



上个月 SAM 3 论文投到顶会 ICLR 2026:万字硬核解读SAM 3:不止分割一切,它开始理解世界了。
接着,字节用LLaVA + SAM-2抢先实现了SAM-3,用概念分割一切,而不需要指出位置。
刚刚,Meta 正式发布了 SAM 3D 和 SAM 3。


Meta 不仅开源了模型权重、推理代码和评测数据集,还推出了 Segment Anything Playground 平台,让研究人员和创作者能够直接体验这些前沿技术。
SAM 3D 能从图像捕捉对象,无论是否遮挡,然后进行 3D 重建。
SAM 3D 突破物理世界的三维重建壁垒
长期以来,3D 重建技术受限于数据的匮乏。
与文本或图像数据相比,高质量 3D 地面真值数据的获取难度高出几个数量级。
以往的模型主要依赖合成 3D 资产进行训练,这导致模型在处理简单背景下的单个物体时表现尚可,但在面对光照复杂、物体遮挡或非标准视角的真实物理世界时,效果往往大打折扣。
SAM 3D 的核心突破在于打破了物理世界 3D 数据的获取瓶颈。
Meta 并没有单纯依赖昂贵的 3D 艺术家从零开始制作模型,而是引入了一种新的数据标注范式:与其让艺术家“画”出 3D 模型,不如让他们“评价”模型生成的质量。
验证和排序网格(Mesh)是一项门槛更低的技能,这使得大规模数据扩展成为可能。
Meta 构建了一个高效的数据引擎,让标注员对模型生成的多个选项进行评分,并将最困难的案例交由专家级 3D 艺术家处理,填补数据盲点。
利用这一引擎,Meta 对近 100 万张不同图像进行了 3D 物体形状、纹理和布局的标注,生成了约 314 万个模型在环(model-in-the-loop)网格。
SAM 3D 包含两个核心子模型:专注于物体和场景重建的 SAM 3D Objects,以及专注于人体姿态与形状估计的 SAM 3D Body。
SAM 3D Objects 采用了一种新的多阶段训练配方,将从合成数据中学习视为 3D 预训练,随后利用数据引擎生成的真实世界数据进行“后训练(post-training)”,以消除模拟与现实之间的差距(sim-to-real gap)。
这一过程形成了一个正向反馈循环:模型鲁棒性的提升优化了数据引擎的生成质量,更优质的数据反过来又促进了模型的迭代。
该模型允许用户从一张自然图像出发,选择任意物体并快速生成具有姿态的 3D 模型。
即使在物体较小、视角受限或存在遮挡的情况下,模型也能利用上下文信息辅助重建。
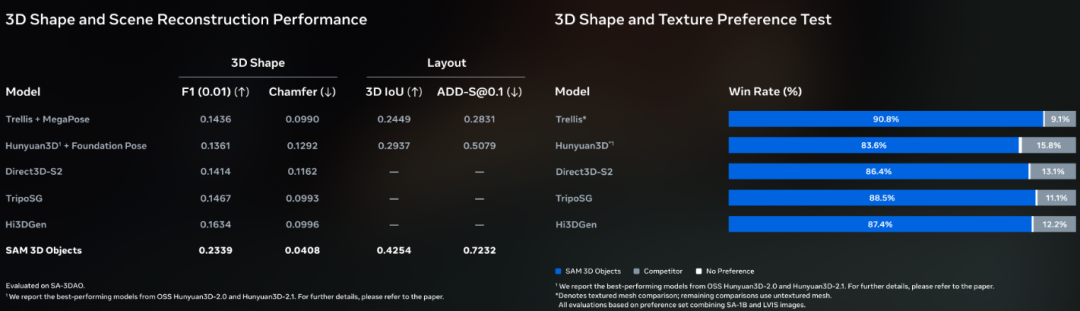
在人机偏好测试中,SAM 3D Objects 对比其他领先模型的胜率达到了 5:1。
结合扩散捷径(diffusion shortcuts)等工程优化,该模型能在几秒钟内生成带有完整纹理的重建结果,具备了支持机器人 3D 感知等近实时应用的潜力。
为了衡量这一领域的进展,Meta 与艺术家合作建立了 SA-3DAO(SAM 3D Artist Objects)数据集。
这是一个包含多样化图像和物体网格的评估基准,其真实感和挑战性远超现有的 3D 基准测试。
尽管表现出色,SAM 3D Objects 目前仍存在局限。
中等的输出分辨率限制了复杂物体的细节表现,例如重建整个人物时可能会出现失真。此外,模型目前逐个预测物体,尚未加入对物体间接触或穿插等物理交互的联合推理。
SAM 3D Body 专注于解决复杂场景下的人体重建问题,包括异常姿势、部分遮挡或多人同框的情况。该模型支持通过分割掩码(Mask)和 2D 关键点等提示(Prompt)进行交互式控制,让用户能够引导模型的预测结果。
技术层面,SAM 3D Body 使用了一种名为 Meta Momentum Human Rig (MHR) 的新型开源 3D 网格格式。
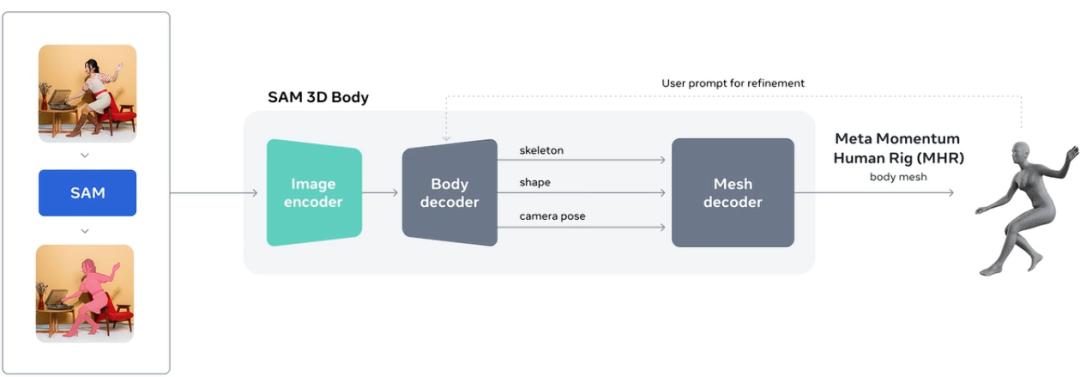
MHR 将人体骨骼结构与软组织形状分离,提升了模型的可解释性。模型架构基于 Transformer 编码器-解码器:图像编码器采用多输入设计以捕捉身体部位的高分辨率细节,网格解码器则扩展支持基于提示的预测。
训练数据的规模和质量是该模型成功的关键。
Meta 从数十亿张图片中筛选出包含异常姿势和罕见拍摄条件的高价值样本,构建了一个约 800 万张图像的高质量训练集。这使得模型在面对遮挡、罕见姿态和多样化服装时具有极高的鲁棒性。
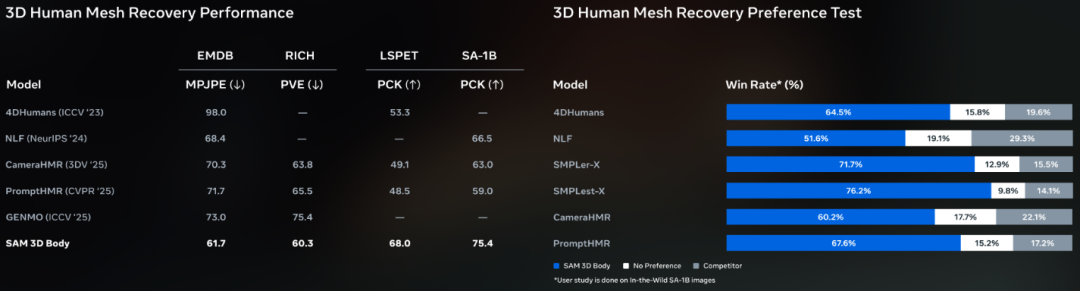
SAM 3D Body 目前将每个人体作为独立个体处理,尚未考虑多人互动或人与物体的物理交互,这限制了其在相对位置推理上的准确性。
同时,尽管手部姿态估计已有显著提升,但精度尚未超越专门的手部姿态估计方法。
SAM 3 实现对视觉概念的极致理解与追踪
与 SAM 3D 专注于三维空间不同,SAM 3(Segment Anything Model 3)致力于统一图像和视频中的物体检测、分割与追踪任务。
传统的计算机视觉模型通常局限于固定的文本标签集,能够识别人,却难以理解“那把红色的条纹雨伞”这类具体的描述。
SAM 3 引入了“可提示概念分割(Promptable Concept Segmentation)”能力,能够查找并分割出由文本或示例提示定义的所有概念实例。
它支持开放词汇的短名词短语作为文本提示,也支持图像示例作为提示,彻底摆脱了预定义标签集的束缚。
同时,它继承并保留了 SAM 1 和 SAM 2 中的视觉提示功能(如点击、框选、掩码),为难以用语言描述的稀有概念提供了灵活的交互方式。
构建一个在所有任务上都表现出色的统一模型,需要解决任务冲突的难题。例如,实例追踪需要区分同类物体的视觉特征,而概念检测则需要同类物体具有相似的特征。
SAM 3 在架构设计上进行了深度融合:
-
编码器: 采用 Meta Perception Encoder,这是 Meta 于今年 4 月开源的模型,相比之前的编码器带来了显著的性能提升。
-
检测器: 基于 DETR 模型,利用 Transformer 进行目标检测。
-
追踪器: 沿用了 SAM 2 的记忆库(Memory Bank)和记忆编码器设计。

在全新的 SA-Co(Segment Anything with Concepts)基准测试中,SAM 3 在图像和视频上的 cgF1 分数(衡量识别和定位概念能力的指标)是现有系统的 2 倍。
它不仅超越了 Gemini 2.5 Pro 等基础模型,也优于 GLEE、OWLv2 和 LLMDet 等强大的专用基线模型。在用户偏好研究中,SAM 3 的输出结果以约 3:1 的比例优于 OWLv2。
SAM 3 的推理速度极快,在 H200 GPU 上处理包含超过 100 个检测对象的单张图像仅需 30 毫秒。
在视频处理中,推理延迟随对象数量线性增加,在约 5 个并发对象的情况下仍能保持近实时的性能。
虽然 SAM 3 本身擅长处理“精装书”这样的短语,但对于“书架顶层右数第二本书”这类涉及复杂空间推理的长难句,它可以通过与多模态大语言模型(MLLM)结合来解决。
在这种名为 SAM 3 Agent 的配置中,MLLM 作为大脑提出名词短语查询,SAM 3 作为感知工具返回掩码,双方迭代直至获得满意结果。
这种组合在 ReasonSeg 和 OmniLabel 等需要推理的基准测试中表现优异。
高质量分割掩码和文本标签的匮乏是训练视觉大模型的主要障碍。
在视频中对每一帧的物体进行详尽掩码标注,是一项极其耗时且昂贵的工作。
Meta 为此构建了一个可扩展的数据引擎,通过 SAM 3、人类标注员和 AI 模型在环的协作,实现了标注效率的飞跃。
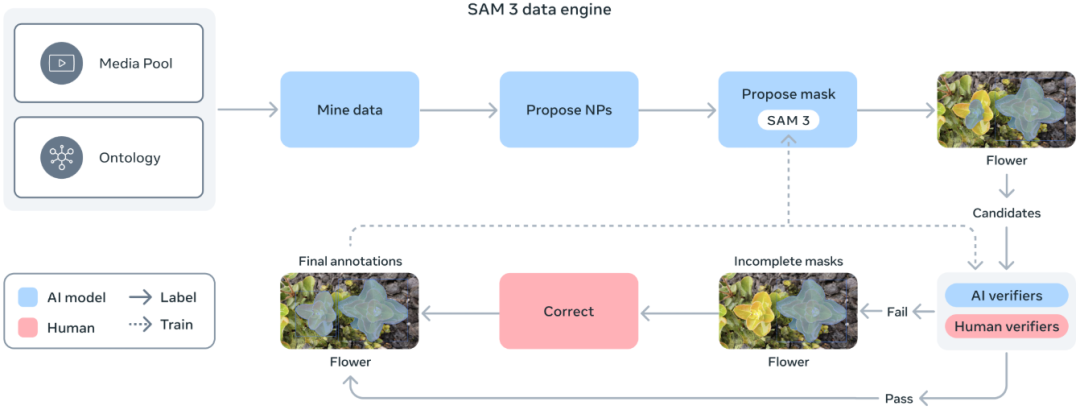
该数据引擎的工作流程如下:
-
自动挖掘: 利用包含 SAM 3 和基于 Llama 的字幕生成器(Captioner)在内的 AI 模型管道,自动挖掘图像和视频。
-
生成建议: 系统生成字幕,将其解析为文本标签,并创建初始的分割掩码建议(Candidates)。
-
人工与 AI 验证: 人类和 AI 标注员对这些建议进行验证和修正。其中,AI 标注员基于 Llama 3.2v 模型,经过专门训练以达到或超过人类的验证准确率。
AI 标注员能够自动过滤掉简单的样本,让人类标注员专注于当前模型无法处理的困难案例。
这种混合系统的标注速度比纯人工快约 5 倍(针对负面提示),即使在精细领域,针对正面提示的速度也提升了 36%。
最终,该引擎构建了一个包含超过 400 万个独特概念的大规模多样化训练集。
Meta 还利用基于维基百科的概念本体(Concept Ontology)将文本标签映射到共享概念空间,从而增加了对低频概念的覆盖率。
消融研究证明,集成 AI 和人工标注的标签显著提升了模型性能。
SAM 3D 和 SAM 3 已赋能 Facebook Marketplace 的 View in Room 功能,提升了用户的购物体验。
在 Instagram 的视频创作应用 Edits 中,SAM 3 将很快支持创作者对视频中的特定人物或物体应用动态效果。
Meta AI 应用中的 Vibes 功能和网页端的 meta.ai 也将利用这些技术,让用户能够重新混合 AI 生成的视频或使用视觉创作工具。
为了降低使用门槛,Meta 推出了 Segment Anything Playground 平台。
用户无需具备技术背景,即可上传图片或视频,利用现有模板(如面部打码、运动轨迹、特定对象放大)进行创意编辑,或从零开始体验模型的分割和重建能力。
Meta 此次发布,展示了其在 3D 重建和通用分割领域的最新技术高度,更通过开源代码、数据集和易用的游乐场平台,为全球开发者和研究者提供了探索物理世界和视觉理解的新工具。
随着微调代码的发布,社区将能够针对医疗、科学等特定领域进一步优化这些模型,推动人工智能在更广泛场景中的应用。
参考资料:
https://ai.meta.com/blog/sam-3d/
https://ai.meta.com/blog/segment-anything-model-3/
https://github.com/facebookresearch/sam-3d-objects
https://github.com/facebookresearch/sam-3d-body
https://github.com/facebookresearch/sam3
https://huggingface.co/facebook/models
END


















 1556
1556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









