



具身智能未来发展路径的突破性尝试,NVIDIA 利用 40000 小时带有按键显示的互联网游戏视频,训练出了一个能玩 1000 多款游戏的通用基础模型。
,时长00:20
NVIDIA 发布 NitroGen 模型,通过从公开游戏视频中提取手柄操作指令,构建了目前规模最大的视觉-动作数据集,让 AI 能够在未见过的游戏中展现出惊人的泛化能力。

构建能够在未知环境中从容行动的通用具身智能体,长久以来都是人工智能研究领域的顶级目标。
计算机视觉和大语言模型已经通过在海量互联网数据上的预训练实现了这种泛化能力,但具身智能领域却因为缺乏大规模、多样化且带有动作标签的数据集而步履维艰。
电子游戏提供了视觉丰富且交互复杂的环境,是推进具身智能的理想温床。
以往的方法要么依赖手动编写的程序接口,要么依赖复杂的感知模块,或者受限于昂贵的强化学习训练成本。
NVIDIA 提出的 NitroGen 通过利用带有输入叠加层的互联网视频,自动提取玩家动作,构建了包含 40000 小时视频和动作标签的数据集,并在此基础上训练了一个基于流匹配的视觉-动作转换模型,在跨游戏泛化和微调任务中展现了卓越性能。
另辟蹊径解决数据匮乏难题
训练通用智能体最大的拦路虎是数据。
互联网上虽然有海量的游戏视频,但绝大多数都只有画面,缺乏对应玩家操作的动作标签。没有动作标签,AI 就无法学习看到什么画面应该做什么动作。
NitroGen 团队并没有去雇佣大量人员玩游戏,也没有去破解每一款游戏的后台数据,而是敏锐地发现了一个被忽视的数据金矿:带有输入叠加层(Input Overlay)的游戏视频。
在速通(Speedrun)社区和许多硬核玩家的直播中,为了展示操作技巧,玩家往往会在屏幕角落开启一个实时显示手柄按键状态的插件。这个可视化的 2D 手柄图像,就是天然的动作标签。
利用这一发现,研究团队构建了一个自动化管道,从公开网络上收集了原始时长达 71000 小时的视频素材。
为了避免单一游戏的数据主导模型,他们结合了关键词搜索和多样性导向的策展策略,确保数据覆盖了不同的游戏类型、流派和技能水平。
最终清洗后的数据集包含了来自 818 位不同内容创作者的 38739 个视频,平均每个视频时长 1 小时 50 分钟。
这些视频覆盖了超过 1000 款独特的游戏,使其成为迄今为止最大的电子游戏视频-动作数据集。
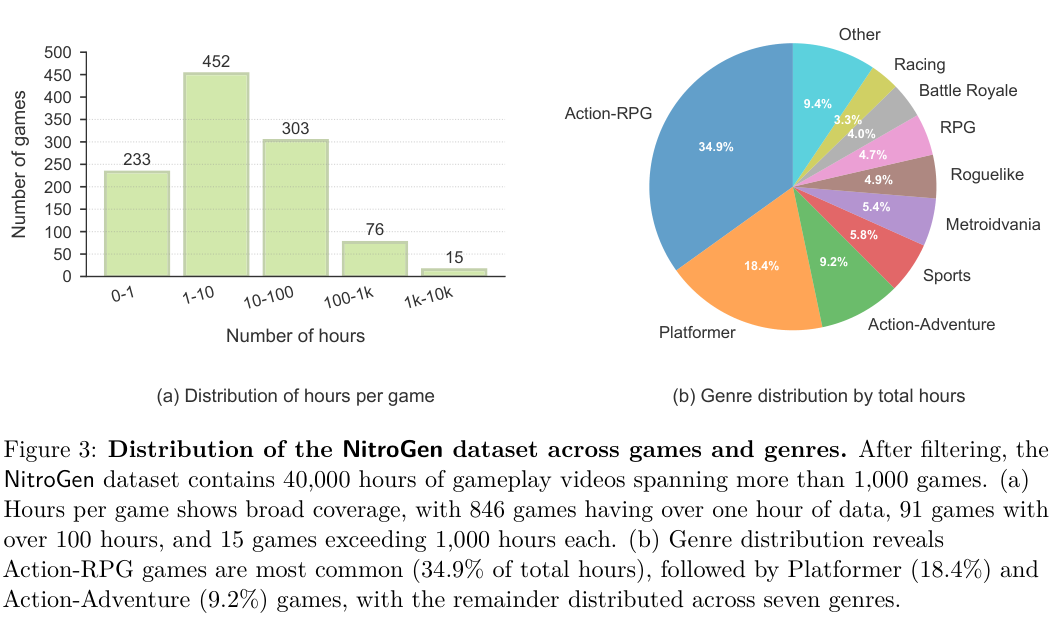
从数据分布来看,动作角色扮演游戏(Action-RPG)占据了主导地位,占比达到 34.9%,其次是平台跳跃类游戏(Platformer)占比 18.4%。
这种分布虽然存在一定偏倚,但涵盖了大量需要快速反应和精准控制的场景,非常适合训练反应型智能体。
自动化动作提取的三级火箭
有了视频,如何把屏幕上的虚拟手柄变回计算机可读的动作指令?研究团队设计了一套包含三个阶段的自动化处理流程,将像素转化为数据。
第一阶段是模板匹配。
由于不同玩家使用的手柄皮肤、透明度各不相同,系统需要先找到手柄在哪。
团队收集了约 300 个常见的手柄模板,利用 SIFT 和 XFeat 特征匹配技术,在视频中采样帧进行比对。只要找到匹配度最高的区域,就锁定了手柄的位置。

第二阶段是手柄动作解析。
这里使用了一个经过微调的 SegFormer 分割模型。
该模型接收连续两帧图像作为输入,以捕捉短时的动态变化。它并不直接回归摇杆的坐标,而是输出一个分割掩码,将摇杆位置定位在一个 11x11 的离散网格上,同时预测按键的开关状态。
实证表明,通过分割掩码估计摇杆位置比直接回归坐标的效果要好得多。
为了训练这个解析模型,团队使用了合成数据。
他们将手柄模板以程序化的方式叠加到游戏画面上,模拟各种透明度、尺寸和视频压缩噪点,生成了 800 万帧带有完美标签的训练数据。
第三阶段是质量过滤。
原始数据中包含了大量闲置或无意义的片段。如果直接使用,模型容易学会什么都不做。
因此,团队通过动作密度进行筛选,只保留那些至少有 50% 的时间步包含非零按键或摇杆动作的片段。这一步过滤掉了一半的数据,最终保留了约 40000 小时的高质量素材。
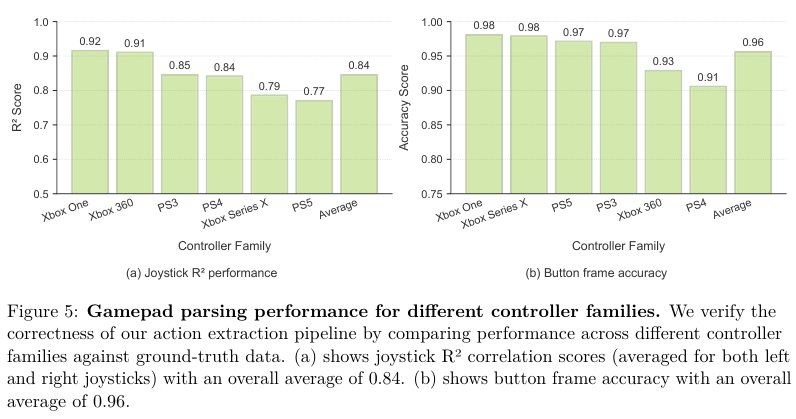
为了验证这套流程的准确性,研究人员在受控环境下录制了 6 款游戏的视频,并记录了真实的按键输入。
结果显示,该管道在提取摇杆位置时的 R2 分数达到了 0.84,按键状态的准确率高达 0.96,证明了从视频中反向工程玩家操作是高度可靠的。
统一架构与通用模拟器
NitroGen 不仅是一个数据集,还包含评估环境和基础模型的解决方案。
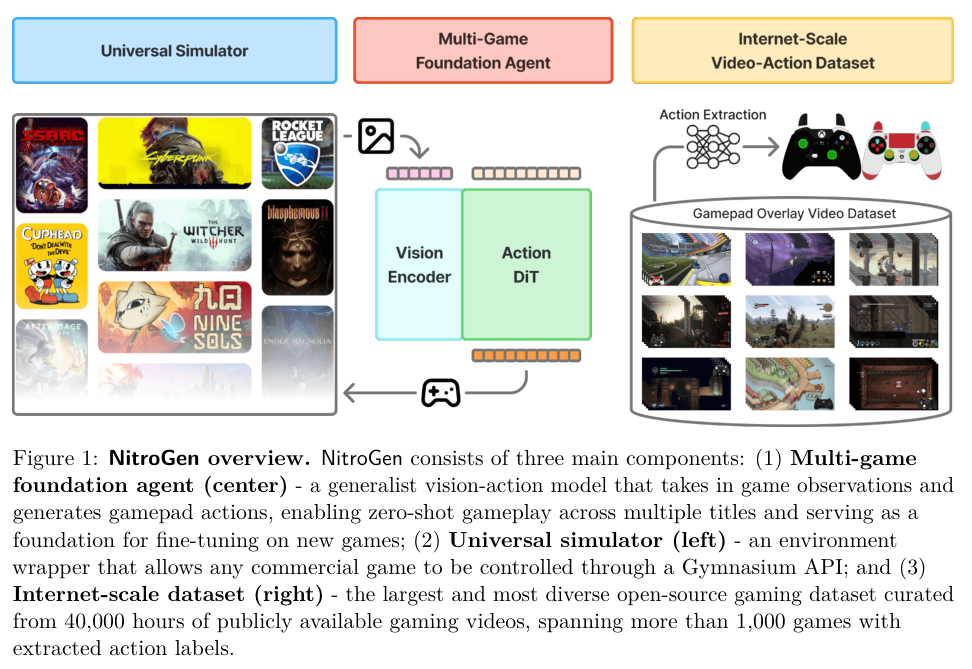
为了测试智能体的通用性,研究团队开发了一个通用模拟器(Universal Simulator)。
商业游戏通常不具备供 AI 调用的 API,这使得自动化测试变得极为困难。
该团队开发了一个库,通过拦截游戏引擎的系统时钟来控制仿真时间。
这种方法允许在不修改游戏代码的情况下进行逐帧交互,确保了物理模拟的一致性,使得任何依赖系统时钟的游戏都可以被封装成标准的 Gymnasium API 接口。
在模型架构方面,NitroGen 采用了基于流匹配(Flow Matching)的生成式模型。
其视觉编码器使用了 SigLIP 2 视觉 Transformer,将 256x256 分辨率的 RGB 图像编码为 256 个图像 Token。
动作生成部分采用扩散 Transformer(DiT)。
不同于传统的单步预测,NitroGen 每次前向传播会生成未来的 16 个动作块(Chunk)。这种分块预测策略不仅提高了推理效率,更重要的是增强了动作在时间维度上的一致性。
有趣的是,尽管模型设计上支持多帧历史输入,但实验发现仅使用当前一帧画面作为上下文就足够了。
增加历史帧并没有带来明显的性能提升,这表明在快节奏的动作游戏中,当前的视觉状态通常已经包含了决策所需的全部信息。
动作空间被统一为一个标准化的格式:16 维的二进制向量用于表示按键(包括方向键、功能键、扳机键等),以及 4 维的连续向量用于表示左右摇杆的位置。
这种统一的接口设计打破了游戏之间的壁垒,使得模型可以在不同游戏间无缝迁移策略。
跨游戏泛化与微调的实战表现
NitroGen 的核心价值在于其强大的泛化能力。
研究人员设计了一个包含 10 款游戏、30 项任务的多游戏评估套件,涵盖了 2D 平台跳跃、3D 开放世界、格斗以及程序生成环境等多种类型。
在预训练阶段,模型没有针对任何特定游戏进行微调,仅凭在海量互联网视频中学到的知识进行操作。
结果显示,NitroGen 在面对全新环境时表现出了非凡的能力。
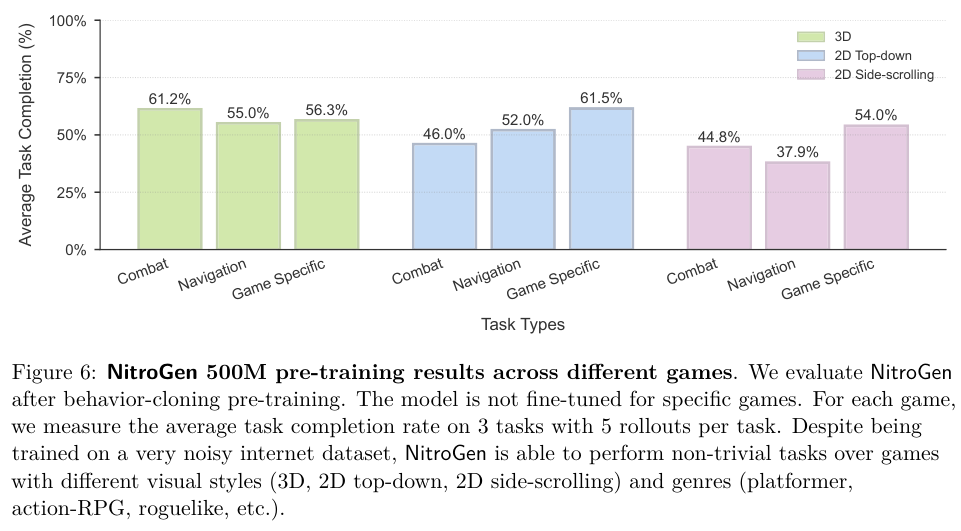
无论是需要记忆固定路线的关卡,还是每次进入都完全不同的程序生成世界,NitroGen 都能应对自如。这说明它不仅仅是记住了视频中的像素,而是真正理解了游戏机制和视觉线索之间的联系。
为了验证预训练对后续学习的帮助,研究人员进行了留一法实验:在训练集中剔除某款游戏,然后用该游戏的少量数据对模型进行微调,并与从零开始训练的模型进行对比。
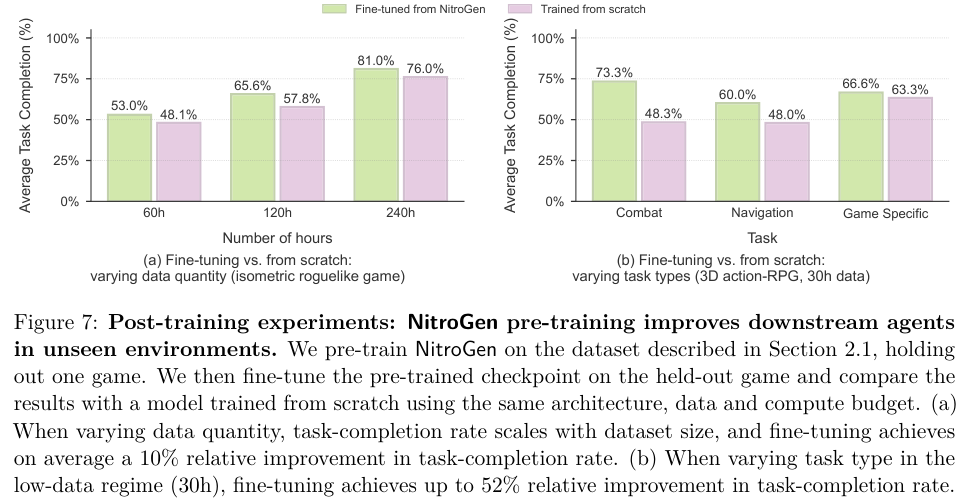
实验结果令人振奋。
在数据量较少的情况下,经过预训练的 NitroGen 模型比从零训练的模型表现出显著优势。
特别是在 3D 动作 RPG 游戏中,对于战斗这类通用任务,相对性能提升高达 52%。
导航任务也提升了 25%。
这意味着 NitroGen 确实学到了可迁移的通用技能,如看见敌人要攻击、看见障碍要躲避。
不过,对于一些游戏特有的机制,预训练带来的收益相对较小(约 5%)。这符合直觉:通用的战斗直觉可以迁移,但特定游戏的解谜逻辑或独特技能仍需专门学习。
NitroGen 利用互联网上现存的视频资源,即便数据中含有噪声(如直播聊天框、不同的手柄映射、非完美操作),依然可以训练出鲁棒的通用策略。
它主要是一个依赖直觉进行瞬时决策,缺乏长期的规划能力和语言理解能力的模型。
数据集虽然庞大,但主要集中在使用手柄操作的动作游戏,对于依赖键盘鼠标的策略类或模拟经营类游戏覆盖不足。
尽管如此,NitroGen 为具身智能的发展铺平了一条新路。
通过降低在原本封闭的商业游戏中训练 AI 的门槛,并提供开源的数据集、模拟器和模型权重,它将为未来通用智能体研究发挥作用。
AI 学会了像人类一样通过视觉观察和手柄操作来探索成千上万个虚拟世界也许不再遥远了。
参考资料:
https://nitrogen.minedojo.org/
https://nitrogen.minedojo.org/assets/documents/nitrogen.pdf
https://github.com/MineDojo/NitroGen
https://huggingface.co/nvidia/NitroGen

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









