计什么到达
--------------------------------------------------
result-->根据提供的信息,商品ABC123456来自于东方仓储中心,存储于深圳市,发货地为广州,预计运输时间为3天。
当然,因为模型不太稳定,有的时候模型的输出可能会是这个样子:
result-->抱歉,我无法回答该问题。根据提供的信息,我无法获得关于ABC123456商品的任何相关信息。建议您联系速达物流以获取更多帮助。
这段代码没啥好讲的了,如果上一篇文章掌握了,这个看懂并不难。
如果我把qa()修改一下,新的代码如下:
def qa():
# 创建模型对象并导入相关文件
llm = ChatGLM2()
llm.load_model('chatglm2-6b-int4')
# 构建提示词
my_prompt = define_prompt()
messages = [ChatMessage(content=my_prompt, role='user')]
print('-'*50)
# 推理
result = llm.invoke(messages)
return result
输出为
result-->根据提供的信息,商品ABC123456来自于东方仓储中心,存储于深圳市,预计将于2024年06月15日从广州出发,预计运输时间为3天。
之所以能得到有效的输出,是因为ChatGLM2类继承了langchain.llms.base.LLM

















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









