






一、LLM核心概念
LLM是利用深度学习和大数据训练的人工智能系统,专门设计来理解、生成和回应自然语言。这些模型通过分析大量的文本数据来学习语言的结构和用法,从而能够执行各种语言相关任务。以GPT系列为代表,LLM以其在自然语言处理领域的卓越表现,成为推动语言理解、生成和应用的引擎。LLM在多个领域都取得了令人瞩目的成就。在自然语言处理领域,GPT系列模型在文本生成、问答系统和对话生成 等任务中展现出色的性能。在知识图谱构建、智能助手开发等方面,LLM技术也发挥了关键作用。此外,它还在代码生成、文本摘要、翻译等任务中展现了强大的通用性。
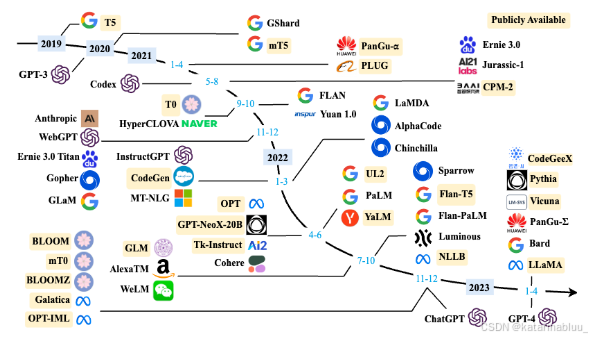
二、LLM架构
1.高层视角(High-level view:)
编码器encoder-解码器decoder的Transformer架构,特别是仅有解码器的GPT架构,几乎所有流行LLM都应用了该架构。
2.令牌化(Tokenization)
如何将原始文本数据转换成模型能理解的格式,这包括将文本拆分成Token(通常是单词或子词)。
3.注意力机制(Attention mechanisms)
掌握注意力机制的理论,包括自注意力和缩放点积注意力,这使得模型能够在产生输出时关注输入的不同部分。
4.文本生成(Text generation)
模型生成输出序列的多种方式。常见方法包括了贪婪解码(greedy decoding)、束搜索(beam search)、top-k采样(top-k sampling,)和核心采样(nucleus sampling)。
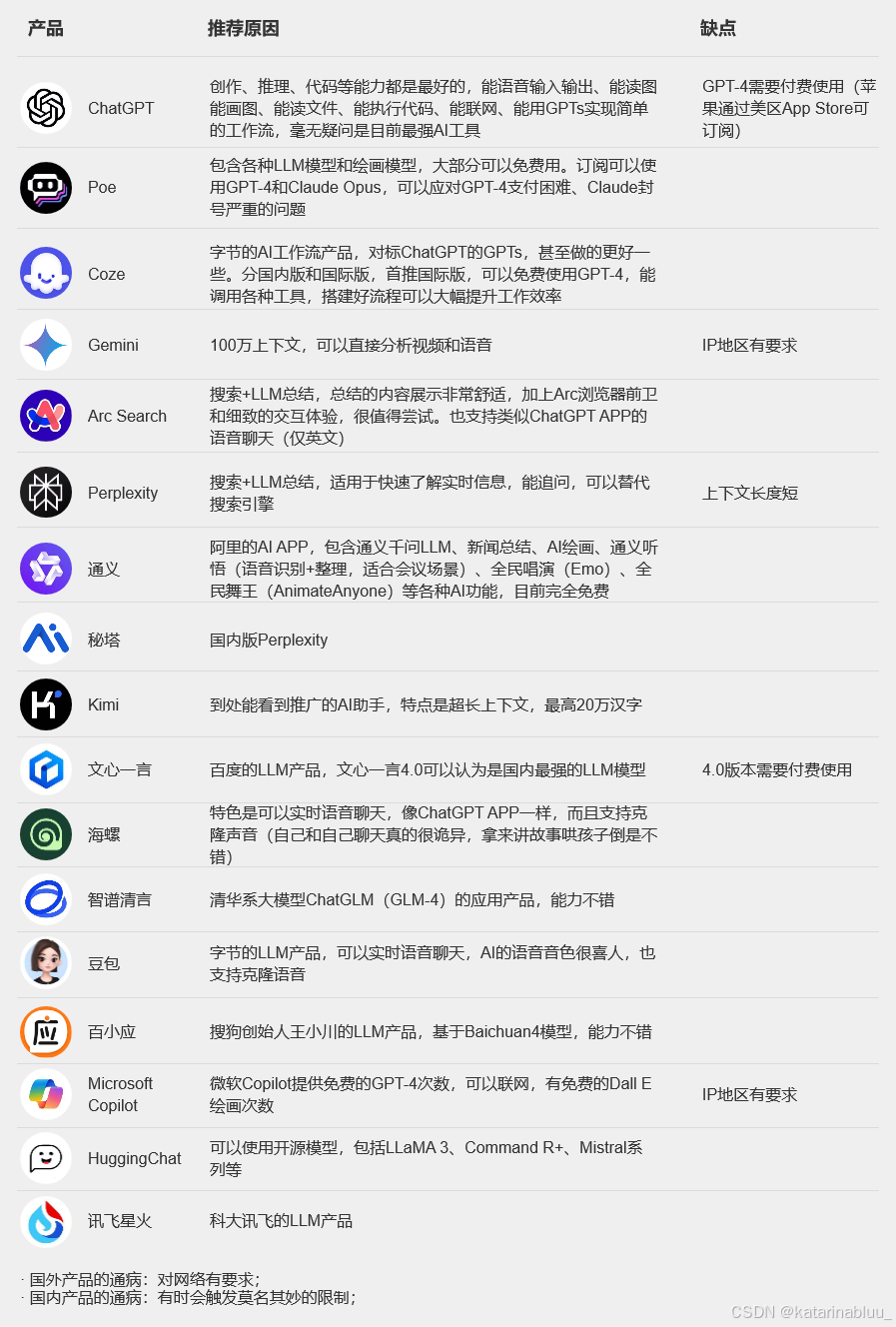
三、LLM产品和模型推荐
四、LLM的特点
LLM具有多种显著特点,这些特点使它们在自然语言处理和其他领域中引起了广泛的兴趣和研究。
1.巨大的规模
LLM通常具有巨大的参数规模,可以达到数十亿甚至数千亿个参数。这使得它们能够捕捉更多的语言知识和复杂的语法结构。
2.预训练和微调
LLM采用了预训练和微调的学习方法。它们首先在大规模文本数据上进行预训练(无标签数据),学会了通用的语言表示和知识,然后通过微调(有标签数据)适应特定任务,从而在各种NLP任务中表现出色。
3.上下文感知
LLM在处理文本时具有强大的上下文感知能力,能力理解和生成依赖于前文的文本内容。这使得它们在对话、文章生成和情境理解方面表现出色。
4.多语言支持
LLM可以用于多种语言,不仅限于英语。它们的多语言能力使得跨文化和跨语言的应用变得更加容易。
5.多模态支持
一些LLM已经扩展到支持多模态数据,包括文本、图像和语音。这意味着它们可以理解和生成不同媒体类型的内容,实现更多样化的应用。
6.涌现能力
LLM表现出令人惊讶的涌现能力,即在大规模模型中出现但在小型模型中不明显的性能提升。这使得它们能够处理更复杂的任务和问题。
7.多领域应用
LLM已经被广泛应用于文本生成、自动翻译、信息检索、摘要生成、聊天机器人、虚拟助手等多个领域,对人们的日常生活和工作产生了深远的影响。
五、挑战与优化方向
1.关键瓶颈
幻觉问题:生成内容与事实不符(如虚构参考文献、错误数据),制约可信度。
效率限制:长上下文窗口(如数万token用户行为序列)导致推理延迟与成本飙升。
2.技术优化
检索增强生成(RAG):结合外部知识库检索,提升生成内容准确性与时效性。
模型轻量化:采用Adapter微调、MoE架构(混合专家系统)降低算力需求。
要么驾驭AI,要么被AI碾碎
当DeepSeek大模型能写出比80%人类更专业的行业报告,当AI画师的作品横扫国际艺术大赛,这场变革早已不是“狼来了”的寓言。2025年的你,每一个逃避学习的决定,都在为未来失业通知书签名。
记住:在AI时代,没有稳定的工作,只有稳定的能力。今天你读的每一篇技术文档,调试的每一个模型参数,都是在为未来的自己铸造诺亚方舟的船票。
1.AI大模型学习路线汇总

L1阶段-AI及LLM基础
L2阶段-LangChain开发
L3阶段-LlamaIndex开发
L4阶段-AutoGen开发
L5阶段-LLM大模型训练与微调
L6阶段-企业级项目实战
L7阶段-前沿技术扩展
2.AI大模型PDF书籍合集

3.AI大模型视频合集
4.LLM面试题和面经合集
5.AI大模型商业化落地方案

📣朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 546
546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









