



百亿私募九坤投资设立的至知创新研究院发布并开源了一系列编码模型。


其中40B-Loop模型在多项基准上超越了Claude 4.5 Sonnet。
代码智能的动态进化
Claude 4.5 Sonnet为代表的专有闭源模型,它们在处理复杂的、多文件的代码库时表现出的逻辑推理能力令人惊叹。
开源模型虽然进步神速,但在长程推理和智能密度上仍显吃力。
至知创新研究院的IQuest-Coder团队通过IQuest-Coder-V1系列模型(涵盖7B、14B、40B及40B-Loop版本)试图填补这一空白。
IQuest-Coder-V1-40B模型在主要的编码基准测试中取得了最先进的结果,在代理软件工程、竞技编程和复杂工具使用方面表现出色,并且向社区开放了从预训练基础到最终微调模型的完整检查点链条。
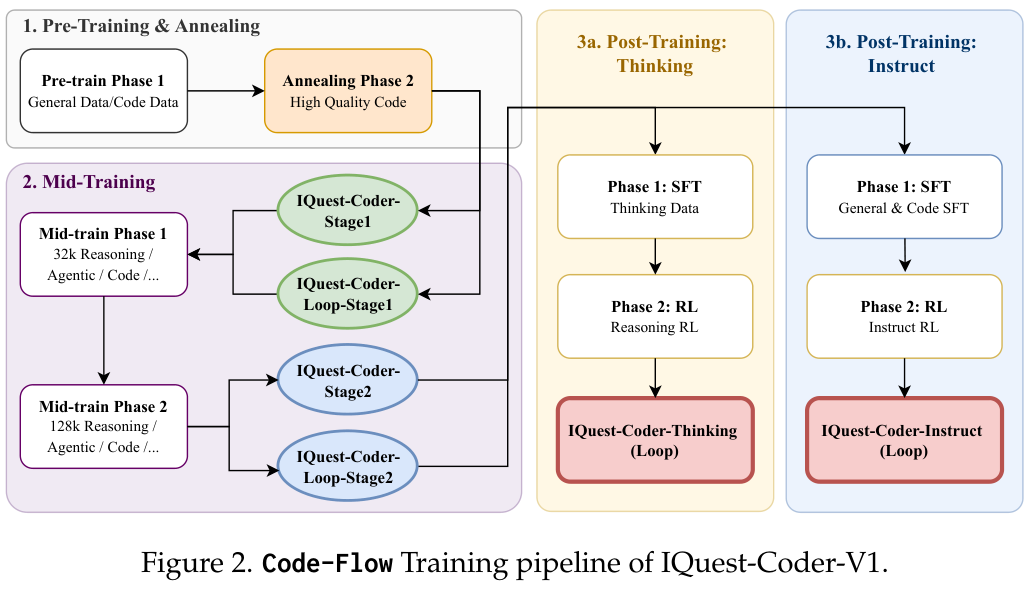
IQuest-Coder团队提出了一种被称为代码流(Code-Flow)的多阶段训练范式,旨在捕捉软件逻辑在不同开发阶段的动态演变。
这种演变始于预训练阶段,团队没有简单地堆砌数据,而是精心构建了一个包含代码事实、存储库和补全数据的进化管道。
这种对数据流动性的关注,源于一个深刻的洞察:存储库的转换数据(即代码提交的流向)比起单纯的静态文件快照,能为模型提供更优越的任务规划信号。
为了构建这种高质量的数据,团队采用了基于项目生命周期的三元组构建策略。
系统会选择处于成熟开发期(项目生命周期的40%-80%)的提交作为起点,这个阶段的代码库相对稳定,避开了早期开发的剧烈波动和后期维护的细碎修补,从而让模型学习到真实的软件开发模式。
在预训练阶段,一个极其有趣的发现是编程语言之间的协同效应。
通常人们认为多语言训练只是简单地混合,但IQuest-Coder的研究表明,优先混合语法相关的编程语言比单纯对单一语言进行上采样能带来更大的提升。
这是一种跨语言的知识迁移,也是一种隐式的数据增强。
为了量化这种效应,团队构建了一个协同增益矩阵(Synergy Gain Matrix),如下表所示。
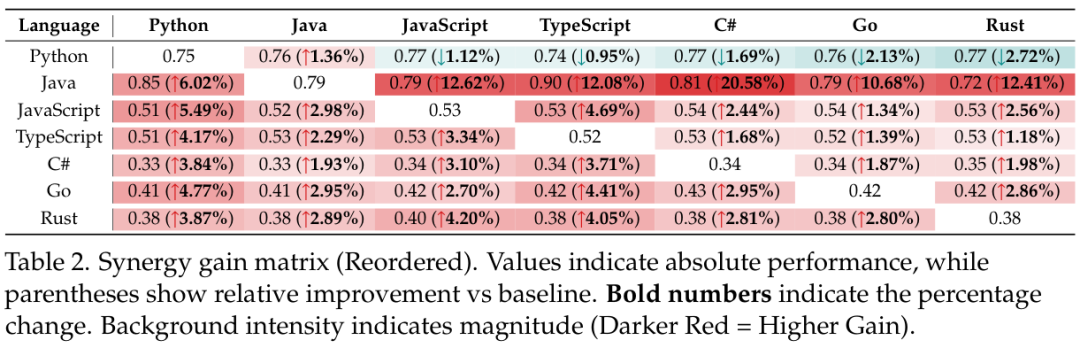
数据清晰地显示,像Java这样的强类型语言对Python、JavaScript等其他语言的学习产生了显著的正向溢出效应,Java对C#的相对提升甚至高达20.58%。
这证明了语言多样性,特别是当它跨越代码领域时,能极大地增强模型的鲁棒性。
这种协同效应的数学表达通过扩展传统的缩放定律来实现,团队在损失函数中明确引入了语言比例参数,捕捉跨语言转移的效果。
在数据处理层面,为了确保输入模型的是纯净的逻辑而非噪声,团队实施了极其严格的清洗流程。
通过抽象语法树(Abstract Syntax Tree, AST)分析来验证代码的句法结构和完整性,确保每一段进入训练管道的代码都是符合语法规则的。
此外,为了扩大质量控制的规模,他们训练了一套专门针对通用文本、代码和数学的领域特定代理分类器,这些小型的代理模型被设计用来模拟更大模型的质量评估能力,在信息密度、教育价值和有毒内容等维度上提供精准的信号,其实证结果优于传统的FastText方法。
在基础预训练之后,是一个至关重要的高质量退火(Annealing)阶段。
这个阶段不再追求数据的广度,而是聚焦于高质量的精选代码,如同铸剑过程中的淬火,确立了模型的基础表征,使其为后续复杂的逻辑任务做好准备。
预训练的语料库来源于Common Crawl等大规模数据集,经过了严格的去重和清洗,甚至引入了包含6600万个样本的CodeSimpleQA-Instruct数据集,通过自动化生成事实性问答对来增强模型在代码相关事实性上的准确度。
这种对数据质量近乎偏执的追求,为IQuest-Coder-V1系列的强大能力奠定了坚实的地基。
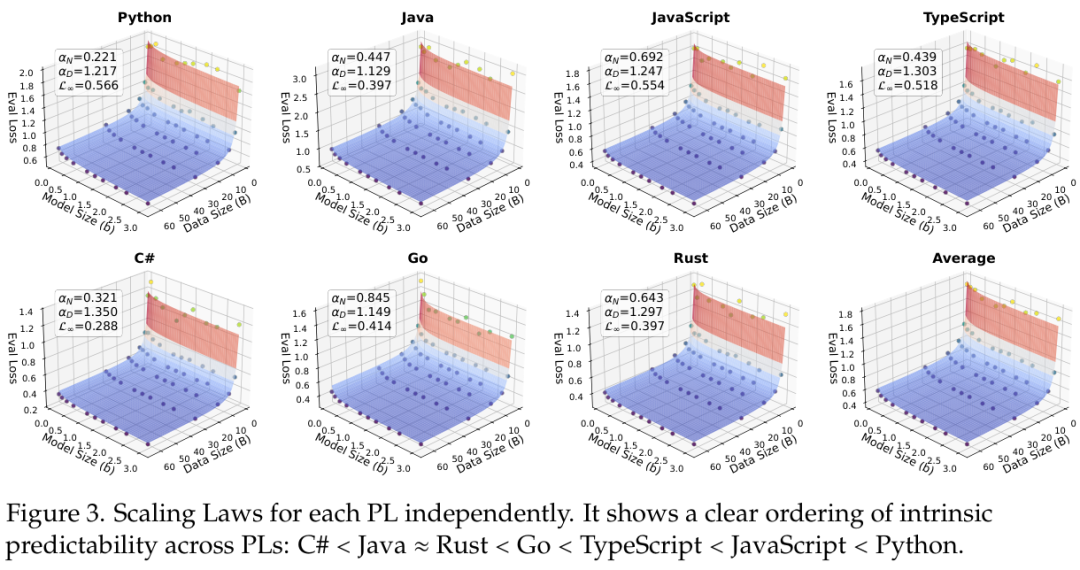
图中展示了每种编程语言独立的缩放定律,揭示了编程语言内在可预测性的清晰排序:C#的可预测性最低,而Python最高。
这一发现对于理解不同语言在模型训练中的行为特征具有重要的参考价值。
循环架构与逻辑脚手架
为了在有限的计算资源下实现更强的推理能力,IQuest-Coder引入了一种极具创新性的架构——LoopCoder。
传统的Transformer架构通常是一次性前向传播,而LoopCoder采用了一种循环机制,通过共享参数的Transformer块在两次固定的迭代中执行计算。
在第一次迭代中,输入嵌入通过具有位置偏移隐藏状态的Transformer层进行处理,建立初步的理解。
而在第二次迭代中,模型会计算两种类型的注意力:全局注意力(Global Attention)和局部注意力(Local Attention)。
全局注意力允许第二次迭代的查询(Query)关注第一次迭代产生的所有键值对(Key-Value),从而获取全局上下文的精炼信息;局部注意力则限制查询仅关注第二次迭代中之前的token,以维持因果性。
这就好比人类在阅读复杂代码时,先通读一遍掌握大意,再回过头来精读细节,LoopCoder通过学习到的门控机制,动态地平衡这两次阅读的信息流,优化了模型容量与部署占用之间的权衡。
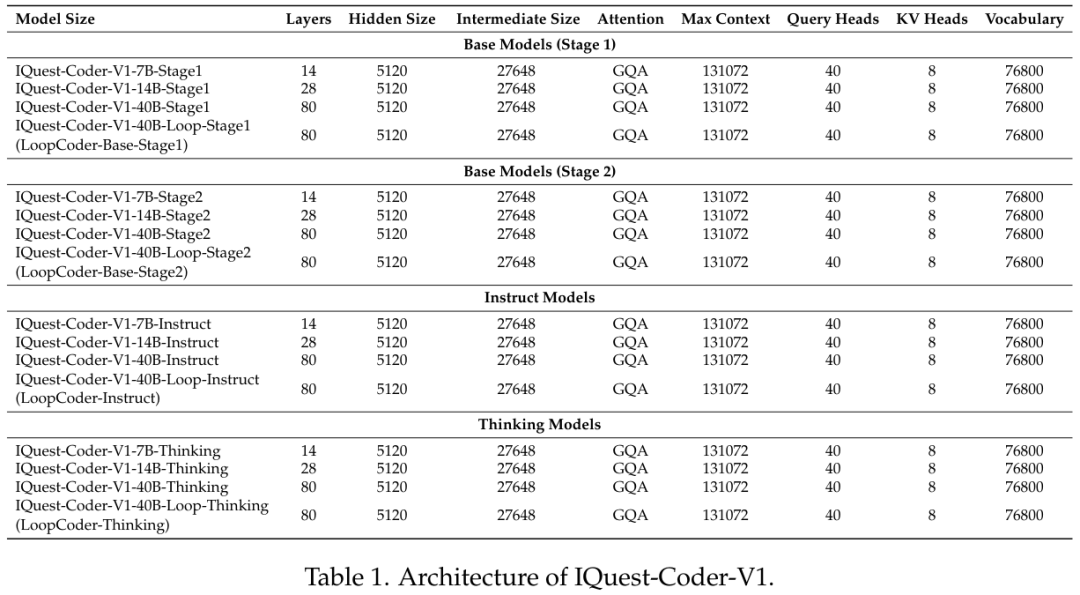
所有模型均支持高达131,072的上下文窗口,这是通过Flash Attention等技术优化实现的。
这种高效的架构为复杂的中间训练(Mid-Training)提供了可能。
中间训练是连接静态知识与代理行动之间的桥梁,它被分为两个阶段,逐步增加上下文长度。
第一阶段使用32k上下文,训练数据包括推理、代理轨迹和代码任务,产出Stage1模型;第二阶段将上下文扩展至128k,专注于更长序列的推理和代码库级别的任务,产出Stage2模型。
团队发现,在高质量代码退火之后、后训练之前,注入32k长度的推理和代理轨迹数据,能够充当关键的逻辑脚手架(Logical Scaffold),稳定模型在分布偏移下的表现。
这种训练迫使模型进行结构化的问题分解和一致性检查,而不是简单的模式匹配。
例如,代理轨迹数据教会了模型闭环智能,即在获得环境反馈(如错误日志、测试结果)后进行观察、修正的循环过程。
这种结合了符号推理支架和接地气代码世界经验的训练,使得模型能够处理长程任务,并从错误中恢复,这是仅靠静态文件训练无法习得的能力。
后训练与强化学习
在后训练阶段,IQuest-Coder展现了对不同应用场景的深刻理解,将训练路径分叉为思考模式(Thinking Models)和指令模式(Instruct Models)。
这两种模式针对不同的优化目标,分别利用了强化学习(RL)的强大能力。
指令模式侧重于通用的代码辅助,优化模型的指令遵循能力;而思考模式则专注于通过显式的推理痕迹来提升深度逻辑能力。
这种分叉策略带来了一个令人兴奋的发现:利用强化学习训练的思考路径,触发了模型在长程任务(如软件工程和代码竞赛任务)中自主错误恢复的涌现能力。
这种能力在标准的指令监督微调(SFT)路径中往往是缺失的。
通过在包含显式推理痕迹的数据上进行监督微调,随后进行针对推理能力优化的强化学习,LoopCoder-Thinking模型学会了在面对复杂问题时停下来思考,生成详细的推理过程,从而显著提升了解决难题的成功率。
后训练的数据构建同样遵循模型中心的框架,利用前沿的大型语言模型生成训练数据,并经过严格的自动化验证。
这包括确定性的基于执行的验证,以及结合规则检查、奖励模型和多智能体辩论的集成机制。
无论是API编排、全栈工程、竞技编程,还是文本到SQL、工具使用,所有数据都经过了精心的合成与筛选。
特别是在大规模监督微调阶段,团队采用了激进的序列打包、余弦退火学习率和三阶段课程学习等优化基础设施,确保数据按难度递进,从而实现稳定的收敛和在复杂基准上的优异表现。
为了防止对齐税(Alignment Tax)导致的通用能力下降,团队采用了重放缓冲区、动态混合适应和组合设计等技术。
同时,针对竞技编程任务,使用了GRPO算法和clip-Higher策略,直接在测试用例通过率上进行强化学习,而不引入KL惩罚。
对于更复杂的软件工程任务,团队构建了基于云端沙盒的可扩展基础设施,将真实的软件工程形式化为交互式强化学习环境,让代理在多步操作中使用工具,并通过测试套件的通过情况获得奖励。
这种并行的轨迹执行和环境反馈,共同锻造了模型自我调试、跨语言迁移和不确定性校准等涌现能力。
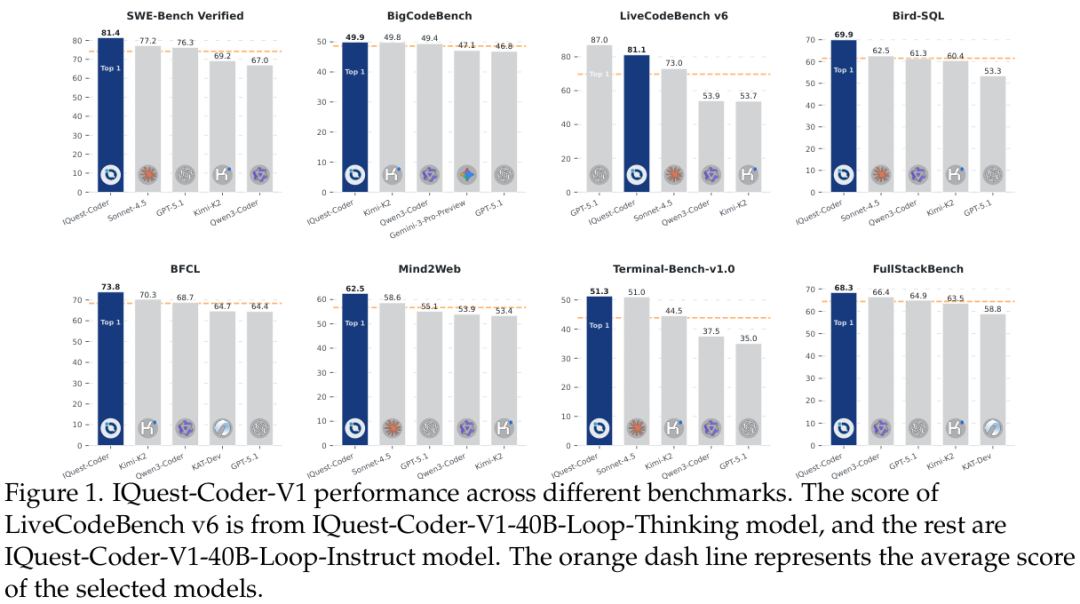
在基准测试中见证性能飞跃
IQuest-Coder-V1在广泛的基准测试中与DeepSeek、Qwen、Claude等顶尖模型进行了比较。
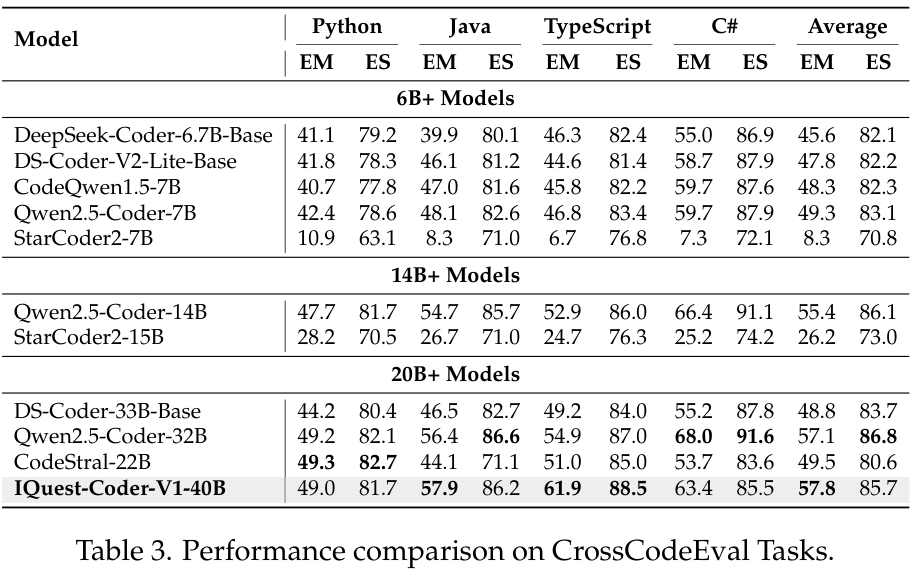
在CrossCodeEval任务中,IQuest-Coder-V1-40B在跨语言代码补全方面表现出了卓越的平衡性,平均EM(精确匹配)得分达到57.8,超越了Qwen2.5-Coder-32B等强劲对手。
这直接验证了其预训练阶段多语言协同策略的有效性。
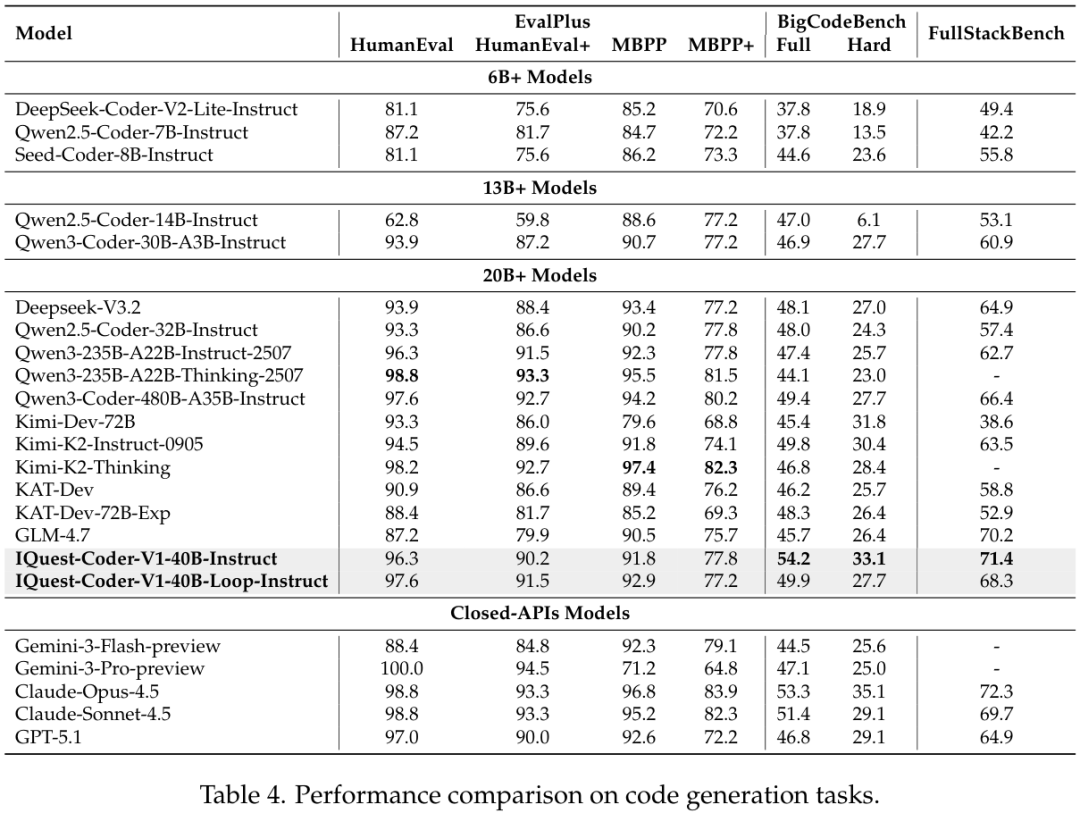
而在代码生成任务上,IQuest-Coder-V1-40B-Loop模型在HumanEval+上的得分高达91.5,在MBPP+上达到77.2,达到了了GPT-5.1和Claude-Sonnet-4.5等闭源巨头的表现。
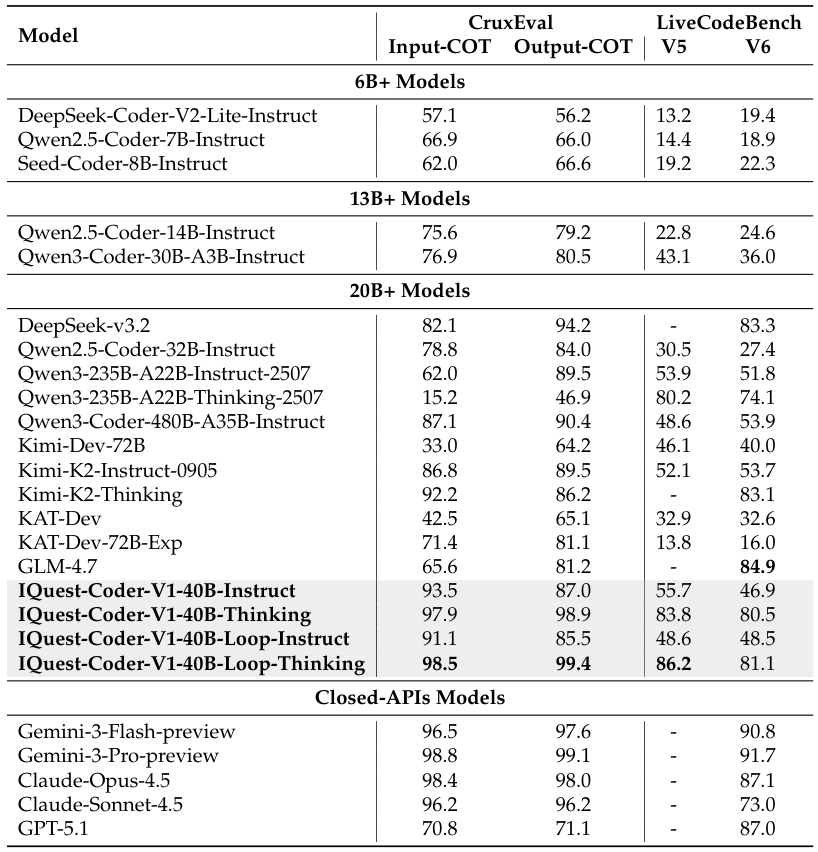
在推理能力方面,CruxEval和LiveCodeBench的测试结果显示了Thinking模型的巨大优势。
IQuest-Coder-V1-40B-Loop-Thinking在CruxEval上取得了99.4的高分,远超GPT-5.1的71.1分。
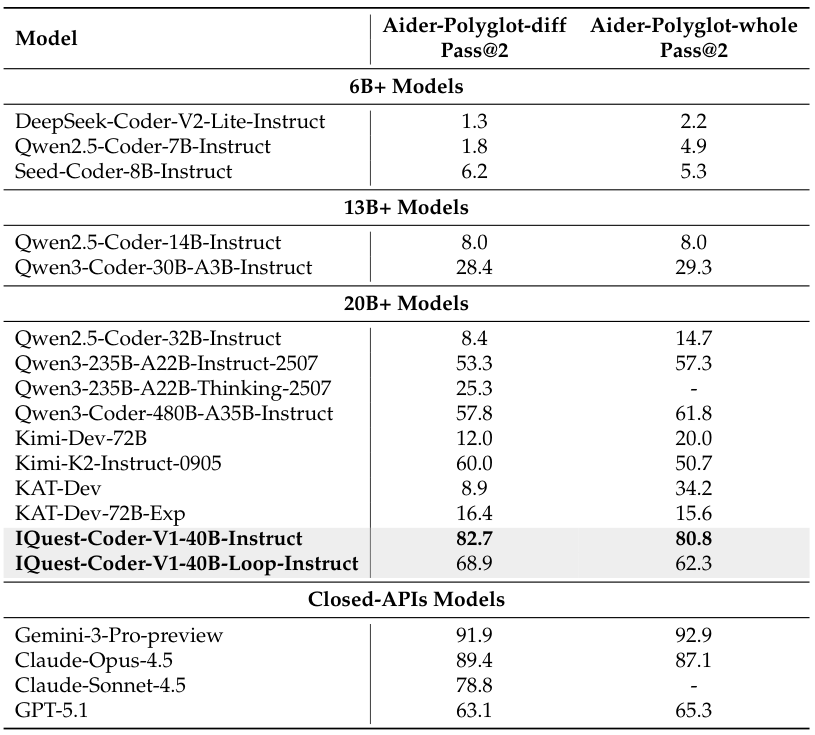
在代码编辑任务上,Instruct模型表现尤为突出,在Aider-Polyglot-diff Pass@2上达到了82.7的分数,显示了其作为实用编码助手的强大潜力。
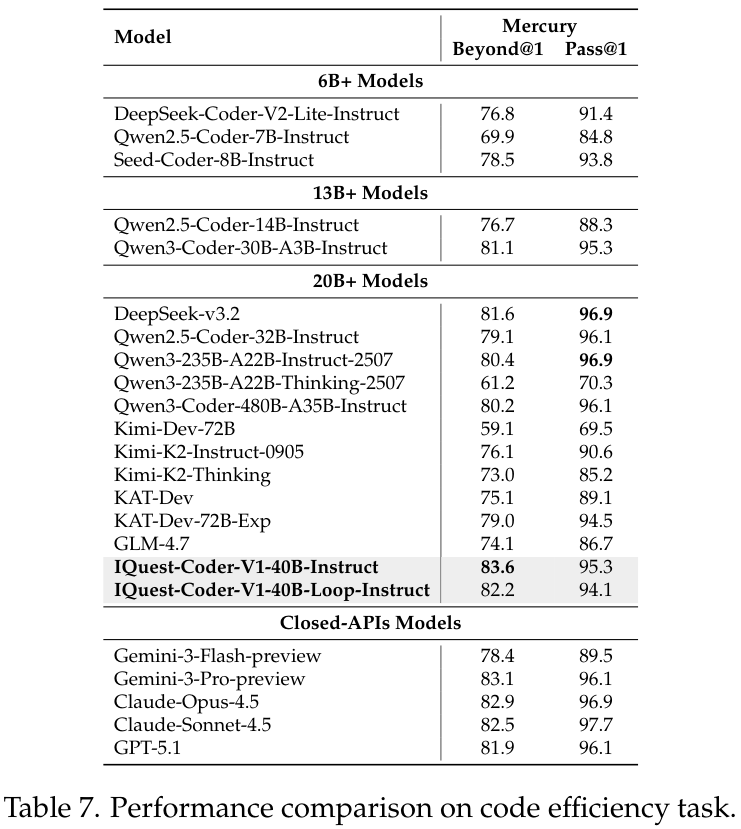
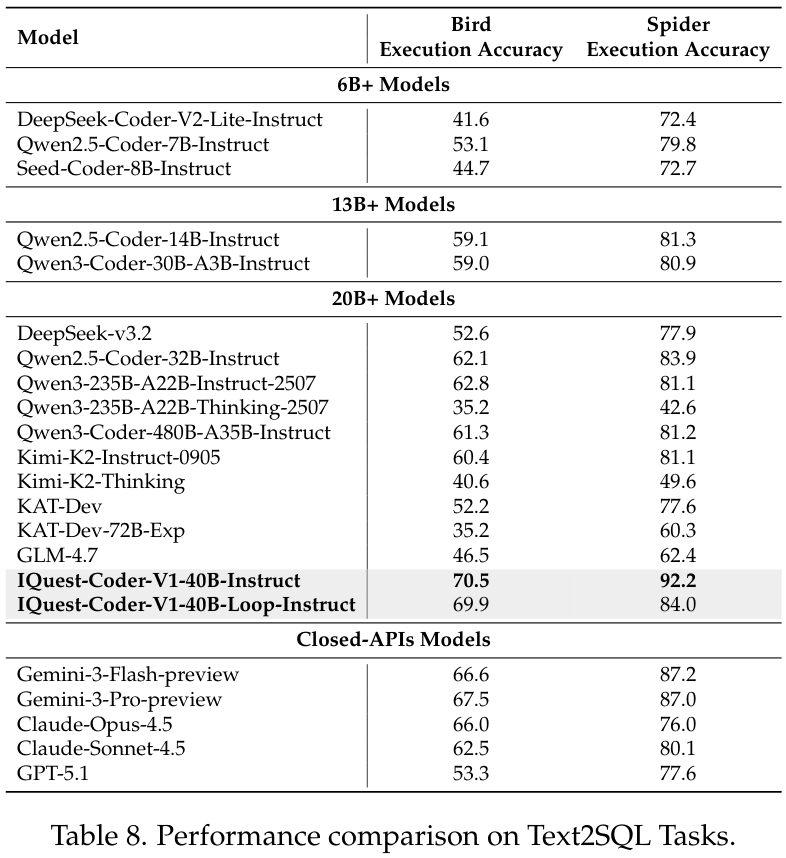
更进一步,在评估代码运行效率的Mercury基准以及Text-to-SQL任务中,模型同样展现了极强的适应性。
特别是在Text-to-SQL的Spider任务中,IQuest-Coder-V1-40B-Instruct取得了92.2的执行准确率,击败了包括Gemini-3和Claude-Opus-4.5在内的所有对手,显示了其在跨领域数据库查询生成上的统治力。
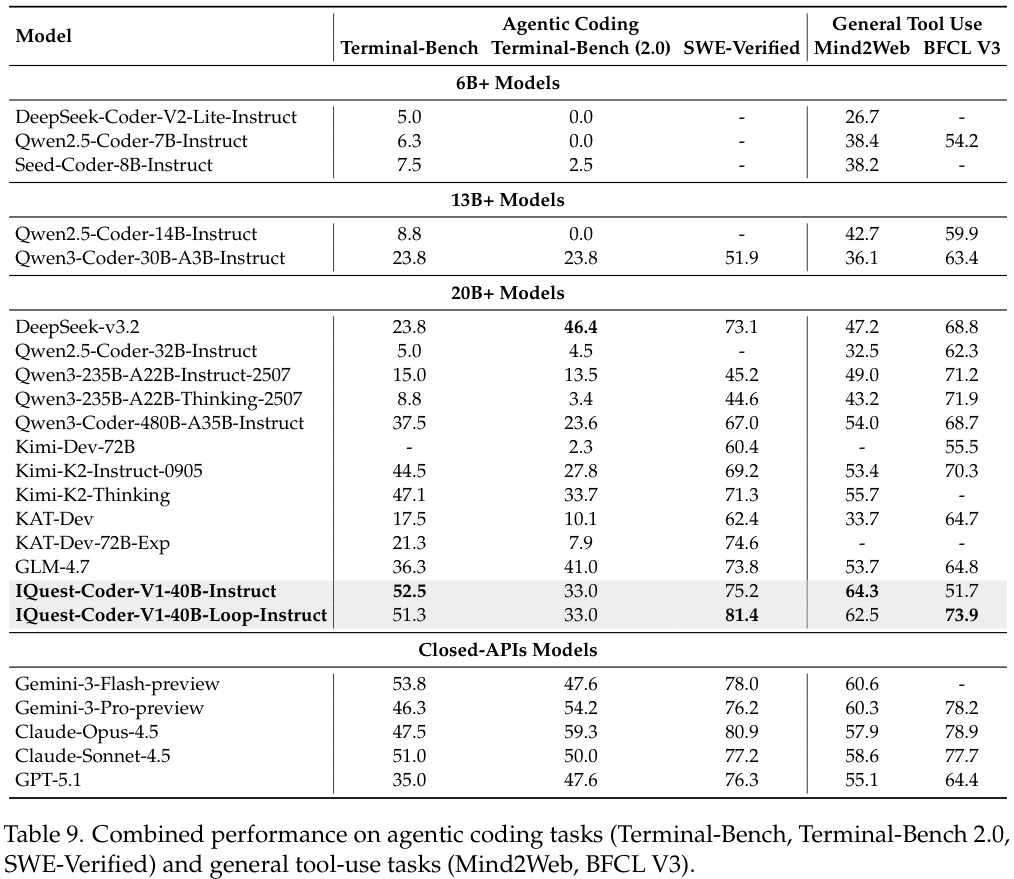
在代理编码(Agentic Coding)和通用工具使用任务中,IQuest-Coder的表现同样抢眼。
特别是在SWE-Verified基准测试中,40B-Loop-Thinking模型取得了81.4的高分,意味着模型能够在标准化的Docker环境中,自主地解决真实世界GitHub仓库中的问题,从阅读Issue到生成并通过测试补丁,其能力已经可以与人类中级开发者相媲美。

最后,安全性评估显示,IQuest-Coder-V1-40B-Thinking模型在保持强大能力的同时,并未牺牲安全性。
其在WildGuardTest和XSTest上的表现甚至超过了部分闭源模型,证明了思考过程有助于模型更好地识别和拒绝有害指令,同时准确响应良性的对抗性提示。
IQuest-Coder-V1系列的发布,为开源社区提供了一套完整的、白盒化的代码智能进化样本。
从动态的代码流预训练,到循环架构的效率创新,再到分叉的后训练策略,每一步都凝聚了对逻辑本质的深刻思考。
这套模型,为开发者构建自主、高效、安全的真实世界代理系统提供了强大的基础。
参考资料:
https://iquestlab.github.io/
https://www.ubiquant.com/website/ai
https://github.com/IQuestLab/IQuest-Coder-V1
https://huggingface.co/collections/IQuestLab/iquest-coder

















 1609
1609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









